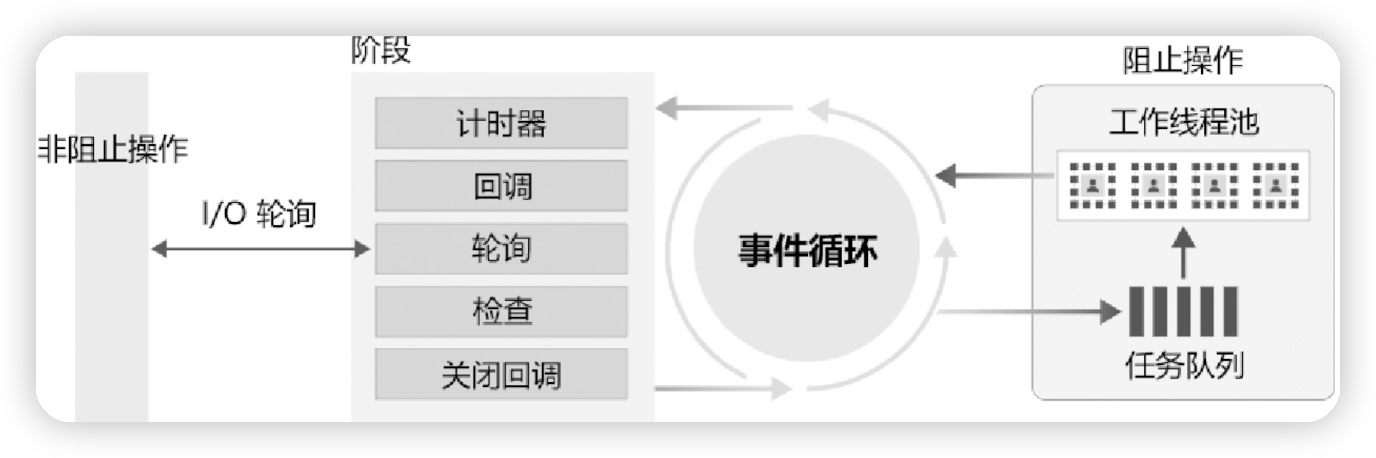
之前一直是做目标检测的研究,在目标检测中主要有两个任务,一个是分类回归,一个是位置回归,所用的评价指标有:AP,mAP,Recall,Precision,F1值,前两个用的一般最多,AP是P与R所围的面积。但在本文中,主要是介绍在分类网络中的评价指标。
在分类网络中常用到的评价指标其实有很多,比如准确率(Acc)、错误率(ErroRate)、精确率(Precision)、召回率(Recall)、F1、ROC等等。
1.准确率(Acc)
我们在做分类任务训练的时候经常会在每个训练迭代后打印acc,那么acc是怎么算的呢?先来看下公式:
公式中的变量的含义:
TP:表示分类正确的正样本;
TN:表示分类正确的负样本;
FP:表示分类错误的正样本(实际就是该类为负样本但识别为正样本了);
FN:表示分类错误的负样本(实际就是该类为正样本但却识别为负样本了);
总结一句话:acc就是分类网络识别正确的样本在所有样本中的占比!
该评价指标是我们经常用的,但这个评价有一定的局限性,比如数据集中的类别数量差距较大出现了不均衡,那么acc是无法客观的评价算法性能的。
因此我们在训练网络之前,在拿到数据集的时候应该先对数据集进行分析。
2.错误率
明白了准确率acc就可以知道错误率了,错误率很好计算:
该评价指标和acc一样,在不均衡的数据集中其实是不够客观的,而且也无法定位具体是什么原因导致的错误率。
3.精确度(Precision)和召回率(Recall)
精确度P和召回率R在目标检测中也常常作为评价指标。P和R针对的目标是不同的,接下来将进一步介绍。
精确度也称为查准率,是针对预测结果的,表示在所有被识别为正样本的中实际正样本的概率。
比如二分类中,网络识别了100个目标为“狗”这个类,但这100个目标中其实有80个是真正的狗(也就是正样本),那么此时的P就是80%。P值越高识别的准确率越高。公式如下:
召回率也称为查全率,是针对原样本的,表示在实际的正样本中被预测为正样本的概率(通俗的讲就是在所有正样本中,网络真正找到了多少,所以也什么叫查全)。同样也是希望值越高越好。公式如下:
理想情况下我们是希望两者都越高越好,但实际情况中两者是一对矛盾体,一个高,另一个很容易低。
4.F1值
F1值是P与R的加权调和平均,是能够反映P与和R整体好坏的指标,F1值越高越好。公式如下:
5.ROC曲线
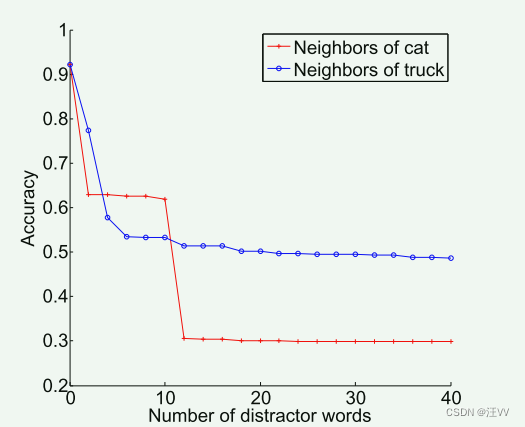
重头戏来了,也是本文的重点。ROC曲线也称为受试者操作曲线。是分类器分类能力随分类阈值的变化而变化的曲线。曲线图如下所示:
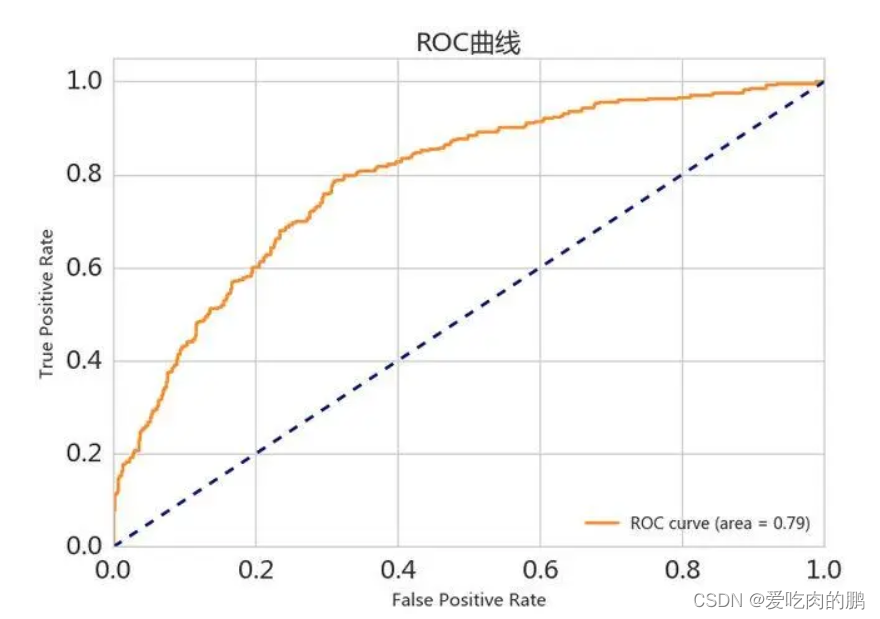
先说结论:曲线越陡峭越接近于左上角,说明模型越好。
接下来再来解释原因。在曲线图中横坐标称之为假阳率(FPR),和前面的FP含义类似,在所有真实的负样本中被识别为正样本的比例,计算公式如下:
纵坐标为真阳率(TPR),和之前的TP含义类似,表示在所有真实的正样本中,被识别为正样本的比例,也就是召回率了。公式如下:
我们希望FPR越低越好(误检低),希望TPR越高越好(准确率高),所以曲线就是越陡峭越接近于左上角越好,也就是横坐标越小的情况下希望纵坐标值越大。
那么ROC曲线中左下角的点就会表示为:全部识别为负样本
那么ROC曲线中右上角的点就会表示为:全部识别为正样本
因此可以理解为,FPR是可以判断模型的误检程度,TPR是模型对正样本的召回程度。
而为什么ROC评价指标和前面的Acc相比更为客观呢?这是因为即便数据集出现了不平衡的问题,ROC并不对此敏感,因为只有TPR和FPR有关。
我们前面也提到了,ROC曲线是会随着阈值的变化而变化的,如果我们的阈值小,那么TPR就会高(希望得到更多的正样本),那么FPR也会高(误检也会升高),曲线会向右上角偏移。阈值越高,TPR会降低,FPR降低(希望误检低),那么曲线会向左下角偏移。
总结为:
阈值越大,TPR、FPR均降低,曲线向左下角偏移;
阈值越小,TPR、FPR均升高,曲线向右上角偏移;
因此我们可以根据ROC得到推荐阈值,或者说最佳阈值用于生产任务中。方法为:
1.找到ROC曲线最靠近左上角的点,对应该点的阈值为最佳阈值;
2.根据具体业务场景需要,权衡正样本和负样本的分类重要性,看是召唤重要还是降低误检重要来定最佳阈值。
参考资料:
[1] 分类算法的性能度量指标