深度学习笔记之优化算法——Adam算法的简单认识
- 引言
- 回顾:基于Nesterov动量的RMSProp算法
- Adam算法的简单认识
- 一阶矩、二阶矩修正偏差的功能
- Adam的算法过程描述
- Adam示例代码
引言
上一节介绍了基于 Nesterov \text{Nesterov} Nesterov动量与 RMSProp \text{RMSProp} RMSProp的融合算法,本节将介绍《深度学习(花书)》 P187 8.5 \text{P187 8.5} P187 8.5自适应学习率算法中的最后一个算法: Adam \text{Adam} Adam算法。
回顾:基于Nesterov动量的RMSProp算法
基于
Nesterov
\text{Nesterov}
Nesterov动量的
RMSProp
\text{RMSProp}
RMSProp算法,其特点在于:对梯度大小(学习率)与梯度方向同时优化。其对应的迭代公式表示如下:
关于动量、学习率加权平均方法的差异性描述,详见上一节链接。
{
θ
^
t
=
θ
t
−
1
+
γ
⋅
m
t
−
1
G
t
=
∇
θ
;
t
−
1
J
(
θ
^
t
)
R
t
=
β
⋅
R
t
−
1
+
(
1
−
β
)
⋅
G
t
⊙
G
t
m
t
=
γ
⋅
m
t
−
1
−
η
R
t
⊙
G
t
θ
t
=
θ
t
−
1
+
m
t
\begin{cases} \hat \theta_{t} = \theta_{t-1} + \gamma \cdot m_{t-1} \\ \mathcal G_t = \nabla_{\theta;t-1} \mathcal J(\hat \theta_t) \\ \mathcal R_t = \beta \cdot \mathcal R_{t-1} + (1 - \beta) \cdot \mathcal G_t \odot \mathcal G_t \\ \begin{aligned} m_t = \gamma \cdot m_{t-1} - \frac{\eta}{\sqrt{\mathcal R_t}} \odot \mathcal G_t \end{aligned} \\ \theta_t = \theta_{t-1} + m_t \end{cases}
⎩
⎨
⎧θ^t=θt−1+γ⋅mt−1Gt=∇θ;t−1J(θ^t)Rt=β⋅Rt−1+(1−β)⋅Gt⊙Gtmt=γ⋅mt−1−Rtη⊙Gtθt=θt−1+mt
Adam算法的简单认识
而 Adam \text{Adam} Adam算法与上述算法的思想相同,即迭代过程中,对梯度大小、方向均进行优化。不同点在于:
- 无论是梯度大小(学习率)还是梯度方向,均使用指数加权移动平均法进行更新:
{ G = ∇ θ ; t − 1 J ( θ t − 1 ) m t = ρ 1 ⋅ m t − 1 + ( 1 − ρ 1 ) ⋅ G R t = ρ 2 ⋅ R t − 1 + ( 1 − ρ 2 ) ⋅ G ⊙ G \begin{cases} \mathcal G = \nabla_{\theta;t-1} \mathcal J(\theta_{t-1}) \\ m_t = \rho_1 \cdot m_{t-1} + (1 - \rho_1) \cdot \mathcal G \\ \mathcal R_t = \rho_2 \cdot \mathcal R_{t-1} + (1 - \rho_2) \cdot \mathcal G \odot \mathcal G \end{cases} ⎩ ⎨ ⎧G=∇θ;t−1J(θt−1)mt=ρ1⋅mt−1+(1−ρ1)⋅GRt=ρ2⋅Rt−1+(1−ρ2)⋅G⊙G - 使用指数加权移动平均法更新的基础上,分别对更新结果
m
t
,
R
t
m_t,\mathcal R_t
mt,Rt进行偏差修正:
关于第一个公式,我们对累积梯度(向量) m t m_t mt进行修正,其本质是对梯度向量 G \mathcal G G进行修正,因而称其为一阶矩偏差修正;同理,第二个公式,我们对累积梯度内积(标量) R t \mathcal R_t Rt进行修正,其本质对梯度内积 G ⊙ G \mathcal G \odot \mathcal G G⊙G进行修正,因而称其为二阶矩偏差修正。其中t t t表示迭代步骤的编号。
{ m ^ t = 1 1 − ( ρ 1 ) t ⋅ m t R ^ t = 1 1 − ( ρ 2 ) t ⋅ R t \begin{cases} \begin{aligned} \hat {m}_t & = \frac{1}{1 - (\rho_1)^t} \cdot m_t \\ \hat {\mathcal R}_t & = \frac{1}{1 - (\rho_2)^t} \cdot \mathcal R_t \end{aligned} \end{cases} ⎩ ⎨ ⎧m^tR^t=1−(ρ1)t1⋅mt=1−(ρ2)t1⋅Rt
- 最终对权重进行更新:
该操作与AdaGrad,RMSProp \text{AdaGrad,RMSProp} AdaGrad,RMSProp原理相同。
θ t = θ t − 1 + Δ θ = θ t − 1 − η ϵ + R ^ t ⋅ m ^ t \begin{aligned} \theta_t & = \theta_{t-1} + \Delta \theta \\ & = \theta_{t-1} - \frac{\eta}{\epsilon + \sqrt{\hat {\mathcal R}_t}} \cdot \hat {m}_t \end{aligned} θt=θt−1+Δθ=θt−1−ϵ+R^tη⋅m^t
下面从个人理解的角度认知:为什么要使用一个关于迭代步骤 t t t的非线性函数对一阶矩、二阶矩的偏差进行修正。
一阶矩、二阶矩修正偏差的功能
首先,从《深度学习(花书)》中关于 ρ 1 , ρ 2 \rho_1,\rho_2 ρ1,ρ2的描述开始:
-
ρ 1 , ρ 2 \rho_1,\rho_2 ρ1,ρ2分别是调整当前梯度/梯度内积与历史累积梯度/梯度内积的比例因子;
-
在书中关于 ρ 1 , ρ 2 \rho_1,\rho_2 ρ1,ρ2的初始化步骤中分别为: ρ 1 = 0.9 , ρ 2 = 0.999 \rho_1 = 0.9,\rho_2 = 0.999 ρ1=0.9,ρ2=0.999。可以看出:无论是梯度还是梯度内积,在迭代过程中极其依赖历史信息,而不是当前步骤信息;
与此同时,完全可以作出 ρ 1 , ρ 2 \rho_1,\rho_2 ρ1,ρ2固定条件下,一阶矩系数 1 1 − ( ρ 1 ) t \begin{aligned}\frac{1}{1 - (\rho_1)^t}\end{aligned} 1−(ρ1)t1、二阶矩系数 1 1 − ( ρ 2 ) t \begin{aligned}\frac{1}{1 - (\rho_2)^t}\end{aligned} 1−(ρ2)t1随迭代步骤 t t t增长的修正变化曲线:

结合上面的权重更新公式可以看出:在迭代初始的几个步骤内,给予 m t ⇒ m ^ t m_t \Rightarrow \hat {m}_t mt⇒m^t较高的增长;但与此同时,同样使用较低的 η ϵ + R ^ t \begin{aligned}\frac{\eta}{\epsilon + \sqrt{\hat {\mathcal R}_t}}\end{aligned} ϵ+R^tη约束 m ^ t \hat {m}_t m^t增长的幅度;
虽然从图中可以看出迭代初期ρ 1 , ρ 2 \rho_1,\rho_2 ρ1,ρ2之间的函数结果相差几十倍,但通过⋅ \sqrt{\cdot} ⋅的消减,使得它们的增长与约束处于同一个量级。
很明显,这是一场对抗,但这场对抗仅仅持续了迭代初期的若干次步骤中。那么换一种思路:为什么在迭代初期的对抗最激烈 ? ? ? 迭代初期发生了什么 ? ? ? 不要忘记,由于 ρ 1 , ρ 2 \rho_1,\rho_2 ρ1,ρ2取值的原因,导致整个迭代过程都非常依赖历史信息,并且初始点通常是随机初始化的,也就是说:初始位置的梯度信息是不确定、不稳定的;
而初始的几次迭代步骤,可能会出现大幅度的折叠、震荡,而这种变化剧烈的梯度若累积在历史梯度/历史梯度内积中,会导致后续的迭代不稳定。虽然这种不稳定被系数 1 1 − ( ρ 1 ) t \begin{aligned}\frac{1}{1 - (\rho_1)^t}\end{aligned} 1−(ρ1)t1小规模放大,但同样被强劲的系数 1 ϵ + R t \begin{aligned}\frac{1}{\epsilon + \sqrt{\mathcal R_t}}\end{aligned} ϵ+Rt1压制,使其虽然梯度方向震荡的很厉害(梯度方向较大),但这种状态没有办法移动较大的步长(梯度大小较小),从而压制住震荡的产生。
该部分更多是对算法的个人理解,不否认,我们可以尝试修改 ρ 1 , ρ 2 \rho_1,\rho_2 ρ1,ρ2的值,但需要知道的是:两者之间的取值存在一种均衡关系。
Adam的算法过程描述
基于
Adam
\text{Adam}
Adam的算法步骤表示如下:
初始化操作:
- 学习率 η \eta η;一阶矩、二阶矩衰减速率 ρ 1 , ρ 2 ∈ [ 0 , 1 ) ( 0.9 , 0.999 ) \rho_1,\rho_2 \in [0,1)(0.9,0.999) ρ1,ρ2∈[0,1)(0.9,0.999);
- 超参数 ϵ = 1 0 − 8 \epsilon = 10^{-8} ϵ=10−8;初始权重参数 θ \theta θ;初始化迭代步骤 t = 0 t=0 t=0;
- 初始化历史累积梯度 m = O m = \mathcal O m=O( O \mathcal O O表示零向量);初始化历史累积梯度内积 R = 0 \mathcal R = 0 R=0;
算法过程:
- While \text{While} While没有达到停止准则 do \text{do} do
- 从训练集 D \mathcal D D中采集出包含 k k k个样本的小批量: { ( x ( i ) , y ( i ) ) } i = 1 k \{(x^{(i)},y^{(i)})\}_{i=1}^k {(x(i),y(i))}i=1k;
- 计算当前迭代步骤参数
θ
\theta
θ的梯度信息
G
\mathcal G
G:
G ⇐ 1 k ∑ i = 1 k ∇ θ L [ f ( x ( i ) ; θ ) , y ( i ) ] \mathcal G \Leftarrow \frac{1}{k} \sum_{i=1}^k \nabla_{\theta} \mathcal L[f(x^{(i)};\theta),y^{(i)}] G⇐k1i=1∑k∇θL[f(x(i);θ),y(i)] - 迭代步骤 t ⇐ t + 1 t \Leftarrow t + 1 t⇐t+1;
- 使用指数加权移动平均法对历史累积梯度
m
m
m进行更新:
m ⇐ ρ 1 ⋅ m + ( 1 − ρ 1 ) ⋅ G m \Leftarrow \rho_1 \cdot m + (1 - \rho_1) \cdot \mathcal G m⇐ρ1⋅m+(1−ρ1)⋅G - 使用指数加权移动平均法对历史累积梯度内积
R
\mathcal R
R进行更新:
R ⇐ ρ 2 ⋅ R + ( 1 − ρ 2 ) ⋅ G ⊙ G \mathcal R \Leftarrow \rho_2 \cdot \mathcal R + (1 - \rho_2) \cdot \mathcal G \odot \mathcal G R⇐ρ2⋅R+(1−ρ2)⋅G⊙G - 对历史累积梯度
m
m
m进行偏差修正:
m ^ ⇐ 1 1 − ( ρ 1 ) t ⋅ m \hat m \Leftarrow \frac{1}{1 - (\rho_1)^t} \cdot m m^⇐1−(ρ1)t1⋅m - 对历史累积梯度内积
R
\mathcal R
R进行偏差修正:
R ^ ⇐ 1 1 − ( ρ 2 ) t ⋅ R \hat {\mathcal R} \Leftarrow \frac{1}{1 - (\rho_2)^t}\cdot \mathcal R R^⇐1−(ρ2)t1⋅R - 计算当前迭代步骤权重参数的更新量
Δ
θ
\Delta \theta
Δθ:
标量乘向量,即向量中的每一个分量均乘一个− η ϵ + R ^ \begin{aligned}-\frac{\eta}{\sqrt{\epsilon + \hat {\mathcal R}}}\end{aligned} −ϵ+R^η
Δ θ = − η ϵ + R ^ ⋅ m ^ \Delta \theta = -\frac{\eta}{\sqrt{\epsilon + \hat {\mathcal R}}} \cdot \hat {m} Δθ=−ϵ+R^η⋅m^ - 应用更新:
θ ⇐ θ + Δ θ \theta \Leftarrow \theta + \Delta\theta θ⇐θ+Δθ - End While \text{End While} End While
Adam示例代码
依然使用凸函数
f
(
x
)
=
x
T
Q
x
;
x
=
(
x
1
,
x
2
)
T
;
Q
=
(
0.5
0
0
20
)
f(x) = x^T \mathcal Qx;x=(x_1,x_2)^T;\mathcal Q = \begin{pmatrix}0.5 \quad 0 \\ 0 \quad 20\end{pmatrix}
f(x)=xTQx;x=(x1,x2)T;Q=(0.50020)作为目标函数,观察其迭代过程。对应代码表示如下:
复制粘贴过来的,哈哈~
import numpy as np
import math
import matplotlib.pyplot as plt
from tqdm import tqdm
def f(x, y):
return 0.5 * (x ** 2) + 20 * (y ** 2)
def ConTourFunction(x, Contour):
return math.sqrt(0.05 * (Contour - (0.5 * (x ** 2))))
def Derfx(x):
return x
def Derfy(y):
return 40 * y
def DrawBackGround():
ContourList = [0.2, 1.0, 4.0, 8.0, 16.0, 32.0]
LimitParameter = 0.0001
for Contour in ContourList:
# 设置范围时,需要满足x的定义域描述。
x = np.linspace(-1 * math.sqrt(2 * Contour) + LimitParameter, math.sqrt(2 * Contour) - LimitParameter, 200)
y1 = [ConTourFunction(i, Contour) for i in x]
y2 = [-1 * j for j in y1]
plt.plot(x, y1, '--', c="tab:blue")
plt.plot(x, y2, '--', c="tab:blue")
def Adam():
def DeviationCorrection(Input,RhoParameter,Step):
if type(Input) == tuple:
Res = (Input[0] / (1 - (RhoParameter ** Step)),Input[1] / (1 - (RhoParameter ** Step)))
return Res
else:
return Input / (1 - (RhoParameter ** Step))
Start = (8.0, 1.0)
LocList = list()
LocList.append(Start)
StartMomentum = (0.0, 0.0)
R = 0.0
Eta = 0.3
Step = 0
Rho1 = 0.9
Rho2 = 0.999
Epsilon = 0.00000001
Delta = 0.1
while True:
DerStart = (Derfx(Start[0]),Derfy(Start[1]))
Step += 1
UpdateMomentum = ((Rho1 * StartMomentum[0]) + ((1 - Rho1) * DerStart[0]),
(Rho1 * StartMomentum[1]) + ((1 - Rho1) * DerStart[1]))
InnerProduct = (DerStart[0] ** 2) + (DerStart[1] ** 2)
DecayR = R * Rho2
R = DecayR + ((1.0 - Rho2) * InnerProduct)
CorrectionMomentum = DeviationCorrection(UpdateMomentum,Rho1,Step)
CorrectionR = DeviationCorrection(R,Rho2,Step)
UpdateMessage = (-1 * (Eta * CorrectionMomentum[0]) / (math.sqrt(CorrectionR) + Epsilon),
-1 * (Eta * CorrectionMomentum[1]) / (math.sqrt(CorrectionR) + Epsilon))
Next = (Start[0] + UpdateMessage[0],Start[1] + UpdateMessage[1])
DerNext = (Derfx(Next[0]),Derfy(Next[1]))
if math.sqrt((DerNext[0] ** 2) + (DerNext[1] ** 2)) < Delta:
break
else:
LocList.append(Next)
StartMomentum = UpdateMomentum
Start = Next
return LocList
def DrawPicture():
NesterovRMSPropLocList = Adam()
plt.figure(figsize=(10,5))
NesterovRMSPropplotList = list()
DrawBackGround()
for (x, y) in tqdm(NesterovRMSPropLocList):
NesterovRMSPropplotList.append((x, y))
plt.scatter(x, y, s=30, facecolor="none", edgecolors="tab:red", marker='o')
if len(NesterovRMSPropplotList) < 2:
continue
else:
plt.plot([NesterovRMSPropplotList[0][0], NesterovRMSPropplotList[1][0]], [NesterovRMSPropplotList[0][1], NesterovRMSPropplotList[1][1]], c="tab:red")
NesterovRMSPropplotList.pop(0)
plt.show()
if __name__ == '__main__':
DrawPicture()
对应图像结果表示如下:

关于
ρ
1
,
ρ
2
\rho_1,\rho_2
ρ1,ρ2的取值情况,为了保证它们之间的均衡关系,在取值过程中需要注意一下。例如:
ρ
1
=
0.3
,
ρ
2
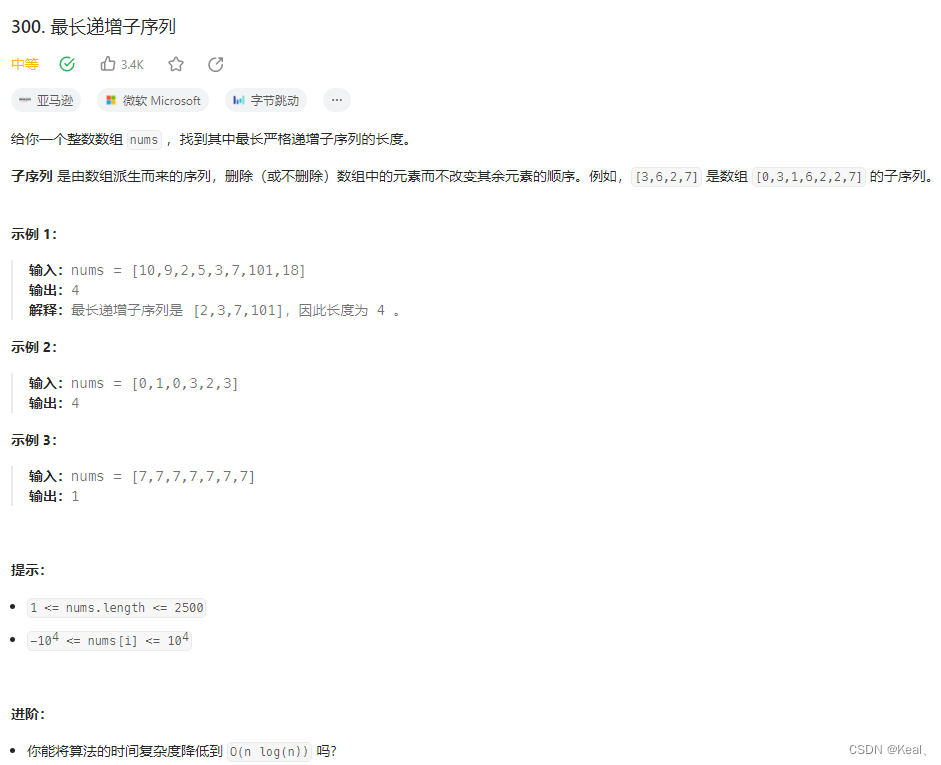
=
0.9
\rho_1 = 0.3,\rho_2 = 0.9
ρ1=0.3,ρ2=0.9对应的函数图像结果表示如下:
因为这个凸函数示例过于简单,大家可以试一试其他的参数组合方式~

至此,深度学习中的优化方法暂时告一段落。
Reference
\text{Reference}
Reference:
《深度学习(花书)》
P189 8.5.3 Adam
\text{P189 8.5.3 Adam}
P189 8.5.3 Adam










![[安洵杯 2019]easy_web - RCE(关键字绕过)+md5强碰撞+逆向思维](https://img-blog.csdnimg.cn/d0ff84da22ea4f94aed095be3ef40e27.png)