目录
进一步实现哈希桶
引入
keyofValue
迭代器
insert返回值
operator[ ]
key不能修改
模拟实现
keyofValue
代码
迭代器
谁在前
普通迭代器转换为const迭代器
const *this 问题
代码
insert和erase
const迭代器转换为普通迭代器
key不能修改
完整版代码
unordered set
代码
unordered map
思路
operator[ ]
erase
代码
进一步实现哈希桶
引入
之前实现的哈希桶,仅仅只是其中的一部分
keyofValue
- 首先,为了和set,map适配,需要一个keyofValue的模板(用来处理set和map不同类型的元素)
- set和map的元素类型,一个K,一个pair<K,V>,但我们有些接口都需要K类型的,所以为了map,set就陪着它一起用一个函数拿到K (K是模板,传入啥类型都行,参考红黑树的set和map)
- (之后就简称了哈,其实ordered系列和红黑树版本的set,map区别真不大,封装出来的接口都是一样的,只不过底层实现不同而已)
迭代器
- 其次,非常重要的迭代器需要实现,很多接口返回的都是迭代器,接受的也是迭代器
- 所以,这里就会出现const迭代器和普通迭代器相互转换的问题!!! 后面细说
- (全是因为set!!(咬牙切齿),它的迭代器实际上都是const类型,但调用hash的insert返回的迭代器又是普通类型的,就很难搞)
insert返回值
- 我们之前的insert返回的是结点指针,但为了和stl保持一致,需要返回pair<iterator,bool>,bool用于标记是否完成插入
operator[ ]
- map中有[ ]操作
- 就是传入K类型,如果存在的话,返回对应的value;不存在就需要插入该key,value使用默认初始化
key不能修改
- 千万不要忘了,set和map中的key值都是不能修改的!!!
模拟实现
keyofValue
不需要在hash中实现,只需要在模板中加入即可
不同的类,让他自己传入相应的keyofValue就行
代码
template <class K, class T, class KeyOfValue, class HF> class HashBucket;set:
template <class K> class unordered_set { struct KeyOfV { const K& operator()(const K& data) { return data; } }; }map:
template <class K, class V> class unordered_map { // 通过key获取value的操作 struct KeyOfValue { const K& operator()(const pair<K, V>& data) { return data.first; } }; }
迭代器
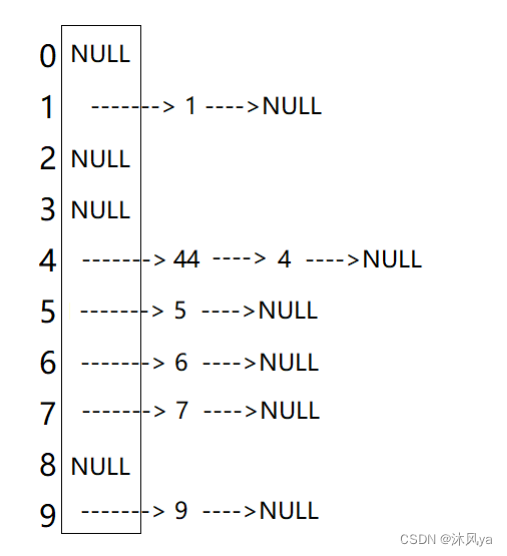
观察一下哈希桶的结构,想象迭代器在上面走的样子
- 因为我们可能需要知道下一条链的位置,所以,需要一个哈希桶的对象,那么,可以直接使用*this来获得哈希桶的资源(现成的指针,不用白不用)
谁在前
- 但是这样就会导致一个问题 -- 哈希表需要用迭代器,但迭代器也需要用哈希表,到底谁在前呢?
- 所以,我们给迭代器类一个哈希桶的前置声明,让迭代器先生成出来,这样就能生成哈希桶了,反过来又继续生成迭代器
- 除此之外,还有最让人头疼的问题,const迭代器
- 比如,在之前红黑树就出现过的将普通迭代器赋值给const迭代器的问题
普通迭代器转换为const迭代器
- 这是红黑树中的(本质完全是一样的):
- 所以,需要在迭代器的构造函数中,增加一个函数:
const *this 问题
接下来,还是set引发的问题:
- 因为两种迭代器都是封装的const迭代器,所以只需要提供const类型的begin和end即可
- 然后,set里的函数去调用了哈希桶里const版本的begin/end:
- 但是!!!!迭代器的构造函数是直接传入对象指针的:
- 所以需要将接收哈希桶对象指针的参数改为底层const类型
- 但是,又会出现使用底层const的指针去初始化一个普通指针(一般来说,不知道会出现这些问题的话,是不会加const的)
- 所以,最终,我们要把这个对象指针改成底层const类型的(改了后不会影响,因为迭代器内部不会修改哈希桶)
代码
template <class K, class T, class KeyOfValue, class HF> class HashBucket; // 前置声明,因为迭代器中要用到哈希桶,而哈希桶也要用到迭代器 // 但迭代器肯定是先的那个,所以给迭代器一个前置声明,让他可以先使用哈希桶(声明不需要给默认值) template <class K, class T, class Ptr, class Ref, class KeyOfValue, class HF> struct HBIterator { typedef HashBucket<K, T, KeyOfValue, HF> HB; typedef HashBucketNode<T>* PNode; typedef HBIterator<K, T, Ptr, Ref, KeyOfValue, HF> Self; // 自己,用于返回 typedef HBIterator<K, T, T*, T&, KeyOfValue, HF> iterator; //用于解决set中插入的问题 KeyOfValue kot; HBIterator(PNode pNode = nullptr, const HB* pHt = nullptr) //因为会出现传入的指针是底层const类型的情况,所以这里也改 : _pnode(pNode), _pHt(pHt) // 需要结点指针+哈希桶对象的指针 { } HBIterator(const iterator& it) : _pnode(it._pnode), _pHt(it._pHt) // 需要结点指针+哈希桶对象的指针 //虽然增加了构造,但会导致,用普通对象构造 { } Self& operator++() { // 当前迭代器所指节点后还有节点时直接取其下一个节点 if (_pnode->_next) { _pnode = _pnode->_next; } else { // 找下一个不空的桶,返回该桶中第一个节点 size_t hashi = _pHt->HashFunc(kot(_pnode->_data)) + 1; _pnode = nullptr; // 这里提前赋值,以防;没有下一个桶后,可以返回指向空的迭代器 for (; hashi < _pHt->BucketCount(); ++hashi) { if (_pnode = _pHt->_table[hashi]) // 注意,这里用到了哈希桶的私密成员,所以需要让迭代器成为哈希桶的友元 { // 好妙 break; } // if (_pHt->_ht[hashi]) // { // _pnode = _pHt->_ht[hashi]; // break; // } } } return *this; } Self operator++(int) { Self tmp(*this); ++(*this); return tmp; } Ref operator*() { return _pnode->_data; } Ptr operator->() { return &_pnode->_data; } bool operator==(const Self& it) const { return _pnode == it._pnode; } bool operator!=(const Self& it) const { return _pnode != it._pnode; } PNode _pnode; // 当前迭代器关联的节点(也就是迭代器的本质) const HB* _pHt; // 哈希桶--为了找下一个位置 //因为,会出现传入的指针是底层const类型的情况,所以这里可以直接定义为底层const类型的指针,因为迭代器内部不修改哈希桶 };





insert和erase
insert的问题主要在于它的返回值,把返回值一改就行
其中存在的普通迭代器转const迭代器已经在上面解决了
但是!!!
由于有这种接口,接收const迭代器,返回普通迭代器,所以需要在erase内部转化一下
const迭代器转换为普通迭代器
其实很简单,将定义出的一个初始的const迭代器,++到要转化的普通迭代器的位置就行
auto it = const_iterator(begin()); int count = 0; while (it != cur) { ++it; ++count; } auto a = iterator(begin()); for (int i = 0; i < count; ++i) { ++a; } return a;

key不能修改
只要将元素类型中的K,传入const K类型就行
完整版代码
#pragma once
#include <iostream>
#include <vector>
#include <string>
#include <type_traits>
using namespace std;
// 哈希桶
namespace my_hash_bucket
{
// hsfunc
// 用于拿到数据对应的整型值->然后可以得到对应的hashi
template <class T>
class HSFunc
{
public:
size_t operator()(const T& val)
{
return val;
}
};
template <>
class HSFunc<string>
{
public:
size_t operator()(const string& s)
{
int size = s.size();
unsigned int seed = 131; // 31 131 1313 13131 131313 都可以
unsigned int hashi = 0;
for (size_t i = 0; i < size; ++i)
{
hashi = hashi * seed + s[i];
}
return hashi;
}
};
// 结点
template <class T>
struct HashBucketNode // 每个位置下链接的结点
{
HashBucketNode(const T& data)
: _next(nullptr), _data(data)
{
}
HashBucketNode<T>* _next;
T _data;
};
// 迭代器
template <class K, class T, class KeyOfValue, class HF>
class HashBucket; // 前置声明,因为迭代器中要用到哈希桶,而哈希桶也要用到迭代器
// 但迭代器肯定是先的那个,所以给迭代器一个前置声明,让他可以先使用哈希桶(声明不需要给默认值)
template <class K, class T, class Ptr, class Ref, class KeyOfValue, class HF>
struct HBIterator
{
typedef HashBucket<K, T, KeyOfValue, HF> HB;
typedef HashBucketNode<T>* PNode;
typedef HBIterator<K, T, Ptr, Ref, KeyOfValue, HF> Self; // 自己,用于返回
typedef HBIterator<K, T, T*, T&, KeyOfValue, HF> iterator; //用于解决set中插入的问题
KeyOfValue kot;
HBIterator(PNode pNode = nullptr, const HB* pHt = nullptr) //因为会出现传入的指针是底层const类型的情况,所以这里也改
: _pnode(pNode), _pHt(pHt) // 需要结点指针+哈希桶对象的指针
{
}
HBIterator(const iterator& it)
: _pnode(it._pnode), _pHt(it._pHt) // 需要结点指针+哈希桶对象的指针
{
}
Self& operator++()
{
// 当前迭代器所指节点后还有节点时直接取其下一个节点
if (_pnode->_next)
{
_pnode = _pnode->_next;
}
else
{
// 找下一个不空的桶,返回该桶中第一个节点
size_t hashi = _pHt->HashFunc(kot(_pnode->_data)) + 1;
_pnode = nullptr; // 这里提前赋值,以防;没有下一个桶后,可以返回指向空的迭代器
for (; hashi < _pHt->BucketCount(); ++hashi)
{
if (_pnode = _pHt->_table[hashi]) // 注意,这里用到了哈希桶的私密成员,所以需要让迭代器成为哈希桶的友元
{ // 好妙
break;
}
// if (_pHt->_ht[hashi])
// {
// _pnode = _pHt->_ht[hashi];
// break;
// }
}
}
return *this;
}
Self operator++(int)
{
Self tmp(*this);
++(*this);
return tmp;
}
Ref operator*()
{
return _pnode->_data;
}
Ptr operator->()
{
return &_pnode->_data;
}
bool operator==(const Self& it) const
{
return _pnode == it._pnode;
}
bool operator!=(const Self& it) const
{
return _pnode != it._pnode;
}
PNode _pnode; // 当前迭代器关联的节点(也就是迭代器的本质)
const HB* _pHt; // 哈希桶--为了找下一个位置
//因为,会出现传入的指针是底层const类型的情况,所以这里可以直接定义为底层const类型的指针,因为迭代器内部不修改哈希桶
};
// 哈希桶
// 这里的key是唯一的
template <class K, class T, class KeyOfValue, class HF = HSFunc<K>>
// KeyOfValue用于不同类型的元素,返回key
// HF用于不同类型的key,返回整型
class HashBucket
{
template <class K, class T, class Ptr, class Ref, class KeyOfValue, class HF>
friend struct HBIterator;
public:
typedef HashBucketNode<T> Node;
typedef Node* PNode;
typedef HashBucket<K, T, KeyOfValue, HF> Self;
typedef HBIterator<K, T, T*, T&, KeyOfValue, HF> iterator;
typedef HBIterator<K, T, const T*, const T&, KeyOfValue, HF> const_iterator;
public:
HashBucket(size_t capacity = 5)
: _size(0)
{
_table.resize(capacity, nullptr);
}
~HashBucket()
{
Clear();
}
iterator begin()
{
for (size_t i = 0; i < _table.size(); ++i) // 遍历数组,找到第一个桶
{
if (_table[i])
{
return iterator(_table[i], this);
}
}
return iterator(nullptr, this); // 很妙,this指针就是所需要的哈希桶对象的指针
}
iterator end()
{
return iterator(nullptr, this);
}
const_iterator begin() const
{
for (size_t i = 0; i < _table.size(); ++i) // 遍历数组,找到第一个桶
{
if (_table[i])
{
return iterator(_table[i], this);
}
}
return const_iterator(nullptr, this); // 很妙,this指针就是所需要的哈希桶对象的指针
}
const_iterator end() const
{
return const_iterator(nullptr, this); //这里的const,修饰的是*this,所以哈希桶对象是const的
//但是,迭代器的构造,是直接将传入的迭代器指针初始化,所以就会出现"const指针初始化普通指针"的问题
}
// 哈希桶中的元素不能重复
pair<iterator, bool> Insert(const T& data)
{
KeyOfValue kot;
auto it = Find(kot(data));
if (it != end())
{
return make_pair(it, false);
}
if (CheckCapacity()) // 需要扩容了
{
size_t newsize = _size * 2;
Self newhsb(newsize);
for (size_t i = 0; i < _size; ++i)
{
PNode cur = _table[i];
while (cur) // 把桶上的结点挂在新位置
{
PNode next = cur->_next;
size_t hashi = newhsb.HashFunc(kot(cur->_data));
cur->_next = newhsb._table[hashi];
newhsb._table[hashi] = cur;
cur = next;
++newhsb._size;
}
_table[i] = nullptr;
}
Swap(newhsb);
}
PNode newnode = new Node(data);
size_t hashi = HashFunc(kot(data));
// 头插
newnode->_next = _table[hashi];
_table[hashi] = newnode;
++_size;
return make_pair(newnode, true);
}
// 删除哈希桶中为data的元素(data不会重复)
iterator Erase(const_iterator del)
{
KeyOfValue kot;
if (del == end()) {
return end();
}
if (del != Find(kot(*del))) // 说明这个迭代器不正确
{
return end();
}
auto cur = const_iterator(del);
++cur;
size_t hashi = HashFunc(kot(*del));
PNode prev = _table[hashi];
if (prev == del._pnode) // 如果删除的是第一个结点
{
_table[hashi] = del._pnode->_next;
}
else
{
while (prev && prev->_next->_data != *del) // 找到上一个结点
{
prev = prev->_next;
}
prev->_next = del._pnode->_next;
}
--_size;
auto it = const_iterator(begin());
int count = 0;
while (it != cur) {
++it;
++count;
}
auto a = iterator(begin());
for (int i = 0; i < count; ++i) {
++a;
}
return a;
}
iterator Find(const K& data) const
{
KeyOfValue kot;
size_t hashi = HashFunc(data);
PNode cur = _table[hashi];
while (cur)
{
if (kot(cur->_data) == data)
{
return iterator(cur);
}
cur = cur->_next;
}
return iterator(nullptr);
}
size_t Size() const
{
return _size;
}
bool Empty() const
{
return 0 == _size;
}
void Print() const
{
for (size_t i = 0; i < _table.size(); ++i)
{
PNode cur = _table[i];
printf("[%d]:", i);
while (cur)
{
PNode next = cur->_next;
cout << cur->_data << " ";
cur = next;
}
cout << endl;
}
cout << endl;
}
void Clear()
{
for (size_t i = 0; i < _table.size(); ++i)
{
PNode cur = _table[i];
while (cur)
{
PNode next = cur->_next;
delete cur;
cur = next;
}
_table[i] = nullptr;
}
}
size_t BucketCount() const
{
return _table.size();
}
void Swap(Self& ht)
{
_table.swap(ht._table);
swap(_size, ht._size);
}
private:
size_t HashFunc(const K& data) const// 将数据转换成hashi
{
HF hf;
return hf(data) % _table.size();
}
bool CheckCapacity() const
{
if (_size == _table.size())
{
return true;
}
else
{
return false;
}
}
private:
vector<PNode> _table;
size_t _size; // 哈希表中有效元素的个数
};
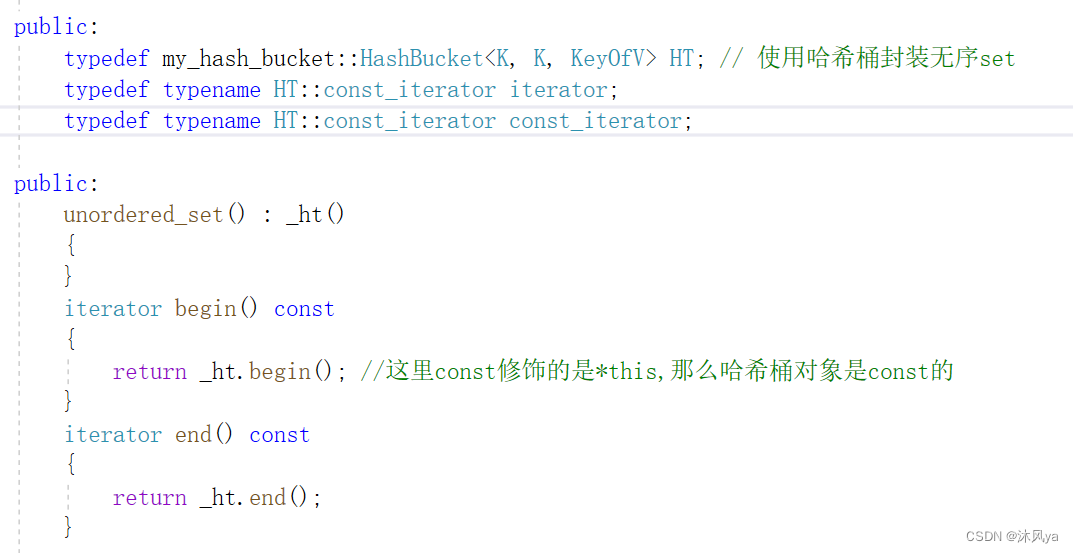
}unordered set
这里的话,只要在哈希桶的迭代器类里,加入普通迭代器构造const迭代器之后,基本没啥问题了
代码
#include "hash.hpp"
namespace my_unordered_set
{
template <class K>
class unordered_set
{
struct KeyOfV
{
const K& operator()(const K& data)
{
return data;
}
};
public:
typedef my_hash_bucket::HashBucket<K, const K, KeyOfV> HT; // 使用哈希桶封装无序set
typedef typename HT::const_iterator iterator;
typedef typename HT::const_iterator const_iterator;
public:
unordered_set() : _ht()
{
}
iterator begin() const
{
return _ht.begin(); //这里const修饰的是*this,那么哈希桶对象是const的
}
iterator end() const
{
return _ht.end();
}
// capacity
size_t size() const
{
return _ht.size();
}
bool empty() const
{
return _ht.empty();
}
// lookup
iterator find(const K& key)
{
return _ht.Find(key);
}
size_t count(const K& key)
{
return _ht.Count(key);
}
// modify
pair<iterator, bool> insert(const K& value)
{
//这里和红黑树一样,都存在普通迭代器转化为const迭代器的问题
//所以,和之前一样,要为迭代器增加一个构造函数
auto it = _ht.Insert(value);
return make_pair(it.first, it.second);
}
iterator erase(iterator position) //接收的是哈希桶的const迭代器
{
auto it = _ht.Erase(position); //返回的是普通迭代器
return it;
}
// bucket
size_t bucket_count()
{
return _ht.BucketCount();
}
size_t bucket_size(const K& key)
{
return _ht.BucketSize(key);
}
private:
HT _ht;
};
}unordered map
思路
operator[ ]
因为[ ]是能实现当key不存在时,自动构造的
所以,需要借助insert
最终返回insert返回值中的value引用就行
erase
erase中存在的const迭代器转为普通的在上面已经处理过了,map中就不需要处理了
代码
#include "hash.hpp"
namespace my_unordered_map
{
template <class K, class V>
class unordered_map
{
// 通过key获取value的操作
struct KeyOfValue
{
const K& operator()(const pair<K, V>& data)
{
return data.first;
}
};
public:
typedef my_hash_bucket::HashBucket<K, pair<const K, V>, KeyOfValue> HT;
typedef typename HT::iterator iterator;
typedef typename HT::const_iterator const_iterator;
public:
unordered_map() : _ht()
{
}
iterator begin() {
return _ht.begin();
}
iterator end() {
return _ht.end();
}
const_iterator begin() const {
return _ht.begin();
}
const_iterator end() const{
return _ht.end();
}
// capacity
size_t size() const {
return _ht.size();
}
bool empty() const {
return _ht.empty();
}
// Acess
V& operator[](const K& key)
{
pair<iterator, bool> ret = _ht.Insert(pair<K, V>(key, V()));
return ret.first->second;
}
const V& operator[](const K& key) const {
pair<iterator, bool> ret = _ht.Insert(pair<K, V>(key, V()));
return (ret.first)->second;
}
// lookup
iterator find(const K& key) {
return _ht.Find(key);
}
size_t count(const K& key) {
return _ht.Count(key);
}
// modify
pair<iterator, bool> insert(const pair<K, V>& valye)
{
return _ht.Insert(valye);
}
iterator erase(const_iterator position)
{
return _ht.Erase(position);
}
// bucket
size_t bucket_count() {
return _ht.BucketCount();
}
size_t bucket_size(const K& key) {
return _ht.BucketSize(key);
}
private:
HT _ht;
};
}