文章目录
- 前言
- 一、Transformer
- 1.Transformer概览
- 2.Self-Attention
- 3.Multi-head Attention
- 4.Position-wise Feed-Forward Networks(位置前馈网络)
- 5.残差连接和层归一化
- 6.Positional Encodings(位置编码)
- 二、Vision Transformer
- 1.Vision Transformer概览
- 2.Embedding层结构
- 🥇 Image Patching(图像分块)
- 🥈Patch Embedding(图像块嵌入)
- 🥉Class token
- 🏅Position Embedding
- 3.Transformer Encoder
- 4.MLP Head
- 5.ViT B/16网络结构
- 三、Hybrid混合模型
- 四、ViT网络实现
- 1.构建ViT网络
- 2.训练和测试模型
- 五、实现图像分类
- 结束语
- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有
帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
前言
Vision Transformer(ViT)是将Transformer模型应用于计算机视觉领域的方法,用于图像分类任务。与传统的卷积神经网络(CNN)不同,ViT通过将图像分成固定大小的图块(Image Patches)并展平成序列,然后将序列输入Transformer模型进行处理。在Transformer中,Self-Attention结构被用来捕捉序列中不同位置的关联信息。通过多层的Transformer编码器,ViT能够从输入图像中学习到更高级的特征表示,最终输出图像的类别预测结果。
一、Transformer
Transformer是2017年Google在Computation and Language上发表的,当时主要是针对自然语言处理领域提出的。RNN模型记忆长度有限且无法并行化,只有计算完 t i t_i ti时刻后的数据才能计算 t i + 1 t_{i+1} ti+1时刻的数据,而Transformer都可以做到。
1.Transformer概览
Transformer模型是一种广泛应用于各个领域的深度学习模型,它是一种基于自注意力机制的编码器-解码器架构。与传统的编码器-解码器模型不同,Transformer模型没有使用传统的卷积神经网络(CNN)和循环神经网络(RNN)方法和模块。
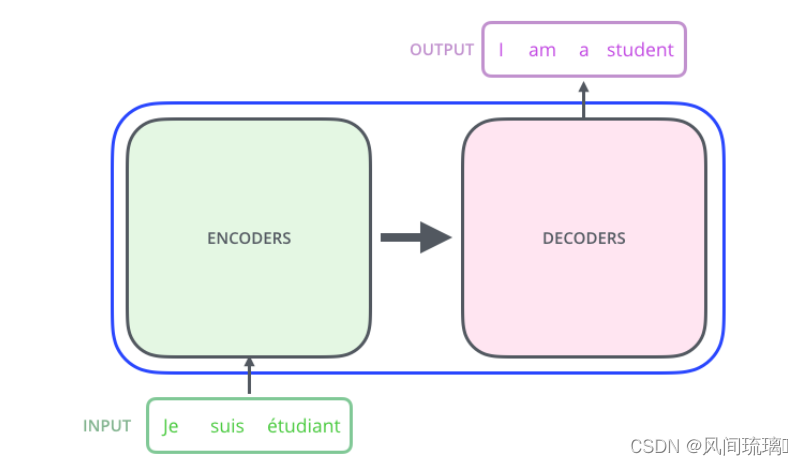
首先,让我们先将 Transformer 模型视为一个黑盒,如图所示。

在机器翻译任务中,将一种语言的一个句子作为输入,然后将其翻译成另一种语言的一个句子作为输出。
Transformer模型的核心思想是通过自注意力机制来捕捉输入序列中不同位置之间的依赖关系。Transformer 本质上是一个Encoder-Decoder 架构。因此中间部分的 Transformer 可以分为两个部分:编码组件和解码组件。
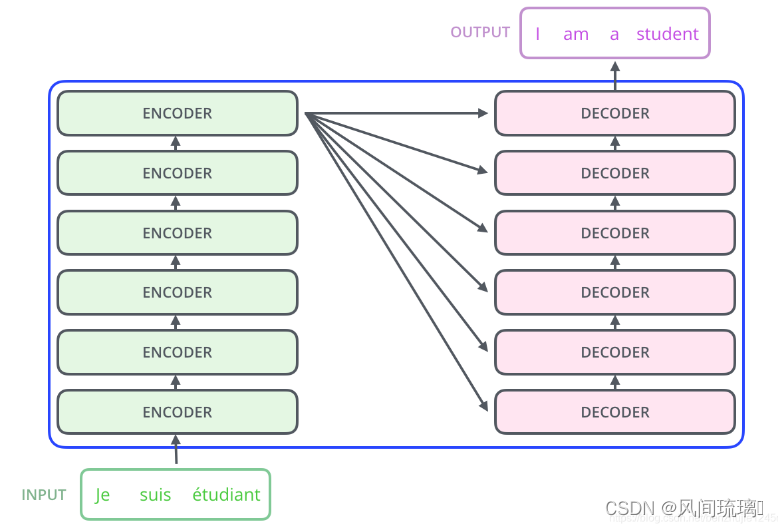
在编码器部分,输入序列经过多个相同的编码器层进行处理,每个编码器层由一个多头自注意力机制和一个前馈神经网络组成。在解码器部分,输出序列的每个位置通过注意力机制对编码器部分的输出进行查找,以便生成正确的输出。
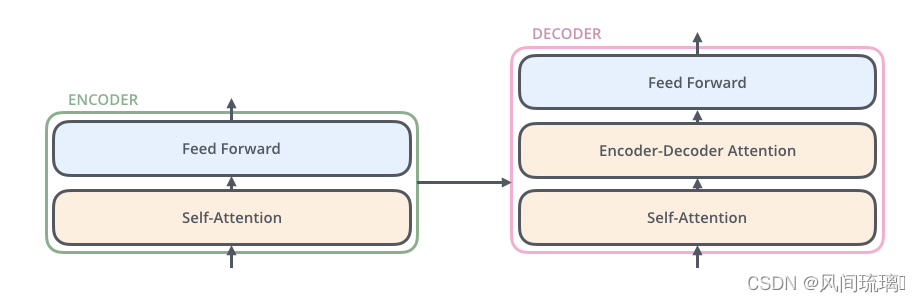
其中,编码组件由多层编码器(Encoder)组成(在论文中作者使用了 6 层编码器,在实际使用过程中可以尝试其他层数)。解码组件也是由相同层数的解码器(Decoder)组成(在论文也使用了 6 层)。如图所示:
每个编码器由两个子层组成:Self-Attention 层(自注意力层)和 Position-wise Feed Forward Network(前馈网络,缩写为 FFN)如下图所示。每个编码器的结构都是相同的,但是它们使用不同的权重参数。
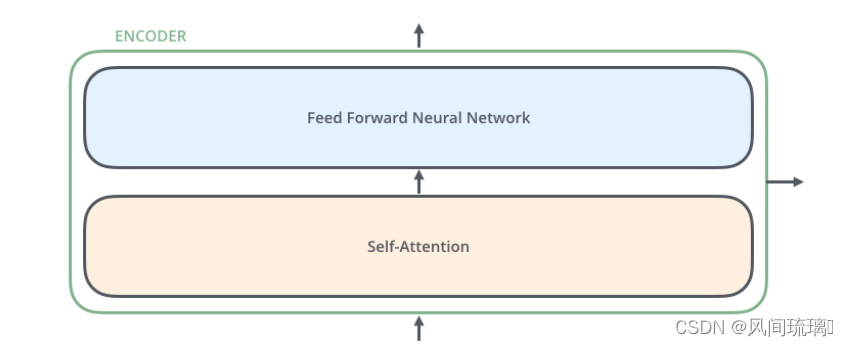
编码器的输入会先流入 Self-Attention 层,它可以让编码器在对特定词进行编码时使用输入句子中的其他词的信息,可以理解为:当我们翻译一个词时,不仅只关注当前的词,而且还会关注其他词的信息。然后,Self-Attention 层的输出会流入前馈网络。
解码器也有编码器中这两层,但是它们之间还有一个注意力层,即 Encoder-Decoder Attention,其用来帮忙解码器关注输入句子的相关部分。
Transformer模型的优点包括并行计算能力强、捕捉长距离依赖关系能力强、易于训练和扩展性好等。这些特性使得Transformer模型在自然语言处理、机器翻译、语音识别等领域取得了显著的成果。
一个典型的 Transformer 结构如下图所示:
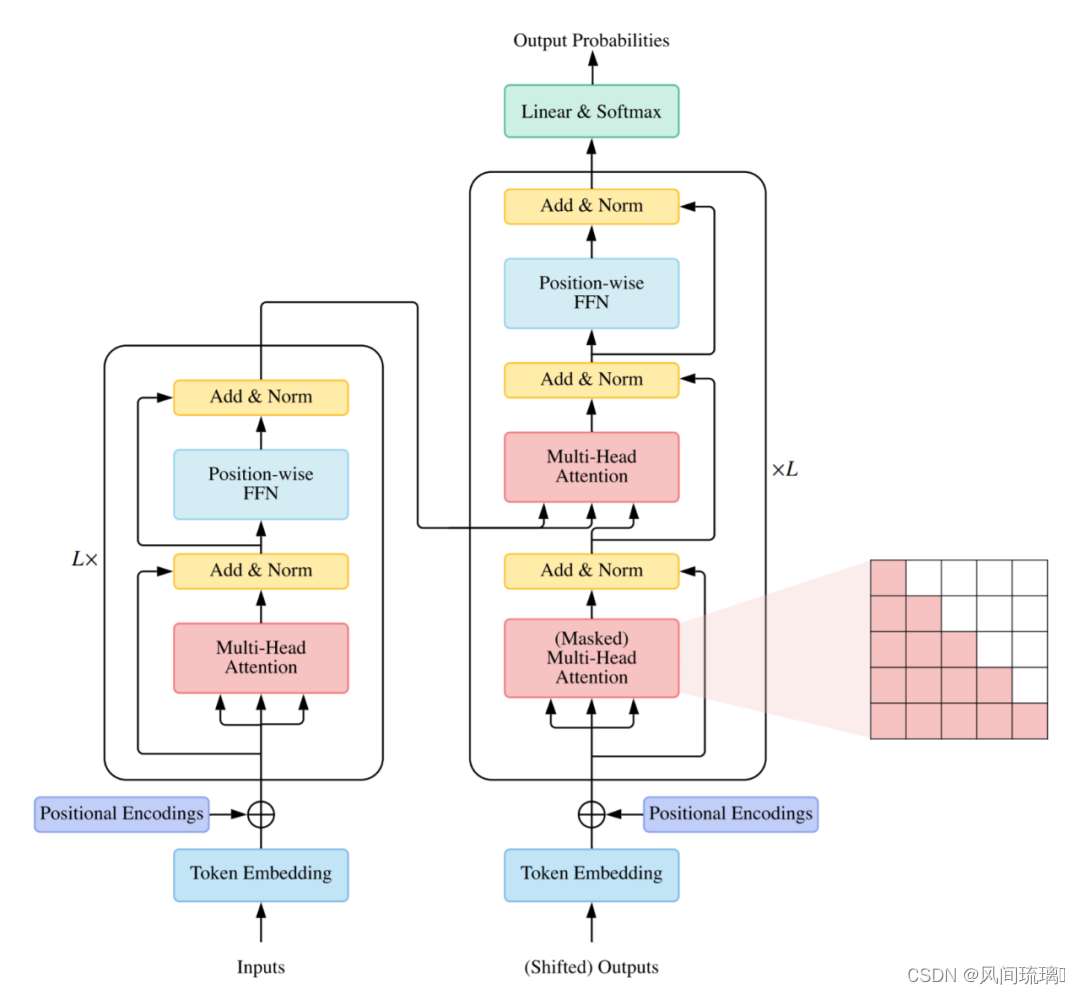
Transformer由一个编码器和一个解码器组成 。每个编码器块主要由一个多头 self-attention 模块和一个位置前馈网络(FFN)组成。为了构建更深的模型,每个模块周围都采用了残差连接,然后是层归一化模块。与编码器块相比,解码器块在多头 self-attention 模块和位置方面 FFN 之间额外插入了 cross-attention 模块。此外,解码器中的 self-attention 模块用于防止每个位置影响后续位置。
2.Self-Attention
在论文中作者提出了Self-Attention的概念,然后在此基础上提出Multi-Head Attention。
首先通过一个例子,来对 Self-Attention 有一个直观的认识。假如,我们要翻译下面这个句子:
The animal didn’t cross the street because it was too tired
这个句子中的 it 指的是什么?是指 animal 还是 street ?对我们来说,这是一个简单的问题,但是算法来说却不那么简单。当模型在处理 it 时,Self-Attention 机制使其能够将 it 和 animal 关联起来。
当模型处理每个词(输入序列中的每个位置)时,Self-Attention 机制使得模型不仅能够关注当前位置的词,而且能够关注句子中其他位置的词,从而可以更好地编码这个词。
如果你熟悉 RNN,想想如何维护隐状态,使 RNN 将已处理的先前词/向量的表示与当前正在处理的词/向量进行合并。Transformer 使用 Self-Attention 机制将其他词的理解融入到当前词中。

当编码器对单词”it“进行编码时,有一部分注意力集中在”The animal“上,并将它们的部分信息融入到”it“的编码中。
Self-Attention其基本结构如下图所示:
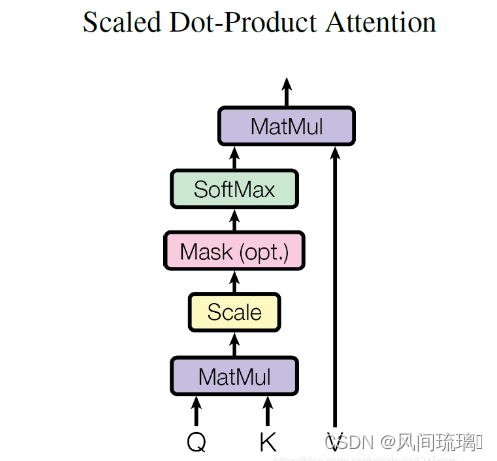
对于 Self Attention 来讲,Q(Query),K(Key)和 V(Value)三个矩阵均来自同一输入,并按照以下步骤计算:
⋆
\star
⋆ 首先计算 Q 和 K 之间的点积,为了防止其结果过大,会除以
d
k
\sqrt{d_{k}}
dk ,其中
d
k
d_{k}
dk为 Key 向量的维度。
⋆ \star ⋆ 然后利用 Softmax 操作将其结果归一化为概率分布,再乘以矩阵 V 就得到权重求和的表示。
整个计算过程表示如下:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q,K,V) = softmax(\cfrac{QK^T}{\sqrt{d_k}})V
Attention(Q,K,V)=softmax(dkQKT)V
如上图所示,QKV矩阵是在自注意力机制(Self-Attention Mechanism)中用于计算注意力权重的三个矩阵。这三个矩阵通常是通过对输入序列进行线性变换得到的。它们分别是:
⋆
\star
⋆ Q矩阵(Query Matrix): Q矩阵用于生成查询向量,每个查询向量代表一个小块(Patch)。在注意力机制中的查询,即用寻找与当前小块相关的信息。
⋆
\star
⋆ K矩阵(Key Matrix): K矩阵用于生成键向量,每个键向量代表一个小块(Patch)。在注意力机制中的键,即用于表示当前小块与其他小块之间的关系。
⋆
\star
⋆ V矩阵(Value Matrix): V矩阵用于生成值向量,每个值向量代表一个小块(Patch。在注意力机制中的值,即用于表示当前小块的特征信息。
在自注意力机制中,输入序列首先通过三个不同的线性变换,分别得到查询矩阵Q、键矩阵K和值矩阵V。这三个矩阵将用于计算注意力权重,从而对输入序列进行加权求和,得到最终的表示。其中,Q和K的点乘得到的矩阵就是注意力权重矩阵A。假设如果只有V矩阵,不经过Q和K的过程,那么这就算是普通的网络,没有加入注意力机制。
举例:假设输入的序列长度为2,输入就两个节点
x
1
,
x
2
x_1,x_2
x1,x2,然后通过Input Embedding,即图中的f(x)将输入映射到
a
1
,
a
2
a_1,a_2
a1,a2。紧接着分别将
a
1
,
a
2
a_1,a_2
a1,a2分别通过三个变换矩阵$W_q,W_k,W_v$(这三个参数是可训练的,是共享的)得到对应的
q
i
,
k
i
,
v
i
q^i,k^i,v^i
qi,ki,vi(这里在源码中是直接使用全连接层实现的,这里为了方便理解,忽略偏执)。
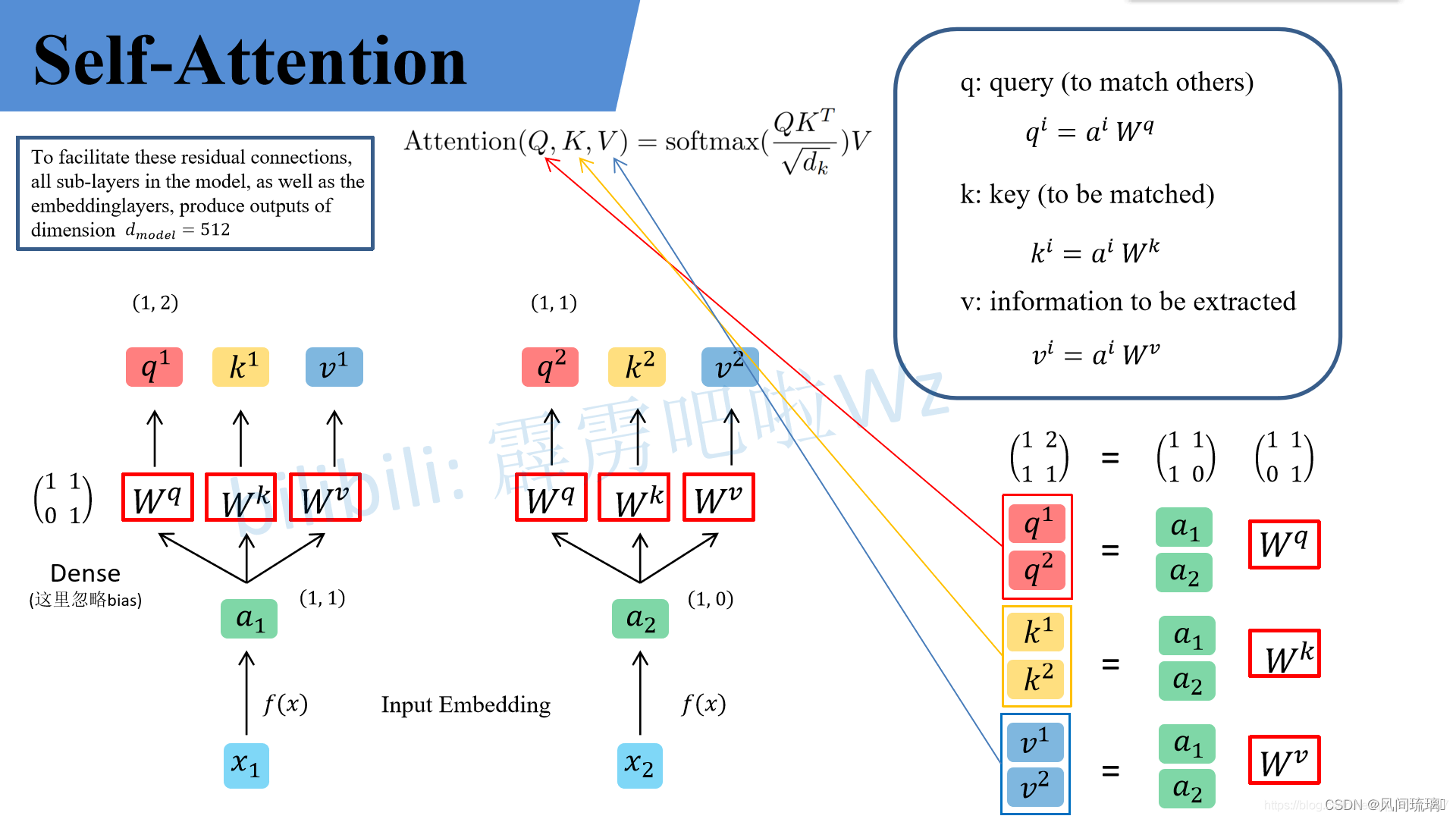
⋆
\star
⋆ q代表query,后续会去和每一个k进行匹配
⋆
\star
⋆ k代表key,后续会被每个q匹配
⋆
\star
⋆ v代表从a中提取得到的信息,即输入的数据
⋆
\star
⋆ q和k匹配的过程可以理解成计算两者的相关性,相关性越大对应v的权重也就越大,q和k一系列运算都是为了计算v的权重。
假设:
a
1
=
(
1
,
1
)
,
a
2
=
(
1
,
0
)
,
W
q
=
(
1
1
0
1
)
a_1=(1,1),a_2=(1,0), W^q = \begin{pmatrix} 1 & 1 \\ 0 & 1 \end{pmatrix}\\
a1=(1,1),a2=(1,0),Wq=(1011)
则(Transformer可以并行化):
(
q
1
q
2
)
\qquad \qquad \qquad \qquad \qquad \begin{pmatrix} q^1 \\ q^2 \end{pmatrix}
(q1q2) =
(
1
1
1
0
)
\begin{pmatrix} 1&1 \\ 1&0 \end{pmatrix}
(1110)
(
1
1
0
1
)
\begin{pmatrix} 1&1 \\ 0&1 \end{pmatrix}
(1011) =
(
1
2
1
1
)
\begin{pmatrix} 1&2 \\ 1&1 \end{pmatrix}
(1121)
(
q
1
q
2
)
\begin{pmatrix} q^1 \\ q^2 \end{pmatrix}
(q1q2)即为论文公式中的Q,
(
k
1
k
2
)
\begin{pmatrix} k^1 \\ k^2 \end{pmatrix}
(k1k2)即为论文公式中的K,
(
v
1
v
2
)
\begin{pmatrix} v^1 \\ v^2 \end{pmatrix}
(v1v2)即为论文公式中的V。然后用
q
1
q_1
q1和每个k进行点乘操作,并除以
d
\sqrt{d}
d就可以得到对应的
α
\alpha
α, 其中d代表向量
k
i
k^i
ki的长度(k=2),除以
d
\sqrt{d}
d的原因是因为进行点乘后的数值很大,会导致通过softmax后梯度变得很小,所以除以
d
\sqrt{d}
d进行缩放。比如
α
1
,
1
\alpha_{1,1}
α1,1的计算:
α
1
,
1
=
q
1
⋅
k
1
d
=
1
⋅
1
+
2
⋅
0
2
=
0.71
\alpha_{1,1}=\cfrac{q^1·k^1}{\sqrt{d}} = \cfrac{1·1+2·0}{\sqrt{2}} = 0.71
α1,1=dq1⋅k1=21⋅1+2⋅0=0.71
使用矩阵计算:
(
α
1
,
1
α
1
,
2
α
2
,
1
α
2
,
2
)
=
(
q
1
q
2
)
(
k
1
k
2
)
T
d
\begin{pmatrix} \alpha_{1,1} & \alpha_{1,2} \\ \alpha_{2,1} & \alpha_{2,2} \end{pmatrix} = \cfrac{\begin{pmatrix} q^1 \\ q^2 \end{pmatrix} \begin{pmatrix} k^1 \\ k^2 \end{pmatrix}^{T} }{ \sqrt{d}}
(α1,1α2,1α1,2α2,2)=d(q1q2)(k1k2)T
完成步骤1,接着对每一行即(
α
1
,
1
,
α
1
,
2
\alpha_{1,1} ,\alpha_{1,2}
α1,1,α1,2)(
α
2
,
1
,
α
2
,
2
\alpha_{2,1} ,\alpha_{2,2}
α2,1,α2,2)分别进行softmax处理得到(
α
^
1
,
1
,
α
^
1
,
2
\widehat{\alpha}_{1,1} ,\widehat{\alpha}_{1,2}
α
1,1,α
1,2)(
α
^
2
,
1
,
α
^
2
,
2
\widehat{\alpha}_{2,1} ,\widehat{\alpha}_{2,2}
α
2,1,α
2,2), 其中$\widehat{\alpha}$相当于计算得到针对每个v的权重。至此,完成Attention(Q,K,V)公式的
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
softmax(\cfrac{QK^T}{\sqrt{d_k}})
softmax(dkQKT)部分计算。
具体计算流程如下图所示:
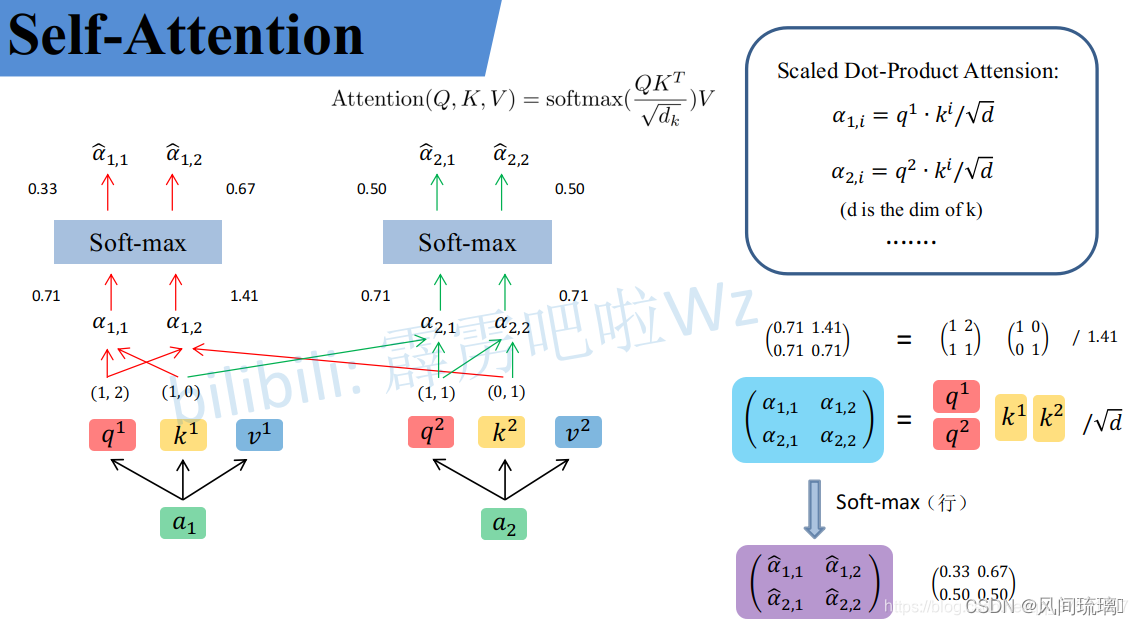
上面已经计算得到
α
\alpha
α,即针对每个v的权重,接着进行加权得到最终结果:
(
b
1
b
2
)
\qquad \qquad \qquad \qquad \qquad \begin{pmatrix} b^1 \\ b^2 \end{pmatrix}
(b1b2) =
(
α
^
1
,
1
α
^
1
,
2
α
^
2
,
1
α
^
2
,
2
)
\begin{pmatrix} \widehat{\alpha}_{1,1} &\widehat{\alpha}_{1,2} \\ \widehat{\alpha}_{2,1} &\widehat{\alpha}_{2,2} \end{pmatrix}
(α
1,1α
2,1α
1,2α
2,2)
(
v
1
v
2
)
\begin{pmatrix} v^1 \\ v^2 \end{pmatrix}
(v1v2)

至此,Self-Attention的公式计算完成。
3.Multi-head Attention
在 Transformer 论文中,通过添加一种多头注意力机制,使用多头注意力机制能够联合来自不同head部分学习到的信息, 进一步完善了自注意力层。具体做法:首先,通过h个不同的线性变换对 Query、Key 和 Value 进行映射;然后,将不同的 Attention 拼接起来;最后,再进行一次线性变换。基本结构如图所示:
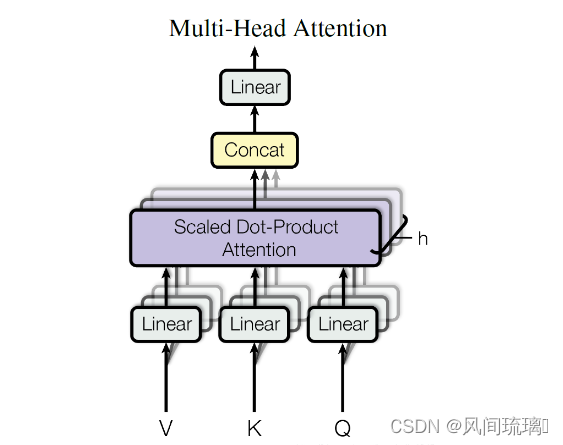
每一组注意力用于将输入映射到不同的子表示空间,这使得模型可以在不同子表示空间中关注不同的位置。整个计算过程可表示为:
M
u
l
t
i
H
e
a
d
(
Q
,
K
,
V
)
=
C
o
n
c
a
t
(
h
e
a
d
1
1
,
.
.
.
,
h
e
a
d
h
)
W
O
MultiHead(Q,K,V) = Concat(head1_1,...,head_h)W^O
MultiHead(Q,K,V)=Concat(head11,...,headh)WO
w
h
e
r
e
h
e
a
d
i
=
A
t
t
e
n
t
i
o
n
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
where \qquad head_i = Attention(QW_i^Q,KW_i^K,VW_i^V)
whereheadi=Attention(QWiQ,KWiK,VWiV) 其中
W
i
Q
∈
R
d
m
o
d
e
l
×
d
k
W_i^Q \in \Bbb{R}^{d_{model} \times d_k}
WiQ∈Rdmodel×dk,
W
i
K
∈
R
d
m
o
d
e
l
×
d
k
W_i^K \in \Bbb{R}^{d_{model} \times d_k}
WiK∈Rdmodel×dk,
W
i
V
∈
R
d
m
o
d
e
l
×
d
v
W_i^V \in \Bbb{R}^{d_{model} \times d_v}
WiV∈Rdmodel×dv和
W
i
O
∈
R
h
d
v
×
d
m
o
d
e
l
W_i^O \in \Bbb{R}^{hd_v \times d_{model}}
WiO∈Rhdv×dmodel。
在论文中,指定h=8,即使用8个注意力头。
d
k
=
d
v
=
d
m
o
d
e
l
/
h
=
64
d_k = d_v = d_{model} / h = 64
dk=dv=dmodel/h=64
注意:
⋆
\star
⋆
d
m
o
d
e
l
d_{model}
dmodel表示Multi-Head Self-Attention输入输出的token维度(向量长度)
⋆ \star ⋆ d k , d v d_k, d_v dk,dv 表示Multi-Head Self-Attention中每个head的key(K)以及query(Q)的维度
举例:首先和Self-Attention模块一样将
a
i
a_i
ai分别通过
W
q
,
W
k
,
W
v
W^q,W^k,W^v
Wq,Wk,Wv得到对应的
q
i
,
k
i
,
v
i
q^i,k^i,v^i
qi,ki,vi,然后根据使用的head的数目h进一步把得到的
q
i
,
k
i
,
v
i
q^i,k^i,v^i
qi,ki,vi均分成h份。
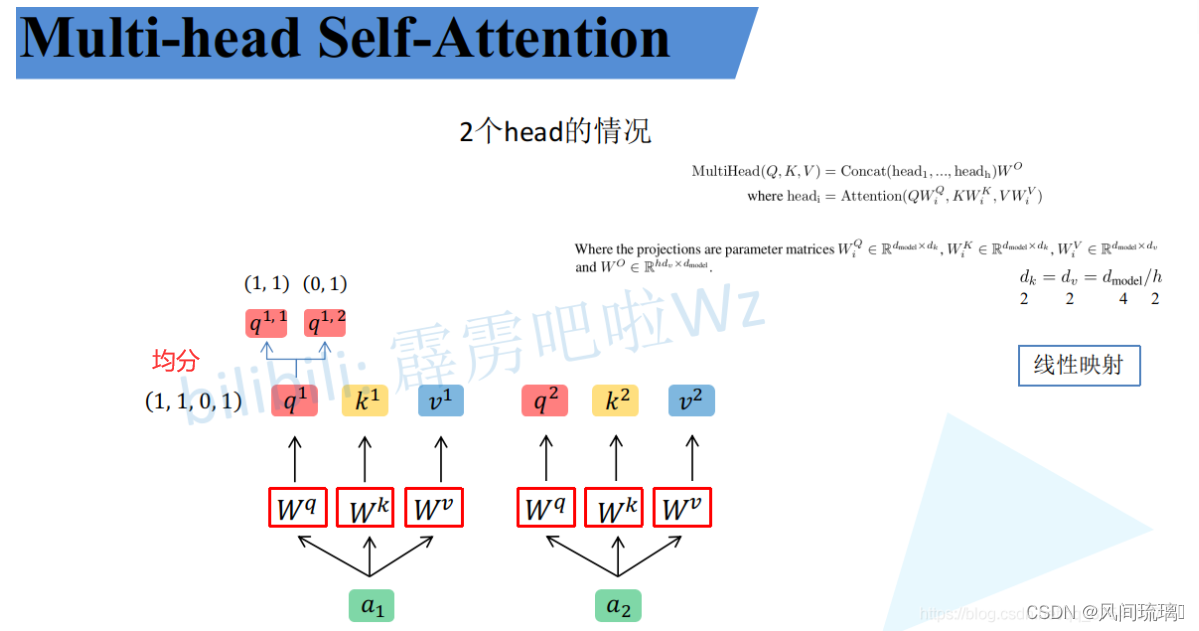
上图假设h=2,将得到的
q
1
=
1
,
1
,
0
,
1
q^1={1,1,0,1}
q1=1,1,0,1分为
q
1
,
1
=
(
1
,
1
)
,
q
1
,
2
=
(
0
,
1
)
q^{1,1} = (1,1),q^{1,2} = (0,1)
q1,1=(1,1),q1,2=(0,1),
q
1
,
1
q^{1,1}
q1,1属于head1,
q
1
,
2
q^{1,2}
q1,2属于head2。
但是在论文中
W
i
Q
,
W
i
K
,
W
i
V
W_i^Q,W_i^K, W_i^V
WiQ,WiK,WiV映射$得到每一个head的
Q
i
,
K
i
,
V
i
Q_i,K_i, V_i
Qi,Ki,Vi :
h
e
a
d
i
=
A
t
t
e
n
t
i
o
n
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
head_i = Attention(QW_i^Q,KW_i^K,VW_i^V)
headi=Attention(QWiQ,KWiK,VWiV)
其实可以进行简单的均分,也可以通过
W
i
Q
,
W
i
K
,
W
i
V
W_i^Q,W_i^K, W_i^V
WiQ,WiK,WiV设置成对应值来实现均分,如下图:
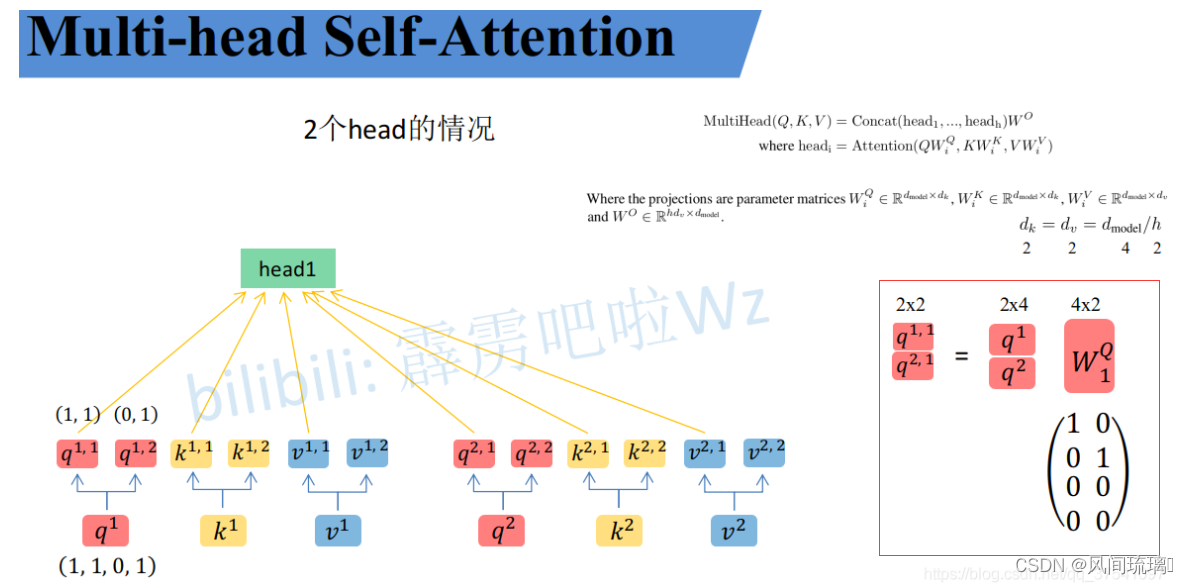
通过上述方法就能得到每个
h
e
a
d
i
head_i
headi对应的
W
i
Q
,
W
i
K
,
W
i
V
W_i^Q,W_i^K, W_i^V
WiQ,WiK,WiV。接下来针对每个head使用和Self-Attention中相同的方法即可得到对应的结果。
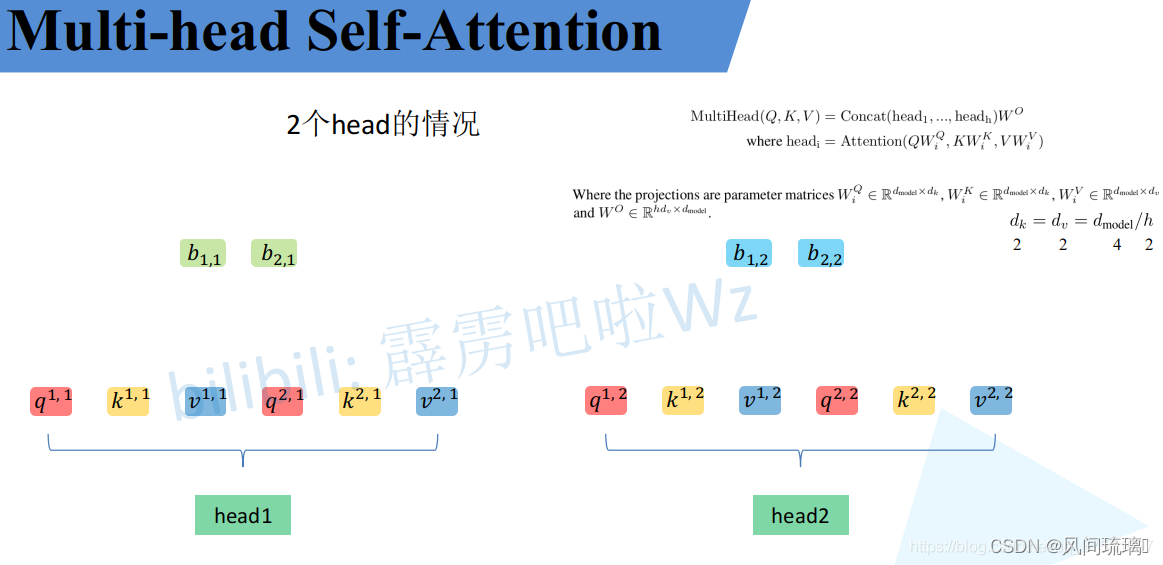
接着将每个head得到的结果进行concat拼接,比如上图中
b
1
,
1
b_{1,1}
b1,1和
b
2
,
1
b_{2,1}
b2,1拼接起来。如下图所示:
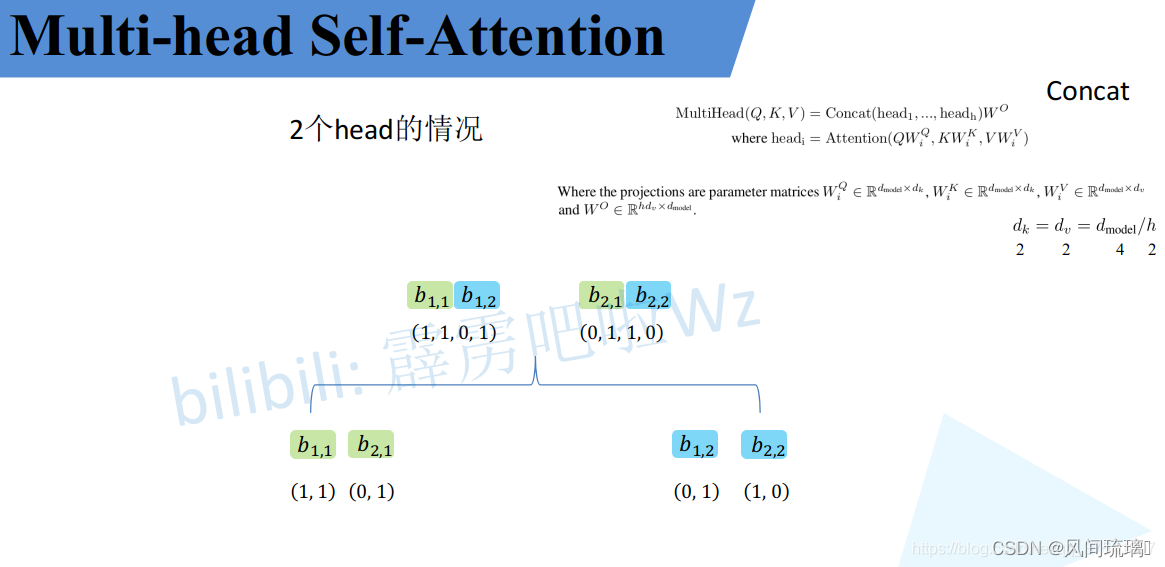
接着将拼接后的结果通过
W
O
W^O
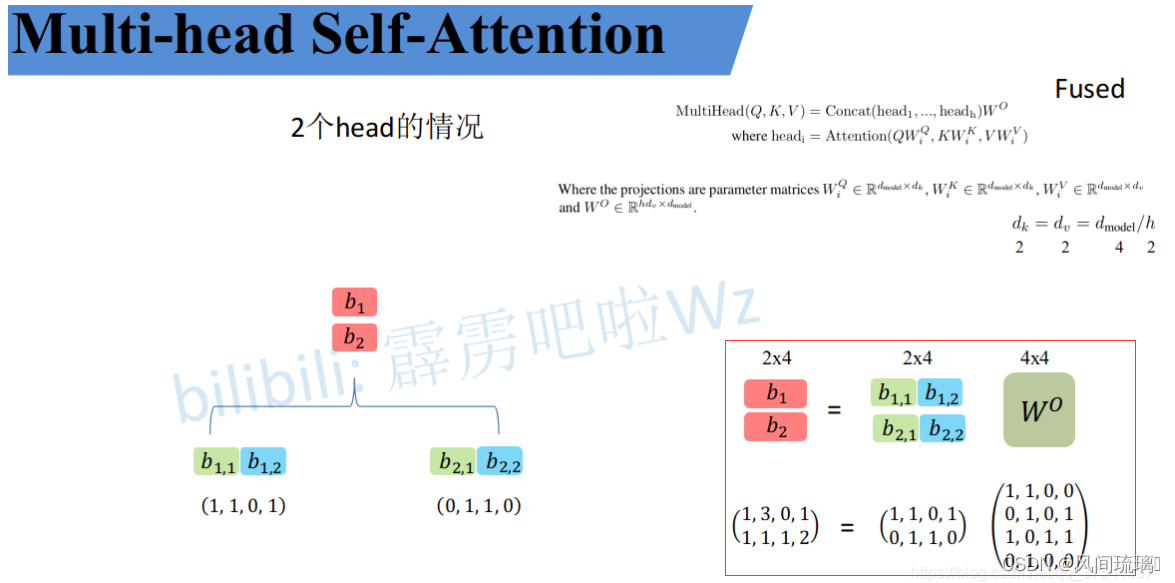
WO(可学习的参数)进行融合,如下图所示,融合后得到最终的结果
b
1
,
b
2
b_1,b_2
b1,b2。
至此Multi-Head Attention公式计算完毕。
4.Position-wise Feed-Forward Networks(位置前馈网络)
位置前馈网络就是一个全连接前馈网络,每个位置的词都单独经过这个完全相同的前馈神经网络。其由两个线性变换组成,即两个全连接层组成,第一个全连接层的激活函数为 ReLU 激活函数。可以表示为:
F
F
N
(
x
)
=
m
a
x
(
0
,
x
W
1
+
b
1
)
W
2
+
b
2
FFN(x)=max(0, xW_1+b_1)W_2 + b_2
FFN(x)=max(0,xW1+b1)W2+b2
在每个编码器和解码器中,虽然这个全连接前馈网络结构相同,但是不共享参数。整个前馈网络的输入和输出维度都是
d
m
o
d
e
l
d_{model}
dmodel=512,第一个全连接层的输出和第二个全连接层的输入维度为
d
f
f
d_{ff}
dff=2048。
5.残差连接和层归一化
编码器结构中有一个需要注意的细节:每个编码器的每个子层(Self-Attention 层和 FFN 层)都有一个残差连接,再执行一个层标准化操作,整个计算过程可以表示为:
s
u
b
l
a
y
e
r
o
u
t
p
u
t
=
L
a
y
e
r
N
o
r
m
(
x
+
S
u
b
L
a
y
e
r
(
x
)
)
sub_layer_output = LayerNorm(x + SubLayer(x))
sublayeroutput=LayerNorm(x+SubLayer(x))
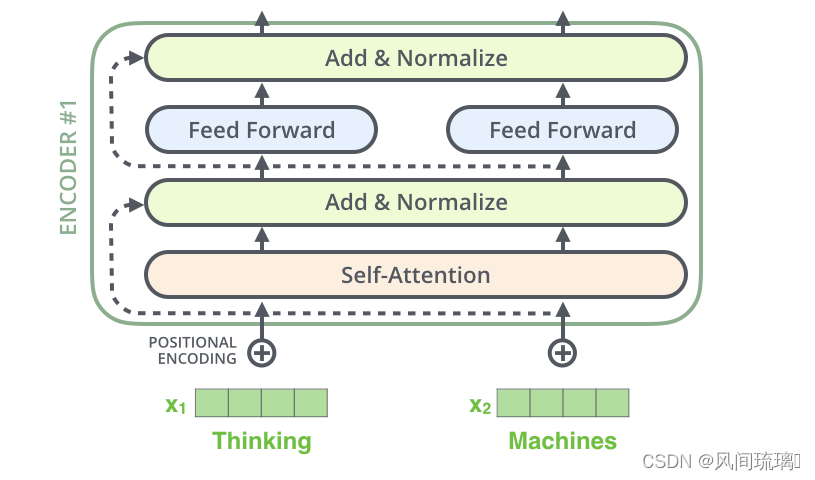
将向量和自注意力层的层标准化操作可视化,如下图所示:
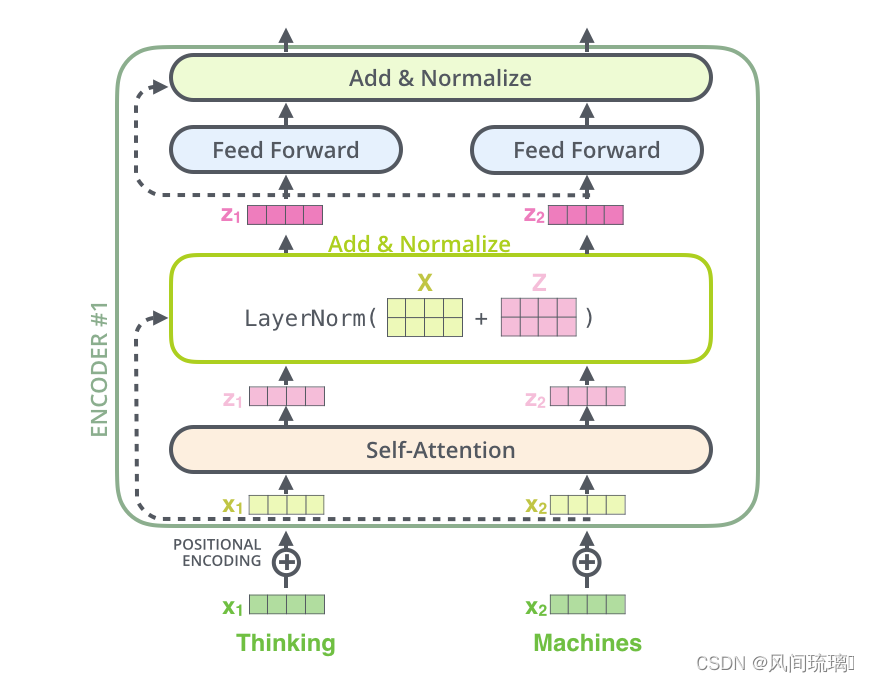
上面的操作也适用于解码器的子层。假设一个 Transformer 是由 2 层编码器和 2 层解码器组成,其如下图所示
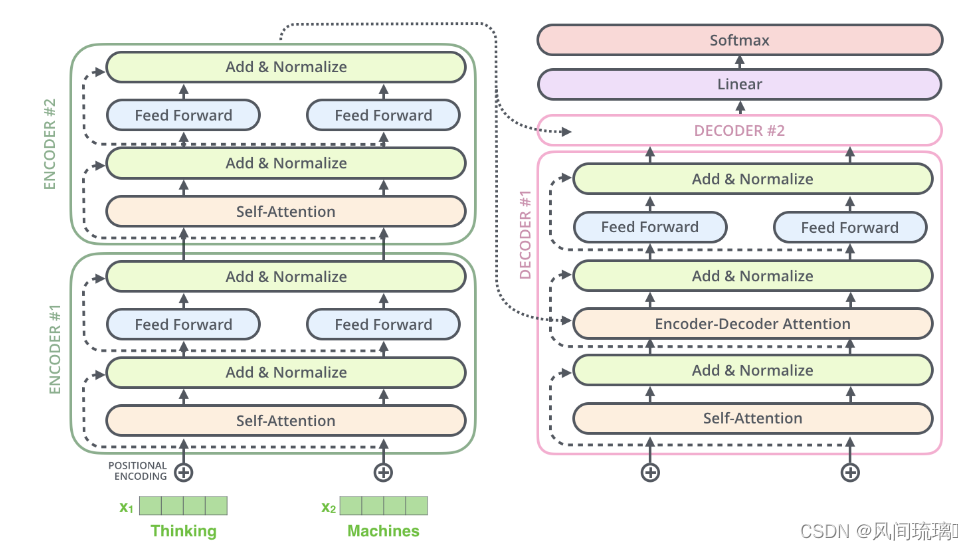
为了方便进行残差连接,编码器和解码器中的所有子层和嵌入层的输出维度需要保持一致,在 Transformer 论文中
d
m
o
d
e
l
d_{model}
dmodel = 512。
6.Positional Encodings(位置编码)
到目前为止,我们所描述的模型中缺少一个东西:表示序列中词顺序的方法。为了解决这个问题,Transformer 模型为每个输入的词嵌入向量添加一个向量。这些向量遵循模型学习的特定模式,有助于模型确定每个词的位置,或序列中不同词之间的距离。
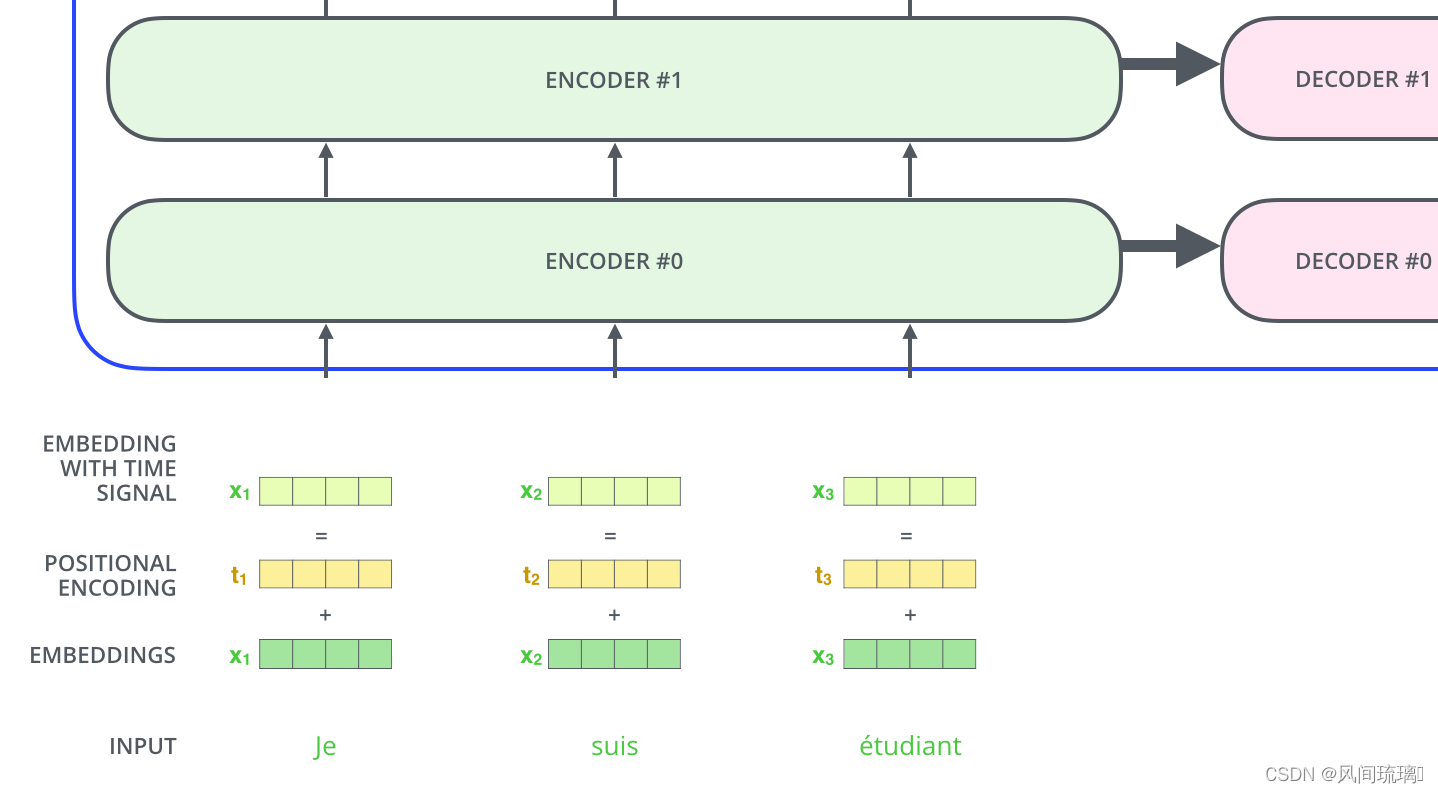
从上图可知位置编码t是直接加在输入的x上的,然后再进行编码的。
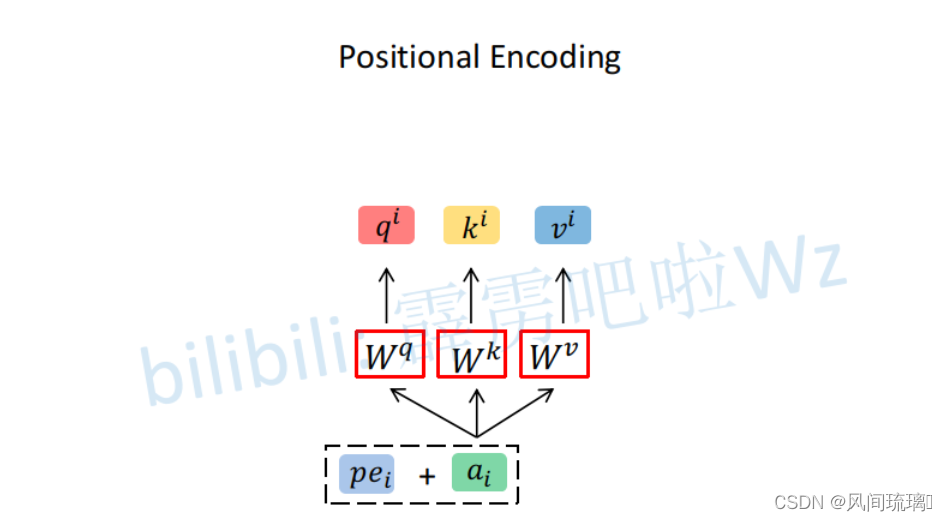
位置编码是直接加在输入的a={
a
1
,
.
.
.
,
a
n
a_1,...,a_n
a1,...,an}上的,所以pe={
p
e
1
,
.
.
.
,
p
e
n
pe_1,...,pe_n
pe1,...,pen}和a={
a
1
,
.
.
.
,
a
n
a_1,...,a_n
a1,...,an}有相同的维度大小。
关于位置编码在原论文中有提出两种方案,一种是原论文中使用的固定编码,即论文中给出的sine and cosine functions方法,按照该方法可计算出位置编码;另一种是可训练的位置编码。
transformer就介绍到这里,有了上面的大概了解,下面进入今天的主题Vision Transformer。
transformer参考文章:transformer
二、Vision Transformer
1.Vision Transformer概览
ViT是2020年Google团队提出的将Transformer应用在图像分类的模型,其模型简单且效果好,可扩展性强(scalable,模型越大效果越好),成为了transformer在CV领域应用的里程碑著作,也引爆了后续相关研究。
ViT原论文中最核心的结论是:当拥有足够多的数据进行预训练的时候,ViT的表现就会超过CNN,突破transformer缺少归纳偏置的限制,可以在下游任务中获得较好的迁移效果。但是当训练数据集不够大的时候,ViT的表现通常比同等大小的ResNets要差一些,因为Transformer和CNN相比缺少归纳偏置(inductive bias),即一种先验知识,提前做好的假设。
CNN具有两种归纳偏置,一种是局部性(locality/two-dimensional neighborhood structure),即图片上相邻的区域具有相似的特征;一种是平移不变形(translation equivariance),
f
(
g
(
x
)
)
=
g
(
f
(
x
)
)
f(g(x)) = g(f(x))
f(g(x))=g(f(x))其中g代表卷积操作,f代表平移操作。当CNN具有以上两种归纳偏置,就有了很多先验信息,需要相对少的数据就可以学习一个比较好的模型。
Vision Transformer(ViT)的模型框架
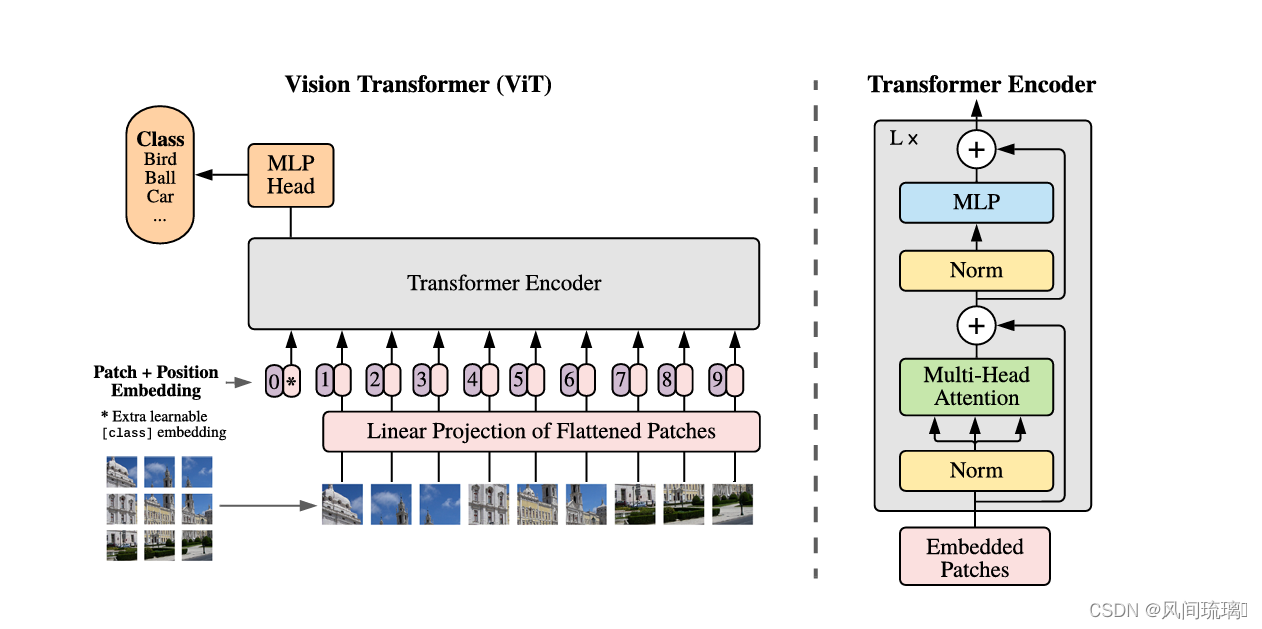
模型由三个模块组成:
⋆
\star
⋆ Linear Projection of Flattened Patches(Embedding层)
⋆
\star
⋆ Transformer Encoder(图右侧)
⋆
\star
⋆ MLP Head(最终用于分类的层结构)
按照上面的流程图,一个ViT block可以分为以下几个步骤:
(1) Patch Embedding:假设输入图片大小为224x224,将图片分为固定大小的patch,然后将每个 Patch 拉成一维向量,patch大小为16x16,则每张图像会生成224x224/16x16=196个patch,即输入序列长度为196,每个patch维度16x16x3=768。
考虑到一维向量维度较大,需要将拉伸后的 Patch 序列经过线性投影 (nn.Linear) 压缩维度,同时也可以实现特征变换功能,这两个步骤可以称为图片 Token 化过程 (Patch Embedding)。
线性投射层的维度为768xN (N=768),因此输入通过线性投射层之后的维度依然为196x768,即一共有196个token,每个token的维度是768。为了方便后续分类,作者还额外引入一个可学习的 Class Token,该 Token 插入到图片 token 化后所得序列的开始位置。现在,已经通过Patch Embedding将一个视觉问题转化为了一个seq2seq问题。
(2) Positional Encoding(standard learnable 1D position embeddings):ViT同样需要加入位置编码,位置编码可以理解为一张表,表一共有N行,N的大小和输入序列长度相同,每一行代表一个向量,向量的维度和输入序列embedding的维度相同(768)。注意位置编码的操作是sum,而不是concat。加入位置编码信息之后,维度依然是197x768。
(3) LN/multi-head attention/LN:LN输出维度依然是197x768。多头自注意力时,先将输入映射到q,k,v,如果只有一个头,qkv的维度都是197x768,如果有12个头(768/12=64),则qkv的维度是197x64,一共有12组qkv,最后再将12组qkv的输出拼接起来,输出维度是197x768,然后在过一层LN,维度依然是197x768
(4) MLP:将维度放大再缩小回去,197x768放大为197x3072,再缩小变为197x768。一个block之后维度依然和输入相同,都是197x768,因此可以堆叠多个block。将最后一个 Transformer 编码器输出序列的第 0 位置( Class Token 位置对应输出)提取出来,后面接 MLP 分类后,然后正常分类即可。
2.Embedding层结构
🥇 Image Patching(图像分块)
对于标准的Transformer模块,要求输入的是token(向量)序列,即二维矩阵[num_token, token_dim],如下图,token0-9对应的都是向量,以ViT-B/16为例,每个token向量长度为768。
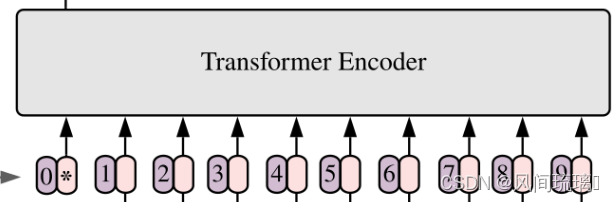
对于图像数据,其数据格式为[H, W, C],不满足Transformer输入要求。所以需要先通过Image Patching来对图像数据处理,将图像划分为固定大小的patch。如下图所示,首先将一张图片按给定大小分成一堆Patches。图像分块(Image Patches)过程如下图所示:

以ViT-B/16为例,将输入图片(224x224)按照16x16大小的Patch进行划分,划分后会得到
(
224
/
16
)
2
(224/16)^2
(224/16)2=196个Patches。
将图像分成小块(即Patch)可以带来的优势:
⋆
\star
⋆ 特征提取: 在一些任务中,特定区域的信息比整个图像更有用。通过对每个Patch进行特征提取,可以获得更细粒度的信息,有助于更好地理解图像内容。
⋆
\star
⋆ 处理大尺寸图像: 对于非常大的图像,可能会遇到计算和存储方面的限制。将图像分成小的Patch可以帮助降低计算复杂度,并且可以更轻松地处理这些小尺寸的块。
⋆
\star
⋆ 自适应性: 在一些自适应处理的算法中,对于不同的图像区域采取不同的策略是很常见的。将图像划分成Patch可以使算法在局部区域上更加灵活和自适应。
🥈Patch Embedding(图像块嵌入)
Patch Embedding与图像处理和卷积神经网络(CNN)相关。CNN对图像数据进行处理是在像素级上的处理,通过卷积核在图像上滑动进行特征提取。而Patch Embedding,则引入了更高级的特征表示方式。它先将一张图片按给定大小分成一堆Patches,然后将每个小块转换为低维的向量表示。这种向量表示可以用作后续任务的输入。
Patch Embedding的目的在于降低计算复杂度并提高特征提取的效率。在卷积神经网络中,相邻的像素通常会有大量重叠,而Patch Embedding将图像分成块后,可以减少冗余计算,同时保留了重要的特征信息。
Patch Embedding过程如下图所示:

通过线性映射将每个Patch映射到一维向量中,以ViT-B/16为例,每个Patche数据shape为[16, 16, 3]通过映射得到一个长度为768的向量(后面都直接称为token)。[16, 16, 3] -> [768]
在代码实现中,直接通过一个卷积层来实现。 以ViT-B/16为例,使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768],此时正好变成了一个二维矩阵,符合Transformer输入数据要求。
🥉Class token
前面说过,为了方便后续分类,作者还额外引入一个可学习的 Class Token,是一个可训练的参数,数据格式和其他token一样都是一个向量,用于表示整个图像的类别信息,以辅助后续的图像分类或生成任务,该 Class Token 插入到图片 token 化后(Patch Embedding操作后)所得序列的开始位置。
在Transformer模型中,Patch Embedding操作后,Class foken通常被添加在输入序列的开头,并且在训练过程中会经过特定的注意力机制,以使得模型能够对类别信息进行编码和利用。

以ViT-B/16为例,假设Patch Embedding后得到196个向量,添加Class Token(一个长度为768的向量)后输入序列为:[Class Token,v1,v2,…,v196]。整个输入序列的第一个向量就是Class Token,它包含了整个图像的类别信息,网络模型在训练过程中可以利用这个类别信息,进行图像分类任务。
🏅Position Embedding
在Vision Transformer 模型中,PE表示位置编码(Positonal Encoding),用于将图像中的每个Patch Embedding 向量与其位置信息相关联,将整个图像的全局位置信息引入到Transformer模型中。
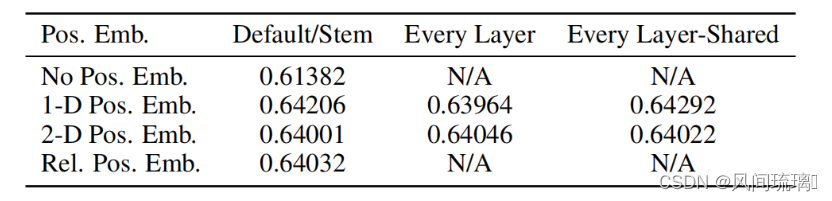
Position Embedding和Transformer中讲到的Positional Encoding一样,这里的Position Embedding采用的是一个可训练的参数(1D Pos. Emb.),直接叠加在tokens上的(add),所以shape要求相同。
以ViT-B/16为例,输入序列添加Class Token后shape是[197, 768],则Position Embedding的shape也要是[197, 768]。
Position Embedding作用:为了给Transformer模型提供输入序列中的位置信息。 在Transformer模型没有像卷积神经网络那样显式地保留位置信息。在自然语言处理任务中,输入是一个词语序列,为了保留词语的位置信息,通常会添加位置编码。同理在ViT中,输入是图像的Patch Embedding 序列,为了保留Patch的位置信息,也需要添加位置编码。
对于Position Embedding作者做了一系列对比试验,在源码中默认使用的是1D Pos. Emb.,对比不使用Position Embedding准确率提升了0.3。
3.Transformer Encoder
Transformer Encoder是重复堆叠Encoder Block L次,Encoder Block如下图所示,
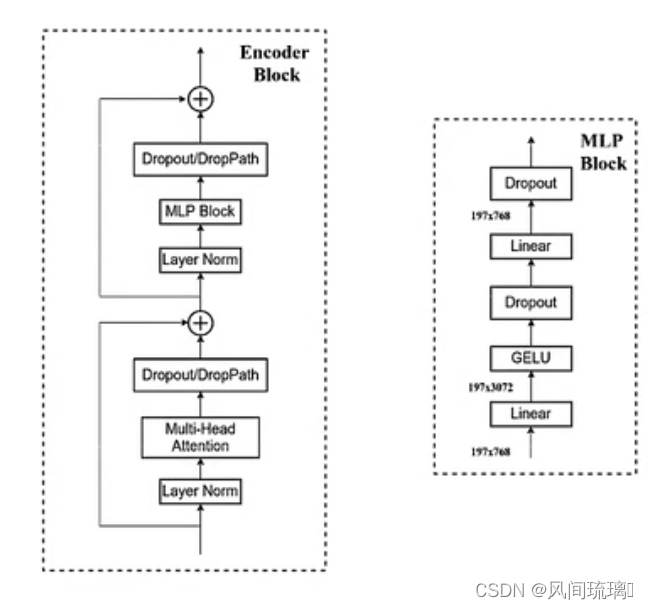
主要由以下几个部分组成:
⋆
\star
⋆ Layer Norm,这种Normalization方法主要是针对NLP领域提出的,这里是对每个token进行Norm处理,在图像处理领域中BN比LN是更有效的,但现在越来越多的人将自然语言领域的模型用来处理图像,比如Vision Transformer,此时还是会涉及到LN。
⋆ \star ⋆ ·Multi-Head Attention·,这个结构在讲前面Transformer中讲过。
⋆ \star ⋆ ·Dropout/DropPath·,在原论文的代码中是直接使用的Dropout层,在但rwightman大佬实现的代码中使用的是DropPath(stochastic depth),可能后者会更好一点。
⋆ \star ⋆ ·MLP Block·,如图右侧所示,全连接+GELU激活函数+Dropout组成,需要注意的是第一个全连接层会把输入节点个数翻4倍[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]
4.MLP Head
Transformer Encoder后输出的shape和输入的shape是保持不变的,以ViT-B/16为例,输入的是[197, 768]输出的还是[197, 768]。
在Transformer Encoder后还有一个Layer Norm,这里我们只是需要分类的信息,所以只需要提取出Class Token生成的对应结果就行,即[197, 768]中抽取出Class Token对应的[1, 768]。接着通过MLP Head得到的分类结果。

MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者自己的数据上时,只用一个Linear即可。
5.ViT B/16网络结构
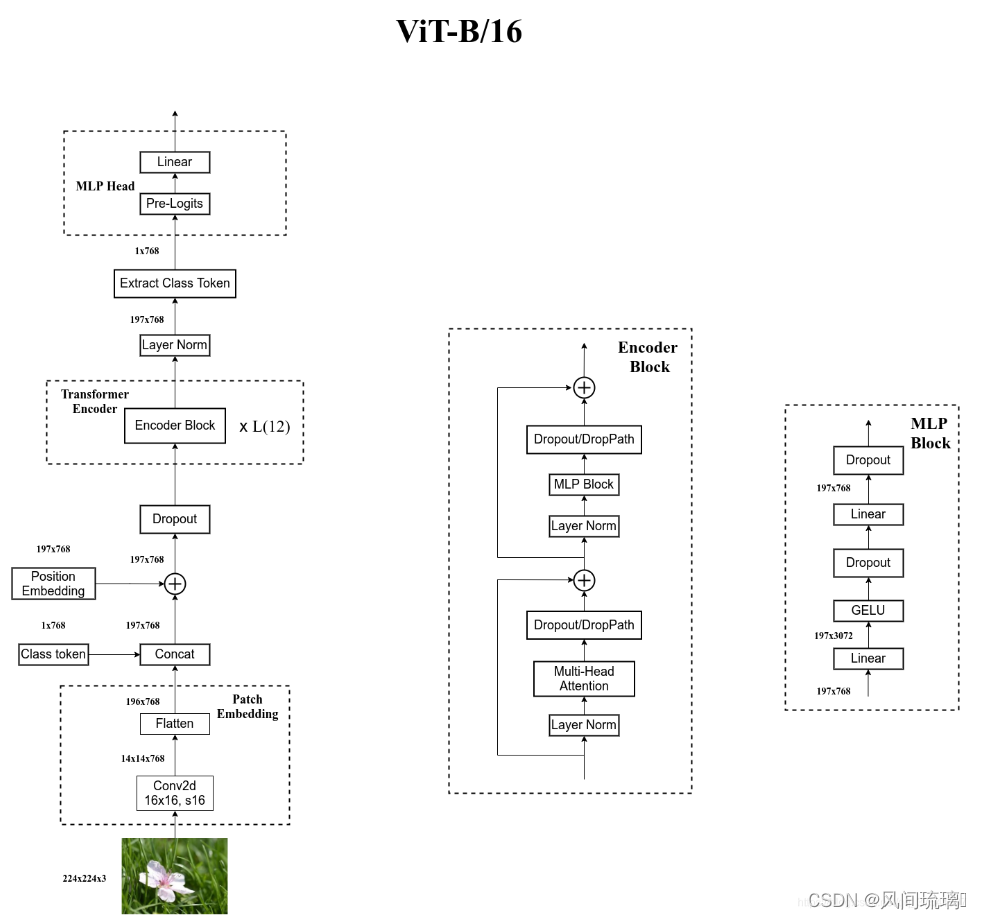
ViT B/16 的网络结构如上图所示,假设输入图为 224 × 224 × 3的RGB彩色图片。
Embedding层:首先经过一个16x16大小的卷积核、步距为16的卷积层,得到14x14x768的特征图,然后进行高度和宽度方向的展平处理,得到196x768的特征向量。紧接着 concat 一个 Class token,其尺寸变为197x768,再加上 Position Embedding 的相加操作,因为尺寸完全相同,可以理解为数值上的相加,这里的 Position Embedding 也是可训练的参数。
Transformer Encoder:将以上的输入序列经过 Dropout 后输入 12 个堆叠的 Encoder Block。Encoder 输出经过 LN 层得到的输出为 197 × 768,即是不变的。然后切片提取Class token信息,切片之后即变成了 1 × 768。
MLP Head:将提取Class token输入 MLP Head层得到最终的输出。如果在 ImageNet21K 预训练的时候,Pre-Logits 是由一个全连接层+tanh 激活函数构成,然后通过一个全连接层得到最终的输出。如果是在 ImageNet1k 或者自己的数据集上的时候训练的时候,可以不需要 Pre-Logits。
在论文中给出三个模型(Base/ Large/ Huge)的参数,ViT B 对应的就是 ViT-Base,ViT L 对应的是 ViT-Large,ViT H 对应的是 ViT-Huge。
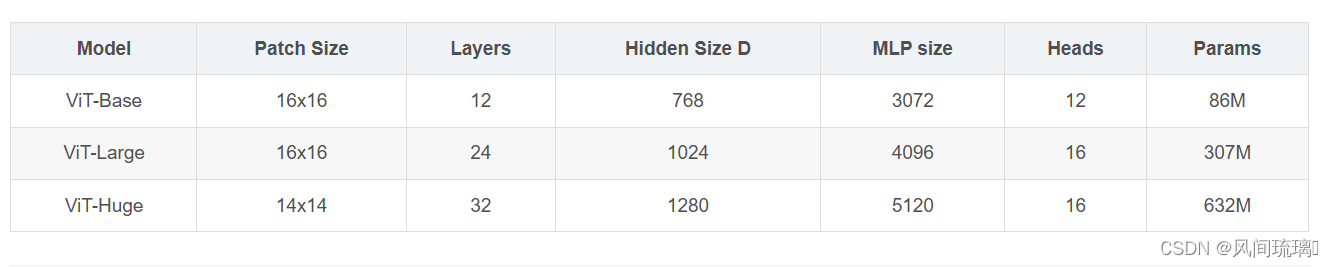
⋆
\star
⋆ patch size 是图片切片大小(源码中还有 32 × 32 )
⋆ \star ⋆ Layers是Transformer Encoder中重复堆叠Encoder Block的次数
⋆ \star ⋆ Hidden Size就是对应通过Embedding层后每个token的dim(向量的长度)
⋆ \star ⋆ MLP size是Transformer Encoder中MLP Block第一个全连接的节点个数(是Hidden Size的四倍)
⋆ \star ⋆ Heads代表Transformer中Multi-Head Attention的heads数
三、Hybrid混合模型
混合模型是指首先使用传统的卷积神经网络提取特征,然后通过Vit模型得到最终的结果。
ResNet50 + ViT-B/16网络结构如下所示:
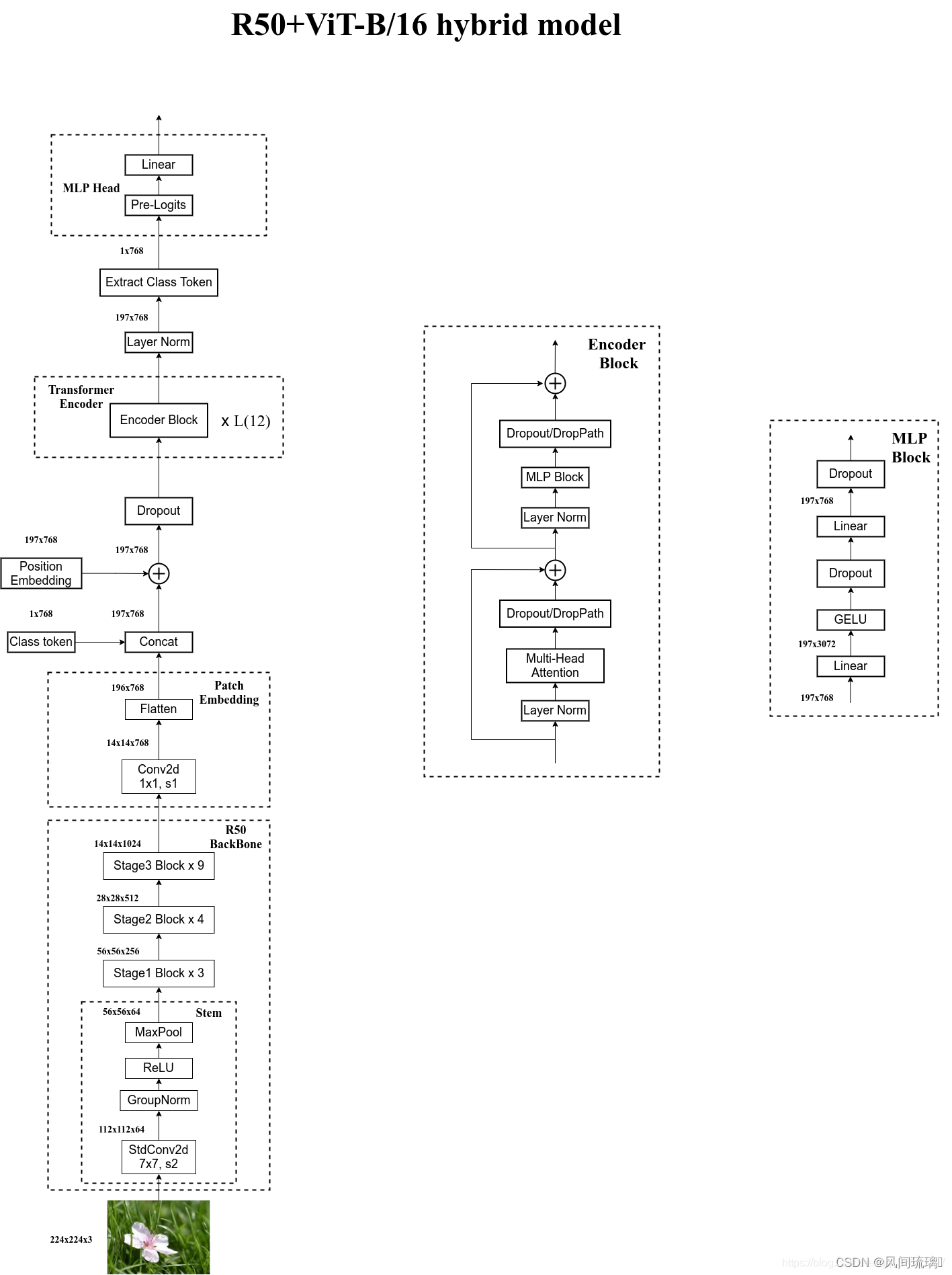
上图以ResNet50作为特征提取器的混合模型,但这里的Resnet与之前讲的Resnet有些不同。首先这里的R50的卷积层采用的StdConv2d不是Conv2d,然后将所有的BatchNorm层替换成GroupNorm层。在原Resnet50网络中,stage1重复堆叠3次,stage2重复堆叠4次,stage3重复堆叠6次,stage4重复堆叠3次,但在这里的R50中,把stage4中的3个Block移至stage3中,所以stage3中共重复堆叠9次。
通过R50 Backbone进行特征提取后,得到的特征矩阵shape是[14, 14, 1024],接着再输入Patch Embedding层,注意Patch Embedding中卷积层Conv2d的kernel_size和stride都变成了1,只是用来调整channel,经过1x1卷积核变为14x14x768,然后经过Flatten就得到token。后面的部分和ViT处理流程一样。
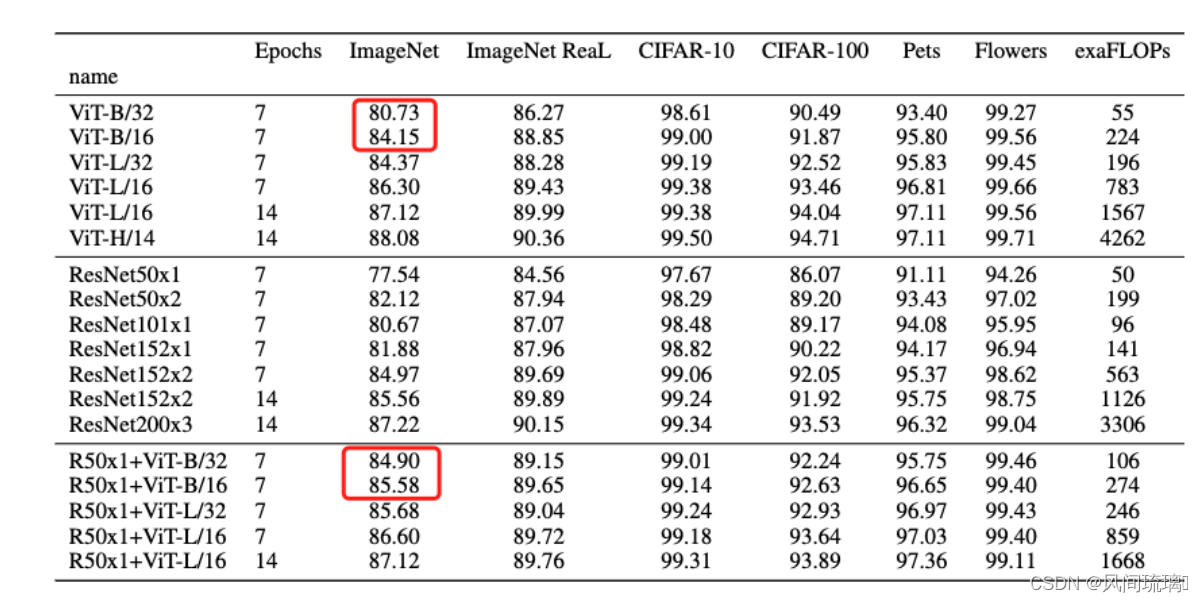
上表是论文用来对比ViT,Resnet以及Hybrid模型的效果。通过对比发现,在训练epoch较少时Hybrid优于ViT,但当epoch增大后ViT优于Hybrid。因此,如果训练迭代次数少,混合模型的效果表现比较好。如果训练迭代次数较多的话,纯ViT的效果更佳。
四、ViT网络实现
1.构建ViT网络
2.训练和测试模型
五、实现图像分类
结束语
感谢阅读吾之文章,今已至此次旅程之终站 🛬。
吾望斯文献能供尔以宝贵之信息与知识也 🎉。
学习者之途,若藏于天际之星辰🍥,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 💞。