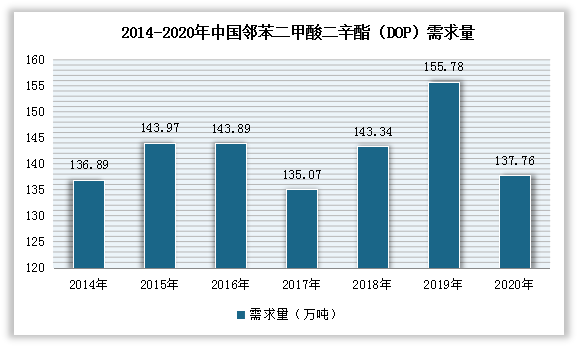
总结来说:
- feature_column定义了一种数据预处理的方式,可以看作是一种格式,指定了key,用于后续读取输入流中对应列的数据
- feature_column不是tensor,所以如果在下一步应用到模型中是需要tensor,还需要通过feature_column.input_layer 进行变换后才能进行使用
如果是将feature column 喂到estimater,就不用转为Tensor(具体可以参考 wide and deep 的代码)
- input_layer( rawData, featureColumns)
- rawData的key和 featureColumns中的每一列 feature_column 的key是一一对应的。
reference
eat tensorflow2 in 30 days 最为系统
Tensorflow.feature_column的总结 对每一类都进行了测试 和 结果的print,比较直观
杨旭东:基于Tensorflow高阶API构建大规模分布式深度学习模型系列之特征工程Feature Columns
这篇对于feature_column的使用讲解更加深入,把一些坑点也讲的比较清楚
- weighted_categorical_column、shared_column 和 sequence_dense_column 还没看
知乎:Tensorflow Feature Column Summary
- tf.feature_column.input_layer 的trainable只对原来就可以设置trainable的feature column起作用,例如像tf.feature_column.embedding_column,并且只有2个都设置为True时候,在训练中才能trainable,任何一个设置为trainable=False,都将使得该column的值无法改变,也就是无法trainable.
- tf.feature_column.input_layer 对于其他例feature column不起作用,如,tf.feature_column.indicator_column,tf.feature_column.numeric_column本身就不支持trainable,所以无论tf.feature_column.input_layer怎么设置都是无法trainable的
- 另外tf.feature_column.input_layer 与其他tensor做contact,该trainable照样可以,不行的照样不行。
官方文档
- tf1.15官网说明
- tf1.15官方代码
misc
学习TensorFlow中有关特征工程的API
有关稀疏矩阵的更多介绍可以参考《深度学习之TensorFlow——入门、原理与进阶实战》一书中的9.4.17小节
-
SparseTensor在官网中已经说得蛮清楚的了
-
把SparseTensor理解为一种存储矩阵的方式,稠密矩阵也可以这样存储,但是收益不大,少量元素为1的矩阵用这种方式去存储比较有收益。
-
还可以参照《深度学习之TensorFlow工程化项目实战》一书7.5节的方式为词向量设置一个初始值。通过具体的数值可以更直观地查看词嵌入的输出内容
归纳总结
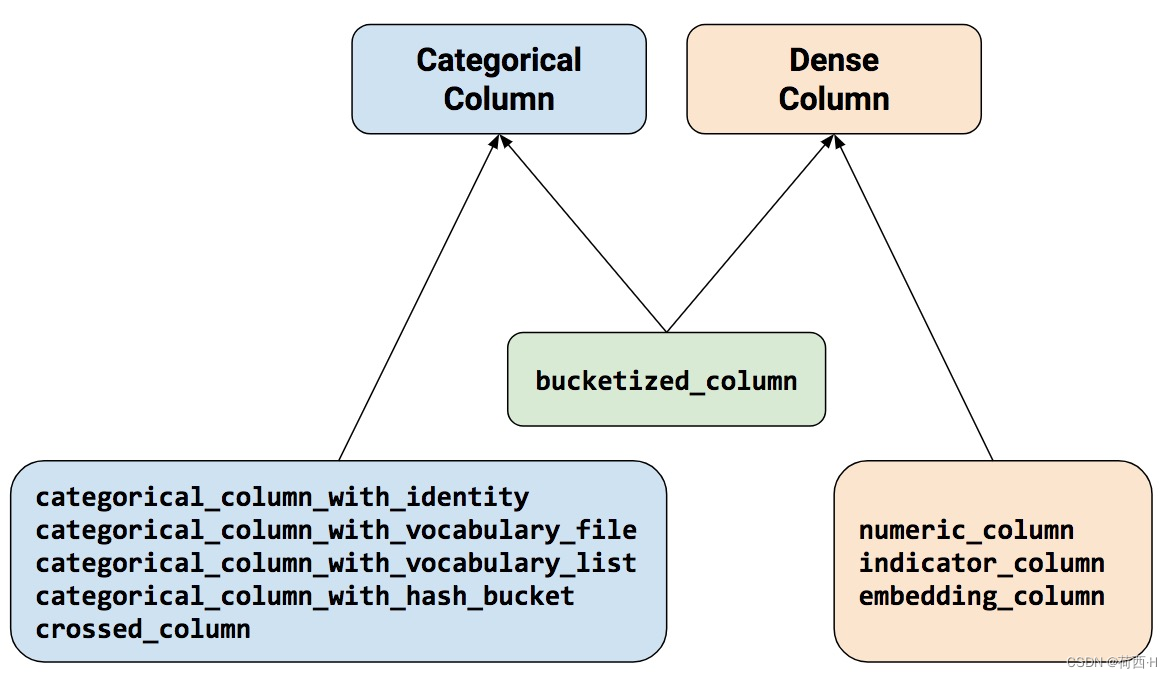
-
Categorical Column 、Embedding Column、 Indicator Column 之间的关系
- 总的来说,Indicator Column 和 embedding Column 不能直接作用在原始特征上,而是作用在Categorical Column上,是Categorical Column的wrapper。
- Indicator Column隶属于DenseColumn,主要是为了把Categorical Column转换成Dense Column用的,因为进入模型推理必须得是Dense Column类型
- Embedding Column的输入是Categorical Column。可以是Indicator Column么?意义上来说是可以的,但是其本身就是Categorical Column的一个wrapper,直接把Categorical Column输入Embedding Column也是转换成了Dense Column,可以输入到模型中去的
-
Categorical Column 中 with_identity 和 with_hash_bucket 区别
- 前者的bucket 必须设置得不小于种类数量,后者就是为了有冲突映射而存在的。
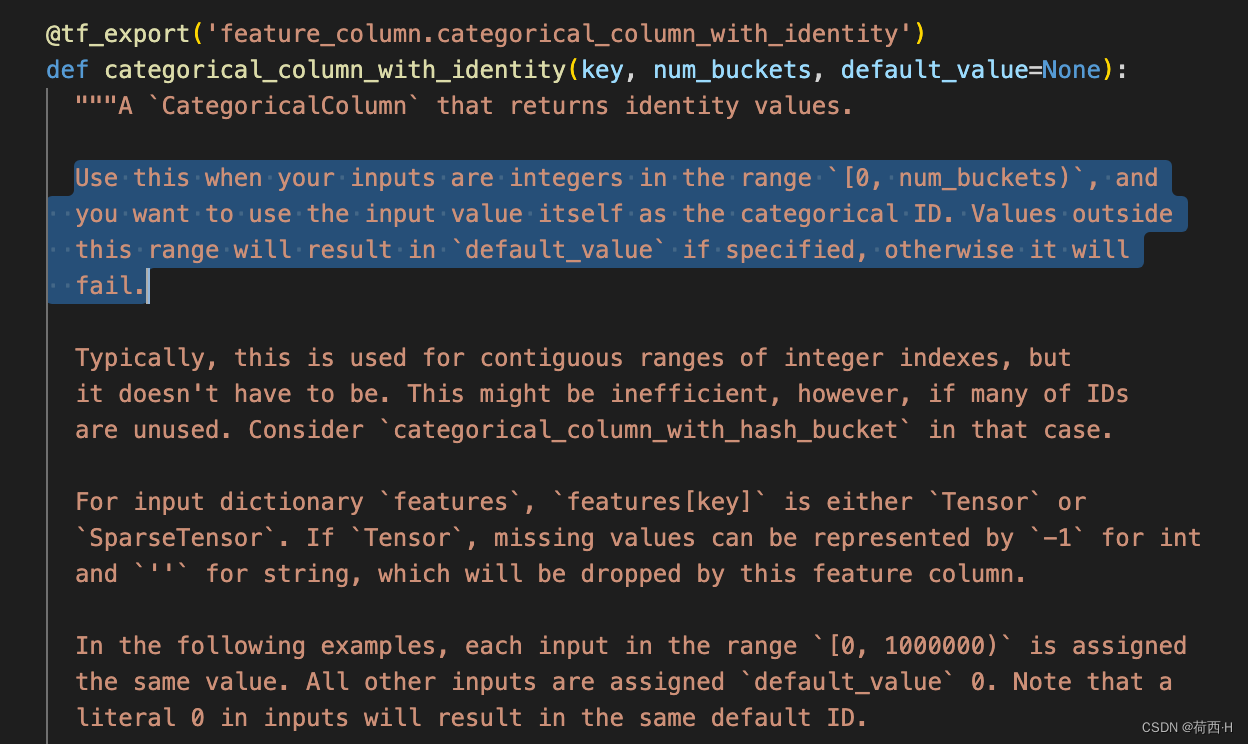
- 前者的bucket 必须设置得不小于种类数量,后者就是为了有冲突映射而存在的。
-
categorical_column_with_vocabulary_list
- default_value 和 num_oov_buckets 参数设置的相互影响
- default_value: 当不在vocabulary_list中的默认值,这时候num_oov_buckets必须是0.
- num_oov_buckets: 用来处理那些不在vocabulary_list中的值,如果是0,那么使用default_value进行填充;如果大于0,则会在[len(vocabulary_list), len(vocabulary_list)+num_oov_buckets]这个区间上重新计算当前特征的值.
- 默认值-1在embeding column时映射为0向量,这是一个很有用的特性
- default_value 和 num_oov_buckets 参数设置的相互影响
可以用-1来填充一个不定长的ID序列,这样可以得到定长的序列,然后经过embedding column之后,填充的-1值不影响原来的结果。
- Embedding Column的dimension设置
推荐是输入数据种类的四次开方(fourth root) - crossed_column也是可以指定hash_buckect_size的
- 继承Categorical Column的类有_get_sparse_tensor的方法,继承Dense Column的类有_get_dense_tensor的方法 (Bucketized Column多继承,所以两个都有),这两个方法输入transformation_cache数据,就可以得到对应的tensor
input_layer() 实际上就是调用get_dense_tensor方法
小坑注意
tf.feature_column.input_layer 特征顺序问题
tf.feature_column,input_layer(raw_features, feature_columns )最后输出的feature顺序不是依据feature_columns的排列顺序,而是根据feature_columns名称的字符排序的