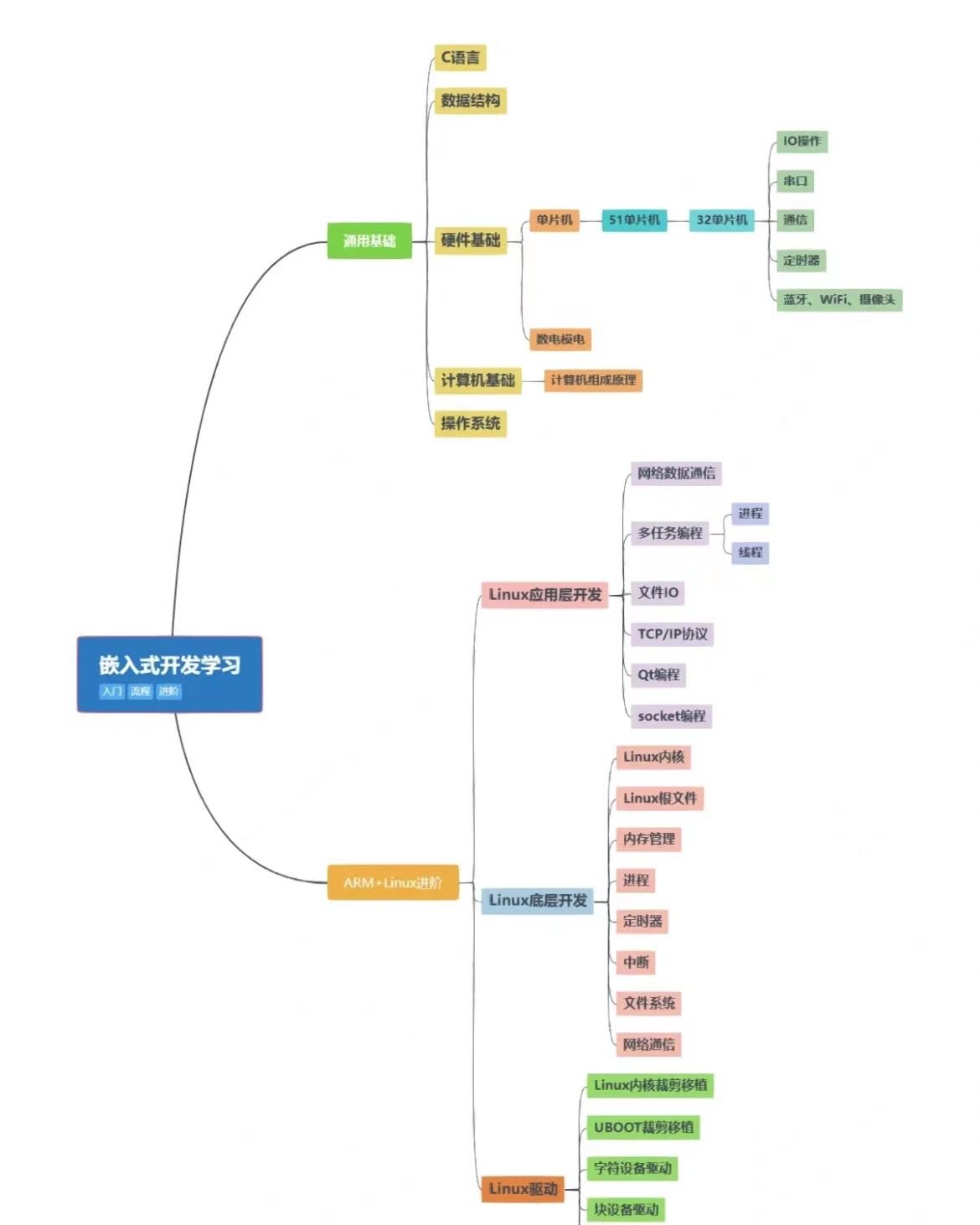
文章目录
- 工具
- excel
- Tableau
- Power Query
- jupyter
- matplotlib
- numpy
- 安装
- 导入包
- 快速掌握(bushi)
- array和list的相互转化
- np的range
- 多维数组的属性
- array的改变形状
- array升降维度
- array内元素的类型
- 数和array的运算
- array之间的加减法
- 认识轴
- 切片
- 条件与逻辑
- 修改值
- append
- insert
- delete
- unique
- 最大最小值运算
- 前缀和和平均值
- 其他的数学函数,基本理解都和上面一样
- array 拼接
- array 分割
- nan介绍
- inf
- 转置
- copy
- 常用接口总结
- 导入数据
- 最简单的接口
- 基础的读取数据-----从txt当中读取
- 有筛选的读取数据------从csv当中读取
- np.random模块
- pandas
工具
excel
略
Tableau
略
Power Query
略
jupyter
见个人链接:30 数据分析(上)链接
matplotlib
见个人链接:30 数据分析(上)链接
numpy
numpy实际上是用于科学计数的一个库,底层是使用c进行实现的,在学习tensor之前建议都先学习一遍numpy这个库,Numpy(Numerical Python)是一个开源的Python科学计算库,用于快速处理任意维度的数组。Numpy支持常见的数组和矩阵操作。对于同样的数值计算任务,使用Numpy比直接使用Python要简洁的多。Numpy使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器。
安装
pip install numpy
导入包
import numpy as np
快速掌握(bushi)
array和list的相互转化
# list转化为nparray 方法 np.array
list1 = [1,2,3,4]
print(list1)
oneArray = np.array(list1)
print(type(oneArray))
print(oneArray)
print('*'*50)
# list转化为nparray 方法1 list
t2 = np.array(range(10))
print(t2)
print(type(t2))
print(list(t2)) #list转回列表
print('*'*50)
# list转化为nparray 方法2 np.tolist
t2 = np.array(range(10))
print(t2.tolist())
print('*'*50)
输出:
[1, 2, 3, 4]
<class 'numpy.ndarray'>
[1 2 3 4]
**************************************************
[0 1 2 3 4 5 6 7 8 9]
<class 'numpy.ndarray'>
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
**************************************************
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
**************************************************
python list打印出来的元素之间有逗号,而ndarray是空格。
np的range
#np自带arange
t3 = np.arange(0,10,2)
print(t3)
print(type(t3))
输出:
[0 2 4 6 8]
<class 'numpy.ndarray'>
多维数组的属性
# 多维数组的属性
Array = np.array([[1,2],[3,4],[5,6]])
# 获取数组长的什么样子
print(Array)
# 获取数组的维度( 注意: 与函数的参数很像)
print(Array.ndim)
# 形状(行,列)
print(Array.shape)
# 有多少个元素
print(Array.size)
输出:
[[1 2]
[3 4]
[5 6]]
2
(3, 2)
6
array的改变形状
array1 = np.array([[1,2,3],[4,5,6]])
array2 = np.array([[1,2,3],[4,5,6]])
print(array1)
print('*'*50)
# 修改形状方法1 修改了本身的array
array1.shape = (3,2)
print(array1)
print('*'*50)
# 修改形状方法2 没有修改本身的array
re_array2 = array2.reshape(3,2)
print(array2)
print(re_array2)
print('*'*50)
输出:
[[1 2 3]
[4 5 6]]
**************************************************
[[1 2]
[3 4]
[5 6]]
**************************************************
[[1 2 3]
[4 5 6]]
[[1 2]
[3 4]
[5 6]]
**************************************************
array升降维度
array1 = np.array([[1,2,3],[4,5,6]])
print(array1)
print(array1.ndim)
print('*'*50)
# 通用的升降维方式
re_array1 = array1.reshape(6)
print(re_array1)
print(re_array1.ndim)
re_array1 = array1.reshape(1,2,3)
print(re_array1)
print(re_array1.ndim)
print('*'*50)
# 将多维变成一维数组
fla_array1 = array1.flatten()
print(fla_array1)
print('*'*50)
输出:
[[1 2 3]
[4 5 6]]
2
**************************************************
[1 2 3 4 5 6]
1
[[[1 2 3]
[4 5 6]]]
3
**************************************************
[1 2 3 4 5 6]
**************************************************
array内元素的类型
指定dtype的目的是减少内存的使用,提高运算效率
整数:
# np.int8到np.int64 16就是16bits
array = np.array([1,2,3,4,5], dtype = np.int16) # 返回数组中每个元素的字节单位长度,dtype设置数据类型
# itemsize 输出的就是所占的字节数
print(array.itemsize)
# 获取数据类型
print(array.dtype)
# 修改数据类型
array = array.astype(np.int64)
print(array.dtype)
print(array.itemsize)
输出:
2
int16
int64
8
小数:
import random
# 随机生成小数
# 使用python语法,round是保留多少位
print(random.random())
print(round(random.random(),2))
print('-'*50)
array = np.array([random.random() for i in range(10)])
print(array)
print(array.itemsize)
print(array.dtype)
print('-'*50)
array1 = array.astype(np.float32)
print(array1)
#float32精度为6-7位
#double(float64)精度是15-16位
# 取小数点后两位,np.round可以把所有的元素都变成2位有效数字
print(np.round(array,2))
输出:
0.979209849421405
0.26
--------------------------------------------------
[0.3763924 0.32276703 0.4589791 0.15596424 0.37418283 0.17352511
0.61259661 0.35300061 0.10490647 0.7840607 ]
8
float64
--------------------------------------------------
[0.3763924 0.32276702 0.4589791 0.15596424 0.37418282 0.17352511
0.61259663 0.3530006 0.10490647 0.7840607 ]
[0.38 0.32 0.46 0.16 0.37 0.17 0.61 0.35 0.1 0.78]
数和array的运算
array = np.arange(6).reshape((2,3))
print(array)
print("-"*50)
# array可以与整数进行加减乘除
print(array+2)
print(array-2)
print(array*2)
print(array/2)
print(array//2)
输出:
[[0 1 2]
[3 4 5]]
--------------------------------------------------
[[2 3 4]
[5 6 7]]
[[-2 -1 0]
[ 1 2 3]]
[[ 0 2 4]
[ 6 8 10]]
[[0. 0.5 1. ]
[1.5 2. 2.5]]
[[0 0 1]
[1 2 2]]
array之间的加减法
形状相同之间的运算:
t1 = np.arange(0,6).reshape((2,3))
t2 = np.arange(100,106).reshape((2,3))
print(t1)
print(t2)
print('-'*50)
print(t1+t2)
print(t1*t2) #是否是矩阵乘法? 不是,是对应位置相乘
输出:
[[0 1 2]
[3 4 5]]
[[100 101 102]
[103 104 105]]
--------------------------------------------------
[[100 102 104]
[106 108 110]]
[[ 0 101 204]
[309 416 525]]
形状不相同之间的运算,只有部分可行:
#一维数组和二维数组进行运算时,一维的元素个数和列数相等
t1 = np.arange(24).reshape((4,6))
t2 = np.arange(0,6)
print(t1)
print(t2)
print('-'*50)
t2=t2.reshape((1,6))
print(t2)
# np.sum(array)函数就是把内部所有的元素相加得到一个值,然后返回
print(np.sum(t2))
print(t2.shape)
print(t1-t2)
输出:
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]]
[0 1 2 3 4 5]
--------------------------------------------------
[[0 1 2 3 4 5]]
15
(1, 6)
[[ 0 0 0 0 0 0]
[ 6 6 6 6 6 6]
[12 12 12 12 12 12]
[18 18 18 18 18 18]]
t1 = np.arange(24).reshape((4,6))
t2 = np.arange(4).reshape((4,1))
print(t2)
print(t1)
print('-'*50)
print(t1-t2)
输出:
[[0]
[1]
[2]
[3]]
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]]
--------------------------------------------------
[[ 0 1 2 3 4 5]
[ 5 6 7 8 9 10]
[10 11 12 13 14 15]
[15 16 17 18 19 20]]
认识轴
轴是从0,1,2,3,4······开始的
0对应的就是第一层括号,1就是第二层括号,沿轴就是将这个括号去掉,然后相运算
array1 = np.array([[1,2,3],[4,5,6]])
print(array1)
print('-'*50)
print(np.sum(array1,axis=0))
print(np.sum(array1,axis=1))
print("-"*50)
# 思维提升 四维测试
array2=np.arange(24).reshape((1,2,3,4))
print(array2)
print(np.sum(array2,axis=1))
print(np.sum(array2,axis=1).shape)
print('-'*50)
输出:
[[1 2 3]
[4 5 6]]
--------------------------------------------------
[5 7 9]
[ 6 15]
--------------------------------------------------
[[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]]
[[[12 14 16 18]
[20 22 24 26]
[28 30 32 34]]]
(1, 3, 4)
--------------------------------------------------
切片
array = np.arange(12).reshape(4,3)
print(array)
print('-'*50)
# 取其中一行
print(array[1])
print('-'*50)
# 切片 取连续多行
print(array[1:])
print('-'*50)
# 切片 取连续的多行
print(array[1:3,:])
print('-'*50)
# 取不连续的多行
print(array[[0,3]])
print('-'*50)
# 取不连续的多行
print(array[[0,2,3],:])
print('-'*50)
# 取一列
print(array[:,1])
print('-'*50)
# 连续的多列
print(array[:,1:])
print('-'*50)
# 取不连续的多列
print(array[:,[0,2]])
print('-'*50)
# 取某一个值,三行四列 py是t1[2][1]
print(array[2,1])
print('-'*50)
# 取多个连续的值 行列的连续
print(array[1:3,1:3])
print('-'*50)
# 取多个不连续的值,[[行,行。。。],[列,列。。。]]
print(t1[[0,1,1],[0,1,3]])
输出:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
--------------------------------------------------
[3 4 5]
--------------------------------------------------
[[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
--------------------------------------------------
[[3 4 5]
[6 7 8]]
--------------------------------------------------
[[ 0 1 2]
[ 9 10 11]]
--------------------------------------------------
[[ 0 1 2]
[ 6 7 8]
[ 9 10 11]]
--------------------------------------------------
[ 1 4 7 10]
--------------------------------------------------
[[ 1 2]
[ 4 5]
[ 7 8]
[10 11]]
--------------------------------------------------
[[ 0 2]
[ 3 5]
[ 6 8]
[ 9 11]]
--------------------------------------------------
7
--------------------------------------------------
[[4 5]
[7 8]]
--------------------------------------------------
[0 7 9]
条件与逻辑
# 条件 与 逻辑
array = np.arange(6).reshape(2,3)
print(array)
print('-'*20)
# 条件 逻辑与:& 逻辑或| 逻辑非~
print(array[(array>1)&(array<4)])
print('-'*20)
输出:
[[0 1 2]
[3 4 5]]
--------------------
[2 3]
--------------------
修改值
array1 = np.arange(12).reshape(3,4)
array2 = np.arange(12).reshape(3,4)
array3 = np.arange(12).reshape(3,4)
array4 = np.arange(12).reshape(3,4)
print(array1)
print('-'*20)
# 切片修改值
array1[1:3,1:3]=0
print(array1)
print('-'*20)
# 条件修改值
array2[~(array2>4)]=0
print(array2)
print('-'*20)
# clip函数修改
# np.clip(array,num1,num2) 就是在这个array当中元素小于num1的都修改成num1,大于num2的都修改成num2
array3 = np.clip(array3,5,10)
print(array3)
print('-'*20)
# where函数的修改
# np.where(condition, x, y)满足条件(condition),输出x,不满足输出y。)
array4 = np.where(array4<7,True,False)
print(array4)
print('-'*20)
输出:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
--------------------
[[ 0 1 2 3]
[ 4 0 0 7]
[ 8 0 0 11]]
--------------------
[[ 0 0 0 0]
[ 0 5 6 7]
[ 8 9 10 11]]
--------------------
[[ 5 5 5 5]
[ 5 5 6 7]
[ 8 9 10 10]]
--------------------
[[ True True True True]
[ True True True False]
[False False False False]]
--------------------
append
# numpy.append 函数在数组的末尾添加值。 追加操作会分配整个数组,并把原来的数组复制到新数组中。
# 此外,输入数组的维度必须匹配,否则将生成ValueError。
array = np.array([[1, 2, 3], [4, 5, 6]])
print(array)
print('-'*20)
# 添加一行
print(np.append(array, [7, 8, 9]))
print('-'*20)
# 沿轴 0 添加元素 这边可以看出(2,3)添加需要(1,3)
print(np.append(array, [[7, 8, 9]], axis=0))
print('-'*20)
# 沿轴 1 添加元素 这边可以看出(2,3)添加需要(2,2),小的总结一下添加哪一维度,那一个维度才可以不同,剩下的都需要相同
print(np.append(array, [[5, 5], [7, 8]], axis=1))
print('-'*20)
输出:
[[1 2 3]
[4 5 6]]
--------------------
[1 2 3 4 5 6 7 8 9]
--------------------
[[1 2 3]
[4 5 6]
[7 8 9]]
--------------------
[[1 2 3 5 5]
[4 5 6 7 8]]
--------------------
当处于高纬度的时候,我们更希望知道的是shape是否是按照我们的想法进行扩展,而不关注内部的数据,因为数据呵呵,当处于高维的时候,我们是没有办法进行想象,像人工智能下的tensor张量,基本我见过的最多达到5阶,那已经是没有办法进行查看了,这边给出三维度的相加,看一下:(实际上就是对应维度相加)
array = np.arange(24).reshape(2,3,4)
print(array.shape)
# axios=0 (2,3,4)+(1,3,4) = (3,3,4)
print(np.append(array,[[[1,2,3,4],[5,6,7,8],[9,10,11,12]]],axis=0).shape)
# axios=1 (2,3,4)+(2,2,4) = (2,5,4)
print(np.append(array,[[[1,2,3,4],[5,6,7,8]],[[5,6,7,8],[9,10,11,12]]],axis=1).shape)
# axios=2 (2,3,4)+(2,3,1) = (2,3,5)
print(np.append(array,[[[1],[2],[3]],[[4],[5],[6]]],axis=2).shape)
(2, 3, 4)
(3, 3, 4)
(2, 5, 4)
(2, 3, 5)
insert
# numpy.insert
# 函数在给定索引之前,沿给定轴在输入数组中插入值。# 如果值的类型转换为要插入,则它与输入数组不同。
# 插入没有原地的,函数会返回一个新数组。 此外,如果未提供轴,则输入数组会被展开。
array = np.arange(6).reshape(3,2)
print(array)
print(array.shape)
print('-'*20)
print(np.insert(array,1, [11, 12]))
print(np.insert(array,1, [11, 12]).shape)
print('-'*20)
# 沿轴0广播
print(np.insert(array,1, [11, 12],axis=0))
print(np.insert(array,1, [11, 12],axis=0).shape)
print('-'*20)
# 沿轴1广播
print(np.insert(array, 1, 11, axis=1))
print(np.insert(array, 1, 11, axis=1).shape)
输出:
[[0 1]
[2 3]
[4 5]]
(3, 2)
--------------------
[ 0 11 12 1 2 3 4 5]
(8,)
--------------------
[[ 0 1]
[11 12]
[ 2 3]
[ 4 5]]
(4, 2)
--------------------
[[ 0 11 1]
[ 2 11 3]
[ 4 11 5]]
(3, 3)
三维查看:
array = np.arange(24).reshape(2,3,4)
print(array.shape)
print('-'*20)
# (2, 3, 4)+11=(3, 3, 4)
print(np.insert(array,1,11,axis=0).shape)
print(np.insert(array,1,11,axis=0))
print('-'*20)
# (2, 3, 4)+(2,4)=(2, 4, 4)
print(np.insert(array,1,[[1,2,3,4],[5,6,7,8]],axis=1).shape)
print(np.insert(array,1,[[1,2,3,4],[5,6,7,8]],axis=1))
print('-'*20)
print(np.insert(array,1,[[1,2,3],[4,5,6]],axis=2).shape)
print(np.insert(array,1,[[1,2,3],[4,5,6]],axis=2))
print('-'*20)
输出:
(2, 3, 4)
--------------------
(3, 3, 4)
[[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[11 11 11 11]
[11 11 11 11]
[11 11 11 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
--------------------
(2, 4, 4)
[[[ 0 1 2 3]
[ 1 2 3 4]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[ 5 6 7 8]
[16 17 18 19]
[20 21 22 23]]]
--------------------
(2, 3, 5)
[[[ 0 1 1 2 3]
[ 4 2 5 6 7]
[ 8 3 9 10 11]]
[[12 4 13 14 15]
[16 5 17 18 19]
[20 6 21 22 23]]]
--------------------
delete
具体多维的理解和insert一致,就是对应维度的shape-1,或者说对应维度的元素num剪掉
#numpy.delete 函数返回从输入数组中删除指定子数组的新数组。 与 insert() 函数的情况一样,
# 如果未提供轴参数, 则输入数组将展开。
array = np.arange(2,14).reshape(3,4)
print(array)
print(array.shape)
print('-'*20)
print(np.delete(array,5))
print(np.delete(array,5).shape)
print('-'*20)
print(np.delete(array,1,axis = 0))
print(np.delete(array,1,axis = 0).shape)
print('-'*20)
print(np.delete(array,2,axis = 1))
print(np.delete(array,2,axis = 1).shape)
print('-'*20)
输出:
[[ 2 3 4 5]
[ 6 7 8 9]
[10 11 12 13]]
(3, 4)
--------------------
[ 2 3 4 5 6 8 9 10 11 12 13]
(11,)
--------------------
[[ 2 3 4 5]
[10 11 12 13]]
(2, 4)
--------------------
[[ 2 3 5]
[ 6 7 9]
[10 11 13]]
(3, 3)
--------------------
unique
# numpy.unique 函数用于去除数组中的重复元素,并且进行排序
array = np.array([5,2,6,2,7,5,6,9,8,2])
print (array)
print('-'*20)
#去除重复元素,输出的是有序序列
print (np.unique(array))
print('-'*20)
# 去重数组的索引数组
u,indices = np.unique(array, return_index = True)
print(u)
print (indices)
print('-'*20)
# 我们可以看到每个和原数组下标对应的数值
# 去重数组的下标
u,indices = np.unique(array,return_inverse = True)
print (u)
print (indices)
print('-'*20)
# 返回去重元素的重复数量
u,indices = np.unique(array,return_counts = True)
print (u)
print (indices)
带上轴的
np.unique(np.array([[1, 0, 0], [1, 0, 0], [2, 0, 0]]), axis=1)
"""
array([[0, 1],
[0, 1],
[0, 2]])
"""
最大最小值运算
array = np.array([[80,88],[82,81],[75,81]])
print(array)
# 获取所有数据最大值,最小值
print(np.max(array))
print(np.min(array))
print('-'*20)
# 获取某一个轴上的数据最大值
print(np.max(array,axis=1))
print(np.min(array,axis=0))
print('-'*20)
# 数据的比较
# 第一个参数中的每一个数与第二个参数比较返回大的
print(np.maximum(np.arange(-2,3), 0 ))
# 第一个参数中的每一个数与第二个参数比较返回小的
print(np.minimum(np.arange(-2,3), 0 ))
print('-'*20)
# argmin求最小值索引
print(array)
print(np.argmax(array,axis=0))
print(np.argmin(array))
输出:
[[80 88]
[82 81]
[75 81]]
88
75
--------------------
[88 82 81]
[75 81]
--------------------
[0 0 0 1 2]
[-2 -1 0 0 0]
--------------------
[[80 88]
[82 81]
[75 81]]
[1 0]
4
前缀和和平均值
array = np.arange(6).reshape(2,3)
print(array)
print('-'*20)
# 求平均值
print(np.mean(array))
print(np.mean(array,axis=1))
print('-'*20)
# 求前缀和
print(array.cumsum(0))
'''
[0, 1, 2]------> |0 |1 |2 |
[3, 4, 5]------> |3=3+0 |5=1+4 |7=5+2|
'''
print(array.cumsum(1))
输出:
[[0 1 2]
[3 4 5]]
--------------------
2.5
[1. 4.]
--------------------
[[0 1 2]
[3 5 7]]
[[ 0 1 3]
[ 3 7 12]]
其他的数学函数,基本理解都和上面一样
直接去看结论,有剩下的函数
array 拼接
# 有的时候我们需要将两个数据加起来一起研究分析,我们就可以将其进行拼接然后分析
a = np.array([[1,2],[3,4]])
b = np.array([[5,6],[7,8]])
# 要求a,b两个数组的维度相同
# 沿轴 0 连接两个数组
print (np.concatenate((a,b),axis= 0))
# 沿轴 1 连接两个数组
print (np.concatenate((a,b),axis = 1))
print('-'*20)
# 升维度相加
print(np.stack((a,b),axis=0))
print(np.stack((a,b),axis=1))
print(np.stack((a,b),axis=-1))
print('-'*20)
# 水平相加
v1 = [[0,1,2,3,4,5],
[6,7,8,9,10,11]]
v2 = [[12,13,14,15,16,17],
[18,19,20,21,22,23]]
print(np.vstack((v1,v2)))
print('-'*20)
# 垂直相加
v1 = [[0,1,2,3,4,5],
[6,7,8,9,10,11]]
v2 = [[12,13,14,15,16,17],
[18,19,20,21,22,23]]
print(np.hstack((v1,v2)))
输出:
[[1 2]
[3 4]
[5 6]
[7 8]]
[[1 2 5 6]
[3 4 7 8]]
--------------------
[[[1 2]
[3 4]]
[[5 6]
[7 8]]]
[[[1 2]
[5 6]]
[[3 4]
[7 8]]]
[[[1 5]
[2 6]]
[[3 7]
[4 8]]]
--------------------
[[ 0 1 2 3 4 5]
[ 6 7 8 9 10 11]
[12 13 14 15 16 17]
[18 19 20 21 22 23]]
--------------------
[[ 0 1 2 3 4 5 12 13 14 15 16 17]
[ 6 7 8 9 10 11 18 19 20 21 22 23]]
array 分割
# 1. 将一个数组分割为多个子数组
'''
参数说明:
ary:被分割的数组
indices_or_sections:是一个整数,就用该数平均切分,如果是一个数组,为沿轴切分的位置(左开右闭)
axis:沿着哪个维度进行切向,默认为0,横向切分。为1时,纵向切分
'''
array = np.arange(6).reshape(2,3)
print(array)
print('-'*20)
print (np.split(array,2))
print (np.hsplit(array,1))
print (np.hsplit(array,3))
print (np.vsplit(array,1))
print (np.vsplit(array,2))
print('-'*20)
输出:
[[0 1 2]
[3 4 5]]
--------------------
[array([[0, 1, 2]]), array([[3, 4, 5]])]
[array([[0, 1, 2],
[3, 4, 5]])]
[array([[0],
[3]]), array([[1],
[4]]), array([[2],
[5]])]
[array([[0, 1, 2],
[3, 4, 5]])]
[array([[0, 1, 2]]), array([[3, 4, 5]])]
nan介绍
# nan可以当成空 inf就当成无限大,不过在计算的时候记得分为正无限大和负无限大
nan = np.nan #nan代表not a number,不是数值,从文档中读取数值时,读取了空
inf = np.inf
array = np.arange(12,dtype=np.float32).reshape(3,4)
array[1,2]=nan
array[2,3]=nan
print(array)
print('-'*20)
# 统计nan的数量 np.count_nonzero(array)统计的是array当中的0的个数,需要注意的是 nan!=nan ,而array当中的其他元素都和自己本身相等,所以就可以用这个来进行判断
print(np.count_nonzero(array != array))
print('-'*20)
# 返回一个是否是nan的数组
print(np.isnan(array))
print('-'*20)
# 把nan变成0
array1 = array
array1[array1!=array1]=0
print(array1)
输出:
[[ 0. 1. 2. 3.]
[ 4. 5. nan 7.]
[ 8. 9. 10. nan]]
--------------------
2
--------------------
[[False False False False]
[False False True False]
[False False False True]]
--------------------
[[ 0. 1. 2. 3.]
[ 4. 5. 0. 7.]
[ 8. 9. 10. 0.]]
看一下是否能看得懂:
array = np.arange(24).reshape(4,6).astype(np.float32)
print(array)
# 将数组中的一部分替换nan
array[1:3,1:5] = np.nan
print(array)
print('-'*20)
print(array.shape)
# 遍历每一列,然后判断每一列是否有nan, column
for i in range(array.shape[1]):
#获取当前列数据
temp_col = array[:,i]
# 判断当前列的数据中是否含有nan
nan_num = np.count_nonzero(temp_col != temp_col)
# 条件成立说明含有nan
if nan_num != 0:
# 将这一列不为nan的数据拿出来
temp_col_not_nan = temp_col[temp_col == temp_col]
print(temp_col_not_nan)
# 将nan替换成这一列的平均值
temp_col[np.isnan( temp_col )] = np.mean( temp_col_not_nan )
print(array)
[[ 0. 1. 2. 3. 4. 5.]
[ 6. 7. 8. 9. 10. 11.]
[12. 13. 14. 15. 16. 17.]
[18. 19. 20. 21. 22. 23.]]
[[ 0. 1. 2. 3. 4. 5.]
[ 6. nan nan nan nan 11.]
[12. nan nan nan nan 17.]
[18. 19. 20. 21. 22. 23.]]
--------------------
(4, 6)
[ 1. 19.]
[ 2. 20.]
[ 3. 21.]
[ 4. 22.]
[[ 0. 1. 2. 3. 4. 5.]
[ 6. 10. 11. 12. 13. 11.]
[12. 10. 11. 12. 13. 17.]
[18. 19. 20. 21. 22. 23.]]
还有就是任何数据和nan计算都是nan
inf
- 对于inf只需要知道无限大有分正无限和负无限大
- 无限大等于无限大
- 1/0=无限大
转置
#对换数组的维度
array = np.arange(6).reshape(2,3)
print (array)
print('-'*20)
# 转置 T和np.transpose是一样的 多维转置(1,2,3)-> (3,2,1)全反
print (np.transpose(array))
print(array.T)
print('-'*20)
# 函数用于交换数组的两个轴
print(np.swapaxes(array,0,1))
print('-'*20)
# 其实对于机器学习来说我们仅仅需要看shape
array = np.arange(6).reshape(1,2,3)
print(np.shape(array))
print(np.shape(np.transpose(array)))
print(np.shape(np.swapaxes(array,0,1)))
print('-'*20)
# 轴滚动
a = np.ones((3,4,5,6))
print(np.rollaxis(a, 3,start=0).shape)
输出:
[[0 1 2]
[3 4 5]]
--------------------
[[0 3]
[1 4]
[2 5]]
[[0 3]
[1 4]
[2 5]]
--------------------
[[0 3]
[1 4]
[2 5]]
--------------------
(1, 2, 3)
(3, 2, 1)
(2, 1, 3)
--------------------
(6, 3, 4, 5)
copy
就如下,就不解释了。。。。
array1=array2.copy()
常用接口总结
| 接口 | 说明 |
|---|---|
| np.array(list,detype) | 把list转化为array,参数list常用列表,也可以是其他的可迭代对象,detype参数可写,写的就是内部元素的类型 |
| list(array) | 把array转化为list,参数array就是array,将之转化为list列表,这个接口是改变本array |
| array.tolist() | 这个接口返回array的list形式,这个接口是返回一个新的list对象,而原本的array还是array,和上面的相对比 |
| np.arange(num1,num2,num3) | 和range的使用方式一样,num1就是起始位置(闭区间),num2就是结束位置(开区间),num3就是步长 |
| array.ndim | 查看数组的维度 |
| array.shape | 查看数组的形状,然后这个值可供赋值操作,可以赋值为一个元组,例如(3,2) |
| array.size | 查看数组总共元素的多少 |
| array.reshape() | 修改数组的形状,同样也可以升降维 |
| array1.flatten() | 直接拉长,变成一维 |
| array.itemsize | itemsize 输出的就是所占的字节数 |
| array.dtype | 元素的属性 |
| array.astype(np.对应元素的属性,如np.float64) | 修改元素的属性,需要关注的是截断 |
| np.round(array,num) | 返回array数组,当中的每一个元素都进行四舍五入,四舍五入的位数和num相关 |
| random.random() | 返回的是0-1之间的小数(np.float64) |
| np.sum(array,axis) | array返回累加值,axis就是轴,沿哪一个轴的方向相加 |
| 切片 | 见上,这边没办法总结 |
| np.clip(array,num1,num2) | 就是在这个array当中元素小于num1的都修改成num1,大于num2的都修改成num2 |
| np.where(condition, x, y) | 满足条件(condition),输出x,不满足输出yarr输入数组 values 要向arr添加的值,需要和arr形状相同(除了要添加的轴)axis 默认为None。当axis无定义时,是横向加成,返回总是为一维数组!当axis有定义的时候,分别为0和1的时候。当axis有定义的时候,分别为0和1的时候(列数要相同)。当axis为1时,数组是加在右边(行数要相同)。 |
| np.append(array, list, axis) | |
| np.insert(array,1, 元素,axis) | 不指定axis就是一维拉长相加,元素如果选常数,就是每一层都相加,元素如果是选列表,数目就需要和array一致,1就是插入的位置,array就是数组 |
| np.delete(array,1,axis) | arr: 输 入 数 组obj:可以被切片,整数或者整数数组,表明要从输入数组删除的子数组axis:沿着它删除给定子数组的轴,如果未提供,则输入数组会被展开 |
| np.unique(array,return的参数,axis) | arr:输入数组,如果不是一维数组则会展开,return_index:如果为true,返回新列表元素在旧列表中的位置(下标),并以列表形式储,return_inverse:如果为true,返回旧列表元素在新列表中的位置(下标),并以列表形式储,return_counts:如果为true,返回去重数组中的元素在原数组中的出现次数,axis就是删除第几维的数据,此时元素按照 |
| np.max(array,axis) | 求取某一个轴上的最大值,如果不写axis,就是展开一维,看所有数值的最大值 |
| np.min(array,axis) | 与上相反 |
| np.maximum(array, 0 ) | 把array当中小于0的数都变成0 |
| np.minimum(array, 0 ) | 与上相反 |
| np.argmax(array,axis) | 寻找array中的选定轴的最大值的索引 |
| np.argmin(array,axis) | 与上相反 |
| np.mean(array,axis) | 算出所选定轴的平均数 |
| array.cumsum(axis) | 算出所选定轴的前缀和 |
| numpy.sqrt(array) | 平方根函数 |
| numpy.exp(array) | e^array[i]的数组 |
| numpy.abs/fabs(array) | 计算绝对值 |
| numpy.square(array) | 计算各元素的平方 等于array 2 |
| numpy.log/log10/log2(array) | 计算各元素的各种对数 |
| numpy.sign(array) | 计算各元素正负号 |
| numpy.isnan(array) | 计算各元素是否为NaN |
| numpy.isinf(array) | 计算各元素是否为NaN |
| numpy.cos/cosh/sin/sinh/tan/tanh(array) | 三角函数 |
| numpy.modf(array) | 将array中值得整数和小数分离,作两个数组返回 |
| numpy.ceil(array) | 向上取整,也就是取比这个数大的整数 |
| numpy.floor(array) | 向下取整,也就是取比这个数小的整数 |
| numpy.rint(array) | 四舍五入 |
| numpy.trunc(array) | 向0取整 |
| numpy.add(array1,array2) | 元素级加法 |
| numpy.subtract(array1,array2) | 元素级减法 |
| numpy.multiply(array1,array2) | 元素级乘法 |
| numpy.divide(array1,array2) | 元素级除法 array1./array2 |
| numpy.power(array1,array2) | 元素级指数 array1.^array2 |
| numpy.maximum/minimum(array1,aray2) | 元素级最大值 |
| numpy.fmax/fmin(array1,array2) | 元素级最大值,忽略NaN |
| numpy.mod(array1,array2) | 元素级求模 |
| numpy.copysign(array1,array2) | 将第二个数组中值得符号复制给第一个数组中值 |
| numpy.greater/greater_equal/less/less_equal/equal/not_equal (array1,array2) | 元素级比较运算,产生布尔数组 |
| numpy.logical_end/logical_or/logic_xor(array1,array2) | 元素级的真值逻辑运算 |
| np.concatenate((array1,array2),axis) | 沿选定轴方向进行拼接,除维度外的shape都需要一样 |
| np.stack((array1,array2),axis) | 升维度进行拼接,不过需要注意的是,这个的前后的,需要维度形状都一样 |
| np.concatenate((array1,array2),axis) | 沿axis方向的array的array相加 |
| np.vstack((array1,array2)) | 水平元素相加 |
| np.hstack((array1,array2)) | 垂直元素相加 |
| np.split(array,num,axios) | 沿轴方向分割数组数组 |
| np.vsplit(array,indices_or_sections) | array:被分割的数组,indices_or_sections:是一个整数,就用该数平均切分,如果是一个数组,为沿轴切分的位置(左开右闭)axis:沿着哪个维度进行切向,默认为0,横向切分。为1时,纵向切分 |
| np.vsplit(array,indices_or_sections) | 上面是水平,这边是竖直方向上 |
| np.count_nonzero(array) | 统计非零的数目 |
| np.nan | null |
| np.inf | 无限大 |
| np.transpose(array) | 逆序倒置他的shape |
| np.T | 同上 |
| np.swapaxes(array,0,1) | 交换两个轴 |
| np.rollaxis(array, num2,start=num1) | 轴滚动,就是把num2和num1进行调换,需要注意的是只有num2>num1才会执行 |
| array1=array2.copy() | 实际上就是后者是前者的一个copy,他们的id不一样 |
导入数据
最简单的接口
直接np.load()
和np.save()
读取的是npy文件,这边就不介绍了
基础的读取数据-----从txt当中读取
np.loadtxt(fname,dtype=np.float,delimiter=None,skiprows=0,
usecols=None,unpack=False)
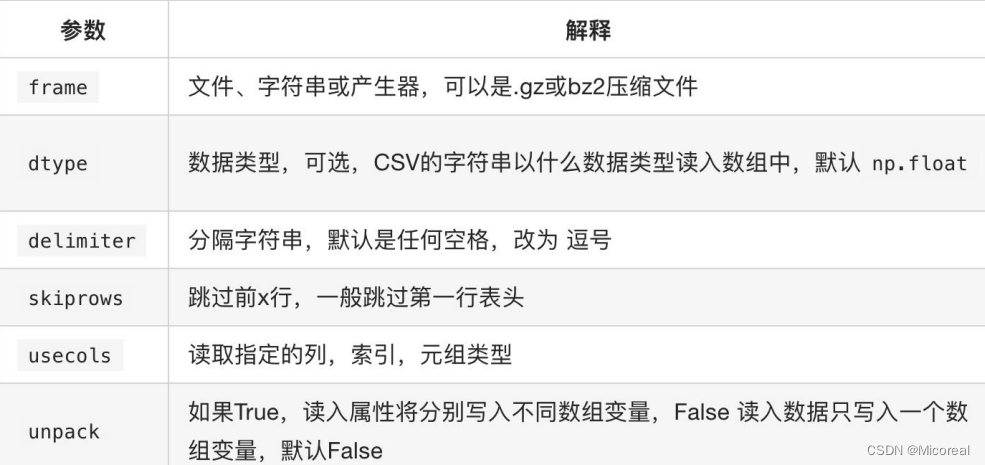
unpack就是转置,一般不要使用,这样子才是一个括号内,包含这个事物的所有特征
数据number.txt
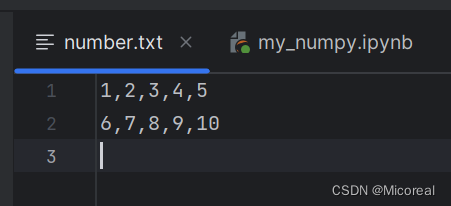
基础的读取数据(从txt当中读取):
number_path = './archive/number.txt'
# delimiter是分隔符,一般是unpack为false,一列为一个特征
t1 = np.loadtxt(number_path,delimiter=",",dtype="int",unpack=True,encoding='utf8')
t2 = np.loadtxt(number_path,delimiter=",",dtype="int",encoding='utf8')
print(t1)
print(t2)
输出:
[[ 1 6]
[ 2 7]
[ 3 8]
[ 4 9]
[ 5 10]]
[[ 1 2 3 4 5]
[ 6 7 8 9 10]]
有筛选的读取数据------从csv当中读取
数据:
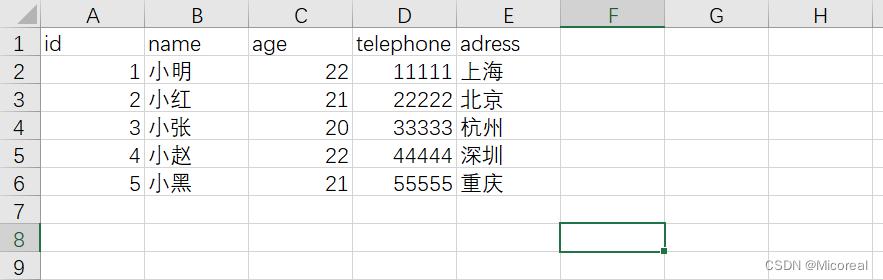
num_path = './archive/num.csv'
t_gb_video = np.loadtxt(num_path,dtype='int64',delimiter=',',skiprows=1,usecols=(0,2,3),encoding='utf8')
print(t_gb_video)
输出:
[[ 1 22 11111]
[ 2 21 22222]
[ 3 20 33333]
[ 4 22 44444]
[ 5 21 55555]]
np.random模块

array1 = np.random.rand(2,3)
print(array1)
print('-'*20)
array2 = np.random.randn(2,3)
print(array2)
print('-'*20)
array3 = np.random.randint(1,5,(2,3))
print(array3)
print('-'*20)
array4 = np.random.uniform(0.0,1.0,(2,3))
print(array4)
输出:
[[0.81889905 0.22799652 0.95090655]
[0.25433465 0.76184529 0.92012839]]
--------------------
[[-1.37504485 0.64581416 -1.25324539]
[ 0.22773263 -1.15448029 -0.51791998]]
--------------------
[[2 2 1]
[1 2 4]]
--------------------
[[6.47574634 4.56261091 1.04990935]
[7.38037415 4.28771509 1.83393943]]
--------------------
pandas
见32 数据分析(下):