Redis-集群

主从复制和哨兵只能在主节点进行写数据,从节点读取数据,因此本质上,是进行了读写的分离,每个节点都保存了所有的数据,并不能实现一个很好的分布式效果。
1.哈希求余算法
假设有N台主机,对每台主机进行编号[0,N-1]。当请求来的时候,通过hash(key)%N得到机器号,映射到相应的主机上,此种方式实现简单,但是也存在一些问题。如果我们对集群进行扩充,数据的迁移概率会很大。
2.一致性哈希算法
建立一个哈希环[0,231-1,每个节点负责环中的部分内容,hash(key)% 231计算得到哈希值,顺时针找到距离最近的一个节点。当我们对集群进行扩充时,只需要将部分数据迁移。
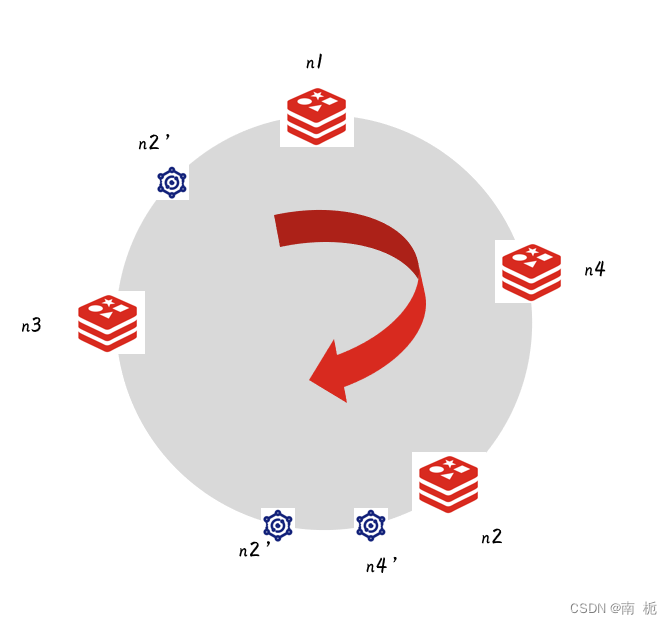
添加节点过程:

数据倾斜问题:新增的服务器n4只是减轻了n2节点的压力,但是n1节点和n3节点的压力没有变化,导致节点数据不均匀,造成部分服务器压力过大,为解决这个问题引入虚拟节点机制。
虚拟节点:从物理节点中虚拟出多个节点,不同的虚拟节点映射一个物理节点,然后统一的对数据迁移。
3.哈希槽算法
定义一个哈希槽,这些槽均匀的分给节点,每个节点持有一个分片(一部分槽位,可以是连续的也可以不是连续的),利用hash_slot = crc16(key)%16384计算key属于哪一个槽位,通过槽位映射到具体属于哪一个分片。
关于16384:在redis cluster中默认是有16384个槽位,槽位的编号是从[0,16384]
- 如果槽位定义过多,数据迁移成本会变高,而16384是相对好的选择。
- 节点之间通过心跳包进行通信,心跳包中包含了该节点持有的槽位,每个节点都会使用位图的数据结构来存储持有的槽位,一个比特位存储一个槽位,用0/1来区分当前分片是否持有该槽位,也就是只需要16484b = 2KB空间,如果偏大,在频繁的网络传输中,开销也不小。
3.1如何处理客户端请求
每个节点都会保存一份槽位映射表,这份映射表记录了每个槽位所对应的节点。当一个节点收到一个操作请求时,它首先会根据这个请求中的键值计算出这个键所对应的槽位,然后根据槽位映射表将这个操作发送到对应的节点上。
这种机制使得Redis集群中的每个节点都能够协同工作,共同维护集群中的数据一致性。即使在某个节点发生故障的情况下,其他节点也能够通过槽位映射表找到对应的节点,继续提供服务。
3.2扩容集群
增加节点是,集群会通过哈希槽分配策略将一些哈希槽分配给新节点,从而实现集群的扩容。