🍁一、链表的分类
🌕1.单向或者双向
🌕2.带头或者不带头(有无哨兵)
🌕3.循环或者不循环
🌕4.无头单向非循环链表(常用)
🌕5.带头双向循环链表(常用)
🌕注意:
1. 无头单向非循环链表: 结构简单 ,一般不会单独用来存数据。实际中更多是作为 其他数据结 构的子结构 ,如哈希桶、图的邻接表等等。另外这种结构在 笔试面试 中出现很多。2. 带头双向循环链表: 结构最复杂 ,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了,后面我们代码实现了就知道了。
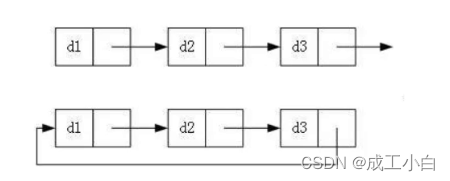


🍁二、双向链表的定义:
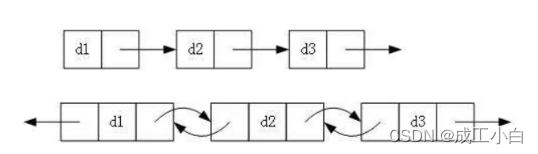
我们知道单链表的结点有一个数据域用于存放数据,一个指针域用于指向下一个结点。而 双向链表即是在此基础上每个结点多了一个指针域用于指向前一个结点;

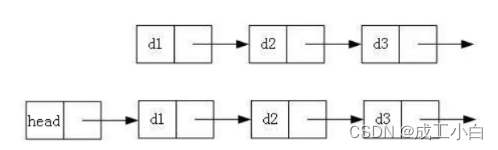
🍁三、带头双向循环链表的定义
带头双向循环链表:即在双向链表的基础上,尾结点的next域指向头结点,使之体现出一个循环的结构。

🍁四、带头双向循环链表操作实现(多文件)
🌕1.定义:
只需在单链表定义的基础上多一个指针域prve,用于指向前驱;
typedef int SLDataType; typedef struct ListNode { struct ListNode* prev;//指向前驱 struct ListNode* next;//指向后继 SLDataType data;//数据域 }ListNode;
🌕2.获得新结点
因为后续经常用到此函数,所以首先介绍。
操作很简单,用malloc函数生成即可
//获得新结点 ListNode* BuyLTNode(SLDataType x) { //用malloc函数动态生成即可 ListNode* node = (ListNode*)malloc(sizeof(ListNode)); if (node == NULL) { //检查malloc错误原因 perror("malloc"); exit(-1); } //处理新结点的成员 node->data = x; node->next = NULL; node->prev = NULL; return node; }
🌕3.初始化
①:原本初始化需要改变头结点phead,所以需要结构体二级指针,但其他操作都不需要二级指针,所以为了排面,我们可以用返回值来代替使用二级指针;
②:初始化只需要获得一个新结点作为一个头结点,然后头结点的两个指针域互相指向代表此时为空表;
//初始化 ListNode* Init() { //获得头结点,头结点数据域可以存点有意义的数据,也可以随便存,因为用不着 ListNode* phead = BuyLTNode(0); //初始化头结点的两个指针域指向头结点本身表示为空表 phead->next = phead; phead->prev = phead; return phead; }
🌕4.尾插法
该种类链表虽然结构复杂,但操作却非常简单,比如尾插法就有几点优势于单链表;
2.1:优势
①:单链表尾插需要考虑元素是否为空,当链表中没有元素时会改变头指针(头结点),所以需要使用结构体二级指针;但带头双向循环链表因为带有头,所以不管有无元素,在尾插时只需改变结构体指针域,即改变结构体,所以都只需要使用结构体指针;
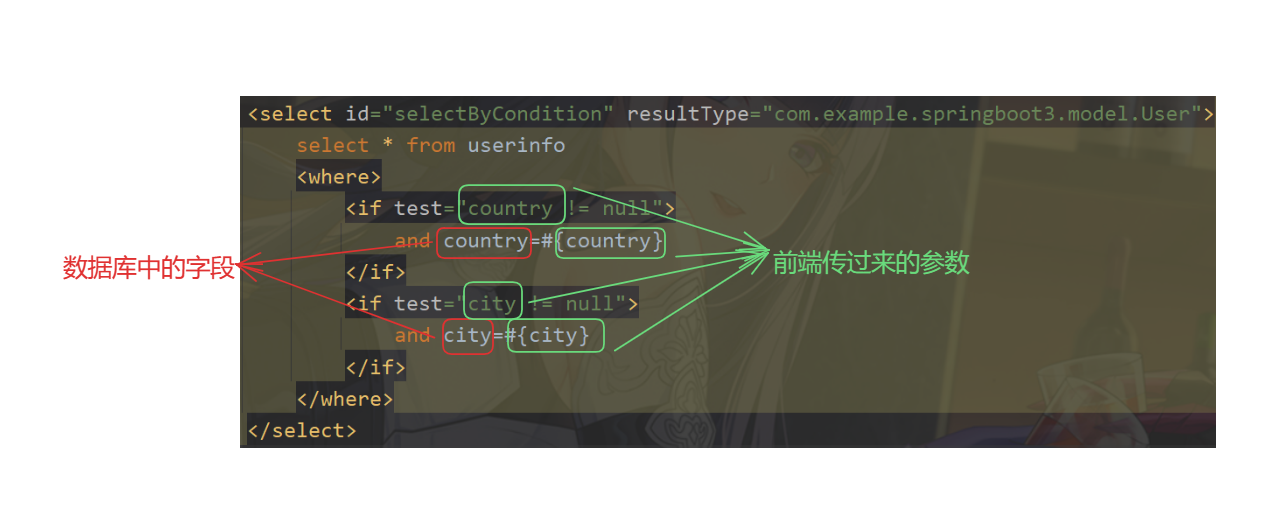
②:单链表尾插时需要找到尾结点,但带头双向循环链表不需要,因为多了一个prev指针域,头结点的prev域就是尾结点;可以参考上述图片;
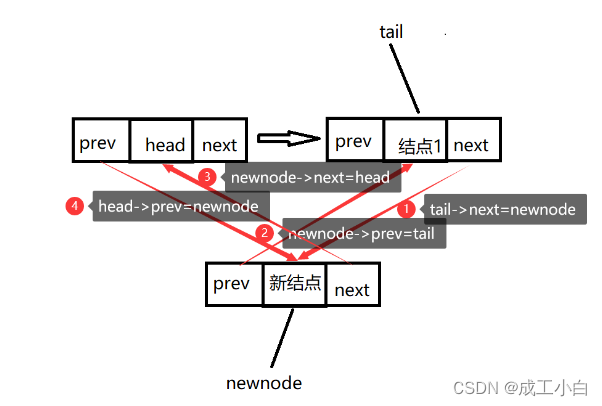
2.2:尾插法大致分为“四步骤”:
首先创建一个临时指针tail指向头结点的prev域,即指向尾结点便于操作
①:将tail的next域指向新结点;
②:将新结点的prev域指向tail结点(尾结点);
③:将新结点的next域指向头结点;
④:将头结点的prev域指向新结点。
2.3:源代码
//尾插 //因为带有头,所以操作只需要改变结构体,所以只需要结构体指针 //具体操作看注释 void LTPushBack(ListNode* phead, SLDataType x) { //因为是带头的,所以phead至少是个头指针,所以phead不可能为空,所以需要用assert检查一下 assert(phead); //找到尾结点tail ListNode* tail = phead->prev; //获取新结点newnode ListNode* newnode = BuyLTNode(x); //四步骤 tail->next = newnode; newnode->prev = tail; phead->prev = newnode; newnode->next = phead; }
🌕5.打印数据
此链表打印数据与单链表有一个区别,就是结束条件不同;因为带头双向循环链表的尾结点的next域不指向NULL,而是指向头结点,所以结束条件为“tail==head”;
//打印 void LTprint(ListNode* phead) { //创建一个临时指针便于遍历操作 ListNode* node = phead->next; //为了体现此链表结构而打印 printf("phead<->"); //打印数据,当临时指针node等于头结点时结束 while (node != phead) { printf("%d<->", node->data); node = node->next; } //为了体现此链表结构而打印 printf("phead\n"); }
🌕6.尾删法
6.1:相对于单链表,该链表也有几个优点:
①:尾删不用找尾结点以及倒数第二个结点,用prev域就可以找到;
②:当表中只有一个元素时,单链表需要改变结构体指针,所以需要单独分类;而此链表因为有带头结点和prev域,所以用正常尾删方法即可;
6.2:尾删步骤:
①:判断单链表是否为空(条件:phead->next=phead时即为空);
②:创建一个临时指针tail1用于保存尾结点,方便后续释放尾结点;
③:创建一个临时指针tail2用于保存尾结点的prev域(尾结点的前一个结点),方便进行尾删操作;
④:tail2的next域指向头结点:tail2->next=phead;
⑤:头结点的prev域指向tail2结点:phead->prev=tail2;
⑥:释放尾结点tail1。
6.3:源代码:
//尾删 void LTPopBack(ListNode* phead) { assert(phead); //检查是否为空 if (phead->next == phead) { printf("此链表为空,尾删失败!\n"); return; } //临时指针保存结点 ListNode* tail1 = phead->prev; ListNode* tail2 = phead->prev->prev; //断开与尾结点的链接 tail2->next = phead; phead->prev = tail2; //释放尾结点 free(tail1); }
🌕7.头插法
同上,因为prev的存在,所以不用考虑初始表是否为空表的情况;
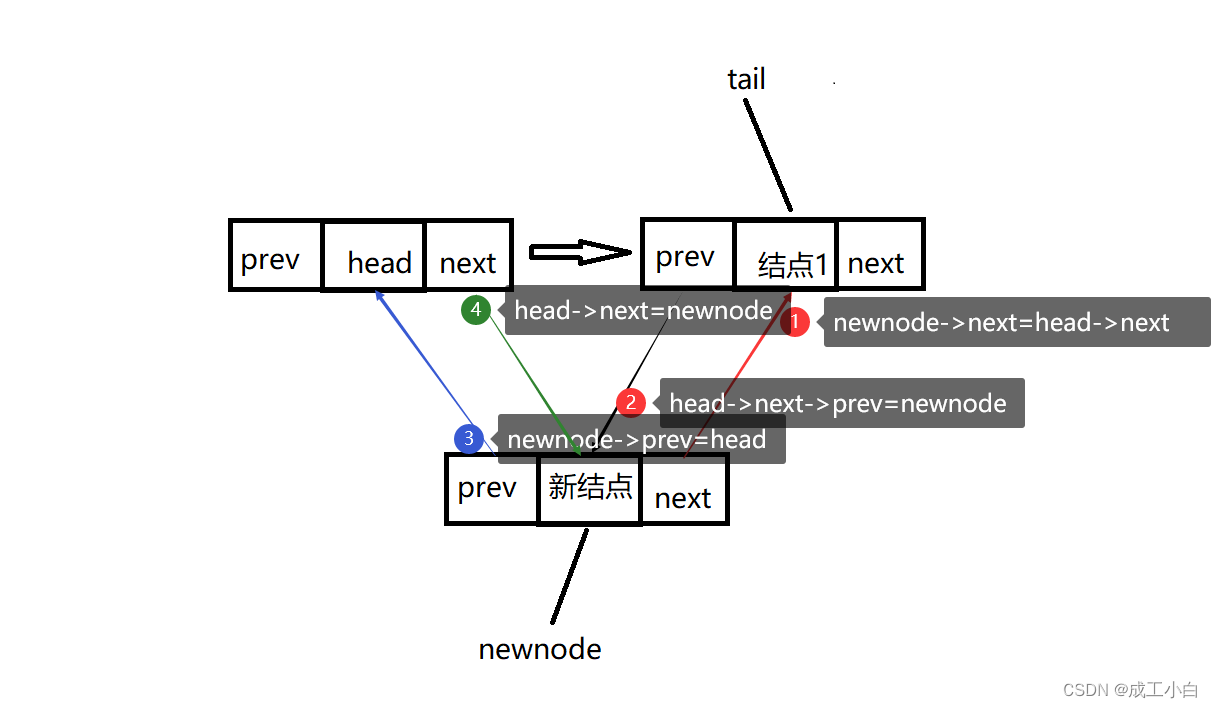
7.1:四步骤:
①:新结点的next域指向head的next域(即指向插入前的首结点);
②:head的next域的prev域指向新结点(即插入前的首结点的prev域指向新结点);
③:新结点的prev域指向头结点head;
④:头结点head的next域指向新结点。
7.2:源代码
//头插 void LTPushFront(ListNode* phead, SLDataType x) { assert(phead); //新结点 ListNode* newnode = BuyLTNode(x); //四步骤 newnode->next = phead->next; phead->next->prev = newnode; newnode->prev = phead; phead->next = newnode; }
🌕8.头删法
头删法也很简单,只需考虑个个指针的链接即可;
8.1:步骤
①:创建临时指针first指向首结点,便于后续释放首结点;
②:创建临时指针second指向第二个结点,便于进行删除操作;
③:改变指针链接:
second->prev = phead;
phead->next = second;
④:释放首结点;
8.2:源代码
//头删 void LTPopFront(ListNode* phead) { assert(phead); if (phead->next == phead) { printf("链表为空,头删失败!\n"); return; } //临时指针first指向首结点,便于后续释放首结点 //临时指针second指向第二个结点,便于进行删除操作 ListNode* first = phead->next; ListNode* second = first->next; //删除 second->prev = phead; phead->next = second; //释放首结点 free(first); }
🌕9.在pos位置之前插入结点
其实很简单,只需要搞得指针域的链接顺序,防止指针丢失即可
9.1:源代码如下:
//在pos位置之前插入结点 ListNode* LTInsrt(ListNode* pos, SLDataType x) { assert(pos); //新结点 ListNode* newnode = BuyLTNode(x); //插入 pos->prev->next = newnode; newnode->prev = pos->prev; newnode->next = pos; pos->prev = newnode; }9.2:有了这个算法后我们可以改进头插与尾插:
①:当pos==phead->next时,即为头插算法:
//头插 void LTPushFront(ListNode* phead, SLDataType x) { assert(phead); //改进 LTInsrt(phead->next, x); }②:当pos等于phead时,即为尾插算法:
//尾插 void LTPushBack(ListNode* phead, SLDataType x) { //因为是带头的,所以phead至少是个头指针,所以phead不可能为空,所以需要用assert检查一下 assert(phead); //改进 LTInsrt(phead, x); }
🌕10.删除pos位置的结点
10.1:步骤:
①:创建临时指针first保存pos前一个结点;
②:创建临时指针second保存pos后一个结点;
③:改变指针链接,删除pos结点:
first->next = second;
second->prev = first;
④:释放pos结点。
10.2:源代码
//删除pos位置的结点 void LTErase(ListNode* pos) { assert(pos); //临时指针 ListNode* first = pos->prev; ListNode* second = pos->next; //删除 first->next = second; second->prev = first; //释放pos free(pos); }10.3:有了这个算法,我们可以改进头删与尾删
①:当pos==phead->next时,即为头删算法:
//头删 void LTPopFront(ListNode* phead) { assert(phead); //改进 LTErase(phead->next); }②:当pos==phead->prev时,即为尾删算法:
//尾删 void LTPopBack(ListNode* phead) { assert(phead); //改进 LTErase(phead->prev); }
🍁五、测试源代码
main.c
#include"List.h" void STTest1() { ListNode* plist = NULL; plist = Init();//初始化 //尾插 LTPushBack(plist, 1); LTPushBack(plist, 2); LTPushBack(plist, 3); LTPushBack(plist, 4); LTPushBack(plist, 5); //打印 LTprint(plist); } void STTest2() { ListNode* plist = NULL; plist = Init();//初始化 //尾插 LTPushBack(plist, 1); //打印 LTprint(plist); //尾删 LTPopBack(plist); //打印 LTprint(plist); } void STTest3() { ListNode* plist = NULL; plist = Init();//初始化 //头插 LTPushFront(plist, 1); LTPushFront(plist, 2); //打印 LTprint(plist); //头删 LTPopFront(plist); //打印 LTprint(plist); //头删 LTPopFront(plist); //打印 LTprint(plist); } int main() { //STTest1(); //STTest2(); STTest3(); return 0; }List.c
#include"List.h" //获得新结点 ListNode* BuyLTNode(SLDataType x) { //用malloc函数动态生成即可 ListNode* node = (ListNode*)malloc(sizeof(ListNode)); if (node == NULL) { //检查malloc错误原因 perror("malloc"); exit(-1); } //处理新结点的成员 node->data = x; node->next = NULL; node->prev = NULL; return node; } //初始化 ListNode* Init() { //获得头结点,头结点数据域可以存点有意义的数据,也可以随便存,因为用不着 ListNode* phead = BuyLTNode(0); //初始化头结点的两个指针域指向头结点本身表示为空表 phead->next = phead; phead->prev = phead; return phead; } //打印 void LTprint(ListNode* phead) { assert(phead); //创建一个临时指针便于遍历操作 ListNode* node = phead->next; //为了体现此链表结构而打印 printf("phead<->"); //打印数据,当临时指针node等于头结点时结束 while (node != phead) { printf("%d<->", node->data); node = node->next; } //为了体现此链表结构而打印 printf("phead\n"); } //尾插 //因为带有头,所以操作只需要改变结构体,所以只需要结构体指针 //具体操作看注释 void LTPushBack(ListNode* phead, SLDataType x) { //因为是带头的,所以phead至少是个头指针,所以phead不可能为空,所以需要用assert检查一下 assert(phead); 找到尾结点tail //ListNode* tail = phead->prev; 获取新结点newnode //ListNode* newnode = BuyLTNode(x); 四步骤 //tail->next = newnode; //newnode->prev = tail; //phead->prev = newnode; //newnode->next = phead; //改进 LTInsrt(phead, x); } //尾删 void LTPopBack(ListNode* phead) { assert(phead); 检查是否为空 //if (phead->next == phead) //{ // printf("此链表为空,尾删失败!\n"); // return; //} 临时指针保存结点 //ListNode* tail1 = phead->prev; //ListNode* tail2 = phead->prev->prev; 断开与尾结点的链接 //tail2->next = phead; //phead->prev = tail2; 释放尾结点 //free(tail1); //改进 LTErase(phead->prev); } //头插 void LTPushFront(ListNode* phead, SLDataType x) { assert(phead); //新结点 //ListNode* newnode = BuyLTNode(x); 四步骤 //newnode->next = phead->next; //phead->next->prev = newnode; //newnode->prev = phead; //phead->next = newnode; //改进 LTInsrt(phead->next, x); } //头删 void LTPopFront(ListNode* phead) { assert(phead); /*if (phead->next == phead) { printf("链表为空,头删失败!\n"); return; }*/ 临时指针first指向首结点,便于后续释放首结点 临时指针second指向第二个结点,便于进行删除操作 //ListNode* first = phead->next; //ListNode* second = first->next; 删除 //second->prev = phead; //phead->next = second; 释放首结点 //free(first); //改进 LTErase(phead->next); } //在pos位置之前插入结点 void LTInsrt(ListNode* pos, SLDataType x) { assert(pos); //新结点 ListNode* newnode = BuyLTNode(x); //插入 pos->prev->next = newnode; newnode->prev = pos->prev; newnode->next = pos; pos->prev = newnode; } //删除pos位置的结点 void LTErase(ListNode* pos) { assert(pos); //临时指针 ListNode* first = pos->prev; ListNode* second = pos->next; //删除 first->next = second; second->prev = first; //释放pos free(pos); }List.h
#pragma once #define _CRT_SECURE_NO_WARNINGS 1 #include<stdio.h> #include<stdlib.h> #include<assert.h> typedef int SLDataType; typedef struct ListNode { struct ListNode* prev;//指向前驱 struct ListNode* next;//指向后继 SLDataType data;//数据域 }ListNode; //获得一个新结点 ListNode* BuyLTNode(SLDataType x); //初始化 ListNode* Init(); //打印 void LTprint(ListNode* phead); //尾插 void LTPushBack(ListNode* phead,SLDataType x); //尾删 void LTPopBack(ListNode* phead); //头插 void LTPushFront(ListNode* phead, SLDataType x); //头删 void LTPopFront(ListNode* phead); //在pos位置之前插入结点 void LTInsrt(ListNode* pos, SLDataType x); //删除pos位置的结点 void LTErase(ListNode* pos);
本次知识到此结束,希望对你有所帮助!