ChatGLM2-6B微调实践
- 环境准备
- 安装部署
- 1、安装 Anaconda
- 2、安装CUDA
- 3、安装PyTorch
- 4、安装 ChatGLM2-6B
- 微调实践
- 1、准备数据集
- 2、安装python依赖
- 3、微调并训练新模型
- 4、微调后模型的推理与评估
- 5、验证与评估微调后的模型
- 6、微调模型优化
- 7、P-Tuning微调灾难性遗忘问题
- 微调过程中遇到的问题
环境准备
申请阿里云GPU服务器:
- CentOS 7.6 64
- Anaconda3-2023.07-1-Linux-x86_64
- Python 3.11.5
- GPU NVIDIA A10(显存24 G/1 core)
- CPU 8 vCore/30G

安装部署
1、安装 Anaconda
wget https://repo.anaconda.com/archive/Anaconda3-2023.07-1-Linux-x86_64.sh
sh Anaconda3-2023.07-1-Linux-x86_64.sh
根据提示一路安装即可。
2、安装CUDA
wget https://developer.download.nvidia.com/compute/cuda/11.2.0/local_installers/cuda_11.2.0_460.27.04_linux.run
sh cuda_11.2.0_460.27.04_linux.run
根据提示安装即可
3、安装PyTorch
conda install pytorch torchvision pytorch-cuda=11.8 -c pytorch -c nvidia
如提示找不到conda命令,需配置Anaconda环境变量。
4、安装 ChatGLM2-6B
mkdir ChatGLM
cd ChatGLM
git clone https://github.com/THUDM/ChatGLM2-6B.git
cd ChatGLM2-6B
pip install -r requirements.txt
加载模型,需要从网上下载模型的7个分片文件,总共大约10几个G大小,可提前下载。
模型下载地址:https://huggingface.co/THUDM/chatglm2-6b/tree/main
微调实践
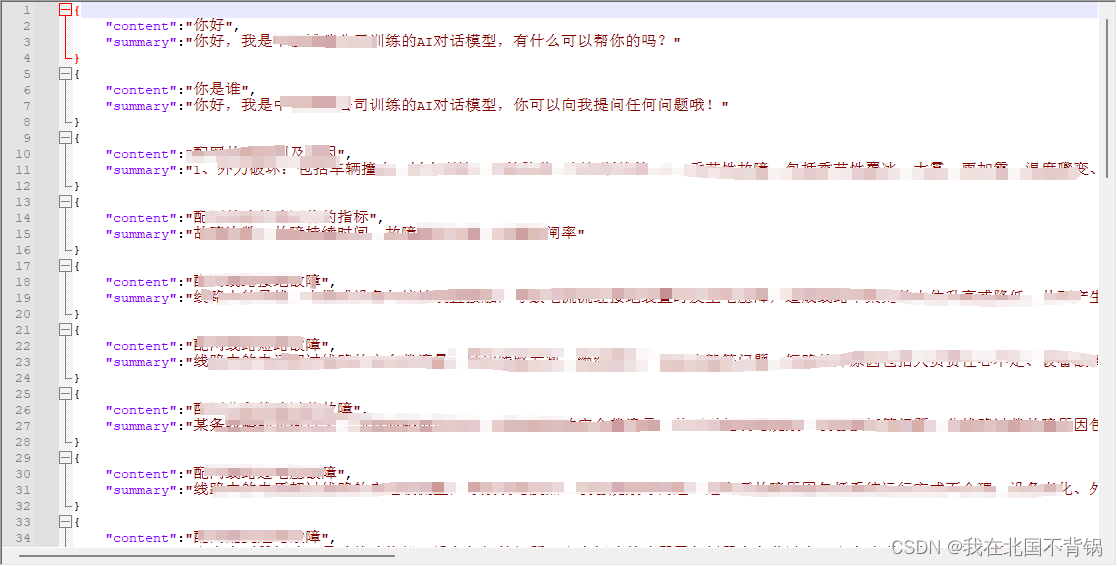
1、准备数据集
准备我们自己的数据集,分别生成训练文件和测试文件这两个文件,放在目录 ChatGLM2-6B/ptuning/myDataset/ 下面。
训练集文件: train.json
测试集文件: dev.json
2、安装python依赖
后面微调训练,需要依赖一些 Python 模块,提前安装一下:
conda install rouge_chinese nltk jieba datasets
3、微调并训练新模型
修改 train.sh 脚本文件,根据自己实际情况配置即可,修改后的配置为:
PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_train \
--train_file myDataset/train.json \
--validation_file myDataset/dev.json \
--preprocessing_num_workers 6 \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b \
--output_dir output/zhbr-chatglm2-6b-checkpoint \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 128 \
--per_device_train_batch_size 6 \
--per_device_eval_batch_size 6 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 20 \
--logging_steps 5 \
--save_steps 5 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
修改完即可进行微调:
cd /root/ChatGLM/ChatGLM2-6B/ptuning/
sh train.sh
运行结果如下:
(base) [root@iZbp178u8rw9n9ko94ubbyZ ptuning]# sh train.sh
[2023-10-08 13:09:12,312] torch.distributed.run: [WARNING] master_addr is only used for static rdzv_backend and when rdzv_endpoint is not specified.
10/08/2023 13:09:15 - WARNING - __main__ - Process rank: 0, device: cuda:0, n_gpu: 1distributed training: True, 16-bits training: False
10/08/2023 13:09:15 - INFO - __main__ - Training/evaluation parameters Seq2SeqTrainingArguments(
_n_gpu=1,
adafactor=False,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-08,
auto_find_batch_size=False,
bf16=False,
bf16_full_eval=False,
data_seed=None,
dataloader_drop_last=False,
dataloader_num_workers=0,
dataloader_pin_memory=True,
ddp_backend=None,
ddp_broadcast_buffers=None,
ddp_bucket_cap_mb=None,
ddp_find_unused_parameters=None,
ddp_timeout=1800,
debug=[],
deepspeed=None,
disable_tqdm=False,
dispatch_batches=None,
do_eval=False,
do_predict=False,
do_train=True,
eval_accumulation_steps=None,
eval_delay=0,
eval_steps=None,
evaluation_strategy=IntervalStrategy.NO,
fp16=False,
fp16_backend=auto,
fp16_full_eval=False,
fp16_opt_level=O1,
fsdp=[],
fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_grad_ckpt': False},
fsdp_min_num_params=0,
fsdp_transformer_layer_cls_to_wrap=None,
full_determinism=False,
generation_config=None,
generation_max_length=None,
generation_num_beams=None,
gradient_accumulation_steps=16,
gradient_checkpointing=False,
greater_is_better=None,
group_by_length=False,
half_precision_backend=auto,
hub_always_push=False,
hub_model_id=None,
hub_private_repo=False,
hub_strategy=HubStrategy.EVERY_SAVE,
hub_token=<HUB_TOKEN>,
ignore_data_skip=False,
include_inputs_for_metrics=False,
jit_mode_eval=False,
label_names=None,
label_smoothing_factor=0.0,
learning_rate=0.02,
length_column_name=length,
load_best_model_at_end=False,
local_rank=0,
log_level=passive,
log_level_replica=warning,
log_on_each_node=True,
logging_dir=output/zhbr-chatglm2-6b-checkpoint/runs/Oct08_13-09-15_iZbp178u8rw9n9ko94ubbyZ,
logging_first_step=False,
logging_nan_inf_filter=True,
logging_steps=5,
logging_strategy=IntervalStrategy.STEPS,
lr_scheduler_type=SchedulerType.LINEAR,
max_grad_norm=1.0,
max_steps=20,
metric_for_best_model=None,
mp_parameters=,
no_cuda=False,
num_train_epochs=3.0,
optim=OptimizerNames.ADAMW_TORCH,
optim_args=None,
output_dir=output/zhbr-chatglm2-6b-checkpoint,
overwrite_output_dir=True,
past_index=-1,
per_device_eval_batch_size=6,
per_device_train_batch_size=6,
predict_with_generate=True,
prediction_loss_only=False,
push_to_hub=False,
push_to_hub_model_id=None,
push_to_hub_organization=None,
push_to_hub_token=<PUSH_TO_HUB_TOKEN>,
ray_scope=last,
remove_unused_columns=True,
report_to=[],
resume_from_checkpoint=None,
run_name=output/zhbr-chatglm2-6b-checkpoint,
save_on_each_node=False,
save_safetensors=False,
save_steps=5,
save_strategy=IntervalStrategy.STEPS,
save_total_limit=None,
seed=42,
sharded_ddp=[],
skip_memory_metrics=True,
sortish_sampler=False,
tf32=None,
torch_compile=False,
torch_compile_backend=None,
torch_compile_mode=None,
torchdynamo=None,
tpu_metrics_debug=False,
tpu_num_cores=None,
use_cpu=False,
use_ipex=False,
use_legacy_prediction_loop=False,
use_mps_device=False,
warmup_ratio=0.0,
warmup_steps=0,
weight_decay=0.0,
)
10/08/2023 13:09:16 - WARNING - datasets.builder - Found cached dataset json (/root/.cache/huggingface/datasets/json/default-8e52c57dfec9ef61/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4)
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 1379.71it/s]
[INFO|configuration_utils.py:713] 2023-10-08 13:09:16,749 >> loading configuration file /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b/config.json
[INFO|configuration_utils.py:713] 2023-10-08 13:09:16,751 >> loading configuration file /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b/config.json
[INFO|configuration_utils.py:775] 2023-10-08 13:09:16,751 >> Model config ChatGLMConfig {
"_name_or_path": "/root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b",
"add_bias_linear": false,
"add_qkv_bias": true,
"apply_query_key_layer_scaling": true,
"apply_residual_connection_post_layernorm": false,
"architectures": [
"ChatGLMModel"
],
"attention_dropout": 0.0,
"attention_softmax_in_fp32": true,
"auto_map": {
"AutoConfig": "configuration_chatglm.ChatGLMConfig",
"AutoModel": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForCausalLM": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForSeq2SeqLM": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForSequenceClassification": "modeling_chatglm.ChatGLMForSequenceClassification"
},
"bias_dropout_fusion": true,
"classifier_dropout": null,
"eos_token_id": 2,
"ffn_hidden_size": 13696,
"fp32_residual_connection": false,
"hidden_dropout": 0.0,
"hidden_size": 4096,
"kv_channels": 128,
"layernorm_epsilon": 1e-05,
"model_type": "chatglm",
"multi_query_attention": true,
"multi_query_group_num": 2,
"num_attention_heads": 32,
"num_layers": 28,
"original_rope": true,
"pad_token_id": 0,
"padded_vocab_size": 65024,
"post_layer_norm": true,
"pre_seq_len": null,
"prefix_projection": false,
"quantization_bit": 0,
"rmsnorm": true,
"seq_length": 32768,
"tie_word_embeddings": false,
"torch_dtype": "float16",
"transformers_version": "4.32.1",
"use_cache": true,
"vocab_size": 65024
}
[INFO|tokenization_utils_base.py:1850] 2023-10-08 13:09:16,752 >> loading file tokenizer.model
[INFO|tokenization_utils_base.py:1850] 2023-10-08 13:09:16,752 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:1850] 2023-10-08 13:09:16,752 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:1850] 2023-10-08 13:09:16,753 >> loading file tokenizer_config.json
[INFO|modeling_utils.py:2776] 2023-10-08 13:09:16,832 >> loading weights file /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b/pytorch_model.bin.index.json
[INFO|configuration_utils.py:768] 2023-10-08 13:09:16,833 >> Generate config GenerationConfig {
"_from_model_config": true,
"eos_token_id": 2,
"pad_token_id": 0,
"transformers_version": "4.32.1"
}
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:05<00:00, 1.39it/s]
[INFO|modeling_utils.py:3551] 2023-10-08 13:09:21,906 >> All model checkpoint weights were used when initializing ChatGLMForConditionalGeneration.
[WARNING|modeling_utils.py:3553] 2023-10-08 13:09:21,906 >> Some weights of ChatGLMForConditionalGeneration were not initialized from the model checkpoint at /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b and are newly initialized: ['transformer.prefix_encoder.embedding.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
[INFO|modeling_utils.py:3136] 2023-10-08 13:09:21,908 >> Generation config file not found, using a generation config created from the model config.
Quantized to 4 bit
input_ids [64790, 64792, 790, 30951, 517, 30910, 30939, 30996, 13, 13, 54761, 31211, 55046, 54766, 36989, 38724, 54643, 31962, 13, 13, 55437, 31211, 30910, 30939, 31201, 54675, 54592, 33933, 31211, 31779, 32804, 51962, 31201, 39510, 57517, 56689, 31201, 48981, 57486, 55014, 31201, 55568, 56528, 55082, 54831, 54609, 54659, 30943, 31201, 35066, 54642, 36989, 31211, 31779, 35066, 54642, 56042, 55662, 31201, 54539, 56827, 31201, 55422, 54639, 55534, 31201, 33576, 57062, 54848, 31201, 55662, 55816, 41670, 39305, 33760, 36989, 54659, 30966, 31201, 32531, 31838, 54643, 31668, 31687, 31211, 31779, 32531, 31838, 33853, 31201, 32077, 43641, 31201, 54933, 55194, 32366, 32531, 49729, 39305, 33760, 36989, 54659, 30972, 31201, 31641, 48655, 31211, 31779, 36293, 54535, 32155, 31201, 45561, 54585, 31940, 54535, 32155, 31201, 54962, 55478, 54535, 32155, 54609, 31641, 31746, 31639, 31123, 32023, 54603, 36989, 55045, 58286, 49539, 31639, 31123, 36128, 33423, 32077, 36989, 31155, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
inputs [Round 1]
问:配网故障类别及原因
答: 1、外力破坏:包括车辆撞击、树木刮擦、风筝坠落、倒杆断线等;2、季节性故障:包括季节性覆冰、大雾、雨加雪、温度骤变、冰灾等因素导致的线路故障;3、施工质量及技术方面:包括施工质量不良、设备老化、未按规范施工等原因导致的线路故障;4、管理不到位:包括巡视不及时、发现问题后处理不及时、消缺不及时等管理上的问题,导致小故障积攒成大问题,进而引发设备故障。
label_ids [-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, 30910, 30939, 31201, 54675, 54592, 33933, 31211, 31779, 32804, 51962, 31201, 39510, 57517, 56689, 31201, 48981, 57486, 55014, 31201, 55568, 56528, 55082, 54831, 54609, 54659, 30943, 31201, 35066, 54642, 36989, 31211, 31779, 35066, 54642, 56042, 55662, 31201, 54539, 56827, 31201, 55422, 54639, 55534, 31201, 33576, 57062, 54848, 31201, 55662, 55816, 41670, 39305, 33760, 36989, 54659, 30966, 31201, 32531, 31838, 54643, 31668, 31687, 31211, 31779, 32531, 31838, 33853, 31201, 32077, 43641, 31201, 54933, 55194, 32366, 32531, 49729, 39305, 33760, 36989, 54659, 30972, 31201, 31641, 48655, 31211, 31779, 36293, 54535, 32155, 31201, 45561, 54585, 31940, 54535, 32155, 31201, 54962, 55478, 54535, 32155, 54609, 31641, 31746, 31639, 31123, 32023, 54603, 36989, 55045, 58286, 49539, 31639, 31123, 36128, 33423, 32077, 36989, 31155, 2, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100]
labels 1、外力破坏:包括车辆撞击、树木刮擦、风筝坠落、倒杆断线等;2、季节性故障:包括季节性覆冰、大雾、雨加雪、温度骤变、冰灾等因素导致的线路故障;3、施工质量及技术方面:包括施工质量不良、设备老化、未按规范施工等原因导致的线路故障;4、管理不到位:包括巡视不及时、发现问题后处理不及时、消缺不及时等管理上的问题,导致小故障积攒成大问题,进而引发设备故障。
[INFO|trainer.py:565] 2023-10-08 13:09:26,290 >> max_steps is given, it will override any value given in num_train_epochs
[INFO|trainer.py:1714] 2023-10-08 13:09:26,460 >> ***** Running training *****
[INFO|trainer.py:1715] 2023-10-08 13:09:26,460 >> Num examples = 17
[INFO|trainer.py:1716] 2023-10-08 13:09:26,460 >> Num Epochs = 20
[INFO|trainer.py:1717] 2023-10-08 13:09:26,460 >> Instantaneous batch size per device = 6
[INFO|trainer.py:1720] 2023-10-08 13:09:26,460 >> Total train batch size (w. parallel, distributed & accumulation) = 96
[INFO|trainer.py:1721] 2023-10-08 13:09:26,460 >> Gradient Accumulation steps = 16
[INFO|trainer.py:1722] 2023-10-08 13:09:26,460 >> Total optimization steps = 20
[INFO|trainer.py:1723] 2023-10-08 13:09:26,460 >> Number of trainable parameters = 1,835,008
0%| | 0/20 [00:00<?, ?it/s]10/08/2023 13:09:26 - WARNING - transformers_modules.chatglm2-6b.modeling_chatglm - `use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...
/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.5058, 'learning_rate': 0.015, 'epoch': 5.0}
25%|██████████████████████████████████████████████▎ | 5/20 [00:21<00:56, 3.77s/it]Saving PrefixEncoder
[INFO|configuration_utils.py:460] 2023-10-08 13:09:47,797 >> Configuration saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-5/config.json
[INFO|configuration_utils.py:544] 2023-10-08 13:09:47,797 >> Configuration saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-5/generation_config.json
[INFO|modeling_utils.py:1953] 2023-10-08 13:09:47,805 >> Model weights saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-5/pytorch_model.bin
[INFO|tokenization_utils_base.py:2235] 2023-10-08 13:09:47,805 >> tokenizer config file saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-5/tokenizer_config.json
[INFO|tokenization_utils_base.py:2242] 2023-10-08 13:09:47,807 >> Special tokens file saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-5/special_tokens_map.json
/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.2925, 'learning_rate': 0.01, 'epoch': 9.0}
50%|████████████████████████████████████████████████████████████████████████████████████████████ | 10/20 [00:34<00:31, 3.17s/it]Saving PrefixEncoder
[INFO|configuration_utils.py:460] 2023-10-08 13:10:01,413 >> Configuration saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-10/config.json
[INFO|configuration_utils.py:544] 2023-10-08 13:10:01,413 >> Configuration saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-10/generation_config.json
[INFO|modeling_utils.py:1953] 2023-10-08 13:10:01,419 >> Model weights saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-10/pytorch_model.bin
[INFO|tokenization_utils_base.py:2235] 2023-10-08 13:10:01,420 >> tokenizer config file saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-10/tokenizer_config.json
[INFO|tokenization_utils_base.py:2242] 2023-10-08 13:10:01,420 >> Special tokens file saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-10/special_tokens_map.json
/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.2593, 'learning_rate': 0.005, 'epoch': 13.0}
75%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ | 15/20 [00:48<00:14, 2.93s/it]Saving PrefixEncoder
[INFO|configuration_utils.py:460] 2023-10-08 13:10:15,139 >> Configuration saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-15/config.json
[INFO|configuration_utils.py:544] 2023-10-08 13:10:15,139 >> Configuration saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-15/generation_config.json
[INFO|modeling_utils.py:1953] 2023-10-08 13:10:15,146 >> Model weights saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-15/pytorch_model.bin
[INFO|tokenization_utils_base.py:2235] 2023-10-08 13:10:15,146 >> tokenizer config file saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-15/tokenizer_config.json
[INFO|tokenization_utils_base.py:2242] 2023-10-08 13:10:15,146 >> Special tokens file saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-15/special_tokens_map.json
/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.3026, 'learning_rate': 0.0, 'epoch': 18.0}
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 20/20 [01:05<00:00, 3.35s/it]Saving PrefixEncoder
[INFO|configuration_utils.py:460] 2023-10-08 13:10:32,333 >> Configuration saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-20/config.json
[INFO|configuration_utils.py:544] 2023-10-08 13:10:32,333 >> Configuration saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-20/generation_config.json
[INFO|modeling_utils.py:1953] 2023-10-08 13:10:32,340 >> Model weights saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-20/pytorch_model.bin
[INFO|tokenization_utils_base.py:2235] 2023-10-08 13:10:32,340 >> tokenizer config file saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-20/tokenizer_config.json
[INFO|tokenization_utils_base.py:2242] 2023-10-08 13:10:32,340 >> Special tokens file saved in output/zhbr-chatglm2-6b-checkpoint/checkpoint-20/special_tokens_map.json
[INFO|trainer.py:1962] 2023-10-08 13:10:32,354 >>
Training completed. Do not forget to share your model on huggingface.co/models =)
{'train_runtime': 65.8941, 'train_samples_per_second': 29.138, 'train_steps_per_second': 0.304, 'train_loss': 0.3400604248046875, 'epoch': 18.0}
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 20/20 [01:05<00:00, 3.29s/it]
***** train metrics *****
epoch = 18.0
train_loss = 0.3401
train_runtime = 0:01:05.89
train_samples = 17
train_samples_per_second = 29.138
train_steps_per_second = 0.304
4、微调后模型的推理与评估
对微调后的模型进行评估验证,修改 evaluate.sh 脚本中的 checkpoint 目录:
PRE_SEQ_LEN=128
CHECKPOINT=zhbr-chatglm2-6b-checkpoint
STEP=20
NUM_GPUS=1
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_predict \
--validation_file myDataset/train.json \
--test_file myDataset/dev.json \
--overwrite_cache \
--prompt_column content \
--response_column summary \
--model_name_or_path /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b \
--ptuning_checkpoint ./output/$CHECKPOINT/checkpoint-$STEP \
--output_dir ./output/$CHECKPOINT \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_eval_batch_size 1 \
--predict_with_generate \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
对微调后的模型进行推理和评估:
/root/ChatGLM/ChatGLM2-6B/ptuning/
sh evaluate.sh
运行结果如下:
(base) [root@iZbp178u8rw9n9ko94ubbyZ ptuning]# sh evaluate.sh
[2023-10-08 13:19:53,448] torch.distributed.run: [WARNING] master_addr is only used for static rdzv_backend and when rdzv_endpoint is not specified.
10/08/2023 13:19:56 - WARNING - __main__ - Process rank: 0, device: cuda:0, n_gpu: 1distributed training: True, 16-bits training: False
10/08/2023 13:19:56 - INFO - __main__ - Training/evaluation parameters Seq2SeqTrainingArguments(
_n_gpu=1,
adafactor=False,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-08,
auto_find_batch_size=False,
bf16=False,
bf16_full_eval=False,
data_seed=None,
dataloader_drop_last=False,
dataloader_num_workers=0,
dataloader_pin_memory=True,
ddp_backend=None,
ddp_broadcast_buffers=None,
ddp_bucket_cap_mb=None,
ddp_find_unused_parameters=None,
ddp_timeout=1800,
debug=[],
deepspeed=None,
disable_tqdm=False,
dispatch_batches=None,
do_eval=False,
do_predict=True,
do_train=False,
eval_accumulation_steps=None,
eval_delay=0,
eval_steps=None,
evaluation_strategy=IntervalStrategy.NO,
fp16=False,
fp16_backend=auto,
fp16_full_eval=False,
fp16_opt_level=O1,
fsdp=[],
fsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_grad_ckpt': False},
fsdp_min_num_params=0,
fsdp_transformer_layer_cls_to_wrap=None,
full_determinism=False,
generation_config=None,
generation_max_length=None,
generation_num_beams=None,
gradient_accumulation_steps=1,
gradient_checkpointing=False,
greater_is_better=None,
group_by_length=False,
half_precision_backend=auto,
hub_always_push=False,
hub_model_id=None,
hub_private_repo=False,
hub_strategy=HubStrategy.EVERY_SAVE,
hub_token=<HUB_TOKEN>,
ignore_data_skip=False,
include_inputs_for_metrics=False,
jit_mode_eval=False,
label_names=None,
label_smoothing_factor=0.0,
learning_rate=5e-05,
length_column_name=length,
load_best_model_at_end=False,
local_rank=0,
log_level=passive,
log_level_replica=warning,
log_on_each_node=True,
logging_dir=./output/zhbr-chatglm2-6b-checkpoint/runs/Oct08_13-19-56_iZbp178u8rw9n9ko94ubbyZ,
logging_first_step=False,
logging_nan_inf_filter=True,
logging_steps=500,
logging_strategy=IntervalStrategy.STEPS,
lr_scheduler_type=SchedulerType.LINEAR,
max_grad_norm=1.0,
max_steps=-1,
metric_for_best_model=None,
mp_parameters=,
no_cuda=False,
num_train_epochs=3.0,
optim=OptimizerNames.ADAMW_TORCH,
optim_args=None,
output_dir=./output/zhbr-chatglm2-6b-checkpoint,
overwrite_output_dir=True,
past_index=-1,
per_device_eval_batch_size=1,
per_device_train_batch_size=8,
predict_with_generate=True,
prediction_loss_only=False,
push_to_hub=False,
push_to_hub_model_id=None,
push_to_hub_organization=None,
push_to_hub_token=<PUSH_TO_HUB_TOKEN>,
ray_scope=last,
remove_unused_columns=True,
report_to=[],
resume_from_checkpoint=None,
run_name=./output/zhbr-chatglm2-6b-checkpoint,
save_on_each_node=False,
save_safetensors=False,
save_steps=500,
save_strategy=IntervalStrategy.STEPS,
save_total_limit=None,
seed=42,
sharded_ddp=[],
skip_memory_metrics=True,
sortish_sampler=False,
tf32=None,
torch_compile=False,
torch_compile_backend=None,
torch_compile_mode=None,
torchdynamo=None,
tpu_metrics_debug=False,
tpu_num_cores=None,
use_cpu=False,
use_ipex=False,
use_legacy_prediction_loop=False,
use_mps_device=False,
warmup_ratio=0.0,
warmup_steps=0,
weight_decay=0.0,
)
Downloading and preparing dataset json/default to /root/.cache/huggingface/datasets/json/default-98f5c44ca2dd481e/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4...
Downloading data files: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 17623.13it/s]
Extracting data files: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 3012.07it/s]
Dataset json downloaded and prepared to /root/.cache/huggingface/datasets/json/default-98f5c44ca2dd481e/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4. Subsequent calls will reuse this data.
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 1488.66it/s]
[INFO|configuration_utils.py:713] 2023-10-08 13:19:57,908 >> loading configuration file /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b/config.json
[INFO|configuration_utils.py:713] 2023-10-08 13:19:57,909 >> loading configuration file /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b/config.json
[INFO|configuration_utils.py:775] 2023-10-08 13:19:57,910 >> Model config ChatGLMConfig {
"_name_or_path": "/root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b",
"add_bias_linear": false,
"add_qkv_bias": true,
"apply_query_key_layer_scaling": true,
"apply_residual_connection_post_layernorm": false,
"architectures": [
"ChatGLMModel"
],
"attention_dropout": 0.0,
"attention_softmax_in_fp32": true,
"auto_map": {
"AutoConfig": "configuration_chatglm.ChatGLMConfig",
"AutoModel": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForCausalLM": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForSeq2SeqLM": "modeling_chatglm.ChatGLMForConditionalGeneration",
"AutoModelForSequenceClassification": "modeling_chatglm.ChatGLMForSequenceClassification"
},
"bias_dropout_fusion": true,
"classifier_dropout": null,
"eos_token_id": 2,
"ffn_hidden_size": 13696,
"fp32_residual_connection": false,
"hidden_dropout": 0.0,
"hidden_size": 4096,
"kv_channels": 128,
"layernorm_epsilon": 1e-05,
"model_type": "chatglm",
"multi_query_attention": true,
"multi_query_group_num": 2,
"num_attention_heads": 32,
"num_layers": 28,
"original_rope": true,
"pad_token_id": 0,
"padded_vocab_size": 65024,
"post_layer_norm": true,
"pre_seq_len": null,
"prefix_projection": false,
"quantization_bit": 0,
"rmsnorm": true,
"seq_length": 32768,
"tie_word_embeddings": false,
"torch_dtype": "float16",
"transformers_version": "4.32.1",
"use_cache": true,
"vocab_size": 65024
}
[INFO|tokenization_utils_base.py:1850] 2023-10-08 13:19:57,911 >> loading file tokenizer.model
[INFO|tokenization_utils_base.py:1850] 2023-10-08 13:19:57,911 >> loading file added_tokens.json
[INFO|tokenization_utils_base.py:1850] 2023-10-08 13:19:57,911 >> loading file special_tokens_map.json
[INFO|tokenization_utils_base.py:1850] 2023-10-08 13:19:57,911 >> loading file tokenizer_config.json
[INFO|modeling_utils.py:2776] 2023-10-08 13:19:57,988 >> loading weights file /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b/pytorch_model.bin.index.json
[INFO|configuration_utils.py:768] 2023-10-08 13:19:57,989 >> Generate config GenerationConfig {
"_from_model_config": true,
"eos_token_id": 2,
"pad_token_id": 0,
"transformers_version": "4.32.1"
}
Loading checkpoint shards: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:04<00:00, 1.41it/s]
[INFO|modeling_utils.py:3551] 2023-10-08 13:20:02,988 >> All model checkpoint weights were used when initializing ChatGLMForConditionalGeneration.
[WARNING|modeling_utils.py:3553] 2023-10-08 13:20:02,988 >> Some weights of ChatGLMForConditionalGeneration were not initialized from the model checkpoint at /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b and are newly initialized: ['transformer.prefix_encoder.embedding.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
[INFO|modeling_utils.py:3136] 2023-10-08 13:20:02,989 >> Generation config file not found, using a generation config created from the model config.
Quantized to 4 bit
input_ids [64790, 64792, 790, 30951, 517, 30910, 30939, 30996, 13, 13, 54761, 31211, 55046, 54848, 55623, 55279, 36989, 13, 13, 55437, 31211]
inputs [Round 1]
问:配变雷击故障
答:
label_ids [64790, 64792, 30910, 55623, 54710, 31921, 55279, 54538, 55046, 38754, 33760, 54746, 32077, 31123, 32023, 33760, 41711, 31201, 32077, 55870, 56544, 35978, 31155]
labels 雷电直接击中配电网线路或设备,导致线路损坏、设备烧毁等问题。
10/08/2023 13:20:06 - INFO - __main__ - *** Predict ***
[INFO|trainer.py:3119] 2023-10-08 13:20:06,946 >> ***** Running Prediction *****
[INFO|trainer.py:3121] 2023-10-08 13:20:06,946 >> Num examples = 2
[INFO|trainer.py:3124] 2023-10-08 13:20:06,946 >> Batch size = 1
[INFO|configuration_utils.py:768] 2023-10-08 13:20:06,949 >> Generate config GenerationConfig {
"_from_model_config": true,
"eos_token_id": 2,
"pad_token_id": 0,
"transformers_version": "4.32.1"
}
0%| | 0/2 [00:00<?, ?it/s][INFO|configuration_utils.py:768] 2023-10-08 13:20:11,223 >> Generate config GenerationConfig {
"_from_model_config": true,
"eos_token_id": 2,
"pad_token_id": 0,
"transformers_version": "4.32.1"
}
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:01<00:00, 1.09it/s]Building prefix dict from the default dictionary ...
10/08/2023 13:20:13 - DEBUG - jieba - Building prefix dict from the default dictionary ...
Dumping model to file cache /tmp/jieba.cache
10/08/2023 13:20:13 - DEBUG - jieba - Dumping model to file cache /tmp/jieba.cache
Loading model cost 0.440 seconds.
10/08/2023 13:20:13 - DEBUG - jieba - Loading model cost 0.440 seconds.
Prefix dict has been built successfully.
10/08/2023 13:20:13 - DEBUG - jieba - Prefix dict has been built successfully.
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:02<00:00, 1.14s/it]
***** predict metrics *****
predict_bleu-4 = 10.9723
predict_rouge-1 = 44.0621
predict_rouge-2 = 11.9047
predict_rouge-l = 33.5968
predict_runtime = 0:00:06.56
predict_samples = 2
predict_samples_per_second = 0.305
predict_steps_per_second = 0.305
5、验证与评估微调后的模型
方法一:
编写python脚本,加载微调训练后生成的 Checkpoint 路径:
from transformers import AutoConfig, AutoModel, AutoTokenizer
import os
import torch
# 载入Tokenizer
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
config = AutoConfig.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True, pre_seq_len=128)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", config=config, trust_remote_code=True)
prefix_state_dict = torch.load(os.path.join("./output/zhbr-chatglm2-6b-checkpoint/checkpoint-20", "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
# Comment out the following line if you don't use quantization
model = model.quantize(4) #或者8
model = model.half().cuda()
model.transformer.prefix_encoder.float()
model = model.eval()
response, history = model.chat(tokenizer, "配网线路过电压故障是什么", history=[])
print(response)
回答效果如下:

以上代码需要修改THUDM/chatglm2-6b为自己的本地路径,然后再修改基座模型的文件的config.json中的_name_or_path。
方法二:
修改ptuning中的web_demo.sh,根据自己实际情况配置:
PRE_SEQ_LEN=128
CUDA_VISIBLE_DEVICES=0 python3 web_demo.py \
--model_name_or_path /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b \
--ptuning_checkpoint output/zhbr-chatglm2-6b-checkpoint/checkpoint-20 \
--pre_seq_len $PRE_SEQ_LEN
执行web_demo.sh,访问http://xxx.xxx.xxx.xxx:7860。
(base) [root@iZbp178u8rw9n9ko94ubbyZ ptuning]# sh web_demo.sh
/root/ChatGLM/ChatGLM2-6B-main/ptuning/web_demo.py:101: GradioDeprecationWarning: The `style` method is deprecated. Please set these arguments in the constructor instead.
user_input = gr.Textbox(show_label=False, placeholder="Input...", lines=10).style(
Loading prefix_encoder weight from output/zhbr-chatglm2-6b-checkpoint/checkpoint-20
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:04<00:00, 1.47it/s]
Some weights of ChatGLMForConditionalGeneration were not initialized from the model checkpoint at /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b and are newly initialized: ['transformer.prefix_encoder.embedding.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
6、微调模型优化
适当修改微调脚本train.sh文件中的各个参数:
--train_file myDataset/train.json \ # 训练文件地址
--validation_file myDataset/dev.json \ # 验证文件地址
--prompt_column content \ # 在输入数据中,用于作为输入的列名是“content”
--response_column summary \ # 在输入数据中,用于作为目标的列名是“summary”
--overwrite_cache \ # 覆盖缓存
--model_name_or_path THUDM/chatglm-6b \ # 加载模型文件地址,可修改为本地路径
--output_dir output/zhbr-chatglm2-6b-checkpoint \ # 保存训练模型文件地址
--overwrite_output_dir \ # 覆盖output文件夹
--max_source_length 64 \ # 输入序列的最大长度
--max_target_length 128 \ # 目标序列的最大长度
--per_device_train_batch_size 1 \ # 每个设备上的训练批次大小
--per_device_eval_batch_size 1 \ # 每个设备上的评估批次大小
--gradient_accumulation_steps 16 \ # 在进行一次参数更新之前,要进行的梯度累积步骤的数量
--predict_with_generate \ # 使用生成的方式来进行预测
--max_steps 2000 \ # 训练模型的步数
--logging_steps 10 \ # 每多少步打印一次日志
--save_steps 500 \ # 每多少步保存一次模型检查点
--learning_rate $LR \ # 学习率
--pre_seq_len $PRE_SEQ_LEN \ # 序列的预设长度
--quantization_bit 4 # 可修改为int8
7、P-Tuning微调灾难性遗忘问题
微调后问答仅能回答数据集中的信息,通用问答能力完全丧失。 具体参考GitHub Issues
两种解决方案:
(1)适当调整参数,部分网友通过调整学习率,表示遗忘问题得到缓解。参考:issue#480、 issue#1148
(2)放弃P-Tuning微调,采用lora和Qlora微调。QLora微调方案参考:ChatGLM2-6B微调实践-QLora方案
微调过程中遇到的问题
报错信息如下:
dataclasses.FrozenInstanceError: cannot assign to field generation_max_length
和
dataclasses.FrozenInstanceError: cannot assign to field generation_num_beams
解决方法:
在main.py文件中注释掉以下代码。