写在前面
两个月前,我们写过一篇关于fury和protostuff的性能对比的文章:谁才是真正的协议之王?fastjson2 vs fury,那时,两个协议框架各有千秋,不分伯仲,今天,看到fury推出了全新的0.2.0版本,fastjson2推出了新2.0.41版本,据说都有很多性能的提升,今天打算再一测,希望这两家伙再接再厉,能带给我们更多惊喜!
我们这次的侧重点,主要关注在序列化,反序列化,数据包压缩率大小。
上次的结论我们再回顾下:
序列化对比
fastjson2在BeanToArray(将对象序列化成数组)情况下,是protostuff 的26.996倍。
fury在 引用解析(RefTracking)关闭,类注册(ClassRegistration)打开,整数压缩(NumberCompressed)打开的情况下 ,是protostuff 的28.160倍。
fury 胜出!
反序列化对比
fastjson2在SupportArrayToBean(将数组反序列化成对象)情况下,是protostuff 的25.002倍。
fury在 引用解析(RefTracking)关闭,类注册(ClassRegistration)打开,整数压缩(NumberCompressed)打开的情况下 ,是protostuff 的22.598倍。
fastjson2 胜出!
包体压缩比上
选取各自表现最优的情况下,fury , protostuff,fastjson 比较 20.45%> 17.90%>16.34% ,fastjson2 胜出!
@ 2023/08/19
官网和引入
fastjson2
官网:无
开源地址:https://github.com/alibaba/fastjson2
使用引入:
implementation 'com.alibaba.fastjson2:fastjson2:2.0.41'
fury
官网:https://furyio.org
开源地址:https://github.com/alipay/fury
使用引入:
implementation 'org.furyio:fury-core:0.2.0'
设备,环境及样本
设备
测试设备: win11, 8core,16g memory,
JDK
openjdk version "11.0.16.1" 2022-08-16
OpenJDK Runtime Environment TencentKonaJDK (build 11.0.16.1+2)
OpenJDK 64-Bit Server VM TencentKonaJDK (build 11.0.16.1+2, mixed mode)
样本
用游戏中高频调用的技能回包做样本,字节大小 为704 bytes,
SkillFire_S2C_Msg[attackerId=2013850838,harmList={HarmDTO[curHp=1061639.1,dead=true,maxHp=972081.06,real=36249,targetId=1711281434,type=84,value=18168.72],HarmDTO[curHp=836323.44,dead=true,maxHp=8546706.0,real=91675,targetId=1527336063,type=22,value=30714.76],HarmDTO[curHp=2022717.6,dead=true,maxHp=8923567.0,real=74008,targetId=1684460215,type=67,value=93250.83]},index=37,param1={7153337,1918282,5243103,1985757,7515730},skillCategory=ATTACK_PASSIVE]
放一张使用的游戏场景,让大家感性认识一下,你所看到的绚丽的技能效果背后是无数个SkillFire_S2C_Msg协议在来回游荡:

测评数据
性能测评的项目下载路径如下:
https://github.com/jiangguilong2000/gamioo-sandbox.git
包体大小
对序列化后传输包体压缩率的各种比较如下:
| 协议 | 设置 | 压缩率 | 前值 |
|---|---|---|---|
| fastjson2 | BeanToArray=false | 41.48% | 一样 |
| fastjson2 | BeanToArray=true | 16.34% | 一样 |
| fury | NumberCompressed=false | 24.01% | 35.94% |
| fury | NumberCompressed=true | 18.61% | 27.84% |
| fury | NumberCompressed=true,ClassRegistration | 18.61% | 20.45% |
| Protostuff | 17.90% | 一样 |
序列化
Benchmark Mode Cnt Score Error Units
ProtoSerializeBenchMark.furySerialize thrpt 10 8008220.631 ± 187910.778 ops/s
ProtoSerializeBenchMark.furySerializeWithClassRegistrationAndNumberCompressed thrpt 10 13614652.032 ± 514327.393 ops/s
ProtoSerializeBenchMark.jsonSerialize thrpt 10 3076330.832 ± 76810.104 ops/s
ProtoSerializeBenchMark.jsonSerializeWithBeanToArray thrpt 10 8459437.606 ± 263671.263 ops/s
ProtoSerializeBenchMark.jsonSerializeWithBeanToArrayAndFieldBase thrpt 10 7289778.892 ± 179821.080 ops/s
ProtoSerializeBenchMark.protostuffSerialize thrpt 10 237222.753 ± 15051.667 ops/s

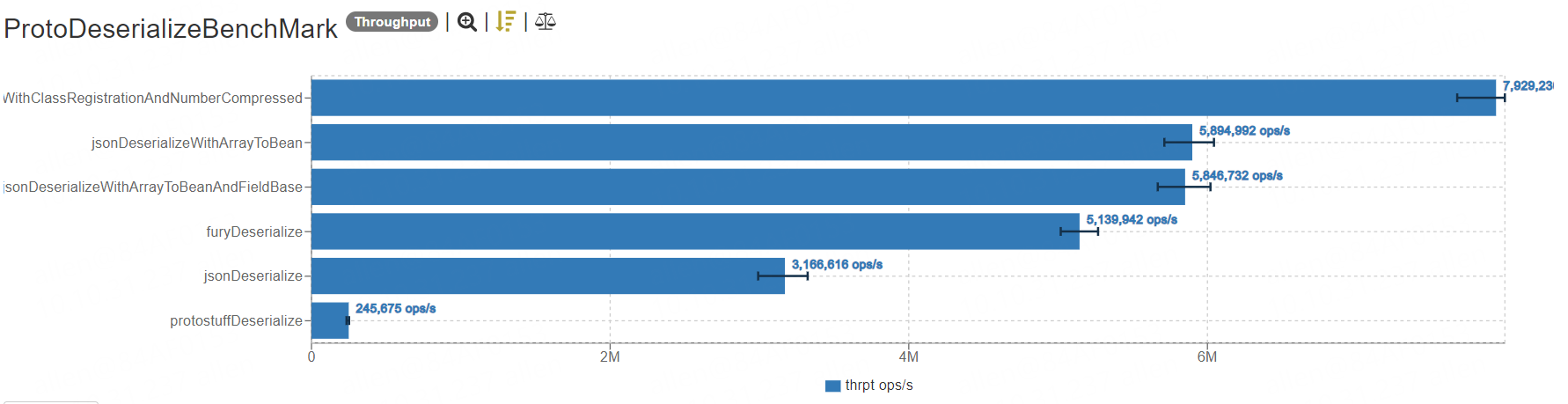
反序列化
Benchmark Mode Cnt Score Error Units
ProtoDeserializeBenchMark.furyDeserialize thrpt 10 5139942.244 ± 134681.750 ops/s
ProtoDeserializeBenchMark.furyDeserializeWithClassRegistrationAndNumberCompressed thrpt 10 7929230.323 ± 143908.696 ops/s
ProtoDeserializeBenchMark.jsonDeserialize thrpt 10 3166615.576 ± 142094.220 ops/s
ProtoDeserializeBenchMark.jsonDeserializeWithArrayToBean thrpt 10 5894992.128 ± 174962.357 ops/s
ProtoDeserializeBenchMark.jsonDeserializeWithArrayToBeanAndFieldBase thrpt 10 5846732.053 ± 183195.377 ops/s
ProtoDeserializeBenchMark.protostuffDeserialize thrpt 10 245674.644 ± 7632.013 ops/s
结论
序列化对比
fastjson2在BeanToArray(将对象序列化成数组)情况下,是protostuff 的30.73倍,比上次26.996提升了13.83%。
fury在 引用解析(RefTracking)关闭,类注册(ClassRegistration)打开,整数压缩(NumberCompressed)打开的情况下 ,是protostuff 的57.39,比上次测试的28.160性能提升了103.8%。
fury 胜出!并且,两者性能差距断崖式拉大。
反序列化对比
fastjson2在SupportArrayToBean(将数组反序列化成对象)情况下,是protostuff 的23.99倍。
fury在 引用解析(RefTracking)关闭,类注册(ClassRegistration)打开,整数压缩(NumberCompressed)打开的情况下 ,是protostuff 的32.275倍,比上次测试的22.598提升了42.82%
fury 反败为胜,并且,两者性能差距大幅拉大。
包体压缩比上
选取各自表现最优的情况下,fury , protostuff,fastjson 比较
18.61%>17.90%> 16.34%,前值是20.45%> 17.90%>16.34%,依旧是fastjson2 胜出!
综述
总之,经过一个大版本的迭代,fury在核心指标序列化,反序列化上已经迎头赶上,并大幅拉开和fastjson2的差距,压缩比上,也大大的缩小了和fastjson2的差距,这是让笔者感到令人惊喜的成果,如果能在多语言生态特别是C#,和接口的易用性上更上一层,谁会笑到最后,让我们拭目以待。
附言:本人认知有限,如本文中有错误的使用或者见解,请联系我纠正,谢谢!
Q&A
Q.当前版本,提前显式注册类不再需要了?
A:对的,带来的影响,简化了框架的使用复杂度,提升了性能。
Q.对long类型的数据有没有优化算法?
A:有的,ong的范围都是在int范围内,其实你可以换成int来序列化,fury压缩率比jsonb要高的,有个高压缩率的long编码算法,在你这个场景开启后压缩效果也更好一点,但是也会导致你数据里面的List跟着一起压缩,而jsonb没有压缩,所以我们默认没开,要开的话,withLongCompressed(LongEncoding.PVL),压缩率更高,不过有性能损失,一般不打开,发现开启后,包体是能进一步压缩,但性能影响还挺大,暂时不用。




![[华为认证]路由表和FIB表](https://img-blog.csdnimg.cn/60e43e46187a4f0ebe6efdf0af6df13b.png)