基础知识
线程
线程是进程中的一个实体,线程本身是不会独立存在的。一个进程中至少有一个线程,进程中的多个线程共享进程的资源。
进程
是程序的一次执行,是系统进行资源分配和调度的基本单位。每一个进程都有自己独立的内存空间和系统资源
管程
Monitor监视器,也就是平时所说的锁。是一种同步机制,保证同一时间只有一个线程可以访问资源。
线程状态
public enum State {
NEW,
RUNNABLE,
BLOCKED,
WAITING,
TIMED_WAITING,
TERMINATED;
}
new,刚刚创建线程,还没执行runnable就绪状态,当调用start()后就处于该状态,但它可能并没有在运行,还在等待系统资源blocked阻塞状态,等待监视器锁。遇到synchronized代码块,但锁被其他线程所持有未释放时,等待获取锁;或者是调用wait方法释放了锁等待重新获取锁继续代码块的执行。waiting等待状态,无限期等待。调用以下任一方法Object.waitwith no timeout,等待其他线程调用notify()或notifyAll()Thread.joinwith no timeout,等待目标线程完成进入终止状态LockSupport.park,等待unpark方法
time_waiting等待状态,有限时间的等待调用以下任一方法Thread.sleepObject.waitwith timeoutThread.joinwith timeoutLockSupport.parkNanosLockSupport.parkUntil
terminated结束状态,线程执行完毕之后进入结束状态
创建线程的方式
- 实现
Runnable接口- 由于
Java是单继承语言,当类本身有父类时,不能再继承Thread类来创建线程,可以实现Runnable接口来创建线程,该类的实例作为参数传入到Thread构造函数中。
- 由于
- 继承
Thread类 - 实现
Callable接口- 同样是实现接口,
Callable相比Runnable接口的优势在于,Callable的call方法有返回值,可以抛出异常 - 创建线程的步骤
new Thread(new FutureTask<>(new CallableTask)):Thread类其中一个构造函数Thread(Runnable target)Runnable有一个实现类FutureTaskFutureTask的一个构造函数FutureTask(Callable<V> callable)
- 同样是实现接口,
wait和sleep的区别
| 方法 | 所属类 | 是否释放 | 作用 | 参数 |
|---|---|---|---|---|
wait | Object | 释放锁 | 常用于线程间通信交互 | 可以不指定时长,通过其他线程调用notify()或notifyAll()方法苏醒;也可以指定时长自动苏醒 |
sleep | Thread | 不释放锁 | 常用于暂停执行 | 必须指定时长 |
虚假唤醒问题
由于把所有线程都唤醒了,但只有其中一部分线程是正确的被唤醒,部分线程仍然不满足唤醒条件,以下代码就可能出现虚假唤醒问题
if (!condition) {
obj.wait();
}
因为被唤醒后不会再次判断是否满足条件,所以应该将wait()方法被while包裹
while (!condition) {
obj.wait();
}
确保被唤醒后还会再次判断是否满足条件,避免了虚假唤醒的问题。
join
等待特定线程先执行完成再执行本线程后续内容。
yield
告知调度器愿意放弃当前处理器的使用,让出CPU的使用权,处于就绪状态(区别于wait),但有可能立马有分配给当前线程。
线程中断
interrupt()
中断线程,线程B调用线程A的interrupt方法,将线程A的中断标志设为true,并立即返回。该方法并不会直接中断线程,仅仅是修改中断标识。
如果线程A因为调用了wait()、sleep()、join()等方法被挂起时调用的interrupt(),线程A会在这些地方抛出InterruptedException而返回。
interrupted()
静态方法,检测当前线程是否被中断,同时清除中断标志,将中断标志设为false
isInterrupted()
实例方法,检测实例线程是否被中断
| 方法 | 静态 | 清除状态 | 线程 |
|---|---|---|---|
interrupted | √ | √ | 当前线程 |
isInterrupted | 实例线程 |
用户线程和守护线程
守护线程是一种特殊的线程,在后台默默地完成一些系统性的服务,比如垃圾回收线程。
用户线程是系统的工作线程,会完成这个程序需要完成的业务操作。
当程序中所有用户线程执行完毕之后,不管守护线程是否结束,系统都会自动退出。
死锁
指两个或以上线程在执行过程中,因争夺资源而造成的互相等待的现象。
必须满足四个条件:
- 互斥条件:资源同一时间只能被一个线程持有,其他线程请求获取只能等待
- 请求并持有条件:指线程已经持有了最少一个资源,还在请求新的资源,而新的资源被其他线程占有,所以线程会被阻塞,但阻塞的同时不释放自己以获得的资源。
- 不可剥夺条件:线程获取到的资源,直到主动释放,不可被其他线程剥夺。
- 环路等待条件:必须存在循环等待的环环形链
避免死锁
使资源申请有序,破坏环路等待条件。
线程池
提前创建好线程,创建新任务是从线程池中获取一个空闲线程来执行该任务,执行完毕后,将线程回收到线程池中等待下一个任务。
特点
- 线程复用
- 控制最大并发数
- 管理线程
newFixedThrealPool(int)
固定线程数的线程池
newSingleThreadExecutor()
线程池中只有一个线程
newCachedThreadPool
corePoolSize为0,maximumPoolSize为Integer.MAX_VALUE。
CompletableFuture
Future
@Test
public void test1() throws ExecutionException, InterruptedException, TimeoutException {
FutureTask<Integer> futureTask = new FutureTask<>(() -> {
TimeUnit.SECONDS.sleep(3);
return 1;
});
new Thread(futureTask).start();
// System.out.println(futureTask.get());//会阻塞在这里直到拿到返回值
// System.out.println(futureTask.get(1l, TimeUnit.SECONDS));//超时会抛出异常TimeoutException
//轮询
while (true){
if(futureTask.isDone()){
System.out.println(futureTask.get());
break;
}
}
System.out.println("after get()");
}
get()方法会阻塞
get(long, TimeUnit)方法会在超时还没拿到结果时抛出异常
isDone()轮询,会耗费无谓的CPU资源。
CompletableStage
基于上述缺陷,对Future类进行改进:CompletableFuture类
CompletableFuture类实现了CompletableStage接口和Future接口
CompletableStage提供了异步方法、回调方法。
主线程设置好回调后,无需再关心异步任务的执行,可以专注本线程的任务。
处理异步计算结果
thenApply(),接受异步处理结果并处理后返回值thenAccept(),接收异步处理结果并处理,但没有返回值thenRun(),无法接受异步处理结果,执行给定的动作whenComplete(),接受异步处理结果和异常
处理异常
handle(),获取异步处理的结果,可以处理任务执行过程中可能出现的抛出异常的情况。exceptionally(),处理异常情况。completeExceptionally(),让CompletableFuture的结果就是异常
组合CompletableFuture
thenCompose(),可以链接两个CompletableFuture对象,并将前一个任务的返回结果作为下一个任务的参数,它们之间存在着先后顺序。thenCombine(),会在两个任务都执行完成后,把两个任务的结果合并。两个任务是并行执行的,它们之间并没有先后依赖顺序
锁
乐观锁和悲观锁
悲观锁认为自己在使用数据的时候一定会有其他线程来修改数据,因此在获取数据前先加锁,保证数据不会被其他线程修改。
乐观锁认为自己在使用数据时不会有其他线程修改数据,所以不会添加锁,只是在更新数据时判断是否有其他线程修改了数据,如果没有其他数据修改,更新数据。
Synchronized
作用对象
- 修饰实例方法,作用对象是当前实例
- 修饰静态方法,作用对象是类的Class对象
- 修饰代码块,指定监视器对象
公平锁和非公平锁
公平锁表示线程获取锁的顺序是按照线程请求锁的实践早晚来决定的。
非公平锁则是在运行期间不停的尝试抢占锁
独占锁和共享锁
独占锁保证任何时候都只有一个线程能得到锁
共享锁则可以同时由多个线程持有,如ReadWriteLock
可重入锁
同一个线程在已经持有锁的时候,再次到达该锁对象的代码块时,可以自动获取锁直接进入,不会因为锁未释放而阻塞。
自选锁
当一个线程在获取锁的时候,发现锁被其他线程占有,不马上阻塞自己,在不放弃CPU使用权的情况下,多次尝试获取。使用CPU实践换取线程阻塞和调度的开销。
LockSupport
park()如果线程已经拿到了许可证,调用park方法会马上返回,否则线程会被禁止参与线程的调度,即阻塞挂起
unpark()给许可证,唤醒阻塞的线程
解决了wait、notify必须要先持有锁的问题
解决了Lock.newCondition必须先等待后唤醒的问题
park和unpark没有先后顺序,可以先unpark给许可证,再到park(此时因为持有许可证,会马上返回)
JMM(Java Memory Model)Java内存模型
JMM本身是一种抽象的概念并不真实存在,它仅仅描述的是一组约定或规范,通过这组规范定义了程序中(尤其是多线程)各个变量的读写访问方式并决定一个线程对共享变量的写入何时以及如何变成对另一个线程可见,关键技术点都是围绕多线程的原子性、可见性和有序性展开的。
CPU缓存模型
CPU 缓存则是为了解决 CPU 处理速度和内存处理速度不对等的问题。
CPU 缓存的工作方式:先从主内存复制一份变量副本到各自CPU缓存中,实际操作都作用域自己缓存内的值,最后再写回主内存。
可能存在的问题:CPU-1和CPU-2同时从主内存中获取一份副本到自己的缓存中并修改,写入到主内存的时候可能会发生其中一个CPU的数据被覆盖的情况。
指令重排
指令重排是指计算机在执行程序代码的过程中,为了提升执行速度、性能,在不影响单线程程序语义的前提下,重新安排执行顺序。
指令重排序可以保证串行语义一致,但是没有义务保证多线程间的语义也一致。
对于处理器,通过插入内存屏障的方式来禁止特定类型的重排序,从而保障指令执行的有序性。同时为了达到屏障的效果,它也会使处理器写入、读取值之前,将主内存的值写入高速缓存,清空无效队列,从而保障变量的可见性。
指令重排下单例模式的问题
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
//先判断对象是否已经实例过,没有实例化过才进入加锁代码
if (uniqueInstance == null) {
//类对象加锁
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
uniqueInstance 采用 volatile 关键字修饰也是很有必要的, uniqueInstance = new Singleton(); 这段代码其实是分为三步执行:
- 为
uniqueInstance分配内存空间 - 初始化
uniqueInstance - 将
uniqueInstance指向分配的内存地址
但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被初始化。
happens-before原则
一个操作对后一个操作是可见的,存在数据依赖的。
三大特性
- 可见性:当一个线程对共享变量进行了修改,那么另外的线程都是立即可以看到修改后的最新值。
- 有序性:通过内存屏障的方式来禁止特定类型的重排序,保障了指令执行的有序性。
- 原子性:一次操作或者多次操作,要么所有的操作全部都得到执行并且不会受到任何因素的干扰而中断,要么都不执行。
volatile
特性
- 可见性
- 当读一个volatile变量时,JMM会把该线程对应的本地内存设置为无效,直接从主内存中读取共享变量
- 当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量值立即刷新回主内存中。
- 有序性
- 被修饰为
volatile的变量在读写时,会插入特定的内存屏障来禁止指令重排序,保障了有序性
- 被修饰为
但volatile并不保证原子性
四种内存屏障
- 写
- 在每个
volatile写之前,插入一个StoreStore屏障 - 在每个
volatile写之后,插入一个StoreLoad屏障
- 在每个
- 读
- 在每个
volatile读之后,插入一个LoadLoad屏障 - 在每个
volatile读之后,插入一个LoadStore屏障
- 在每个
内存屏障禁止了指令重排,确保写数据立即刷新到主内存,读数据从主内存读取。
这四种内存屏障保证了:
volatile写之前的操作禁止重排到后面volatile读之后的操作禁止重排到前面volatile写之后有volatile读的话,禁止重排
CAS(Compare and Swap)
CAS用于实现乐观锁,将内存位置的值与预期值做比较,如果相匹配,那么将该位置的值更新为目标值,如果不匹配,则不做任何操作。
CAS是靠硬件实现的从而在硬件层面提升效率,最底层还是交给硬件来保证原子性和可见性
ABA问题
线程T1获取到内存位置V的值为A,同时线程T2也获取到V的值为A。在线程T1进行CAS操作前,可能发生以下情形:线程T2使用CAS将V位置的值修改成B,然后又通过CAS将B修改成A。此时T1执行CAS成功,但这个A已经不是原来的A了。
解决ABA问题思路是追加版本号或者戳记,在对比的时候同时对比版本号或戳记。
Unsafe类
Unsafe类中的方法都是native方法,提供了硬件级别的原子性操作。
原子类
基本类型原子类
AtomicIntegerAtomicBooleanAtomicLong
数组类型原子类
AtomicIntegerArrayAtomicLongArrayAtomicReferenceArray
引用类型原子类
AtomicReferenceAtomicStampedReferenceAtomicMarkableReference
对象的属性原子类
AtomicIntegerFieldUpdaterAtomicLongFieldUpdaterAtomicReferenceFieldUpdater
原子操作增强类
DoubleAccumulatorDoubleAdderLongAccumulatorLongAdder
LongAdder为什么性能不AtomicLong更好
先说结论:LongAdder通过增加变量来维护数据,空间换时间将热点分散,大大减少了不断自旋尝试CAS的消耗。
AtomicLong
public class AtomicLong extends Number implements java.io.Serializable {
private static final long VALUE
= U.objectFieldOffset(AtomicLong.class, "value");
//一个变量维护数据
private volatile long value;
//调用UnSafe类的方法
public final long incrementAndGet() {
return U.getAndAddLong(this, VALUE, 1L) + 1L;
}
}
public final class Unsafe {
@IntrinsicCandidate
public final long getAndAddLong(Object o, long offset, long delta) {
long v;
//通过自旋进行CAS
do {
v = getLongVolatile(o, offset);
} while (!weakCompareAndSetLong(o, offset, v, v + delta));
return v;
}
}
AtomicLong类用一个long类型的变量维护数据,所有线程对这个类的操作都作用于这个变量,当出现高并发的时候,同一时间只有一个线程可以CAS成功,其他线程都在无限循环自选尝试CAS,这严重影响性能、消耗CPU资源。
LongAdder
LongAdder继承Striped64类,Striped64类中有一个long类型的base变量,当并发数量不高时,和AtomicLong一样,通过一个变量维护数据。
此外Striped64类还声明了一个内部类Cell,这个类中也有一个value变量,当高并发的时候,Striped64类启用Cell[]数组cells来热点分流,减少了大量线程集中到一个变量上自旋的情况。
abstract class Striped64 extends Number {
static final class Cell {
volatile long value;
Cell(long x) { value = x; }
}
//Table of cells. When non-null, size is a power of 2.
//非空时,大小是2的幂
transient volatile Cell[] cells;
/**
* Base value, used mainly when there is no contention, but also as
* a fallback during table initialization races. Updated via CAS.
* 基值,主要在没有争抢的时候使用,但也可以作为数组表初始化期间的后备值,CAS更新
*/
transient volatile long base;
}
add()
//LongAdder类
public void add(long x) {
Cell[] cs; long b, v; int m; Cell c;
//判断cells是否为空(是否已经初始化cells了)
//如果还没初始化,就对base进行CAS,在没有线程竞争时,cas成功,方法返回
//如果有线程竞争了,cas失败,进入if代码块
if ((cs = cells) != null || !casBase(b = base, b + x)) {
int index = getProbe();
//竞争标识:true为无竞争
boolean uncontended = true;
//cs == null: 竞争失败但cells仍未初始化
//(m = cs.length - 1) < 0:一般不会出现,长度小于0
//(c = cs[index & m]) == null:如果目标cell为空。cells长度为2的幂次的目的,做与运算快速获取对应下标
//(uncontended = c.cas(v = c.value, v + x)):对目标cell做一次cas,成功cas则方法返回
if (cs == null || (m = cs.length - 1) < 0 ||
(c = cs[index & m]) == null ||
!(uncontended = c.cas(v = c.value, v + x)))
//未初始化或仍然发生竞争
longAccumulate(x, null, uncontended, index);
}
}
/**
* @param wasUncontended false if CAS failed before call
* 如果调用前CAS失败了,则为false
*/
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended, int index) {
//如果下标为0,重新获取下标,并清除竞争标识
if (index == 0) {
ThreadLocalRandom.current(); // force initialization
index = getProbe();
wasUncontended = true;
}
for (boolean collide = false;;) { // True if last slot nonempty
Cell[] cs; Cell c; int n; long v;
//已经初始化了cells
if ((cs = cells) != null && (n = cs.length) > 0) {
//但对应下标位置仍为空
if ((c = cs[(n - 1) & index]) == null) {
if (cellsBusy == 0) { // Try to attach new Cell
Cell r = new Cell(x); // Optimistically create
if (cellsBusy == 0 && casCellsBusy()) {
try { // Recheck under lock
Cell[] rs; int m, j;
//再次判断该槽确实为空
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & index] == null) {
rs[j] = r;
break;
}
} finally {
cellsBusy = 0;
}
continue; // Slot is now non-empty
}
}
//槽为空但表锁
collide = false;
}
//争夺失败,那就重新刷新hash值再来一次
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
//尝试cas
else if (c.cas(v = c.value,
(fn == null) ? v + x : fn.applyAsLong(v, x)))
break;
//表大小已经超过限制,或者cells已经被其他线程更新
else if (n >= NCPU || cells != cs)
collide = false; // At max size or stale
else if (!collide)
collide = true;
//扩容
else if (cellsBusy == 0 && casCellsBusy()) {
try {
//确认表还未被其他线程修改过
if (cells == cs) // Expand table unless stale
cells = Arrays.copyOf(cs, n << 1);
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
index = advanceProbe(index);
}
//cellsBusy,表锁,在创建和扩容时锁住表
//此时cs应该为空
//再次判断cells为空
//通过cas锁表
else if (cellsBusy == 0 && cells == cs && casCellsBusy()) {
try { // Initialize table
if (cells == cs) {//再次判断cells为空,类似DCL
Cell[] rs = new Cell[2];//初始化长度为2的数组,0 和 1 下标位置应该为null
rs[index & 1] = new Cell(x);//初始化对应下标
cells = rs;//初始化完成赋值给cells
break;
}
} finally {
cellsBusy = 0;//解锁
}
}
// Fall back on using base
//兜底方法,表正在初始化当中、cas锁表竞争失败时,来对base进行CAS
//成功就break退出循环,否则继续循环重新判断
else if (casBase(v = base,
(fn == null) ? v + x : fn.applyAsLong(v, x)))
break;
}
}
final boolean casCellsBusy() {
return CELLSBUSY.compareAndSet(this, 0, 1);
}
两者对比
AtomicLongCAS+自旋锁- 低并发的全局计算
- 能保证计数的准确性
- 高并发下性能急剧降低,自旋称为瓶颈
LongAdderCAS+base+cells数组分散热点- 空间换时间
- 高并发下的全局计算
sum是不保证准确的,在计算的同时如果有其他线程修改了,无法精确获取到
ThreadLocal
ThreadLocal提供线程的局部变量,使每个线程有自己独立的变量,不和其他线程共享。
Thread类维护了ThreadLocalMap类型的变量,ThreadLocalMap是TreadLocal的内部类。
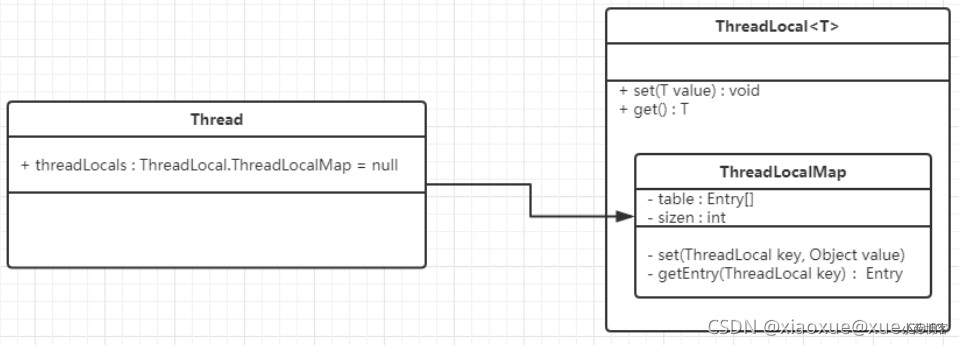
public class Thread implements Runnable {
ThreadLocal.ThreadLocalMap threadLocals = null;
}
public class ThreadLocal<T> {
static class ThreadLocalMap {
//Map内部是用Entry存储,key是threadLocal实例,value是任意对象
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
private Entry[] table;
}
}
public T get() {
//获取当前线程
Thread t = Thread.currentThread();
//获取当前线程的ThreadLocalMap
ThreadLocalMap map = getMap(t);
if (map != null) {
//获取以当前实例为key的Entry
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
ThreadLocalMap getMap(Thread t) {
//获取指定线程的ThreadLocalMap,就是返回线程的局部变量threadLocals
return t.threadLocals;
}
内存泄漏
ThreadLocalMap 中使用的 key 为 ThreadLocal 的弱引用,而 value 是强引用。所以,如果 ThreadLocal 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。
这样一来,ThreadLocalMap 中就会出现 key 为 null 的 Entry。假如我们不做任何措施的话,value 永远无法被 GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap 实现中已经考虑了这种情况,在调用 set()、get()、remove() 方法的时候,会清理掉 key 为 null 的记录。使用完 ThreadLocal方法后最好手动调用remove()方法
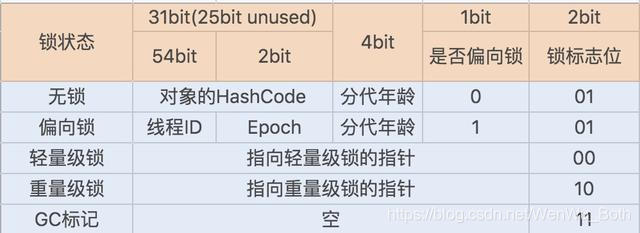
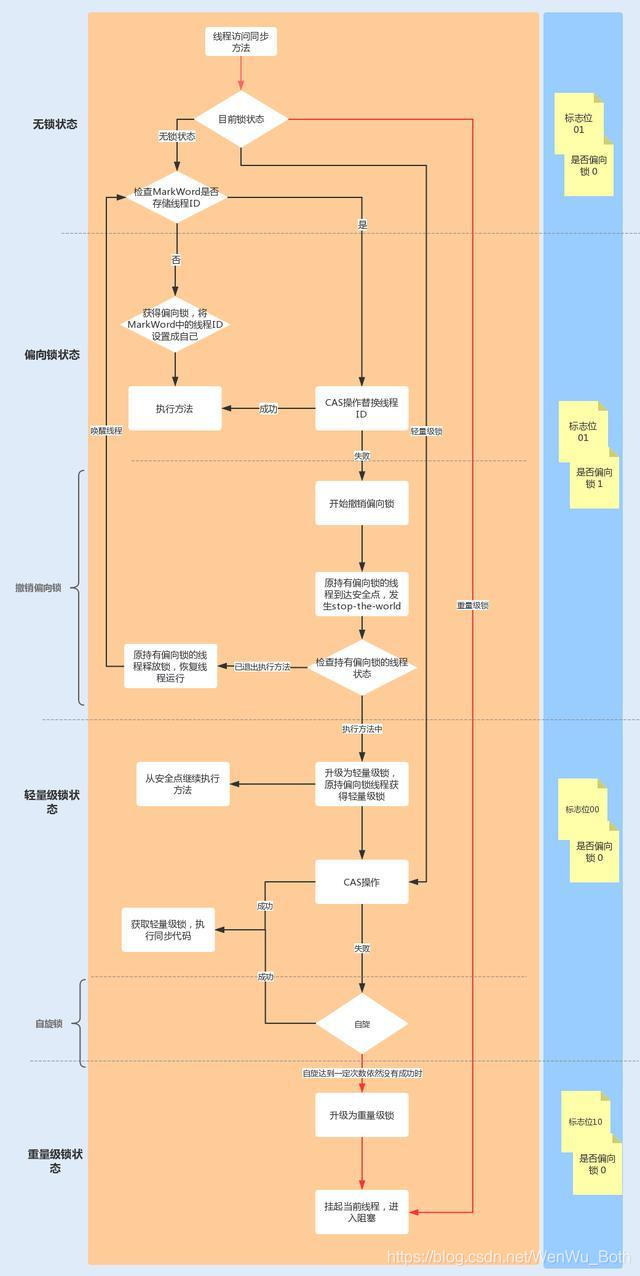
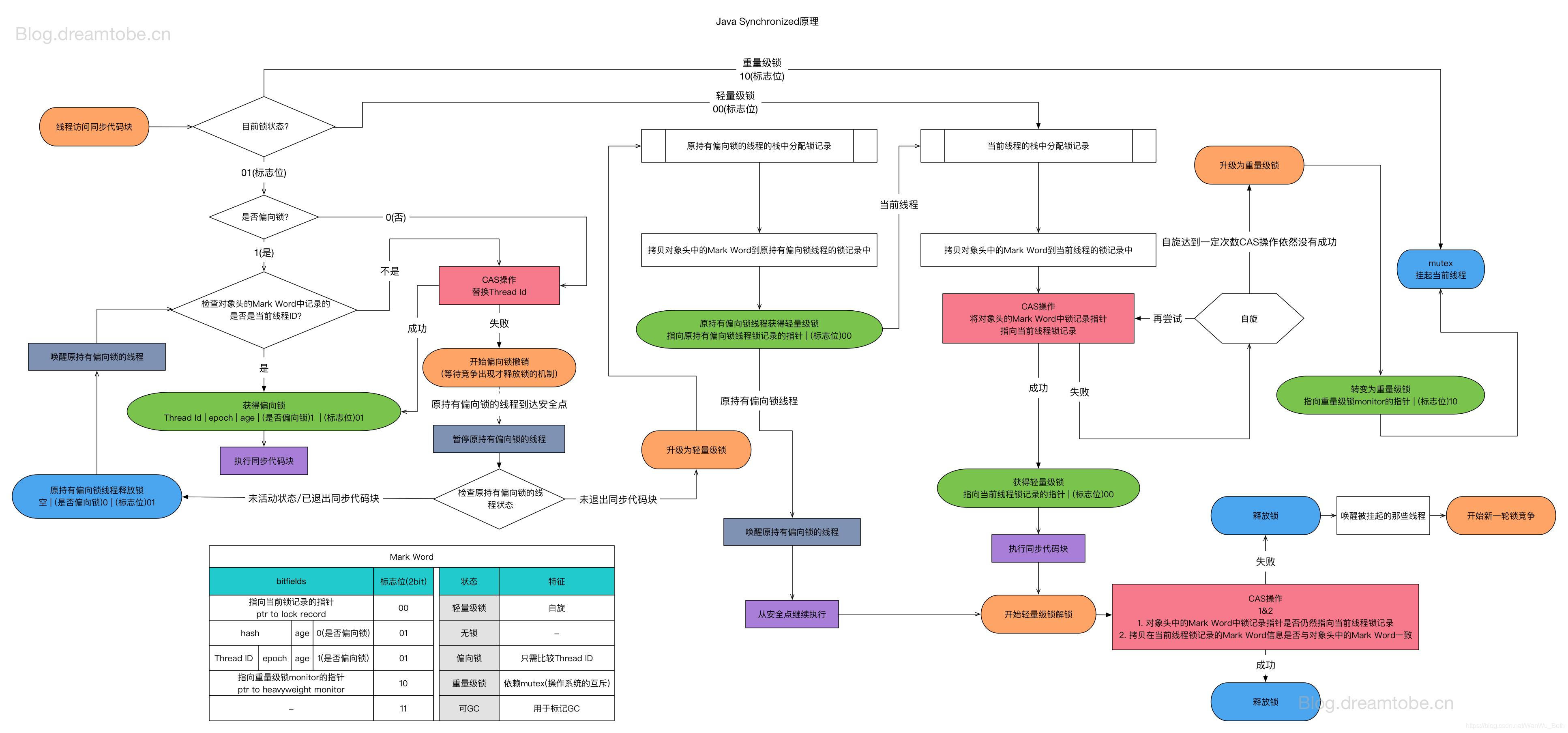
synchronized的锁升级
Java 6之后,为了减少获得锁和释放锁所带来的性能消耗,引入了轻量级锁和偏向锁。
偏向锁
偏向锁主要用来优化同一线程,多次申请同一个锁的竞争,在某些情况下大部分时间都是同一个线程竞争锁资源。
当线程1再次获取锁时,会比较当前线程ID与锁对象头Mark Word中的线程ID是否一致。
- 如果一致,直接获取锁,无需
CAS来抢占锁 - 如果不一致,需要查看锁对象
Mark Word中的线程是否存活- 若存活,查找线程1的栈帧信息,如果线程1还需要继续持有该锁对象,那么暂停线程1(
Stop-The-World),撤销偏向锁,升级为轻量级锁;如果线程1不再使用锁对象,则将锁对象设置为无锁状态(也属于锁撤销),然后重新偏向线程2; - 不存活,将锁对象设置为无锁状态(也属于锁撤销),然后重新偏向线程2
- 若存活,查找线程1的栈帧信息,如果线程1还需要继续持有该锁对象,那么暂停线程1(
可以看到,当持有锁的线程宕掉之后,其他请求锁的线程会检查持有锁的线程是否存活,若不存活则直接撤销锁,从而避免了死锁。
轻量锁
轻量锁适应的场景是:各线程交替执行同步块,大部分的锁在同步周期内不存在长时间的竞争。
AQS(AbstractQueuedSynchronizer)
AQS,抽象队列同步器, 是应该抽象类,主要用来构建锁和同步器。
AQS使用一个volatile的int类型的成员变量来表示同步状态,通过内置的FIFO队列来完成资源获取的排队工作将每条要去抢占资源的线程封装成一个Node节点来实现锁的分配,通过CAS完成对State值的修改。
以ReentrantLock理解AQS源码
关系图
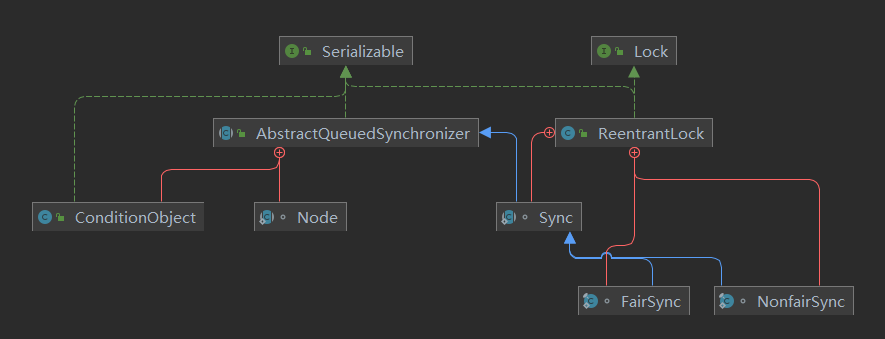
ReentrantLock中的内部类Sync继承了AQS类,公平锁FairSync和非公平锁NonfairSync继承了Sync。
Lock
//(1). NonfairSync
final void lock() {
//上来就先抢一次锁,通过CAS修改共享变量state的值
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
//抢占失败
acquire(1); //(2)
}
//(2). AQS
public final void acquire(int arg) {
if (!tryAcquire(arg) && //(3)
//(5)addWaiter
//(7)acquireQueued
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
//(3). NonfairSync
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires); //(4)
}
//(4). Sync
final boolean nonfairTryAcquire(int acquires) {
// 获取当前线程、锁的状态
final Thread current = Thread.currentThread();
int c = getState();
// 如果锁状态空闲
if (c == 0) {
// 再次尝试抢占
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
// 如果锁不空闲,但是当前线程就是占用锁的线程
else if (current == getExclusiveOwnerThread()) {
//把state值+acquires
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
//(5). AQS,前面几次尝试抢占都失败,加入队列
private Node addWaiter(Node mode) {
// 封装成Node对象
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
// 如果已经初始化过队列
if (pred != null) {
node.prev = pred;
// cas更新尾节点
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
// 入队
enq(node); //(6)
return node;
}
//(6). AQS
private Node enq(final Node node) {
for (;;) {
Node t = tail;
// 尾节点为空必须初始化队列
if (t == null) { // Must initialize
// 初始化一个队列头,虚假的Node节点
if (compareAndSetHead(new Node()))
tail = head;
} else {
// 更新尾节点
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
//(7). AQS
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
// 自旋,要么获取锁,要么中断
for (;;) {
// 获取当前节点的前置节点
final Node p = node.predecessor();
// 如果前置节点是头节点,就再去抢占一次
if (p == head && tryAcquire(arg)) {
// 抢占成功就把自己设为头节点
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
if (shouldParkAfterFailedAcquire(p, node) && //(8) 判断节点是否需要阻塞
parkAndCheckInterrupt()) //(9) 阻塞线程
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
//(8). AQS
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
// 获取前面一个节点的状态
int ws = pred.waitStatus;
if (ws == Node.SIGNAL)
//前一个节点已经是SIGNAL了,阻塞
return true;
if (ws > 0) {
//前面节点要取消
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
//设置前一个节点的状态为SIGNAL
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
//(9). AQS
private final boolean parkAndCheckInterrupt() {
// 挂起线程
LockSupport.park(this);
return Thread.interrupted();
}
unlock
//(1). ReentrantLock
public void unlock() {
sync.release(1);
}
//(2). AQS
public final boolean release(int arg) {
if (tryRelease(arg)) { //(3)
//所有锁释放完了
Node h = head;
//头节点不为空且状态不是刚初始化
if (h != null && h.waitStatus != 0)
unparkSuccessor(h); //(4)
return true;
}
return false;
}
//(3). Sync
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
//判断锁是否已经释放完
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
//(4). AQS
private void unparkSuccessor(Node node) {
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
//获取下一个节点,因为当前节点为头节点即虚拟节点,所以下一个节点是真实需要抢占的节点
Node s = node.next;
//如果是null,或者是被取消状态,找队列第一个<=0的节点
if (s == null || s.waitStatus > 0) {
s = null;
//从队尾往前找,找到队列第一个waitState<=0的节点
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
//如果该节点不为空且状态<=0,唤醒
if (s != null)
LockSupport.unpark(s.thread);
}
线程同步器
CountDownLatch
等待指定线程执行完成,再执行阻塞线程后的内容。
countDown()
计数-1,直到减到0,唤醒被await()阻塞的线程
await()
state > 0时阻塞,直到countDown到0;
两种使用场景
等待指定数量的线程完成
public class CountDownLatchDemo {
public static void main(String[] args) throws InterruptedException {
int count = 10;
//初始化计数器
CountDownLatch countDownLatch = new CountDownLatch(count);
for (int i = 0; i < count; i++) {
final int threadNum = i;
new Thread(() -> {
try {
business(threadNum);
countDownLatch.countDown();//计数-1
} catch (InterruptedException e) {
e.printStackTrace();
}
}, threadNum+"").start();
}
countDownLatch.await();//阻塞
System.out.println("主线程需要等待子线程完成后才进行的其他业务");
}
private static void business(int i) throws InterruptedException {
int v = (int) (Math.random() * 5 + 1);
System.out.println(Thread.currentThread().getName()+"进入工作,需要等待"+v+"秒");
TimeUnit.SECONDS.sleep(v);//随即休眠一段时间
System.out.println(Thread.currentThread().getName()+"完成工作");
}
}
一系列线程等待同时启动
public static void main(String[] args) throws InterruptedException {
//**一系列线程等待同时启动**
//初始化为1
CountDownLatch countDownLatch = new CountDownLatch(1);
for (int i = 0; i < 10; i++) {
final int threadNum = i;
new Thread(() -> {
try {
countDownLatch.await();
System.out.println(Thread.currentThread().getName()+"开始工作");
} catch (InterruptedException e) {
e.printStackTrace();
}
}, threadNum+"").start();
}
System.out.println("主线程开始做前置工作,一段时间后让子线程同时运转");
int v = (int) (Math.random() * 5 + 1);
for (int i = 1; i <= v; i++) {
TimeUnit.SECONDS.sleep(1);
System.out.println("第"+i+"秒");
}
System.out.println("主线程完成前置工作");
countDownLatch.countDown();//计数-1
}
CyclicBarrier
CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是:让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。
await()
线程执行到这个方法后阻塞,直到指定数量的线程都调用该方法(到达栅栏前),一起冲破栅栏继续执行后面的业务。
区别于CountDownLatch,CyclicBarrier是可重复的。
public class CyclicBarrierDemo {
private static ExecutorService threadPool = Executors.newFixedThreadPool(20);
private static int threadCnt = 50;
public static void main(String[] args) throws InterruptedException {
CyclicBarrier cyclicBarrier = new CyclicBarrier(5);//初始化屏障数
for (int i = 0; i < threadCnt; i++) {
final int threadNum = i;
Thread.sleep(200);
threadPool.execute(() -> {
try {
System.out.println(threadNum +"is ready");
//到达屏障,计数-1,计数器不归0则阻塞
cyclicBarrier.await();
System.out.println(threadNum +"is finished");
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
});
}
threadPool.shutdown();
}
}
Semaphore
信号量,相当于一个许可库,初始化许可证数量,需要时请求许可acquire,用完后释放许可归还许可库release,可以控制同时访问特定资源的线程数量。
区别于CountDownLatch计数器,信号量是可以重复使用的。
acquire()、acquire(int)
请求许可,如果请求量大于库中剩余量,则阻塞。
release
释放许可,将许可归还给许可库,使计数器+1。即使已经超出初始化的值,仍可以+1。
两种使用场景
等待指定数量线程执行完毕
public class SemaphoreDemo {
private static ExecutorService threadPool = Executors.newFixedThreadPool(30);
private static int threadCnt = 50;
public static void main(String[] args) throws InterruptedException {
//初始为0
Semaphore semaphore = new Semaphore(0);
for (int i = 0; i < threadCnt; i++) {
final int threadNum = i;
threadPool.execute(() -> {
try {
if ((threadNum & 1) == 1)
TimeUnit.SECONDS.sleep(1);
business(threadNum);
semaphore.release();//释放
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
semaphore.acquire(5);
System.out.println("主线程业务继续进行");
threadPool.shutdown();
}
public static void business(int i) throws InterruptedException {
//模拟业务
TimeUnit.SECONDS.sleep(1);
System.out.println(i);
TimeUnit.SECONDS.sleep(1);
}
}
限制访问资源的线程数量
public class SemaphoreDemo {
private static ExecutorService threadPool = Executors.newFixedThreadPool(30);
private static int threadCnt = 50;
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(5);
for (int i = 0; i < threadCnt; i++) {
final int threadNum = i;
threadPool.execute(() -> {
try {
//请求许可,没有则阻塞
semaphore.acquire();
business(threadNum);
semaphore.release();//释放许可
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
threadPool.shutdown();
}
public static void business(int i) throws InterruptedException {
//模拟业务
TimeUnit.SECONDS.sleep(1);
System.out.println(i);
TimeUnit.SECONDS.sleep(1);
}
}
读写锁
ReentrantReadWriteLock实现了 ReadWriteLock ,是一个可重入的读写锁,既可以保证多个线程同时读的效率,同时又可以保证有写入操作时的线程安全。实现了读读共存。
锁降级
在线程持有写锁的情况下,获取读锁,再将写锁释放。这样写锁就降级为读锁。
作用:
- 降低锁的力度,写锁会阻塞其他线程,而读锁可以与其他的读线程共存。
- 当前线程可能需要使用自己刚修改完的值,在确保不丢失锁(保证不会被其他写线程修改,因为读锁与写锁互斥)的情况下完成后续工作。
StampedLock
是由锁饥饿问题引出。相比ReentrantReadWriteLock,多了乐观读,允许写线程获取写锁,不会导致所有写锁阻塞,性能更好。但他不可重入。
参考资料
尚硅谷2022版JUC并发编程
《Java并发编程之美》
《实战 Java 高并发程序设计》
小薛博客 - JUC
打酱油的葫芦娃 - Java的锁机制–偏向锁、轻量锁、自旋锁、重量锁