系列文章目录
大数据主要组件核心源码解析
文章目录
- 系列文章目录
- 大数据主要组件核心源码解析
- 前言
- 一、HQL转化为MR 核心思路
- 二、核心代码
- 1. 入口类,生命线
- 2. 编译代码
- 3. 执行代码
- 总结
前言
提示:这里可以添加本文要记录的大概内容:
对大数据几个核心组件的源码,记录一下生命线
提示:以下是本篇文章正文内容,下面案例可供参考
一、HQL转化为MR 核心思路
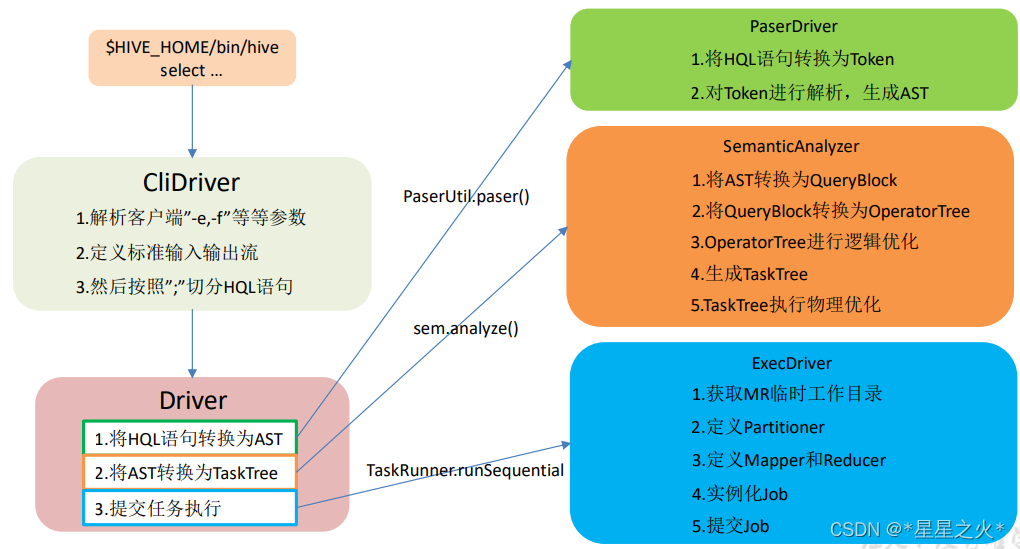
二、核心代码
1. 入口类,生命线
CliDriver.main
run()
executeDriver()
cli.processLine(ss.execString);--hive -e 和 hive读取命令
CliDriver.processLine()
List<String> commands = splitSemiColon(line);
processCmd(command);
processLocalCmd(cmd, proc, ss)
if (proc instanceof IDriver)
IDriver qp = (IDriver) proc;
qp.run(cmd)
Driver.run()
runInternal(command, alreadyCompiled:false);
compileInternal(command, true); --关键代码1:编译sql
execute(); --关键代码2: 执行hql
2. 编译代码
--关键代码1:编译sql
Driver.compileInternal(command, true);
compile(command, true, deferClose);
ASTNode tree = ParseUtils.parse(command, ctx); --解析器工作
// Do semantic analysis and plan generation
BaseSemanticAnalyzer sem = SemanticAnalyzerFactory.get(queryState, tree); --编译器、优化器工作
sem.analyze(tree, ctx);
// get the output schema
schema = getSchema(sem, conf);
plan = new QueryPlan(queryStr, sem, perfLogger.getStartTime(PerfLogger.DRIVER_RUN), queryId, queryState.getHiveOperation(), schema);
3. 执行代码
--关键代码2: 执行hql
Driver.execute();
TaskRunner runner = launchTask(task, queryId, noName, jobname, jobs, driverCxt);
TaskRunner tskRun = new TaskRunner(tsk);
tskRun.start();
TaskRunner.run()
runSequential()
tsk.executeTask(ss == null ? null : ss.getHiveHistory());
--tsk的各种实现类运行 ExecDriver(MR任务的driver类) 、CopyTask, DDLTask, MapRedTask等
int retval = execute(driverContext); --不同的task实现执行
ExecDriver(MR任务的driver类) mr任务构造、提交
总结
提示:这里对文章进行总结:
对核心流程,生命线进行追踪。
学习源码:核心思路,抓大放小。
把上面的生命线抓住,需要分析具体问题再细看。







![Python库学习(九):Numpy[续篇三]:数组运算](https://img-blog.csdnimg.cn/img_convert/ca61747b8ddf2c308913aba23ab10a02.png)