Gossip协议是什么
Gossip protocol 也叫 Epidemic Protocol (流行病协议), 是基于流行病传播方式的节点或者进程之间信息交换的协议, 也被叫做流言算法, 八卦算法、疫情传播算法等等.
说到 Gossip 协议, 就不得不提著名的六度分隔理论.
简单地说, 你和任何一个陌生人之间所间隔的人不会超过六个. 也就是说, 最多通过六个人你就能够认识任何一个陌生人(Facebook通过实验发现当今这个“网络直径”是 4.57 ), 六度分隔理论也就是 Gossip 协议的雏形了.
定义
Gossip 协议的定义十分简单: 以给定的频率, 每台计算机随机选择另一台计算机, 并共享任何消息.
因为简单的定义, 实现方式和变种也特别多, 根据不同的场景和需求, Gossip 协议的表现方式也不尽相同
原理
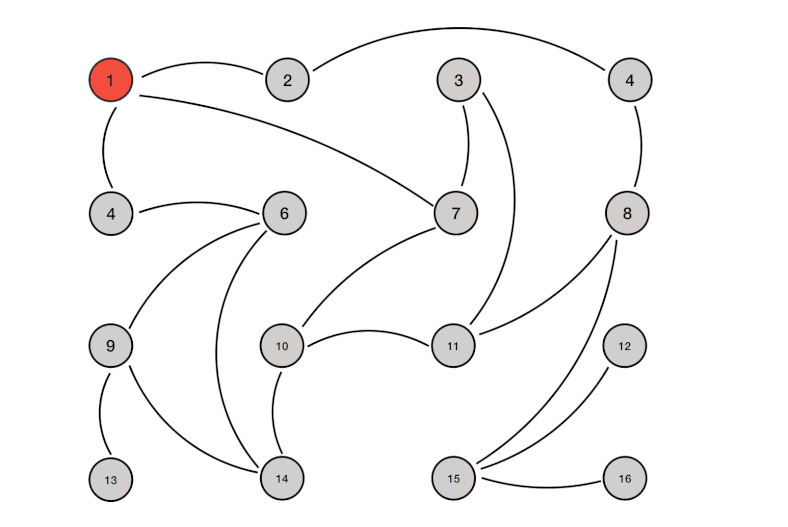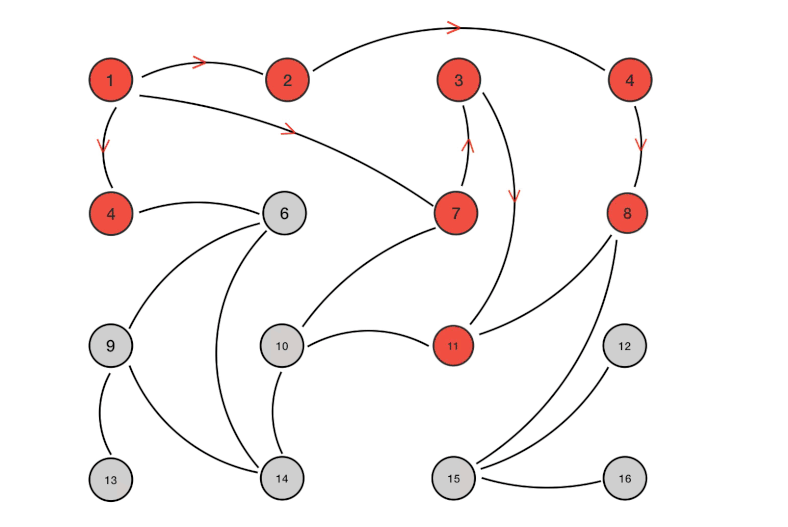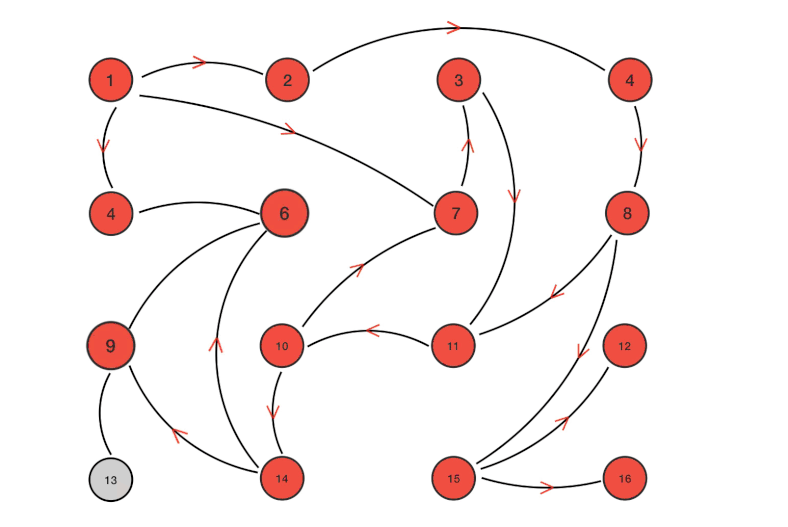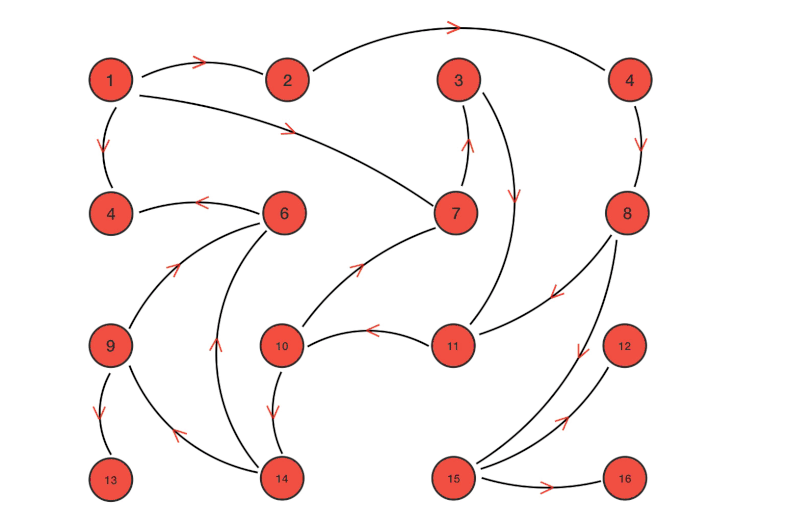
假如公司内突然没有了网络, 该如何快速且高效的将一个消息传递给所有员工呢? Gossip 给出的解决方案类似公司内的八卦传播, 一传十, 十传百的将消息同步给所有人. 基本思想就是: 一个节点想要分享一些信息给网络中的其他的一些节点. 于是, 它周期性的随机选择一些节点, 并把信息传递给这些节点. 这些收到信息的节点接下来会做同样的事情, 即把这些信息传递给其他一些随机选择的节点. 一般而言, 信息会周期性的传递给N个目标节点, 而不只是一个.这个N被称为fanout.
工作过程类似下图(可以理解为并行广度优先遍历)
实现
Gossip 协议被广泛用于多种场景, 如 Redis Cluster, Bitcoin 等等. 本文以一个实现了 Gossip 协议的 Golang Repo — memberlist 作为切入点, 简要说明一下其中对 Gossip 协议的具体实现. 该 Repo 被 Alertmanager、Consul 等项目使用, 例如 Alertmanager 就使用其同步多节点之间的 Silence 信息.
SWIM 简介
memberlist 基于 SWIM 协议开发, SWIM 是 Gossip 协议的一种, 用原文来说, SWIM is Scalable Weakly-Consistent Infection-Style Process Group Membership Protocol. 定义里的每一部分都描述了 SWIM 可以做什么:
- 可扩展性: 如果集群中的一个节点出现异常, 至少会有一个其他节点在常数时间内得知该情况, 其他节点得知该情况的速度取决于集群规模(对数级). 集群内每个节点的负载始终是保持不变的, 不会因为集群规模的增大而增大. 这是非常重要的一个性质, 也是 Gossip协议的杀手锏.
- 弱一致性: Gossip 协议只保证最终一致.
- 感染式传播: Gossip 协议中的事件以感染式传播, 这也是可扩展性里传播时间和集群规模为对数比的原因.
- 成员: 集群的每个节点都包含集群所有其他成员的状态表, 并根据从其他节点和广播收到的‘Gossip’来更新该表.
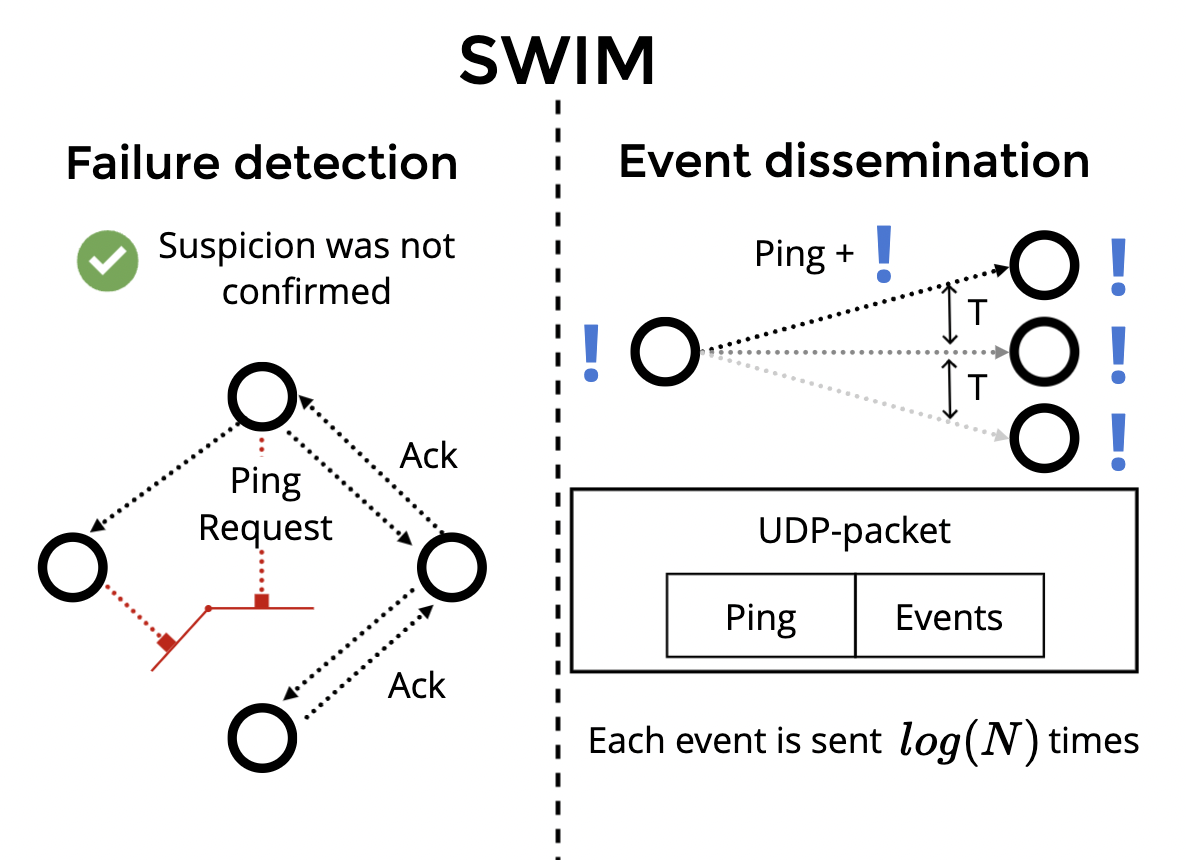
SWIM 组件
SWIM 由两个独立的组件组成——故障检测组件(failure detection)和事件传播组件(event dissemination). 故障检测组件会通过 ping, ping-req 和 ack 消息对集群中的节点进行存活检测, 事件传播组件则负责通过 UDP 在集群节点之间传递事件.
memberlist 实现
memberlist 实现了 SWIM , 而且在其基础之前增加了不少优化性改动.
让我们来瞅一下 memberlist 的实现, 下面的代码是 memberlist 的主流程代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | // Schedule is used to ensure the Tick is performed periodically. This
// function is safe to call multiple times. If the memberlist is already
// scheduled, then it won't do anything.
func (m *Memberlist) schedule() {
m.tickerLock.Lock()
defer m.tickerLock.Unlock()
// 创建probe goroutine
if m.config.ProbeInterval > 0 {
t := time.NewTicker(m.config.ProbeInterval)
go m.triggerFunc(m.config.ProbeInterval, t.C, stopCh, m.probe)
m.tickers = append(m.tickers, t)
}
// 创建push/pull goroutine
if m.config.PushPullInterval > 0 {
go m.pushPullTrigger(stopCh)
}
// 创建gossip goroutine
if m.config.GossipInterval > 0 && m.config.GossipNodes > 0 {
t := time.NewTicker(m.config.GossipInterval)
go m.triggerFunc(m.config.GossipInterval, t.C, stopCh, m.gossip)
m.tickers = append(m.tickers, t)
}
}
|
probe goroutine, gossip goroutine 可以简单的理解为 memberlist 对于故障检测和事件传播的实现.
消息类型
memberlist 在整个生命周期内, 总共有两种类型的消息:
- udp协议消息: 传输PING消息、间接PING消息、ACK消息、NACK消息、Suspect消息、 Alive消息、Dead消息、消息广播
- tcp协议消息: 用户数据同步、节点状态同步、PUSH-PULL消息
故障检测
memberlist 利用点对点随机探测机制实现成员的故障检测, 因此将节点的状态分为3种:
- Alive: 活动节点
- Suspect: 可疑节点
- Dead: 死亡节点
probe goroutine 通过点对点随机探测实现成员的故障检测, 强化系统的高可用. 整体流程如下:
- 随机探测: 节点启动后, 每隔一定时间间隔, 会选取一个节点对其发送PING消息.
- 重试与间隔探测请求: PING消息失败后, 会随机选取N(由config中
IndirectChecks设置)个节点发起间接PING请求和再发起一个TCP PING消息. - 间隔探测: 收到间接PING请求的节点会根据请求中的地址发起一个PING消息, 将PING的结果返回给间接请求的源节点.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 | HANDLE_REMOTE_FAILURE:
// Get some random live nodes.
m.nodeLock.RLock()
kNodes := kRandomNodes(m.config.IndirectChecks, m.nodes, func(n *nodeState) bool {
return n.Name == m.config.Name ||
n.Name == node.Name ||
n.State != StateAlive
})
m.nodeLock.RUnlock()
// Attempt an indirect ping.
expectedNacks := 0
selfAddr, selfPort = m.getAdvertise()
ind := indirectPingReq{
SeqNo: ping.SeqNo,
Target: node.Addr,
Port: node.Port,
Node: node.Name,
SourceAddr: selfAddr,
SourcePort: selfPort,
SourceNode: m.config.Name,
}
for _, peer := range kNodes {
// We only expect nack to be sent from peers who understand
// version 4 of the protocol.
if ind.Nack = peer.PMax >= 4; ind.Nack {
expectedNacks++
}
if err := m.encodeAndSendMsg(peer.FullAddress(), indirectPingMsg, &ind); err != nil {
m.logger.Printf("[ERR] memberlist: Failed to send indirect ping: %s", err)
}
}
// Also make an attempt to contact the node directly over TCP. This
// helps prevent confused clients who get isolated from UDP traffic
// but can still speak TCP (which also means they can possibly report
// misinformation to other nodes via anti-entropy), avoiding flapping in
// the cluster.
//
// This is a little unusual because we will attempt a TCP ping to any
// member who understands version 3 of the protocol, regardless of
// which protocol version we are speaking. That's why we've included a
// config option to turn this off if desired.
fallbackCh := make(chan bool, 1)
// Wait for the acks or timeout. Note that we don't check the fallback
// channel here because we want to issue a warning below if that's the
// *only* way we hear back from the peer, so we have to let this time
// out first to allow the normal UDP-based acks to come in.
select {
case v := <-ackCh:
if v.Complete == true {
return
}
}
// Finally, poll the fallback channel. The timeouts are set such that
// the channel will have something or be closed without having to wait
// any additional time here.
for didContact := range fallbackCh {
if didContact {
m.logger.Printf("[WARN] memberlist: Was able to connect to %s but other probes failed, network may be misconfigured", node.Name)
return
}
}
// Update our self-awareness based on the results of this failed probe.
// If we don't have peers who will send nacks then we penalize for any
// failed probe as a simple health metric. If we do have peers to nack
// verify, then we can use that as a more sophisticated measure of self-
// health because we assume them to be working, and they can help us
// decide if the probed node was really dead or if it was something wrong
// with ourselves.
awarenessDelta = 0
if expectedNacks > 0 {
if nackCount := len(nackCh); nackCount < expectedNacks {
awarenessDelta += (expectedNacks - nackCount)
}
} else {
awarenessDelta += 1
}
// No acks received from target, suspect it as failed.
m.logger.Printf("[INFO] memberlist: Suspect %s has failed, no acks received", node.Name)
s := suspect{Incarnation: node.Incarnation, Node: node.Name, From: m.config.Name}
m.suspectNode(&s)
|
- 探测超时标识可疑: 如果探测超时之间内, 本节点没有收到任何一个要探测节点的ACK消息, 则标记要探测的节点状态为suspect.
- 可疑节点广播: 启动一个定时器用于发出一个 suspect 广播, 此期间内如果收到其他节点发来的相同的 suspect 信息时, 将本地 suspect 的确认数 +1 , 当定时器超时后, 该节点信息仍然不是 alive 的, 且确认数达到要求, 会将该节点标记为 dead.
- 可疑消除: 当本节点收到别的节点发来的 suspect 消息时, 会发送 alive 广播, 从而清除其他节点上的 suspect 标记.
- 死亡通知: 当本节点离开集群时或者本地探测的其他节点超时被标记死亡, 会向集群发送本节点dead广播.
- 死亡消除: 如果从其他节点收到自身的 dead 广播消息时, 会发起一个 alive 广播以修正其他节点上存储的本节点数据.
与 SWIM 不同的是, memberlist 将故障节点的状态保留一段时间, 以便可以在完整状态同步中传递有关故障节点的信息. 这有助于集群的状态更快地收敛.
事件传播
gossip goroutine 通过 udp 向 config.GossipNodes 个节点(一般设置为集群节点数/2)发送消息, 节点从广播队列里面获取消息, 广播队列里的消息发送失败超过一定次数后, 消息就会被丢弃.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | // gossip is invoked every GossipInterval period to broadcast our gossip
// messages to a few random nodes.
func (m *Memberlist) gossip() {
// Get some random live, suspect, or recently dead nodes
m.nodeLock.RLock()
kNodes := kRandomNodes(m.config.GossipNodes, m.nodes, func(n *nodeState) bool {
if n.Name == m.config.Name {
return true
}
switch n.State {
case StateAlive, StateSuspect:
return false
case StateDead:
return time.Since(n.StateChange) > m.config.GossipToTheDeadTime
default:
return true
}
})
m.nodeLock.RUnlock()
for _, node := range kNodes {
// Get any pending broadcasts
msgs := m.getBroadcasts(compoundOverhead, bytesAvail)
if len(msgs) == 0 {
return
}
addr := node.Address()
if len(msgs) == 1 {
// Send single message as is
if err := m.rawSendMsgPacket(node.FullAddress(), &node.Node, msgs[0]); err != nil {
m.logger.Printf("[ERR] memberlist: Failed to send gossip to %s: %s", addr, err)
}
} else {
// Otherwise create and send a compound message
compound := makeCompoundMessage(msgs)
if err := m.rawSendMsgPacket(node.FullAddress(), &node.Node, compound.Bytes()); err != nil {
m.logger.Printf("[ERR] memberlist: Failed to send gossip to %s: %s", addr, err)
}
}
}
}
|
这点和 SWIM 有些不同, gossip goroutine 独立于故障检测组件发送 gossip 消息, 这使得我们可以手动调整这个过程的频次(可以比故障检测的频次更高), 以加快收敛速度.
扩展
memberlist 在 SWIM 的基础之上, 还增加了一些扩展
反熵
memberlist 添加了一种反熵机制, 通过该机制, 每个成员通过 TCP 定期与另一个随机选择的成员进行完整状态同步. 这种全状态同步增加了节点更快完全收敛的可能性, 但代价是更多的带宽消耗. 这种机制对于加快从网络分区的恢复来说特别有帮助.
push/pull goroutine 既是对该机制的实现, 其周期性的从已知的 alive 的集群节点中选1个节点进行push/pull 交换信息. 交换的信息包含2种:
- 集群信息: 节点数据
- 用户自定义的信息: 实现
Delegate接口的struct
push/pull goroutine 可以加速集群内信息的收敛速度, 整体流程为:
- 建立TCP链接: 每隔一个时间间隔, 随机选取一个节点, 跟它建立tcp连接.
- 将本地的全部节点、状态、用户数据发送过去.
- 对端将其掌握的全部节点状态、用户数据发送回来, 然后完成2份数据的合并.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | // pushPull is invoked periodically to randomly perform a complete state
// exchange. Used to ensure a high level of convergence, but is also
// reasonably expensive as the entire state of this node is exchanged
// with the other node.
func (m *Memberlist) pushPull() {
// Get a random live node
m.nodeLock.RLock()
// 随机抽取一个Alive的Node进行pushPull
nodes := kRandomNodes(1, m.nodes, func(n *nodeState) bool {
return n.Name == m.config.Name ||
n.State != StateAlive
})
m.nodeLock.RUnlock()
// If no nodes, bail
if len(nodes) == 0 {
return
}
node := nodes[0]
// Attempt a push pull
if err := m.pushPullNode(node.FullAddress(), false); err != nil {
m.logger.Printf("[ERR] memberlist: Push/Pull with %s failed: %s", node.Name, err)
}
}
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | // pushPullNode does a complete state exchange with a specific node.
func (m *Memberlist) pushPullNode(a Address, join bool) error {
defer metrics.MeasureSince([]string{"memberlist", "pushPullNode"}, time.Now())
// 发送自己的状态信息并获取目标Node的状态信息
remote, userState, err := m.sendAndReceiveState(a, join)
if err != nil {
return err
}
// 合并状态信息
if err := m.mergeRemoteState(join, remote, userState); err != nil {
return err
}
return nil
}
|
Lifeguard
lifeguard 用于在出现消息处理缓慢(由于 CPU 不足、网络延迟或丢失等因素)的情况下使 memberlist 更加健壮. 例如在 CPU 耗尽的情况下, 不带 lifeguard 的 SWIM 与带 lifeguard 的 SWIM 误报数对比如下:

具体介绍可参阅 Lifeguard : SWIM-ing with Situational Awareness
劣势
末尾来总结下 Gossip 协议的一些劣势:
- 达成最终一致性的时间不确定性
- 消息延迟, 只能实现最终一致性, 传播过程中, 数据不一致
- 虽然可以通过各种参数调节, 但是由于协议本身事件传播方面的冗余性, 广播rpc消息量大, 对网络压力较大
- 拜占庭将军问题, 不允许存在恶意节点, 恶意节点的数据也会传遍整个集群(这点确实和八卦很像XD)