ChatGLM2-6B微调实践-Lora方案
- 环境部署
- Lora微调
- 项目部署
- 准备数据集
- 修改训练脚本
- adapter推理
- 模型合并与量化
- 合并后的模型推理
- 微调过程中遇到的问题
- 参考:
环境部署
安装Anaconda、CUDA、PyTorch
参考:ChatGLM2-6B微调实践-P-Tuning方案
Lora微调
项目部署
git clone https://github.com/shuxueslpi/chatGLM-6B-QLoRA.git
cd chatGLM-6B-QLoRA
pip install -r requirements.txt
准备数据集
准备我们自己的数据集,分别生成训练文件和测试文件这两个文件,放在项目data文件夹,数据格式为:
{
"instruction": "类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔腿裤",
"output": "宽松的阔腿裤这两年真的吸粉不少,明星时尚达人的心头爱。毕竟好穿时尚,谁都能穿出腿长2米的效果宽松的裤腿,当然是遮肉小能手啊。上身随性自然不拘束,面料亲肤舒适贴身体验感棒棒哒。系带部分增加设计看点,还让单品的设计感更强。腿部线条若隐若现的,性感撩人。颜色敲温柔的,与裤子本身所呈现的风格有点反差萌。"
}
训练集文件: train.json
测试集文件: dev.json
修改训练脚本
创建train_qlora.sh,添加以下命令:
python3 train_qlora.py \
--train_args_json chatGLM_6B_QLoRA.json \
--model_name_or_path THUDM/chatglm-6b \
--train_data_path data/train.json \
--eval_data_path data/dev.json \
--lora_rank 4 \
--lora_dropout 0.05 \
--compute_dtype fp32
修改model_name_or_path参数为本地真实的模型路径。
chatGLM_6B_QLoRA.json文件为所有transformers框架支持的TrainingArguments,可根据实际情况自行修改。参考:https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments
执行脚本训练,训练过程如下:
(base) [root@iZbp178u8rw9n9ko94ubbyZ chatGLM-6B-QLoRA-main]# sh train_qlora.sh
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please run
python -m bitsandbytes
and submit this information together with your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
bin /root/anaconda3/lib/python3.11/site-packages/bitsandbytes/libbitsandbytes_cuda118.so
CUDA SETUP: CUDA runtime path found: /root/anaconda3/lib/libcudart.so.11.0
CUDA SETUP: Highest compute capability among GPUs detected: 8.6
CUDA SETUP: Detected CUDA version 118
CUDA SETUP: Loading binary /root/anaconda3/lib/python3.11/site-packages/bitsandbytes/libbitsandbytes_cuda118.so...
The model weights are not tied. Please use the `tie_weights` method before using the `infer_auto_device` function.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:07<00:00, 1.13s/it]
trainable params: 974,848 || all params: 3,389,286,400 || trainable%: 0.0287626327477076
Found cached dataset json (/root/.cache/huggingface/datasets/json/default-a26442a3257bd6e5/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4)
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 920.81it/s]
Loading cached processed dataset at /root/.cache/huggingface/datasets/json/default-a26442a3257bd6e5/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4/cache-a6ee5e96ac795161.arrow
Loading cached shuffled indices for dataset at /root/.cache/huggingface/datasets/json/default-a26442a3257bd6e5/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4/cache-20df68b061e7d292.arrow
Loading cached processed dataset at /root/.cache/huggingface/datasets/json/default-a26442a3257bd6e5/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4/cache-e9ff6a88c507a91d.arrow
Found cached dataset json (/root/.cache/huggingface/datasets/json/default-f82d1afe86c1e9ec/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4)
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1191.56it/s]
Loading cached processed dataset at /root/.cache/huggingface/datasets/json/default-f82d1afe86c1e9ec/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4/cache-baa6cdf34a027bbb.arrow
Loading cached shuffled indices for dataset at /root/.cache/huggingface/datasets/json/default-f82d1afe86c1e9ec/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4/cache-8aa40269a670f4fd.arrow
Loading cached processed dataset at /root/.cache/huggingface/datasets/json/default-f82d1afe86c1e9ec/0.0.0/e347ab1c932092252e717ff3f949105a4dd28b27e842dd53157d2f72e276c2e4/cache-dd26c6462b17896e.arrow
wandb: Tracking run with wandb version 0.15.3
wandb: W&B syncing is set to `offline` in this directory.
wandb: Run `wandb online` or set WANDB_MODE=online to enable cloud syncing.
0%| | 0/160 [00:00<?, ?it/s]`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`...
/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 1.9799, 'learning_rate': 6.25e-05, 'epoch': 0.12}
{'loss': 2.8439, 'learning_rate': 0.000125, 'epoch': 0.24}
{'loss': 2.6293, 'learning_rate': 0.0001875, 'epoch': 0.35}
{'loss': 2.6095, 'learning_rate': 0.00025, 'epoch': 0.47}
{'loss': 2.2325, 'learning_rate': 0.0003125, 'epoch': 0.59}
{'eval_loss': 2.7306337356567383, 'eval_runtime': 0.1659, 'eval_samples_per_second': 12.057, 'eval_steps_per_second': 12.057, 'epoch': 0.59}
3%|█████▉ | 5/160 [00:04<01:36, 1.60it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 2.4916, 'learning_rate': 0.000375, 'epoch': 0.71}
{'loss': 2.4591, 'learning_rate': 0.0004375, 'epoch': 0.82}
{'loss': 2.0441, 'learning_rate': 0.0005, 'epoch': 0.94}
{'loss': 1.8674, 'learning_rate': 0.0005625000000000001, 'epoch': 1.06}
{'loss': 1.5093, 'learning_rate': 0.000625, 'epoch': 1.18}
{'eval_loss': 1.626299262046814, 'eval_runtime': 0.1665, 'eval_samples_per_second': 12.013, 'eval_steps_per_second': 12.013, 'epoch': 1.18}
6%|███████████▉ | 10/160 [00:06<01:23, 1.80it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 1.7075, 'learning_rate': 0.0006875, 'epoch': 1.29}
{'loss': 1.6792, 'learning_rate': 0.00075, 'epoch': 1.41}
{'loss': 1.4942, 'learning_rate': 0.0008125000000000001, 'epoch': 1.53}
{'loss': 1.8202, 'learning_rate': 0.000875, 'epoch': 1.65}
{'loss': 0.9729, 'learning_rate': 0.0009375, 'epoch': 1.76}
{'eval_loss': 0.7719208002090454, 'eval_runtime': 0.1673, 'eval_samples_per_second': 11.953, 'eval_steps_per_second': 11.953, 'epoch': 1.76}
9%|█████████████████▊ | 15/160 [00:09<01:20, 1.81it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 1.3478, 'learning_rate': 0.001, 'epoch': 1.88}
{'loss': 1.3449, 'learning_rate': 0.0009930555555555556, 'epoch': 2.0}
{'loss': 0.6173, 'learning_rate': 0.0009861111111111112, 'epoch': 2.12}
{'loss': 0.5325, 'learning_rate': 0.0009791666666666666, 'epoch': 2.24}
{'loss': 1.1995, 'learning_rate': 0.0009722222222222222, 'epoch': 2.35}
{'eval_loss': 0.06268511712551117, 'eval_runtime': 0.1694, 'eval_samples_per_second': 11.804, 'eval_steps_per_second': 11.804, 'epoch': 2.35}
12%|███████████████████████▊ | 20/160 [00:12<01:17, 1.81it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 1.0089, 'learning_rate': 0.0009652777777777778, 'epoch': 2.47}
{'loss': 0.9793, 'learning_rate': 0.0009583333333333334, 'epoch': 2.59}
{'loss': 0.814, 'learning_rate': 0.0009513888888888889, 'epoch': 2.71}
{'loss': 1.1905, 'learning_rate': 0.0009444444444444445, 'epoch': 2.82}
{'loss': 0.8011, 'learning_rate': 0.0009375, 'epoch': 2.94}
{'eval_loss': 0.21860463917255402, 'eval_runtime': 0.1697, 'eval_samples_per_second': 11.782, 'eval_steps_per_second': 11.782, 'epoch': 2.94}
16%|█████████████████████████████▋ | 25/160 [00:15<01:14, 1.82it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.3818, 'learning_rate': 0.0009305555555555556, 'epoch': 3.06}
{'loss': 0.3961, 'learning_rate': 0.0009236111111111112, 'epoch': 3.18}
{'loss': 0.4549, 'learning_rate': 0.0009166666666666666, 'epoch': 3.29}
{'loss': 0.1871, 'learning_rate': 0.0009097222222222222, 'epoch': 3.41}
{'loss': 0.8322, 'learning_rate': 0.0009027777777777778, 'epoch': 3.53}
{'eval_loss': 0.11932770907878876, 'eval_runtime': 0.1681, 'eval_samples_per_second': 11.901, 'eval_steps_per_second': 11.901, 'epoch': 3.53}
19%|███████████████████████████████████▋ | 30/160 [00:18<01:12, 1.80it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0794, 'learning_rate': 0.0008958333333333334, 'epoch': 3.65}
{'loss': 0.2307, 'learning_rate': 0.0008888888888888888, 'epoch': 3.76}
{'loss': 0.5759, 'learning_rate': 0.0008819444444444444, 'epoch': 3.88}
{'loss': 0.5141, 'learning_rate': 0.000875, 'epoch': 4.0}
{'loss': 0.1513, 'learning_rate': 0.0008680555555555556, 'epoch': 4.12}
{'eval_loss': 0.01624702289700508, 'eval_runtime': 0.1677, 'eval_samples_per_second': 11.929, 'eval_steps_per_second': 11.929, 'epoch': 4.12}
22%|█████████████████████████████████████████▌ | 35/160 [00:21<01:07, 1.84it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.1017, 'learning_rate': 0.0008611111111111112, 'epoch': 4.24}
{'loss': 0.0328, 'learning_rate': 0.0008541666666666666, 'epoch': 4.35}
{'loss': 0.03, 'learning_rate': 0.0008472222222222222, 'epoch': 4.47}
{'loss': 0.1851, 'learning_rate': 0.0008402777777777778, 'epoch': 4.59}
{'loss': 0.0946, 'learning_rate': 0.0008333333333333334, 'epoch': 4.71}
{'eval_loss': 0.04633883014321327, 'eval_runtime': 0.1688, 'eval_samples_per_second': 11.845, 'eval_steps_per_second': 11.845, 'epoch': 4.71}
25%|███████████████████████████████████████████████▌ | 40/160 [00:23<01:04, 1.87it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0802, 'learning_rate': 0.0008263888888888889, 'epoch': 4.82}
{'loss': 0.5968, 'learning_rate': 0.0008194444444444445, 'epoch': 4.94}
{'loss': 0.263, 'learning_rate': 0.0008125000000000001, 'epoch': 5.06}
{'loss': 0.2971, 'learning_rate': 0.0008055555555555556, 'epoch': 5.18}
{'loss': 0.0483, 'learning_rate': 0.0007986111111111112, 'epoch': 5.29}
{'eval_loss': 0.18734805285930634, 'eval_runtime': 0.1696, 'eval_samples_per_second': 11.79, 'eval_steps_per_second': 11.79, 'epoch': 5.29}
28%|█████████████████████████████████████████████████████▍ | 45/160 [00:26<01:04, 1.79it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0725, 'learning_rate': 0.0007916666666666666, 'epoch': 5.41}
{'loss': 0.0611, 'learning_rate': 0.0007847222222222222, 'epoch': 5.53}
{'loss': 0.0533, 'learning_rate': 0.0007777777777777778, 'epoch': 5.65}
{'loss': 0.0112, 'learning_rate': 0.0007708333333333334, 'epoch': 5.76}
{'loss': 0.085, 'learning_rate': 0.0007638888888888888, 'epoch': 5.88}
{'eval_loss': 0.04521441087126732, 'eval_runtime': 0.1684, 'eval_samples_per_second': 11.877, 'eval_steps_per_second': 11.877, 'epoch': 5.88}
31%|███████████████████████████████████████████████████████████▍ | 50/160 [00:29<01:00, 1.81it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0027, 'learning_rate': 0.0007569444444444444, 'epoch': 6.0}
{'loss': 0.0903, 'learning_rate': 0.00075, 'epoch': 6.12}
{'loss': 0.0194, 'learning_rate': 0.0007430555555555556, 'epoch': 6.24}
{'loss': 0.1515, 'learning_rate': 0.0007361111111111112, 'epoch': 6.35}
{'loss': 0.1667, 'learning_rate': 0.0007291666666666666, 'epoch': 6.47}
{'eval_loss': 0.010895016603171825, 'eval_runtime': 0.1706, 'eval_samples_per_second': 11.722, 'eval_steps_per_second': 11.722, 'epoch': 6.47}
34%|█████████████████████████████████████████████████████████████████▎ | 55/160 [00:32<00:58, 1.80it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.1637, 'learning_rate': 0.0007222222222222222, 'epoch': 6.59}
{'loss': 0.0302, 'learning_rate': 0.0007152777777777778, 'epoch': 6.71}
{'loss': 0.2117, 'learning_rate': 0.0007083333333333334, 'epoch': 6.82}
{'loss': 0.0893, 'learning_rate': 0.0007013888888888889, 'epoch': 6.94}
{'loss': 0.0446, 'learning_rate': 0.0006944444444444445, 'epoch': 7.06}
{'eval_loss': 0.017673835158348083, 'eval_runtime': 0.1683, 'eval_samples_per_second': 11.883, 'eval_steps_per_second': 11.883, 'epoch': 7.06}
38%|███████████████████████████████████████████████████████████████████████▎ | 60/160 [00:35<00:54, 1.82it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0124, 'learning_rate': 0.0006875, 'epoch': 7.18}
{'loss': 0.0157, 'learning_rate': 0.0006805555555555556, 'epoch': 7.29}
{'loss': 0.0426, 'learning_rate': 0.0006736111111111112, 'epoch': 7.41}
{'loss': 0.1031, 'learning_rate': 0.0006666666666666666, 'epoch': 7.53}
{'loss': 0.0127, 'learning_rate': 0.0006597222222222222, 'epoch': 7.65}
{'eval_loss': 0.04288101941347122, 'eval_runtime': 0.1691, 'eval_samples_per_second': 11.826, 'eval_steps_per_second': 11.826, 'epoch': 7.65}
41%|█████████████████████████████████████████████████████████████████████████████▏ | 65/160 [00:38<00:52, 1.81it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0545, 'learning_rate': 0.0006527777777777778, 'epoch': 7.76}
{'loss': 0.0147, 'learning_rate': 0.0006458333333333334, 'epoch': 7.88}
{'loss': 0.0342, 'learning_rate': 0.0006388888888888888, 'epoch': 8.0}
{'loss': 0.0109, 'learning_rate': 0.0006319444444444444, 'epoch': 8.12}
{'loss': 0.003, 'learning_rate': 0.000625, 'epoch': 8.24}
{'eval_loss': 0.003974442835897207, 'eval_runtime': 0.1712, 'eval_samples_per_second': 11.685, 'eval_steps_per_second': 11.685, 'epoch': 8.24}
44%|███████████████████████████████████████████████████████████████████████████████████▏ | 70/160 [00:41<00:49, 1.81it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0151, 'learning_rate': 0.0006180555555555556, 'epoch': 8.35}
{'loss': 0.0043, 'learning_rate': 0.0006111111111111112, 'epoch': 8.47}
{'loss': 0.0145, 'learning_rate': 0.0006041666666666666, 'epoch': 8.59}
{'loss': 0.0067, 'learning_rate': 0.0005972222222222222, 'epoch': 8.71}
{'loss': 0.005, 'learning_rate': 0.0005902777777777778, 'epoch': 8.82}
{'eval_loss': 0.004422146826982498, 'eval_runtime': 0.17, 'eval_samples_per_second': 11.762, 'eval_steps_per_second': 11.762, 'epoch': 8.82}
47%|█████████████████████████████████████████████████████████████████████████████████████████ | 75/160 [00:44<00:47, 1.81it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0384, 'learning_rate': 0.0005833333333333334, 'epoch': 8.94}
{'loss': 0.003, 'learning_rate': 0.0005763888888888889, 'epoch': 9.06}
{'loss': 0.0035, 'learning_rate': 0.0005694444444444445, 'epoch': 9.18}
{'loss': 0.0029, 'learning_rate': 0.0005625000000000001, 'epoch': 9.29}
{'loss': 0.0027, 'learning_rate': 0.0005555555555555556, 'epoch': 9.41}
{'eval_loss': 0.0012616427848115563, 'eval_runtime': 0.1692, 'eval_samples_per_second': 11.82, 'eval_steps_per_second': 11.82, 'epoch': 9.41}
50%|███████████████████████████████████████████████████████████████████████████████████████████████ | 80/160 [00:46<00:43, 1.85it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0105, 'learning_rate': 0.0005486111111111112, 'epoch': 9.53}
{'loss': 0.0019, 'learning_rate': 0.0005416666666666666, 'epoch': 9.65}
{'loss': 0.0058, 'learning_rate': 0.0005347222222222222, 'epoch': 9.76}
{'loss': 0.0027, 'learning_rate': 0.0005277777777777778, 'epoch': 9.88}
{'loss': 0.0236, 'learning_rate': 0.0005208333333333334, 'epoch': 10.0}
{'eval_loss': 0.0005044374847784638, 'eval_runtime': 0.1711, 'eval_samples_per_second': 11.691, 'eval_steps_per_second': 11.691, 'epoch': 10.0}
53%|████████████████████████████████████████████████████████████████████████████████████████████████████▉ | 85/160 [00:49<00:41, 1.79it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0024, 'learning_rate': 0.0005138888888888888, 'epoch': 10.12}
{'loss': 0.0009, 'learning_rate': 0.0005069444444444444, 'epoch': 10.24}
{'loss': 0.0009, 'learning_rate': 0.0005, 'epoch': 10.35}
{'loss': 0.0024, 'learning_rate': 0.0004930555555555556, 'epoch': 10.47}
{'loss': 0.0022, 'learning_rate': 0.0004861111111111111, 'epoch': 10.59}
{'eval_loss': 0.00045453320490196347, 'eval_runtime': 0.1717, 'eval_samples_per_second': 11.646, 'eval_steps_per_second': 11.646, 'epoch': 10.59}
56%|██████████████████████████████████████████████████████████████████████████████████████████████████████████▉ | 90/160 [00:52<00:38, 1.80it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0014, 'learning_rate': 0.0004791666666666667, 'epoch': 10.71}
{'loss': 0.0009, 'learning_rate': 0.00047222222222222224, 'epoch': 10.82}
{'loss': 0.0047, 'learning_rate': 0.0004652777777777778, 'epoch': 10.94}
{'loss': 0.0017, 'learning_rate': 0.0004583333333333333, 'epoch': 11.06}
{'loss': 0.0011, 'learning_rate': 0.0004513888888888889, 'epoch': 11.18}
{'eval_loss': 0.0004512905434239656, 'eval_runtime': 0.1693, 'eval_samples_per_second': 11.816, 'eval_steps_per_second': 11.816, 'epoch': 11.18}
59%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████▊ | 95/160 [00:55<00:35, 1.81it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.001, 'learning_rate': 0.0004444444444444444, 'epoch': 11.29}
{'loss': 0.0006, 'learning_rate': 0.0004375, 'epoch': 11.41}
{'loss': 0.0006, 'learning_rate': 0.0004305555555555556, 'epoch': 11.53}
{'loss': 0.0015, 'learning_rate': 0.0004236111111111111, 'epoch': 11.65}
{'loss': 0.0035, 'learning_rate': 0.0004166666666666667, 'epoch': 11.76}
{'eval_loss': 0.00042770570144057274, 'eval_runtime': 0.1702, 'eval_samples_per_second': 11.75, 'eval_steps_per_second': 11.75, 'epoch': 11.76}
62%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ | 100/160 [00:58<00:34, 1.76it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0008, 'learning_rate': 0.00040972222222222224, 'epoch': 11.88}
{'loss': 0.0013, 'learning_rate': 0.0004027777777777778, 'epoch': 12.0}
{'loss': 0.0005, 'learning_rate': 0.0003958333333333333, 'epoch': 12.12}
{'loss': 0.0006, 'learning_rate': 0.0003888888888888889, 'epoch': 12.24}
{'loss': 0.0004, 'learning_rate': 0.0003819444444444444, 'epoch': 12.35}
{'eval_loss': 0.0004152616602368653, 'eval_runtime': 0.1709, 'eval_samples_per_second': 11.704, 'eval_steps_per_second': 11.704, 'epoch': 12.35}
66%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ | 105/160 [01:01<00:29, 1.84it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0004, 'learning_rate': 0.000375, 'epoch': 12.47}
{'loss': 0.0014, 'learning_rate': 0.0003680555555555556, 'epoch': 12.59}
{'loss': 0.0004, 'learning_rate': 0.0003611111111111111, 'epoch': 12.71}
{'loss': 0.001, 'learning_rate': 0.0003541666666666667, 'epoch': 12.82}
{'loss': 0.0011, 'learning_rate': 0.00034722222222222224, 'epoch': 12.94}
{'eval_loss': 0.0003934216219931841, 'eval_runtime': 0.1709, 'eval_samples_per_second': 11.706, 'eval_steps_per_second': 11.706, 'epoch': 12.94}
69%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▉ | 110/160 [01:04<00:28, 1.77it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0003, 'learning_rate': 0.0003402777777777778, 'epoch': 13.06}
{'loss': 0.0011, 'learning_rate': 0.0003333333333333333, 'epoch': 13.18}
{'loss': 0.0004, 'learning_rate': 0.0003263888888888889, 'epoch': 13.29}
{'loss': 0.0004, 'learning_rate': 0.0003194444444444444, 'epoch': 13.41}
{'loss': 0.0005, 'learning_rate': 0.0003125, 'epoch': 13.53}
{'eval_loss': 0.0003844855527859181, 'eval_runtime': 0.171, 'eval_samples_per_second': 11.694, 'eval_steps_per_second': 11.694, 'epoch': 13.53}
72%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▊ | 115/160 [01:07<00:24, 1.81it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0004, 'learning_rate': 0.0003055555555555556, 'epoch': 13.65}
{'loss': 0.0007, 'learning_rate': 0.0002986111111111111, 'epoch': 13.76}
{'loss': 0.0004, 'learning_rate': 0.0002916666666666667, 'epoch': 13.88}
{'loss': 0.0006, 'learning_rate': 0.00028472222222222223, 'epoch': 14.0}
{'loss': 0.0007, 'learning_rate': 0.0002777777777777778, 'epoch': 14.12}
{'eval_loss': 0.00029086240101605654, 'eval_runtime': 0.1713, 'eval_samples_per_second': 11.673, 'eval_steps_per_second': 11.673, 'epoch': 14.12}
75%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▊ | 120/160 [01:09<00:22, 1.78it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0004, 'learning_rate': 0.0002708333333333333, 'epoch': 14.24}
{'loss': 0.0004, 'learning_rate': 0.0002638888888888889, 'epoch': 14.35}
{'loss': 0.0007, 'learning_rate': 0.0002569444444444444, 'epoch': 14.47}
{'loss': 0.0003, 'learning_rate': 0.00025, 'epoch': 14.59}
{'loss': 0.0003, 'learning_rate': 0.00024305555555555555, 'epoch': 14.71}
{'eval_loss': 0.00020883249817416072, 'eval_runtime': 0.1722, 'eval_samples_per_second': 11.611, 'eval_steps_per_second': 11.611, 'epoch': 14.71}
78%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▋ | 125/160 [01:12<00:19, 1.81it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0008, 'learning_rate': 0.00023611111111111112, 'epoch': 14.82}
{'loss': 0.0002, 'learning_rate': 0.00022916666666666666, 'epoch': 14.94}
{'loss': 0.0003, 'learning_rate': 0.0002222222222222222, 'epoch': 15.06}
{'loss': 0.0002, 'learning_rate': 0.0002152777777777778, 'epoch': 15.18}
{'loss': 0.0005, 'learning_rate': 0.00020833333333333335, 'epoch': 15.29}
{'eval_loss': 0.00018148773233406246, 'eval_runtime': 0.172, 'eval_samples_per_second': 11.63, 'eval_steps_per_second': 11.63, 'epoch': 15.29}
81%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▌ | 130/160 [01:15<00:16, 1.79it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0002, 'learning_rate': 0.0002013888888888889, 'epoch': 15.41}
{'loss': 0.0002, 'learning_rate': 0.00019444444444444446, 'epoch': 15.53}
{'loss': 0.0008, 'learning_rate': 0.0001875, 'epoch': 15.65}
{'loss': 0.0004, 'learning_rate': 0.00018055555555555555, 'epoch': 15.76}
{'loss': 0.0005, 'learning_rate': 0.00017361111111111112, 'epoch': 15.88}
{'eval_loss': 0.00016719780978746712, 'eval_runtime': 0.1707, 'eval_samples_per_second': 11.716, 'eval_steps_per_second': 11.716, 'epoch': 15.88}
84%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▍ | 135/160 [01:18<00:13, 1.79it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0002, 'learning_rate': 0.00016666666666666666, 'epoch': 16.0}
{'loss': 0.0002, 'learning_rate': 0.0001597222222222222, 'epoch': 16.12}
{'loss': 0.0002, 'learning_rate': 0.0001527777777777778, 'epoch': 16.24}
{'loss': 0.0003, 'learning_rate': 0.00014583333333333335, 'epoch': 16.35}
{'loss': 0.0004, 'learning_rate': 0.0001388888888888889, 'epoch': 16.47}
{'eval_loss': 0.00015975727001205087, 'eval_runtime': 0.1705, 'eval_samples_per_second': 11.728, 'eval_steps_per_second': 11.728, 'epoch': 16.47}
88%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▍ | 140/160 [01:21<00:11, 1.80it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0002, 'learning_rate': 0.00013194444444444446, 'epoch': 16.59}
{'loss': 0.0007, 'learning_rate': 0.000125, 'epoch': 16.71}
{'loss': 0.0002, 'learning_rate': 0.00011805555555555556, 'epoch': 16.82}
{'loss': 0.0005, 'learning_rate': 0.0001111111111111111, 'epoch': 16.94}
{'loss': 0.0005, 'learning_rate': 0.00010416666666666667, 'epoch': 17.06}
{'eval_loss': 0.00015415673260577023, 'eval_runtime': 0.1704, 'eval_samples_per_second': 11.737, 'eval_steps_per_second': 11.737, 'epoch': 17.06}
91%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▎ | 145/160 [01:24<00:08, 1.76it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0001, 'learning_rate': 9.722222222222223e-05, 'epoch': 17.18}
{'loss': 0.0002, 'learning_rate': 9.027777777777777e-05, 'epoch': 17.29}
{'loss': 0.0003, 'learning_rate': 8.333333333333333e-05, 'epoch': 17.41}
{'loss': 0.0002, 'learning_rate': 7.63888888888889e-05, 'epoch': 17.53}
{'loss': 0.0007, 'learning_rate': 6.944444444444444e-05, 'epoch': 17.65}
{'eval_loss': 0.00015087085193954408, 'eval_runtime': 0.1715, 'eval_samples_per_second': 11.662, 'eval_steps_per_second': 11.662, 'epoch': 17.65}
94%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▏ | 150/160 [01:27<00:05, 1.77it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0002, 'learning_rate': 6.25e-05, 'epoch': 17.76}
{'loss': 0.0003, 'learning_rate': 5.555555555555555e-05, 'epoch': 17.88}
{'loss': 0.0004, 'learning_rate': 4.8611111111111115e-05, 'epoch': 18.0}
{'loss': 0.0007, 'learning_rate': 4.1666666666666665e-05, 'epoch': 18.12}
{'loss': 0.0002, 'learning_rate': 3.472222222222222e-05, 'epoch': 18.24}
{'eval_loss': 0.00014878850197419524, 'eval_runtime': 0.1731, 'eval_samples_per_second': 11.554, 'eval_steps_per_second': 11.554, 'epoch': 18.24}
97%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████ | 155/160 [01:30<00:02, 1.79it/s/root/anaconda3/lib/python3.11/site-packages/torch/utils/checkpoint.py:429: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants.
warnings.warn(
{'loss': 0.0001, 'learning_rate': 2.7777777777777776e-05, 'epoch': 18.35}
{'loss': 0.0002, 'learning_rate': 2.0833333333333333e-05, 'epoch': 18.47}
{'loss': 0.0003, 'learning_rate': 1.3888888888888888e-05, 'epoch': 18.59}
{'loss': 0.0005, 'learning_rate': 6.944444444444444e-06, 'epoch': 18.71}
{'loss': 0.0004, 'learning_rate': 0.0, 'epoch': 18.82}
{'eval_loss': 0.00014794316666666418, 'eval_runtime': 0.1724, 'eval_samples_per_second': 11.602, 'eval_steps_per_second': 11.602, 'epoch': 18.82}
{'train_runtime': 99.4155, 'train_samples_per_second': 3.42, 'train_steps_per_second': 1.609, 'train_loss': 0.2966294680955798, 'epoch': 18.82}
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 160/160 [01:33<00:00, 1.72it/s]
wandb: Waiting for W&B process to finish... (success).
wandb:
wandb: Run history:
wandb: eval/loss █▅▃▁▂▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁
wandb: eval/runtime ▁▂▂▄▅▃▃▄▅▃▆▃▄▆▅▄▆▇▄▅▆▆▆▆▇▇▆▅▅▆█▇
wandb: eval/samples_per_second █▇▇▄▄▆▆▅▄▅▃▆▅▃▄▅▃▂▅▄▃▃▃▃▂▂▃▃▄▃▁▂
wandb: eval/steps_per_second █▇▇▄▄▆▆▅▄▅▃▆▅▃▄▅▃▂▅▄▃▃▃▃▂▂▃▃▄▃▁▂
wandb: train/epoch ▁▁▁▂▂▂▂▂▂▃▃▃▃▃▄▄▄▄▄▄▅▅▅▅▅▅▆▆▆▆▆▇▇▇▇▇▇███
wandb: train/global_step ▁▁▁▂▂▂▂▂▂▃▃▃▃▃▄▄▄▄▄▄▅▅▅▅▅▅▆▆▆▆▆▇▇▇▇▇▇███
wandb: train/learning_rate ▂▄▅▇███▇▇▇▇▇▆▆▆▆▆▅▅▅▅▅▄▄▄▄▄▃▃▃▃▃▂▂▂▂▂▁▁▁
wandb: train/loss █▇▅▅▃▃▂▃▂▁▂▁▁▁▂▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁
wandb: train/total_flos ▁
wandb: train/train_loss ▁
wandb: train/train_runtime ▁
wandb: train/train_samples_per_second ▁
wandb: train/train_steps_per_second ▁
wandb:
wandb: Run summary:
wandb: eval/loss 0.00015
wandb: eval/runtime 0.1724
wandb: eval/samples_per_second 11.602
wandb: eval/steps_per_second 11.602
wandb: train/epoch 18.82
wandb: train/global_step 160
wandb: train/learning_rate 0.0
wandb: train/loss 0.0004
wandb: train/total_flos 293076187017216.0
wandb: train/train_loss 0.29663
wandb: train/train_runtime 99.4155
wandb: train/train_samples_per_second 3.42
wandb: train/train_steps_per_second 1.609
wandb:
wandb: You can sync this run to the cloud by running:
wandb: wandb sync /root/chatGLM-6B-QLoRA-main/wandb/offline-run-20231010_100222-9j69u4g5
wandb: Find logs at: ./wandb/offline-run-20231010_100222-9j69u4g5/logs
训练完成会在saved_files文件夹下生成checkpoint及adapter文件。
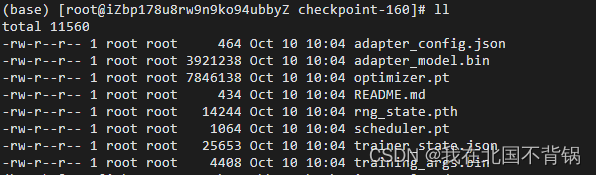
adapter推理
创建test.py脚本,添加以下代码:
import torch
from transformers import AutoModel, AutoTokenizer, BitsAndBytesConfig
from peft import PeftModel, PeftConfig
peft_model_path = 'saved_files/chatGLM_6B_QLoRA_t32'
config = PeftConfig.from_pretrained(peft_model_path)
q_config = BitsAndBytesConfig(load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.float32)
base_model = AutoModel.from_pretrained(config.base_model_name_or_path,
quantization_config=q_config,
trust_remote_code=True,
device_map='auto')
input_text = '配网故障故障评价的指标是什么'
print(f'输入:\n{input_text}')
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path, trust_remote_code=True)
response, history = base_model.chat(tokenizer=tokenizer, query=input_text)
print(f'微调前:\n{response}')
model = PeftModel.from_pretrained(base_model, peft_model_path)
response, history = model.chat(tokenizer=tokenizer, query=input_text)
print(f'微调后: \n{response}')
推理结果如下:
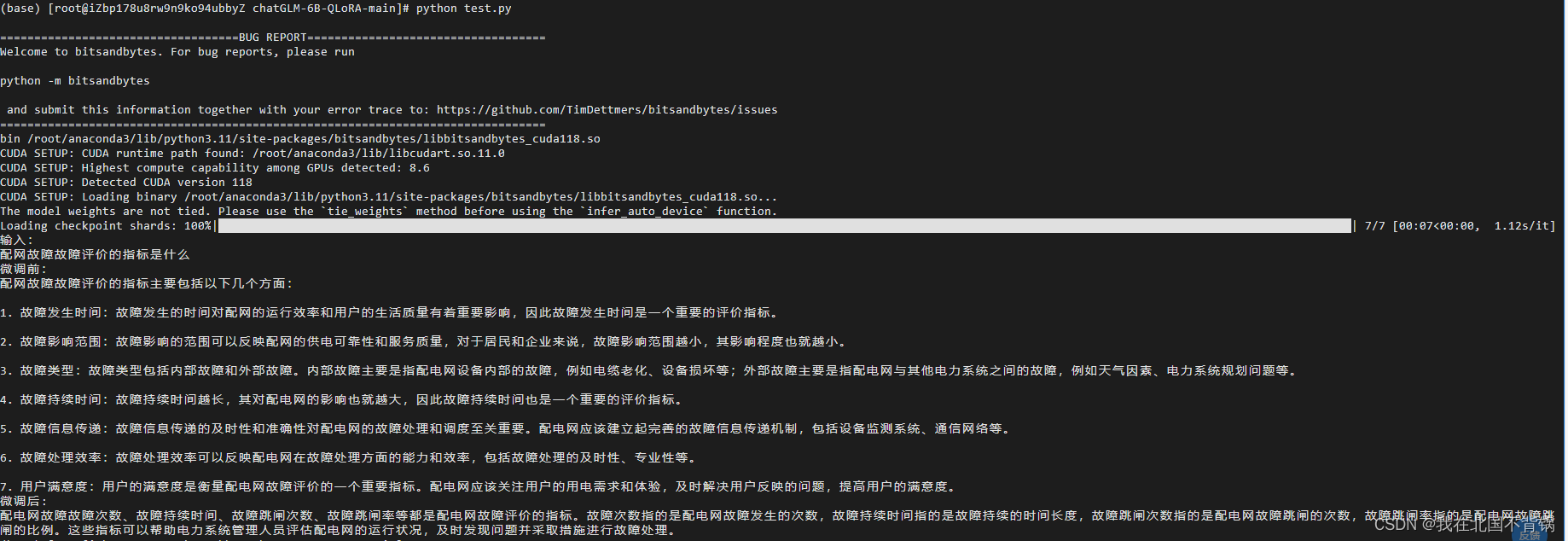
通过对比微调前和微调后的回答结果,可见微调后的回答更贴近数据集的内容:

模型微调达到了预期目标。
模型合并与量化
合并微调的Lora model和基座base model。
使用的项目目前使用的peft为dev的版本,在合并lora model和base model时,会报错。项目推荐将peft的版本回退到0.3.0。
pip install peft==0.3.0
创建merge_lora_and_quantize.sh脚本,添加如下命令:
python3 merge_lora_and_quantize.py \
--lora_path saved_files/chatGLM_6B_QLoRA_t32 \
--output_path /tmp/merged_qlora_model_4bit \
--remote_scripts_dir /root/ChatGLM/ChatGLM2-6B-main/zhbr/chatglm2-6b \
--qbits 4
remote_scripts_dir 为ChatGLM2的本地地址
qbits 量化为4bit
执行脚本,运行结果如下:
(base) [root@iZbp178u8rw9n9ko94ubbyZ chatGLM-6B-QLoRA-main]# sh merge_lora_and_quantize.sh
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please run
python -m bitsandbytes
and submit this information together with your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
bin /root/anaconda3/lib/python3.11/site-packages/bitsandbytes/libbitsandbytes_cuda118.so
CUDA SETUP: CUDA runtime path found: /root/anaconda3/lib/libcudart.so.11.0
CUDA SETUP: Highest compute capability among GPUs detected: 8.6
CUDA SETUP: Detected CUDA version 118
CUDA SETUP: Loading binary /root/anaconda3/lib/python3.11/site-packages/bitsandbytes/libbitsandbytes_cuda118.so...
The model weights are not tied. Please use the `tie_weights` method before using the `infer_auto_device` function.
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7/7 [00:09<00:00, 1.40s/it]
2023-10-10 10:39:59.215 | INFO | __main__:main:58 - Lora model和base model成功merge, 并量化为4bits, 保存在/tmp/merged_qlora_model_4bit
模型合并的如下所示:
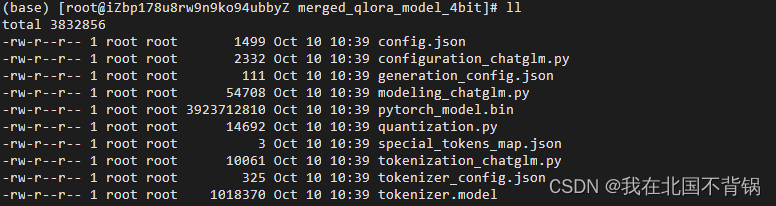
合并后的模型推理
创建test2.py,添加如下代码:
from transformers import AutoModel, AutoTokenizer
model_path = '/tmp/merged_qlora_model_4bit'
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModel.from_pretrained(model_path, trust_remote_code=True).half().cuda()
input_text = '配网故障故障评价的指标是什么'
response, history = model.chat(tokenizer=tokenizer, query=input_text)
print(response)
推理结果如下,贴合训练数据集的内容:

测试lora微调后是否会产生灾难性遗忘问题:
1、以李白的风格写一首描述秋天的七言律诗:

2、开车过程如何减少燃油消耗
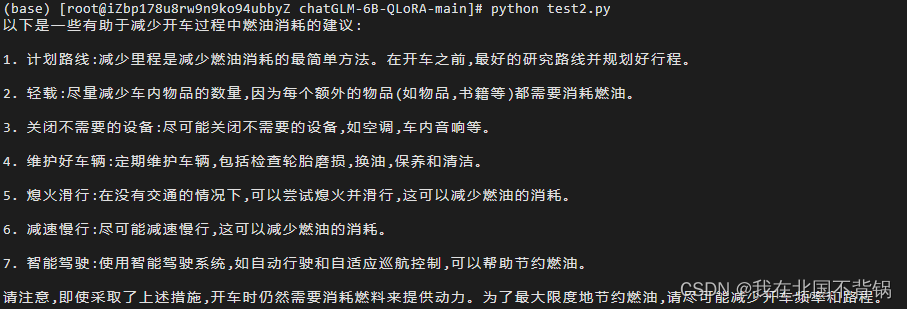
测试没有出现类似P-Tuning微调出现的严重遗忘问题。
微调过程中遇到的问题
1、出现wandb让选择W&B Account
解决方法:
1、执行wandb off,关掉即可
2、在train_qlora.py开头配置环境变量:
os.environ[“WANDB_DISABLED”] = “true”
2、微调后saved_files中只有adapter_config.json和adapter_model.bin两个文件,没有checkpoint:

正常训练完不只这两个文件,还会有多个checkpoints。原因是训练的步数太少,连保存checkpoint的step都没有达到。
解决方法:
适当调整chatGLM_6B_QLoRA.json中的配置
参考:
https://github.com/shuxueslpi/chatGLM-6B-QLoRA
https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments