贡献:
- 提出了超大卷积,用于CNN中长距离特征相互作用的有效建模。与ParCNetV1相比,它能够在所有空间位置上进行均匀卷积,同时消除了对额外位置编码的需求。
- 提出了两个分叉门单元(空间BGU和通道BGU),它们是紧凑而强大的注意力模块。它们提高了ParCNetV2的性能,并且可以很容易地集成到其他网络结构中。
- 我们将超大卷积引入到CNNs的浅层中,并统一了跨块的局部全局卷积设计。
具体来说,我们提出了一种新的卷积神经网络,即ParCNetV2,它将位置感知的圆形卷积(ParCNet)扩展为超大卷积和分叉门单元,以提高注意力。
超大规模的卷积使用了一个具有两倍输入大小的内核,通过一个全局接受域来建模长期依赖关系。
同时,通过去除卷积核的位移不变特性,即当核大小为输入大小的两倍时,不同空间位置的有效核是不同的,从而实现隐式的位置编码。
该分岔门单元实现了一种类似于Transformer中的自注意的注意机制。
它是通过两个分支的元素乘法来实现的,一个作为特征变换,另一个作为注意权重。
此外,我们还引入了一个统一的局部全局卷积块来统一早期和晚期卷积块的设计。大量的实验表明,我们的方法比其他卷积神经网络和混合模型的cnn和变压器有优势。
1、介绍
为了挑战CNN的极限:ParCNetV1通过编码更广泛的空间上下文,成功地提高了cnn的性能。
具体来说,parnetv1在cnn中引入了位置感知的圆形卷积(ParC)。采用输入特征图大小(C × H×1, C×1×W)的深度圆形一维卷积实现全局接受域。为了避免全局导致的空间过度平滑,ParCNetV1对特征输入进行了绝对位置编码增强,以保证特征输出仍然是位置敏感的。采用挤压激励块,将关注机构引入框架。
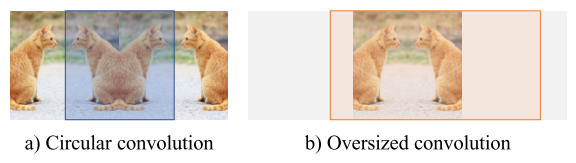
图2:圆形卷积与超大卷积的比较。为了便于演示,我们只展示了水平卷积。a)在ParCNetV1中进行圆卷积不可避免地会使图像边界处的上下文信息失真。b)过大的卷积在保持整个图像的全局接受域的同时,解决了失真问题。
虽然提高了模型的效率和精度,但仍存在一些设计缺陷。
首先,如图2所示,圆形填充通过对图像边界进行卷积而引入空间畸变。
其次,与Transformer相比,注意力设计相对薄弱,可能会限制框架的性能。
第三,在CNNs中,将全局卷积应用到所有的块是不可行的,特别是对于那些较浅的块,由于计算成本高和过度平滑的影响。
为了解决这些问题,我们提出了一个纯卷积神经网络架构,称为parnetv2。它由三个基本改进组成:
首先,通过加倍循环卷积核并去除绝对位置编码,将核的大小推到极致。如图2所示,卷积运算通过较大的填充(等于输入的大小),避免了图像边界的特征失真。通过使用常量拨入,过大的内核在与特性特征图进行卷积时隐式地对空间位置进行编码。它使我们能够在不损害网络性能的情况下丢弃位置编码模块。
其次,原始的ParC块在通道混合阶段的末端插入了一个有限的注意机制。在我们新设计的块中,我们在token混合阶段(空间BGU)和通道混合阶段(通道BGU)提出了一种更灵活的分岔门单元(BGU)。与挤压激励块相比,BGU更强,更紧凑,更通用,与各种结构结合,引起空间关注和渠道关注。增强的注意机制也简化了我们的ParC V2块,因为两个阶段都采用一致的BGU结构。
最后,与只在后期CNN块上应用大核卷积的ParCNetV1不同,我们将大核卷积与局部深度卷积混合在所有块上,统一了块的设计。这两种类型的卷积都是在输入特征映射通道上操作的。这种渐进的设计将局部特征和全局特征结合在一个卷积步骤中,不像其他许多作品那样将两个部分按顺序堆叠或作为两个独立的分支。为此,所得到的重新设计的ParC V2结构能够在一个块中执行局部卷积、全局卷积、令牌通道混合和基于BGU-based attention。
3、方法
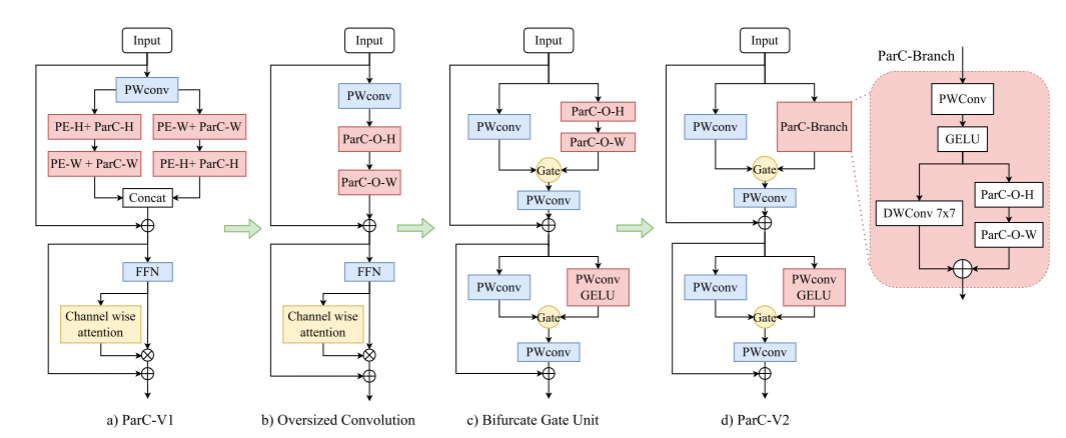
图3:从原始ParC V1到ParC V2块的转换。与ParCNetV 1相比,我们首先引入超大卷积,在简化架构的同时进一步增强容量;设计了分叉门单元,提高了效率,加强了注意力;最后我们提出了均匀局部-全局块,并以此构造了整个网络。
图3展示了一个parnetv2架构的概述。与原始的ParCNet(图3a)相比,我们首先将位置感知的圆形卷积替换为超大卷积,以编码长依赖关系和位置信息(图3b)。然后我们引入分叉门单元作为一个更强的注意机制(图3c)。最后,我们提出了一个平衡局部和全局卷积的统一块,以构建完整的ParCNetV2(图3d)。下面的部分将描述这些组件的详细信息。
3.1 超大卷积
在ParCNetV1中,模型分为两个分支,交替进行垂直卷积和水平卷积的顺序。
然而,我们发现改变顺序并不影响输出(补充证明),因此为了简单起见,我们只保留一个分支。
为了进一步增强模型的容量并纳入长期空间环境,我们引入了一个超大深度的卷积,其内核大小约为输入特征大小的两倍(ParC-O-H和ParC-O-W),如图3b所示。
在本节中,我们将详细介绍超大卷积,并讨论其有效性、效率和适应性。
3.1.1 公式化
我们表示输入feature map为X∈RC×H×W,其中C、H、W分别表示X的通道数、高度、宽度。垂直和水平的超大卷积的核权为kh∈RC×(2H−1)×1和kw∈RC×1×(2W−1)。
设下标0表示kh和kw的中心点。如图4所示,我们选择这个大小是因为它自然覆盖了每个位置的全局接受域,并且保持输出大小与输入大小相同,不需要任何后处理。相反,较小的内核不能同时保留位置线索并提供一个全局接受域,而较大的内核需要后处理来调整输出大小。
为了计算超大卷积Zi,j在位置(i, j)处的输出,我们使用以下公式:
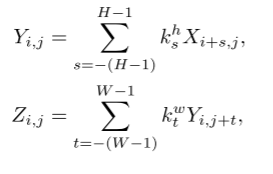
式中(1)式为ParC-O-H,(2)式为ParCO-W。零填充意味着,如果i /∈[0,H−1]或j /∈[0,W−1],Xi,j = 0, Yi,j = 0。
填充操作设计用于处理过大的卷积,它不仅编码全局依赖关系,还编码位置信息。对于水平卷积,我们在左右两边应用W−1像素的零填充,其中W是输入特征的宽度。垂直卷积也可以进行类似的操作。该模式保持输出特征大小与输入特征大小一致,并根据空间位置将部分卷积核参数归零,从而隐式编码位置线索。
3.1.2 有效性
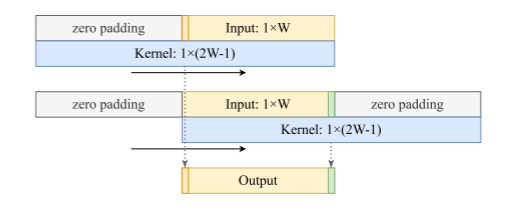
图4:超大卷积图。内核的大小几乎是输入特性特征图的两倍,并且使用了零填充来保持输出分辨率与输入相同。
超大的卷积有两个优点。
首先,它通过使用零填充将位置信息嵌入到每个位置来编码位置信息,消除了位置嵌入的需要。如图4所示,输出中的每个位置通过不同的参数跨输入特征进行变换,从而将位置信息嵌入到模型的权值中。它类似于相对位置嵌入,而超大卷积在核权值中同时对空间上下文和位置信息进行编码。因此,不再需要位置嵌入,因此为了使网络更简洁而放弃了位置嵌入。
其次,在有限的计算复杂度下提高了模型容量。例如,在ParCNetV2-Tiny中,最大的超大内核被扩展到111 × 1和1 × 111,输入尺寸为224 × 224。如此大的卷积核将大大提高模型的容量。据我们所知,它实现了目前主流视觉cnn中最大的卷积核。其他关于大型内核的研究使用了空间密集的卷积形式,这需要大量的计算。相比之下,我们的超大卷积以更少的计算成本提高了性能。它使我们的模型能够实现最先进的性能,这表明它是一个有效的操作。
3.1.3 效率
虽然超大卷积的计算量比以前的大型核卷积网络要少,但硬件对多片段结构的支持能力较差,尤其是PyTorch。这是因为PyTorch没有针对多片段进行优化,因此我们在RepLKNet之后实现了一个逐块(逆)隐式gemm算法。对比结果如图1所示。与其他最近提出的模型相比,我们的ParCNetV2在准确性和推理速度方面都具有明显的优势。此外,即使是在Vanilla PyTorch上,我们的ParCNetV2也在准确性和速度之间取得了卓越的平衡。额外的结果可以在补充材料中找到。
3.1.4 对多尺度输入的适应性
为了处理不同分辨率的输入图像,首先用线性插值将每个卷积核放大到C×(2H−1)×1和C× 1 ×(2W−1)。此外,该方法保持模型的全局接受域为任意输入尺寸,并学会提取尺度不变特征。
3.2 分岔门单元
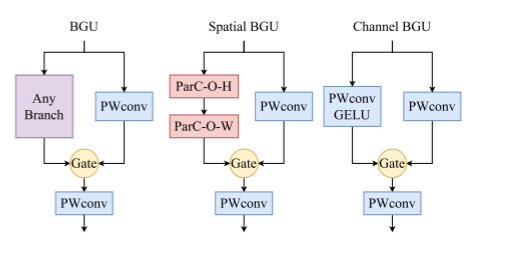
图5:分叉门单元(BGU)的插图。我们提出了一种通用的BGU,它可以很容易地集成到各种网络结构中。对于空间GPU,我们插入ParC分支和逐点卷积来提取空间特征。而在BGU信道中,我们简单地采用逐点卷积来进行信道混合。
为了使模型数据驱动为ViT模型,parnetv1采用了挤压-激励模块,验证了挤压-激励模块可以提高模型在各种任务上的性能。在本工作中,对注意机制进行了改进:增强了注意,提高了计算效率。具体来说,我们在门控线性单元(GLU)的启发下提出了分岔门单元(BGU)结构,通过门控机制改进了MLP。BGU继承了GLU的高计算效率,在单个单元内完成注意力和特征提取。与传统的在两个相似的特征中插入门操作的算法不同,该算法对来自两个分支的两个特征进行门操作。一个分支采用逐点卷积作为注意权重。另一种是根据模块的目的对特征进行变换,即ParC分支提取空间信息进行空间交互,逐点卷积进行信道混合。因此,将BGU设计扩展到空间BGU模块和通道BGU模块,使其成为如图5所示的通用模块。最后,两个分支的输出通过逐元素的乘法运算和额外的逐点卷积进行融合。本节对其进行了详细的介绍,并讨论了其与其他注意事项的区别。
3.2.1 空间BGU
在空间BGU中,我们的目标是提取具有代表性的空间信息,包括局部和全局依赖关系。我们采用ParC分支作为特征变换分支,它包括一个点卷积、一个标准的局部深度卷积和一个超大的可分离卷积。基本上,我们的空间BGU定义为:
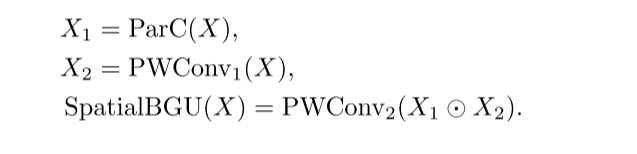
3.2.2 通道BGU
对于信道混合模块,普通变压器的原始前馈网络(FFN)通常包含两个由GELU激活隔开的逐点卷积。第一层将通道的数量扩大了1倍,而第二层则将尺寸缩小到原来的尺寸:
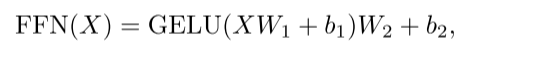
其中,W1∈RC×αC, W2∈RαC×C表示两个点卷积的权值,b1和b2分别为偏置项。在我们的BGU通道中,我们将隐藏层拆分为两个分支,并使用基于元素的乘法进行合并。整个模块定义为:
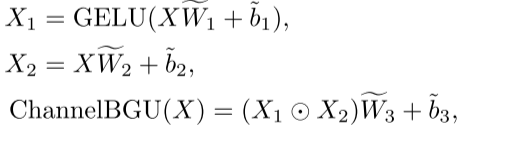
其中W1,W2∈RC× αC和W3∈R αC×C分别表示点方向卷积的权值,属于b1,属于b2,属于b3分别表示偏差。我们调整~ α以适应模型大小接近原始的FFN(补充细节)。
3.2.3 与以前的注意力机制进行比较
大量类似骨干分支的参数。BGU是一个紧凑的注意机制,具有更平衡的分支。每个分支不存在下采样或瓶颈。此外,BGU并没有增加模型的参数数量。经典的通道注意和空间注意由两个不平衡的分支组成:重主干分支和轻注意分支。注意力分支通过全局平均池化、跨渠道或空间的共享注意力价值以及瓶颈结构来丢弃大量信息。但是,它包含了大量类似于骨干分支的参数。BGU是一个紧凑的注意机制,具有更平衡的分支。每个分支不存在下采样或瓶颈。此外,BGU并没有增加模型的参数数量。
3.3 均匀局部全局卷积
parnetv1采用了两种不同的网络结构,一种是浅层的传统卷积块MBConvs[22],另一种是深层的ParC操作。我们在早期和晚期将全局卷积扩展到每个块,因为这表明在浅层中,一个大的接受域也是关键的,特别是在下游任务中[12,34]。我们为整个网络设计了一个由局部卷积和全局组成的统一块。如图3所示,我们首先采用逐点卷积的方式融合信道信息。然后我们将这个特征传递给两个分支,其中一个分支是标准的7x7深度卷积来提取局部信号,另一个分支是一个超大的卷积来对全局独立性进行建模。最后,我们添加两个分支来创建多尺度特征。形式上,均匀局部全局卷积定义为:
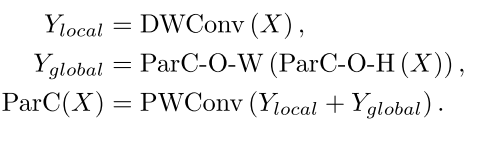
3.4 pcnetv2
基于上述提出的模块,我们构建了具有四种不同尺度的ParCNetV2。受[35,36]的启发,我们采用四阶段分层结构,每个阶段的通道和块数如表1所示。为了与ParC-ConvNeXt-T (0.5×W)进行比较,设计了parnetv2 - xt, ParC-ConvNeXt-T是parnetv1的四阶段版本[69]。设计成parnetv2 -t、parnetv2 - s和parnetv2 - b是为了与最先进的网络进行比较。信道BGU的扩展比(ratio)设置为2.5,复杂度接近于原始FFN。
4 实验
在本节中,我们展示定量和定性的实验,以证明所提模型的有效性。首先,我们在ImageNet-1K[11]上进行了图像分类实验。我们将其性能与卷积神经网络进行了比较,结果表明,我们的parnetv2在包括parnetv1在内的纯卷积网络上的性能更好。然后,将该模型与变压器和混合神经网络进行了比较。接下来,我们在COCO[33]上进行目标检测和实例分割,在ADE20K数据集上进行语义分割等下游任务的实验[75]。最后,我们比较了在gpu和边缘设备上的推理延迟。所有的实验都是基于PyTorch[40]实现的。
4.1 与cnn性能比较
我们在使用最广泛的基准数据集ImageNet-1K[11]上进行图像分类。我们在训练集上训练ParCNetV2模型,并在验证集上报告最高的准确性。我们遵循与ConvNeXt[36]中使用的相同的训练超参数和增强,只是批处理大小限制为2048,初始学习速率设置为4×−3。我们也用Resscale[53]代替LayerScale来稳定训练。
与纯卷积网络在图像分类上的比较如表2所示。显然,在各种模型规模上,parnetv2的性能大大超过了其他卷积网络,包括ResNet的变体(ResNet [19, 62], ResNeSt[70])、NAS架构(ReGNetY[42])、ConvNeXt[36]和MetaFormer架构(PoolFormer[67])。具体来说,我们的研究结果是parnetv2t优于parnetv1 - 27m[69],这表明我们的方法沿着更大的卷积和更强的注意机制走得更远。此外,在参数和复杂度上,parnetv2 - s的性能优于其他所有的cnn,甚至是两倍大的cnn,这表明我们的模型是非常有效的。
4.2 与vit和混合模型的性能比较
brid模型,parnetv2 - t在参数更少的情况下优于CvT[64]、CoAtNet[9]、Uniformer[31]和Next-ViT[30]。结合以上4.1节中对纯卷积的分析,我们所提出的模型在各种结构上具有可比参数和计算规模,实现了更好的分类精度。
4.3 消融实验
4.3.1 超大卷积
过大的卷积增加了模型的容量,并对位置信息进行编码。没有过大的卷积,模型不仅丧失了容量和位置信息,而且丧失了学习远程依赖关系的能力。通过比较基线和第1行,没有过大卷积的模型的准确性大幅下降0.6% (79.4% vs . 78.9%)。它说明了远程依赖关系对网络很重要。分岔门单位。超大卷积增加了模型的容量,并对位置信息进行编码。没有过大的卷积,模型不仅丧失了容量和位置信息,而且丧失了学习远程依赖关系的能力。通过比较基线和第1行,没有过大卷积的模型的准确性大幅下降0.6% (79.4% vs . 78.9%)。它说明了远程依赖关系对网络很重要。
4.3.2 分岔门单位
分岔门单元是将数据驱动操作引入parnetv2的重要机制。它增加了非线性,提高了拟合能力。如基线,第2行和第3行所示,在没有空间BGU的情况下,降解率为0.2% (79.4% vs . 79.2%),在没有通道BGU的情况下,降解率为0.3%(79.4% vs . 79.1%)。它类似于ParC V1中挤压激励块的数据驱动操作,而我们的BGU在以下两点上不同。首先,BGU不会增加参数。α = 2.5时,我们的信道BGU比原始的FFN稍轻一些。第二,我们BGU的两个分支比较均衡。它们共享相似数量的参数和计算成本,不像大多数方法中的重主分支和轻量通道。
4.3.3 均匀局部全局卷积
均匀局部全局卷积块的目标是对各个阶段使用的块进行标准化。在ParCNetv1中,MobileNetV2块必须与ParC块混合,以构建整个网络。而在ParCNet V2中,整个网络是通过ParCNet V2块的叠加来构建的,如图1所示。这种统一的设计提供了更大的灵活性,并易于与其他结构组合。此外,均匀的设计使性能提高了0.2%。
5、结论
本文介绍了一个具有最先进性能的纯卷积神经网络——parnetv2。它扩展了超大卷积的位置感知循环卷积,并通过分叉门单元加强了注意力。此外,它采用统一的局部全局卷积块来统一早期和晚期卷积块的设计。我们在图像分类和语义分割方面进行了大量的实验,以证明本文提出的ParCNetV2体系结构的有效性和优越性。