一、介绍
近年来,大型语言模型的演进速度飞速发展。BERT成为最流行和最有效的模型之一,可以高精度地解决各种NLP任务。在BERT之后,一组其他模型随后出现在现场,也展示了出色的结果。
很容易观察到的明显趋势是,随着时间的推移,大型语言模型(LLM)往往会通过成倍增加它们所训练的参数和数据的数量而变得更加复杂。深度学习的研究表明,这种技术通常会带来更好的结果。不幸的是,机器学习世界已经处理了有关LLM的几个问题,可扩展性已成为有效训练,存储和使用它们的主要障碍。
考虑到这个问题,已经制定了压缩LLM的特殊技术。压缩算法的目标是减少训练时间、减少内存消耗或加速模型推理。实践中使用的三种最常见的压缩技术如下:
- 知识蒸馏涉及训练一个较小的模型,试图表示一个较大模型的行为。
- 量化是减少内存的过程,用于存储表示模型权重的数字。
- 修剪是指丢弃最不重要的模型权重。
在本文中,我们将了解应用于BERT的蒸馏机制,该机制导致了一种称为DistilBERT的新模型。顺便说一下,下面讨论的技术也可以应用于其他NLP模型。
二、蒸馏基础知识
蒸馏的目标是创建一个可以模仿较大模型的较小模型。在实践中,这意味着如果一个大型模型预测了某事,那么较小的模型应该做出类似的预测。
为了实现这一点,需要已经预先训练了一个更大的模型(在我们的例子中是BERT)。然后需要选择较小模型的架构。为了增加成功模仿的可能性,通常建议较小的模型具有与较大模型类似的体系结构,但参数数量较少。最后,较小的模型从较大模型对某个数据集所做的预测中学习。对于这个目标,选择一个适当的损失函数是至关重要的,这将有助于较小的模型更好地学习。
在蒸馏符号中,较大的模型称为教师,较小的模型称为学生。
通常,蒸馏程序在保鲜过程中应用,但也可以在微调期间应用。
三、迪斯蒂尔伯特
DistilBERT从BERT学习,并使用由三个组件组成的损失函数更新其权重:
- 屏蔽语言建模 (MLM) 丢失
- 蒸馏损失
- 相似性损失
下面,我们将讨论这些损失组成部分以及每个损失组成部分的必要性。然而,在深入研究之前,有必要了解softmax激活函数中称为温度的重要概念。温度概念用于DistilBERT损失函数。
四、软最高温度
通常将softmax变换视为神经网络的最后一层。Softmax 对所有模型输出进行归一化,因此它们的总和为 1,并且可以解释为概率。
存在一个softmax公式,其中模型的所有输出都除以温度参数T:
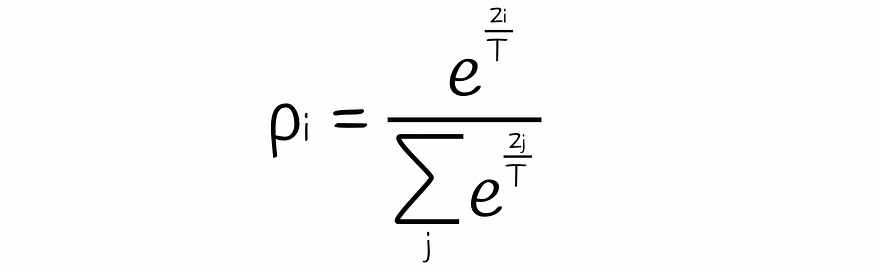
软最大温度公式。Pi 和 Zi 分别是第 i 个对象的模型输出和归一化概率。T 是温度参数。
温度T控制输出分布的平滑度:
- 如果 T > 1,则分布变得更平滑。
- 如果 T = 1,则如果应用正态 softmax,则分布相同。
- 如果 T < 1,则分布变得更加粗糙。
为了清楚起见,让我们看一个例子。考虑一个具有 5 个标签的分类任务,其中神经网络生成 5 个值,指示属于相应类的输入对象的置信度。对不同的 T 值应用 softmax 会导致不同的输出分布。
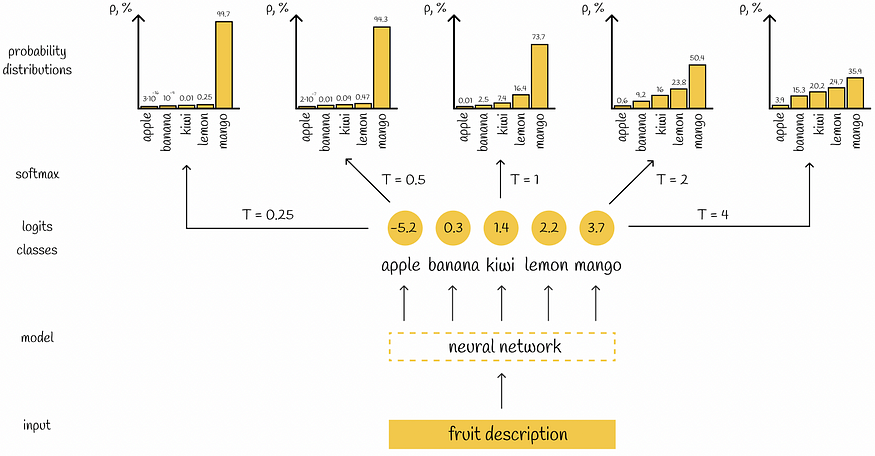
基于温度 T 生成不同概率分布的神经网络示例
温度越高,概率分布越平滑。
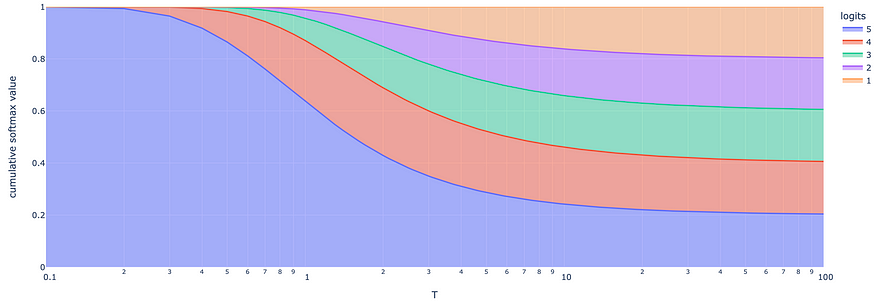
基于不同温度 T 值的对数(从 1 到 5 的自然数)的 Softmax 变换。随着温度的升高,softmax值彼此更加一致。
五、损失函数
5.1 屏蔽语言建模丢失
与教师模型(BERT)类似,在预训练期间,学生(DistilBERT)通过预测掩蔽语言建模任务来学习语言。在对某个令牌进行预测后,将预测的概率分布与教师模型的独热编码概率分布进行比较。
独热编码分布指定一个概率分布,其中最可能的令牌的概率设置为 1,所有其他令牌的概率设置为 0。
与大多数语言模型一样,交叉熵损失是在预测分布和真实分布之间计算的,学生模型的权重通过反向传播进行更新。

掩蔽语言建模损失计算示例
5.2 蒸馏损失
实际上,可以仅使用学生损失来训练学生模型。但是,在许多情况下,这可能还不够。仅使用学生损失的常见问题在于其 softmax 变换,其中温度 T 设置为 1。在实践中,T = 1 的结果分布结果是这样的形式:其中一个可能的标签具有接近 1 的非常高的概率,而所有其他标签概率都变得很低,接近 0。
这种情况与两个或多个分类标签对特定输入有效的情况不太吻合:T = 1 的 softmax 层很可能排除除一个标签之外的所有有效标签,并使概率分布接近 one-hot 编码分布。这导致学生模型可以学习的潜在有用信息的丢失,从而使其多样性降低。
这就是为什么该论文的作者引入了蒸馏损失,其中softmax概率是在温度T > 1的情况下计算的,从而可以平滑地对齐概率,从而考虑学生的几个可能的答案。
在蒸馏损失中,对学生和教师施加相同的温度T。删除了教师分布的独热编码。
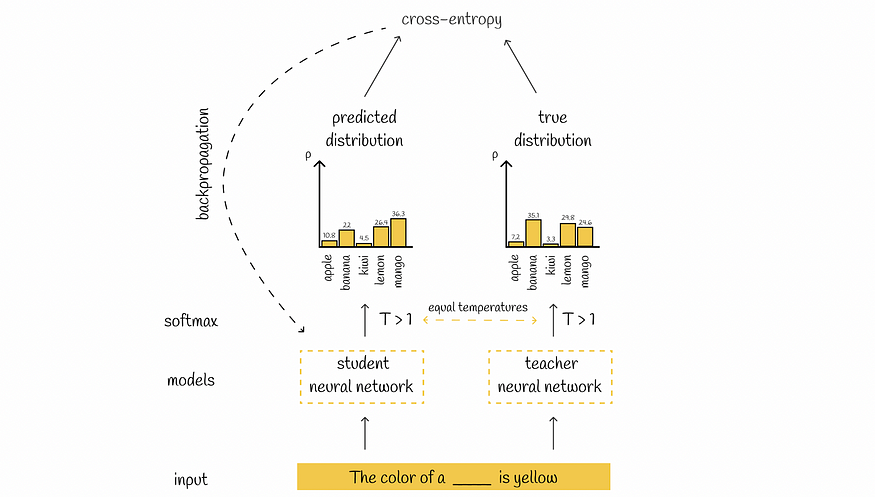
蒸馏损失计算示例
可以使用KL散度损失代替交叉熵损失。
5.3 相似性损失
研究人员还指出,在隐藏状态嵌入之间增加余弦相似性损失是有益的。
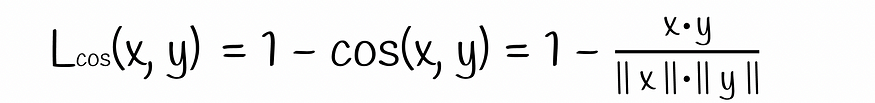
余弦损耗公式
这样,学生不仅可以正确复制屏蔽令牌,还可以构建与教师类似的嵌入。它还为在模型的两个空间中保留嵌入之间的相同关系打开了大门。
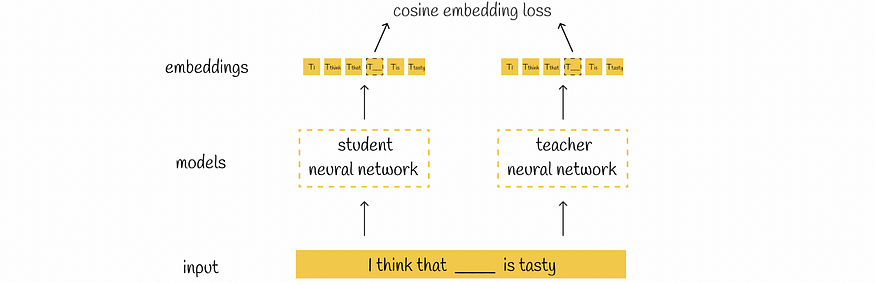
相似性损失计算示例
5.4 三重损失
最后,计算所有三个损失函数的线性组合之和,该和定义了DistilBERT中的损失函数。根据损失值,对学生模型执行反向传播以更新其权重。

迪斯蒂尔伯特损失函数
有趣的是,在三个损失分量中,掩蔽语言建模损失对模型性能的影响最小。蒸馏损失和相似性损失的影响要大得多。
六、推理
DistilBERT中的推理过程与训练阶段完全相同。唯一微妙的是软最大温度T设置为1。这样做是为了获得接近BERT计算的概率。
6.1 建筑
通常,DistilBERT使用与BERT相同的体系结构,除了以下更改:
- DistilBERT只有一半的BERT层。模型中的每一层都是通过从两个层中取出一个BERT层来初始化的。
- 删除令牌类型嵌入。
- 应用于分类任务的 [CLS] 令牌隐藏状态的密集层将被删除。
- 为了获得更强大的性能,作者使用了RoBERTa中提出的最佳想法:
- 动态掩码的使用 - 删除下一个句子预测目标
- 大批量训练
- 梯度累积技术应用于优化梯度计算
DistilBERT中的最后一个隐藏层大小(768)与BERT中的相同。作者报告说,它的减少并没有导致计算效率方面的显着提高。根据他们的说法,减少总层数的影响要大得多。
6.2 数据
DistilBERT在与BERT相同的数据语料库上进行训练,其中包含BooksCorpus(800M字)英语维基百科(2500M字)。
七、伯特与迪斯蒂尔伯特比较
比较了BERT和DistilBERT的关键性能参数,并比较了几个最受欢迎的基准。以下是需要保留的重要事实:
- 在推理过程中,DistilBERT比BERT快60%。
- DistilBERT的参数减少了44M,总共比BERT小40%。
- DistilBERT保留了97%的BERT性能。
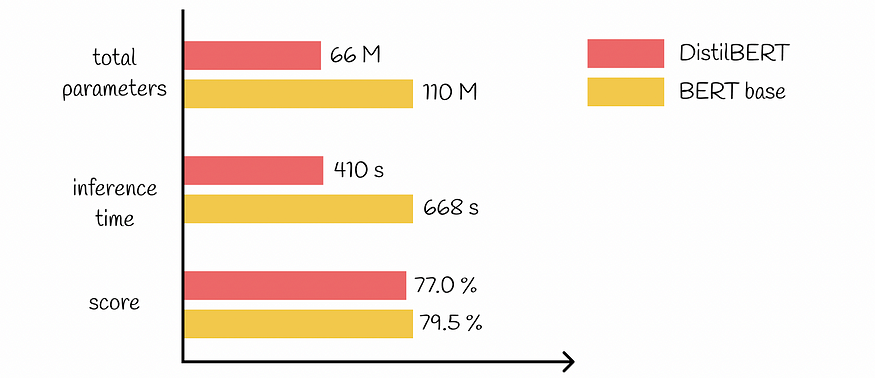
BERT 与 DistilBERT 比较(在 GLUE 数据集上)
八、结论
DistilBERT在BERT的发展中迈出了一大步,允许它显着压缩模型,同时在各种NLP任务上实现可比的性能。除此之外,DistilBERT仅重207 MB,使在容量有限的设备上的集成变得更加容易。知识蒸馏并不是唯一适用的技术:DistilBERT可以通过量化或修剪算法进一步压缩。
资源
- DistilBERT,BERT的蒸馏版本:更小,更快,更便宜,更轻
除非另有说明,否则所有图片均由 c提供 维亚切斯拉夫·叶菲莫夫