Floorplanning with Graph Attention
DAC ’22
目录
- Floorplanning with Graph Attention
- 摘要
- 1.简介
- 2.相关工作
- 3.问题公式化
- 4. FLORA的方法
- 4.1 解决方案概述
- 4.2 C-谱聚类算法
- 4.3 基于GAT的模型
- 4.4 合成训练数据集生成
摘要
布图规划一直是一个关键的物理设计任务,具有很高的计算复杂度。它的主要目标是确定初始位置的宏和标准单元与优化的线长为给定的面积约束。本文介绍了Flora,一个基于图形注意力的布图规划器,学习电路连接性和物理线长之间的优化映射,并使用高效的模型推理产生芯片布图规划。植物群已与两个最先进的混合放置工具整合。使用学术基准和工业设计的实验研究表明,与最先进的混合尺寸放置器相比,Flora将放置运行时间提高了18%,平均线长减少了2%。
1.简介
在超大规模集成电路芯片的物理实现中,芯片布图规划一直是一项关键且具有挑战性的任务。它影响到关键的下游优化目标,其中布局线长是最重要的一个。与仅放置宏的传统布图规划不同,现代版本输入混合宏块和标准单元的网表,并放置它们,以便针对给定区域约束优化物理线长,这与时序和可布线性密切相关[10]。即使在经典公式[14]中也被证明是NP难的,芯片布图规划难以使用算法方法有效地解决。缺乏有效的自动化工具,大多数专家设计师他们采取手动方式完成这项工作,通常需要数月的紧张工作[13]。为了提高生产力,Google开发了一种基于深度强化学习的平面规划器[13]。采用成功的AlphaGo系统中使用的方法,它将布局规划视为一系列移动,每个移动都在芯片上放置一个宏。当所有的宏被放置时,下游的物理实现阶段使用商业工具进行,并且计算最终的奖励。与AlphaGo类似,这个最终奖励被反向传播到序列中的每个情况和动作,并基于这些奖励训练评估网络和策略网络。在TPU设计上,它报告了比人类专家更好的结果,由系统在6小时内生成。
我们的工作受到了Google工作的极大启发,我们同意深度学习是解决芯片布局问题的一种有前途的方法。另一方面,我们在芯片布局规划上使用强化学习是相当保守的,因为将任务分解为一系列移动,每个移动只放置一个块,使工作复杂化。与围棋游戏完全不同的是,在围棋游戏中,玩家只能在对方未知的下一步棋之前走一步棋,芯片设计师预先拥有电路网表的完整连接信息,并且很少需要在顺序过程中一次一个块地进行布图规划。在现实中,考虑到电路的整体视图,专家设计师通常将电路划分为越来越精细的子电路,并且每次同时将一个级别的所有子电路放置在芯片上,优化它们之间的数据流。本质上,它是一次建立粗略的布图规划的过程,其中从子电路连接到物理位置的映射是优化的。
在这项工作中,我们追求一个图形注意力网络(GAT)为基础的方法芯片布局。根据“在人类直觉发挥作用的地方,神经网络可能获胜”的一般经验法则,我们方法的主要思想是利用GAT [16]来获得对子电路连接性的整体理解,并学习子电路连接性和物理线长之间的优化映射,然后通过有效的模型推理解码电路块的物理位置。所得到的布局,然后用于驱动下游的混合大小的布局任务。本文旨在回答以下研究问题。
(1)如何在电路连接性和物理线长之间建立优化的映射?我们建议使用基于GAT的方法。所提出的模型包括共享的基于GAT的编码器,随后是两个任务特定的自动编码器,以学习电路连接性和物理线长之间的优化映射,并生成宏和标准单元的物理位置,即,芯片布局,然后驱动下游布局任务。
(2)如何在不需要大的真实世界数据集的情况下训练基于GAT的布图规划器?现实世界的最佳布图规划是具有挑战性的。**我们提出了一种方法来生成一个合成的训练数据集来训练GAT模型。**在数据集中,电路连通性和物理线长之间的映射被保证是最优的。此外,它还提供了广泛的统计连接分布,以确保经过训练的模型在现实世界的设计中得到很好的推广。
拟议的平面规划器,称为Flora,已与两个最先进的混合大小的放置工具结合4,7],这将是公开发布的合成数据集沿着。使用ISPD 2005基准测试和实际行业设计的实验研究表明,与最先进的混合尺寸放置器相比,植物群始终将放置运行时间提高了18%,平均线长减少了2%。使用学术基准和工业设计也验证了所提出的基于GAT的方法的泛化能力。本文的其余部分组织如下。第2节总结了相关工作。第3节描述了问题公式化。第4节介绍了拟议的方法。第5节展示了实验结果。我们在第6节中结束本文。
2.相关工作
布局规划是NP难问题,其确定大型物理模块(例如,嵌入式存储器、知识产权(IP)核、标准单元簇),并且能够早期估计互连线长[1]。研究人员提出了各种表示方案[14]和优化算法[9]。布图规划的早期工作集中在宏包装上,并将放置标准单元的任务留给下游放置器,这可能限制物理设计的优化空间[8]。最近的工作解决了宏和标准单元格的放置问题,同时作为一个混合大小的放置任务[12]。
最先进的混合尺寸放置器包括ePlace [11],RePlAce [4]和DREAMPlace [7],其将混合尺寸放置问题表述为约束非线性优化问题。目标函数由凸线长函数和加权非凸密度函数组成。芯片布局是一个由无线感应力和密度感应力共同驱动的迭代优化过程。研究表明,这些方法产生高质量的解决方案,但需要很长的迭代时间。
最近,谷歌开发了一种基于深度强化学习的平面规划器[13]。它按顺序放置宏并迭代计算奖励,然后反向传播以训练策略网络。它报告了比人类专家更好和更快的TPU设计结果。然而,有了完整的电路预先提供网表信息,基于强化学习的顺序优化过程可能不必要地使工作复杂化。受电路专家如何创建和优化芯片布局的启发,我们采用基于GAT的方法来学习从电路连接到具有优化线长的块物理位置的映射。
3.问题公式化
平面布置图实例可以被建模为具有对象集合的超图
G
=
(
C
,
E
)
G=(C,E)
G=(C,E)(即,𝐶𝐺宏和聚集的标准单元)由超边连接。芯片布图规划的主要目标可以用公式表示为最小化总线长
W
(
c
)
W(c)
W(c),同时遵守密度约束
p
(
c
)
p(c)
p(c)。
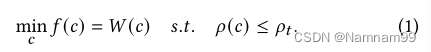
布图规划的总线长可以被估计为所有连接的对象之间的线长的总和,其在等式(2)中定义。
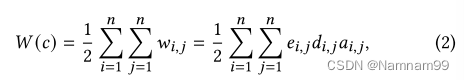
其中,
e
i
j
e_{ij}
eij和,
d
i
j
d_{ij}
dij分别表示对象
i
i
i和
j
j
j之间的连接数和距离,
A
i
j
A_{ij}
Aij是邻接矩阵,如果对象
i
i
i和
j
j
j连接,则
A
i
j
=
1
A_{ij}= 1
Aij=1否则为0。对于给定的电路网表,
e
e
e和
a
a
a是已知的。根据等式2,布图规划的目标是计算连接对象之间的最佳距离
d
d
d。因此,布图规划的本质是构建互连和物理距离之间的优化映射,然后引导下游任务优化并产生最终的芯片布局。
4. FLORA的方法
即所提出的基于GAT的布图规划器。它首先描述了整体算法流程,然后介绍了植物群的关键组件,包括聚类,基于GAT的模型和合成训练数据集生成。
4.1 解决方案概述
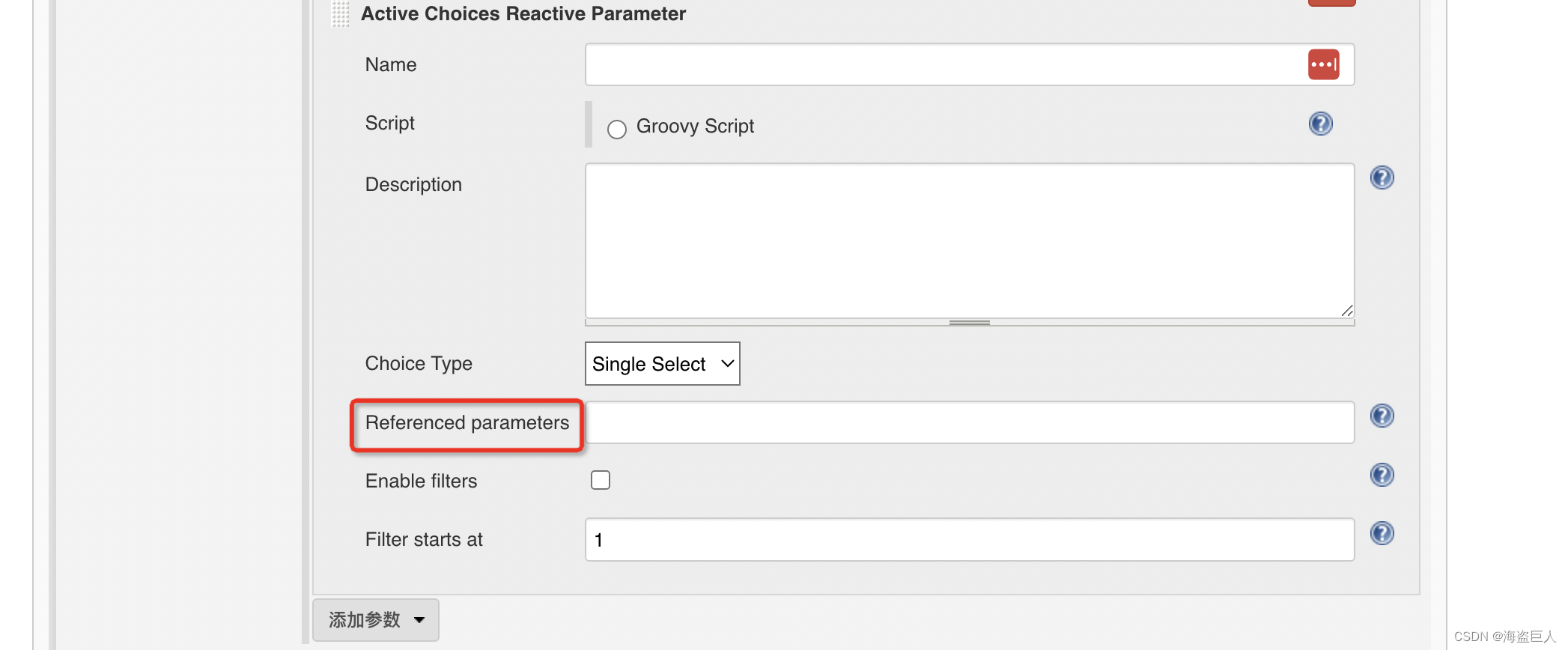
图1描述了FLORA的整体算法流程。给定一个电路网表表示为一个加权的无向超图,植物群分区的网表成子电路簇使用建议的C-谱聚类算法。划分的子电路超图,包括宏和标准单元的集群,被送入基于GAT的模型,以生成芯片布局,然后送入下游的放置器,以产生最终的芯片布局。GAT模型使用合成数据集进行训练,而不需要真实世界的芯片设计。该数据集涵盖了广泛的电路连接性分布,以确保所提出的基于GAT的布图规划器的泛化。
4.2 C-谱聚类算法
本节描述所提出的c-谱聚类算法。先前的工作表明,谱聚类可以有效地最小化簇间加权连接,但运行时间较长。大规模的图形[15]。提出的c-谱聚类算法的目的是利用谱聚类的好处,但避免其高计算成本,通过自底向上的超边缘粗化。

所提出的c-谱聚类算法在Alg.1.第1-2行描述了自底向上的超边缘粗化过程。由于具有高连通性权重的对象需要紧密地放置在芯片上,粗化过程基于超边缘权重执行自底向上聚类,从而减小图的规模并减轻谱聚类的计算成本。具体地,给定在无向超图中描述的电路网表,超边粗化过程首先基于边权重以非递增顺序对超边进行排序。𝐸𝐶𝐺按照排序顺序,由同一超边连接的对象将合并到一个簇中。该过程继续,直到达到集群总数方面的预定义界限。
粗化过程的输出,即,一个规模小得多的超图,然后被送入谱聚类(第3-4行)。我们采用基于谱的聚类方法[15]。我们首先计算图的拉普拉斯矩阵,并计算对应于的第二小特征值的特征向量。然后,我们对特征向量进行排序,并通过查找排序后的特征向量的最大 k − 1 k− 1 k−1间隙将对象划分为簇。我们还应用Lanczos算法[5]来提高特征值和特征向量的计算效率。最后,我们提取宏作为单个集群,以平衡每个集群内的细胞的总面积。
4.3 基于GAT的模型
本节介绍了所提出的用于布图规划生成的基于GAT的模型,该模型具有电路连接性和物理线长之间的优化映射。架构如图1所示,该模型包含三个关键组件,包括一个共享编码器和两个特定于任务的自动编码器,分别称为Dtask-model和Ltask-model。共享编码器对电路网表信息进行编码。用GAT [16]嵌入。Dtask模型旨在学习嵌入,以建立电路连接性和布局图中连接对象之间的物理线长之间的优化映射。Dtask-model的嵌入与Ltask-model的嵌入级联,然后馈送到Ltask-model解码器以生成对象物理位置或芯片布局。
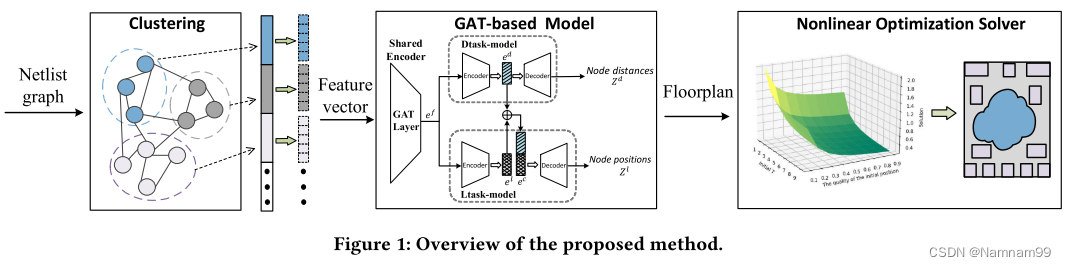
共享GAT编码器。到共享GAT编码器的输入是由c谱聚类生成的聚类级网表(参见图1)。第4.2节),表示为由对象集合
V
V
V和邻接矩阵
A
A
A定义的图
G
=
(
V
,
A
)
G=(V,A)
G=(V,A)。每个对象具有表示连接性分布的
N
N
N维特征向量。设
F
∈
R
N
∗
N
F∈R^{N*N}
F∈RN∗N是包含所有对象的特征向量作为行的特征矩阵。邻接矩阵
A
A
A中的元素表示是否有链接,有为1,没有为0。
共享的基于GAT的编码器通过聚合来自其本地邻居的消息来学习每个对象的新表示,称为第一级对象嵌入
e
f
∈
R
N
∗
M
e^f∈R^{N*M}
ef∈RN∗M,其中,M是每个对象中新特征的维度。然后将
e
f
e^f
ef传递给Dtask-model和Ltask-model,以完成以下具体任务。
Dtask-model.
它的目的是学习集群网表连接和物理线长之间的优化映射。该模型由一个GAT层和一个多层感知器(MLP)[6]组成,GAT层用于计算维距离嵌入
e
d
∈
R
N
∗
M
e^d ∈ R^{N*M}
ed∈RN∗M,MLP将解码为连接对象
e
d
e^d
ed的距离
D
∈
R
N
∗
N
D ∈ R^{N*N}
D∈RN∗N。由于GAT可以为邻居分配不同的注意力,因此它能够学习对象之间的相关性,并将具有更多相关性的邻居编码为更接近新特征空间中的对象,从而使模型能够学习所有连接对象的互连和距离之间的映射。
设
Z
d
∈
R
N
∗
N
Z^d ∈ R^{N*N}
Zd∈RN∗N是包含距离信息的D任务模型的输出矩阵,我们定义了模型计算
Z
d
Z^d
Zd如下:
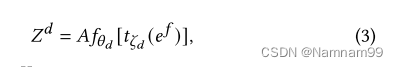
其中
t
ζ
d
:
R
M
→
R
H
t_{\zeta_{d}}:\mathbb{R}^{M}\rightarrow\mathbb{R}^{H}
tζd:RM→RH是一个GAT层,具有可学习的参数以计算距离嵌入
e
d
e^d
ed。同时
A
f
θ
d
:
R
H
→
R
N
Af_{\theta_{d}}:\mathbb{R}^{H}\rightarrow\mathbb{R}^{N}
Afθd:RH→RN是具有可学习的参数乘以邻接矩阵
A
A
A解码来得到连接对象之间距离的MLP。该模型通过最小化地面真实值和预测值之间的均方损失(MSELoss)进行训练,如下所示:
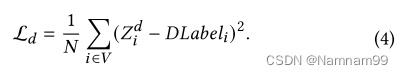
Ltask-model.
其旨在生成芯片布图规划,即,宏和标准单元簇的位置。Ltask-model的架构类似于Dtask-model的架构,GAT层后面跟着MLP,定义如下:
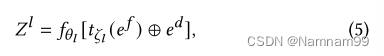
其中,
Z
l
Z^l
Zl表示由Ltask模型预测的对象位置,
t
ζ
l
:
R
M
→
R
T
t_{\zeta_{l}}:\mathbb{R}^{M}\rightarrow\mathbb{R}^{T}
tζl:RM→RT是具有可学习参数
ζ
l
\zeta_{l}
ζl的GAT层,用于计算位置嵌入
e
l
e^l
el,
⊕
\oplus
⊕表示级联运算符,并且
f
θ
l
:
R
T
+
H
→
R
2
f_{\theta_{l}}:\mathbb{R}^{T+H}\rightarrow\mathbb{R}^{2}
fθl:RT+H→R2是具有可学习参数
θ
\theta
θ的MLP,用于解码对象位置。特别是,为了建立对象的相对距离和绝对坐标之间的映射,我们将位置嵌入
e
d
e^d
ed和距离嵌入
e
c
e^c
ec作为位置嵌入,并将其馈送到下面的MLP层以生成对象分布。
该模型使用地面真实值和预测值
Z
l
Z^l
Zl之间的MSELoss进行训练,如下所示:
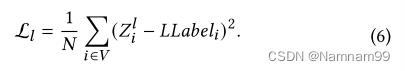
通过组合来自Dtask模型和Ltask模型的损失函数,基于GAT的模型的最终损失函数定义如下:

4.4 合成训练数据集生成
现实世界的最佳平面布置很难获得。即使假设它们的最佳布局是已知的,有限数量的公共基准也远远不足以支持深度模型的训练。我们提出了一种方法来创建一个合成训练数据集来解决这个问题[3]。
合成训练数据集的创建需要保证每个创建的网表-布图规划对应包含电路连接性和物理线长之间的最佳映射。如第3节中所述,布图规划器的主要优化目标是最小化总线长,其可以被计算为等式2。我们可以从给定的集群网表中提取的关键特征是和,它们可以转换为连通性的统计分布,更具体地说,两个邻居之间的连接数分布和每个对象的邻居数分布。为了构建训练数据集,我们首先创建一个空的芯片区域,并将所有对象放置在该区域上。然后,我们计算了和在各种簇电路中的概率分布,可以分别表示为
P
(
e
)
P(e)
P(e)和
P
(
b
)
P(b)
P(b)。接下来,我们生成邻居的数量
B
=
(
b
1
,
.
b
i
,
.
.
,
b
n
)
P
(
b
)
B=(b_1,.b_i,..,b_n)~P(b)
B=(b1,.bi,..,bn) P(b),并且连接数
E
=
(
e
1
,
…
,
e
i
,
…
,
e
n
)
,
∀
e
i
∼
P
(
e
)
E=(e_{1},\ldots,e_{i},\ldots,e_{n}),\forall e_{i}\sim P(e)
E=(e1,…,ei,…,en),∀ei∼P(e),其中
b
i
b_i
bi表示对象的邻居数量,表示对象
i
i
i与其邻居
e
i
e_i
ei之间的连接分布。我们将
e
i
∈
E
e_i∈E
ei∈E按降序排序,并将更多的连接分配给距离更近的邻居。对象之间的连接的最终数量被设置为对象对的平均连接。然后,每个对象的坐标
O
(
x
,
y
)
O(x,y)
O(x,y)可以被视为位置标签,每个连接的对象对之间的物理距离是距离标签。数据集的构造在Alg.2中描述。

因此,我们可以获得具有最佳布图规划解决方案的合成训练数据集(参见图1证明),同时确保统计连接分布的广泛覆盖,从而使训练模型在各种基准上得到很好的推广。定理4.1.在Alg.2是最佳的。
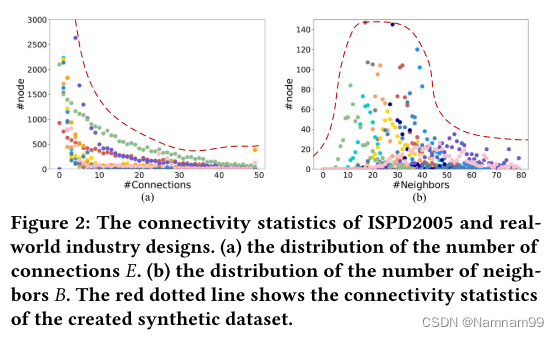
此外,合成数据集应在电路连接性方面提供广泛的覆盖范围,以确保训练模型的泛化。如图2所示,两个关键特征和的分布在不同的基准测试中(用不同的颜色表示)有很大的不同。在这项工作中,合成数据集的连通性统计数据充分覆盖了学术基准,例如,ISPD2005和实际行业设计,可以进一步扩展以适应具有不同连接统计数据的新设计。