入门案例
学习目标
- 创建一个Scrapy项目
- 定义提取的结构化数据(Item)
- 编写爬取网站的 Spider 并提取出结构化数据(Item)
- 编写 Item Pipelines 来存储提取到的Item(即结构化数据)
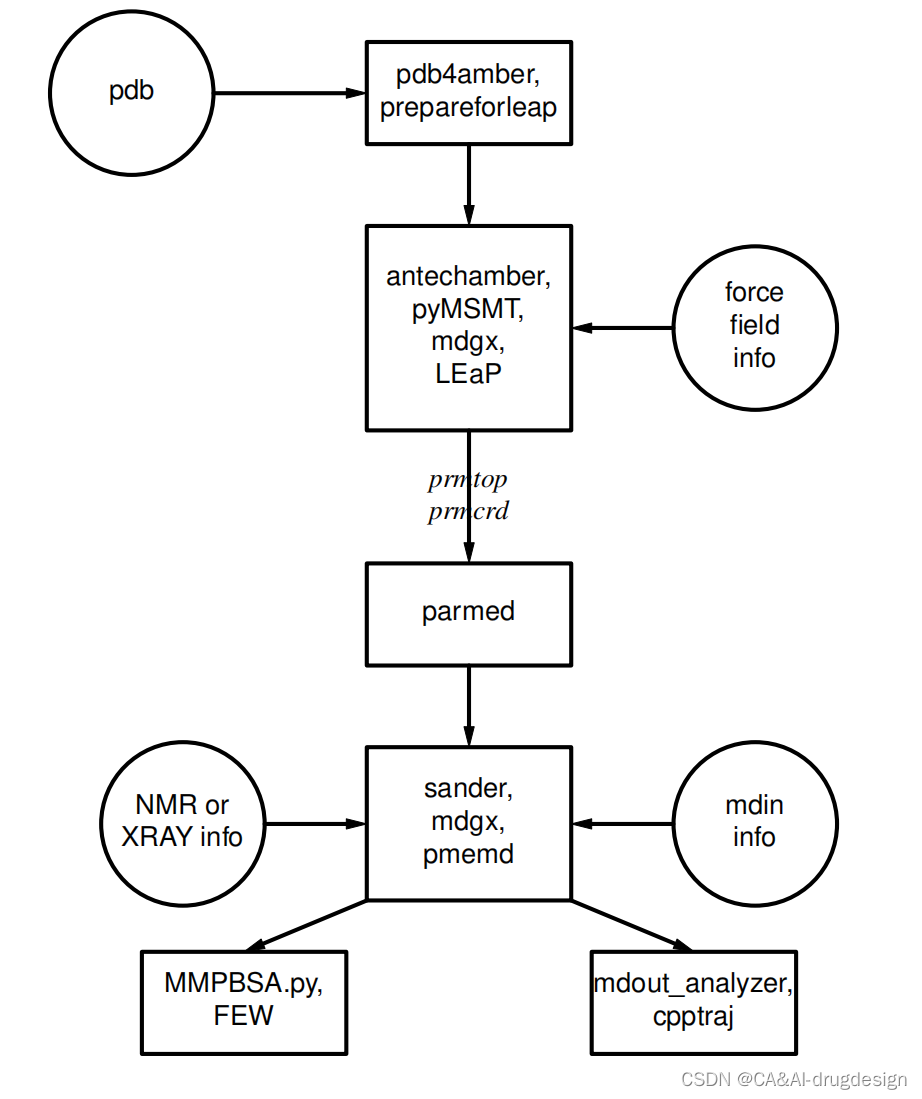
一. 新建项目(scrapy startproject)
- 在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
scrapy startproject mySpider
- 其中, mySpider 为项目名称,可以看到将会创建一个 mySpider 文件夹,目录结构大致如下:
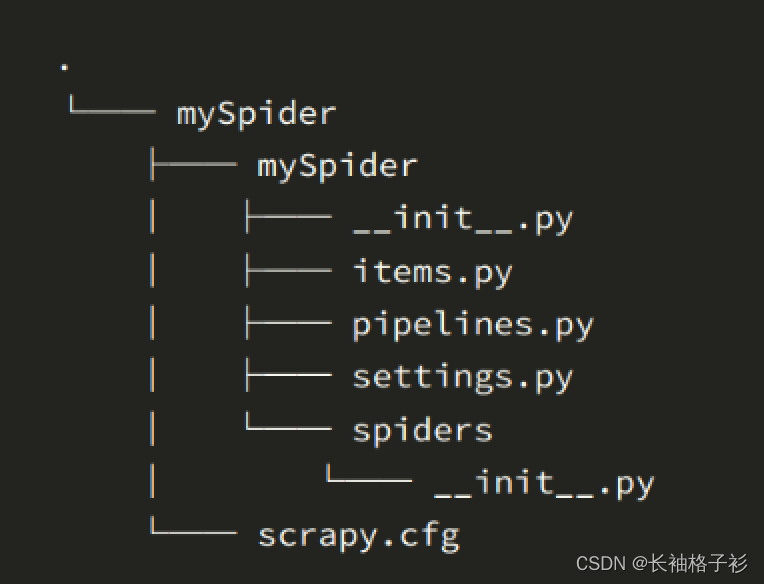
下面来简单介绍一下各个主要文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目的Python模块,将会从这里引用代码
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ :存储爬虫代码目录
二、明确目标(mySpider/items.py)
我们打算抓取:传智教育课程培训教研团队 网站里的所有讲师的姓名、职称和个人信息。
-
打开mySpider目录下的items.py
-
Item 定义结构化数据字段,用来保存爬取到的数据,有点像Python中的dict,但是提供了一些额外的保护减少错误。
-
可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field的类属性来定义一个Item。
-
接下来,创建一个Itc