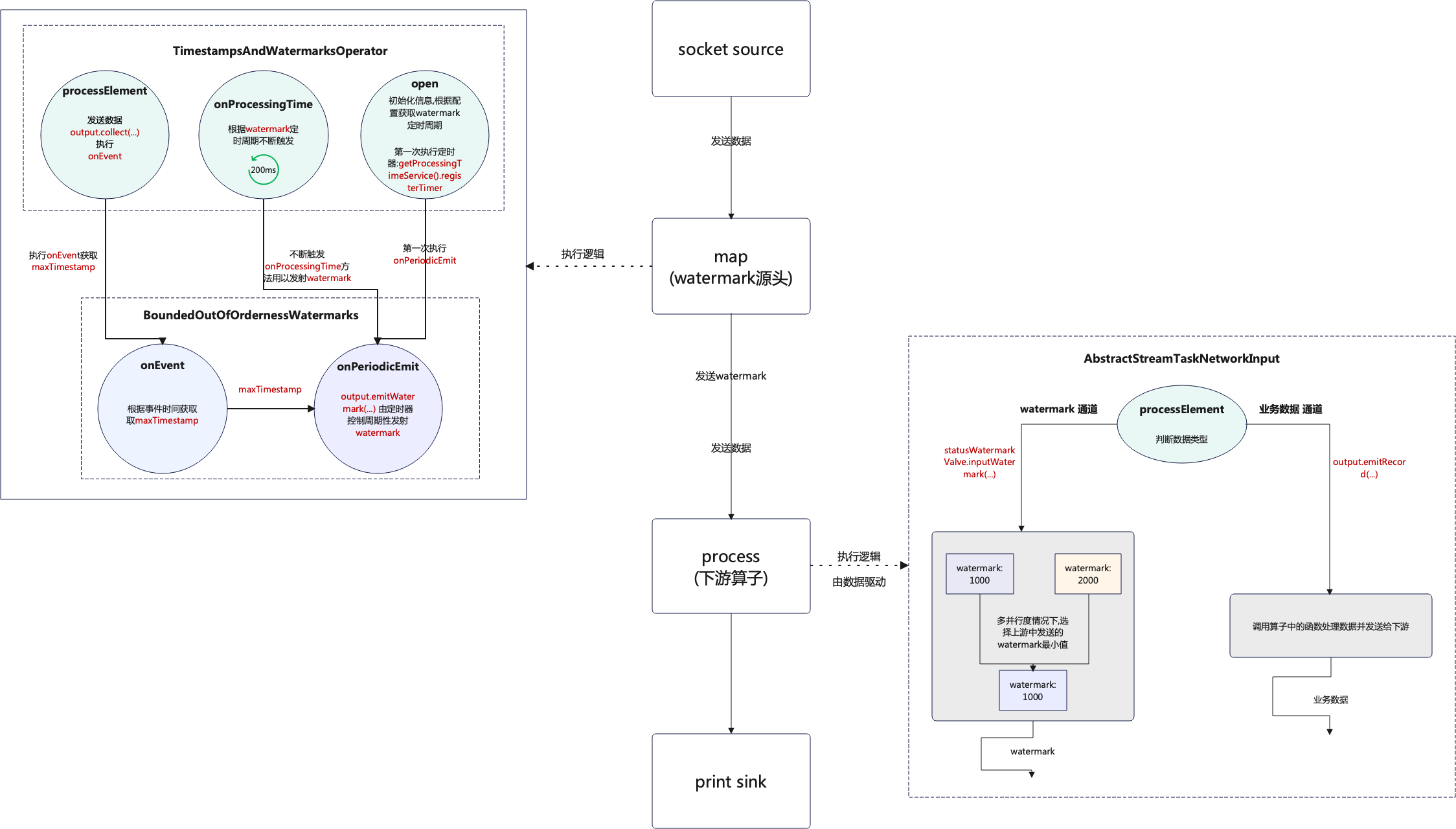
跑腿配送App正经历着快速的技术演进,为提供更智能、高效和个性化的服务而不断创新。本文将探讨其中一个可能的创新方向:使用机器学习和实时数据分析来改进配送路线,提高效率,并为用户提供更好的体验。

技术背景
要实现这个创新方向,我们需要使用Python编程语言和一些主要的机器学习和数据分析库,例如NumPy、pandas、scikit-learn和地理信息系统(GIS)工具。此外,我们还需要获取实时的地理数据,以便在配送过程中动态地调整路线。
代码示例
以下是一个简化的示例代码,演示如何使用Python和机器学习来优化配送路线:
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
import geopy.distance
# 模拟实时订单数据
orders = pd.DataFrame({'latitude': [37.7749, 37.7749, 37.7749, 34.0522, 34.0522],
'longitude': [-122.4194, -122.4194, -122.4194, -118.2437, -118.2437]})
# 使用K均值聚类将订单分成若干簇
kmeans = KMeans(n_clusters=2)
orders['cluster'] = kmeans.fit_predict(orders[['latitude', 'longitude']])
# 计算每个簇的中心点
cluster_centers = pd.DataFrame(kmeans.cluster_centers_, columns=['latitude', 'longitude'])
# 计算距离矩阵
distance_matrix = np.zeros((len(orders), len(cluster_centers)))
for i, order in orders.iterrows():
for j, center in cluster_centers.iterrows():
coords_1 = (order['latitude'], order['longitude'])
coords_2 = (center['latitude'], center['longitude'])
distance = geopy.distance.distance(coords_1, coords_2).km
distance_matrix[i, j] = distance
# 为每个订单分配最近的簇
orders['nearest_cluster'] = np.argmin(distance_matrix, axis=1)
# 输出最终的路线
for cluster_id, group in orders.groupby('nearest_cluster'):
print(f"Cluster {cluster_id} Route: {list(group.index)}")
这个示例代码演示了如何使用K均值聚类来将订单分成若干簇,并计算每个簇的中心点。然后,它计算每个订单到各个簇中心点的距离,并将订单分配给最近的簇,以便为配送员提供最佳路线。这只是一个简化的例子,未来的跑腿配送App可能会使用更复杂的算法和数据来进行优化。
结论
跑腿配送App的未来充满了技术和创新的机会。使用机器学习和实时数据分析来改进配送路线只是其中之一。随着技术的不断发展,我们可以期待跑腿配送App提供更加智能、高效和个性化的服务,从而满足用户日益增长的需求。这个领域的创新将继续推动未来的发展,创造更多的商机和价值。