异常现象1
按照以下方式设置backend目录和checkpoint目录,fsbackend目录有数据,checkpoint目录没数据
env.getCheckpointConfig().setCheckpointStorage(PropUtils.getValueStr(Constant.ENV_FLINK_CHECKPOINT_PATH));
env.setStateBackend(new FsStateBackend(PropUtils.getValueStr(Constant.ENV_FLINK_STATEBACKEND_PATH)));
原因
我以为checkpoint和fsbackend要同时设置,其实,1.14.3版本,setCheckpointStorage和stateBackend改成了分着设置
我上边代码这样设置,相当于首先指定了以下checkpoint按照默认的backend存储,然后又指定了按照fsbackend存储,因此首先指定的checkpoint目录没有数据。
正解
env.setStateBackend(new HashMapStateBackend());
env.getCheckpointConfig().setCheckpointStorage(PropUtils.getValueStr(Constant.ENV_FLINK_CHECKPOINT_PATH));State Backends | Apache Flink

异常现象2
开启checkpoint eos,开启容错,每次任务重新提交都会重新消费kafka已经完成了checkpoint的数据
原因
我以为只要开启这两个配置就可以保证已经checkpoint的kafka数据不会被重复消费,其实不然
checkpoint是flink内部的容错机制,他能保证在设置了失败重启策略之后(setRestartStrategy),如果发生异常导致失败重试之后自动从最新checkpoint恢复。不是手动重启。。。手动重启默认不会进行加载状态数据,所以每次都会从头消费

正解
flink任务 -s 指定恢复点提交,这个恢复点可以是checkpoint也可以时savepoint。
# 启动
/home/cuadmin/flink-1.14.3/bin/flink run -d \
-c cn.flink.ApplicationMaster \
/home/cuadmin/portal-flink-2021.0.1-SNAPSHOT-shaded.jar
# 备份,创建savepoint
/home/cuadmin/flink-1.14.3/bin/flink savepoint 19f4bb5d103ea8695712d4d1a797893f /home/cuadmin/flink-1.14.3/savepoint
# 指定savepoint启动
/home/cuadmin/flink-1.14.3/bin/flink run -d \
-c cn.flink.ApplicationMaster \
-s file:/home/cuadmin/flink-1.14.3/savepoint/savepoint-033556-251a9e55ed25 \
/home/cuadmin/portal-flink-2021.0.1-SNAPSHOT-shaded.jar
异常现象4
这是错误的
# 指定savepoint启动
/home/cuadmin/flink-1.14.3/bin/flink run -d \
-c cn.flink.ApplicationMaster \/home/cuadmin/portal-flink-2021.0.1-SNAPSHOT-shaded.jar
-s file:/home/cuadmin/flink-1.14.3/savepoint/savepoint-033556-251a9e55ed25 \
按照上述命令执行,这个地方显示恢复点的加载情况,这里没显示,代表恢复点没有执行成功
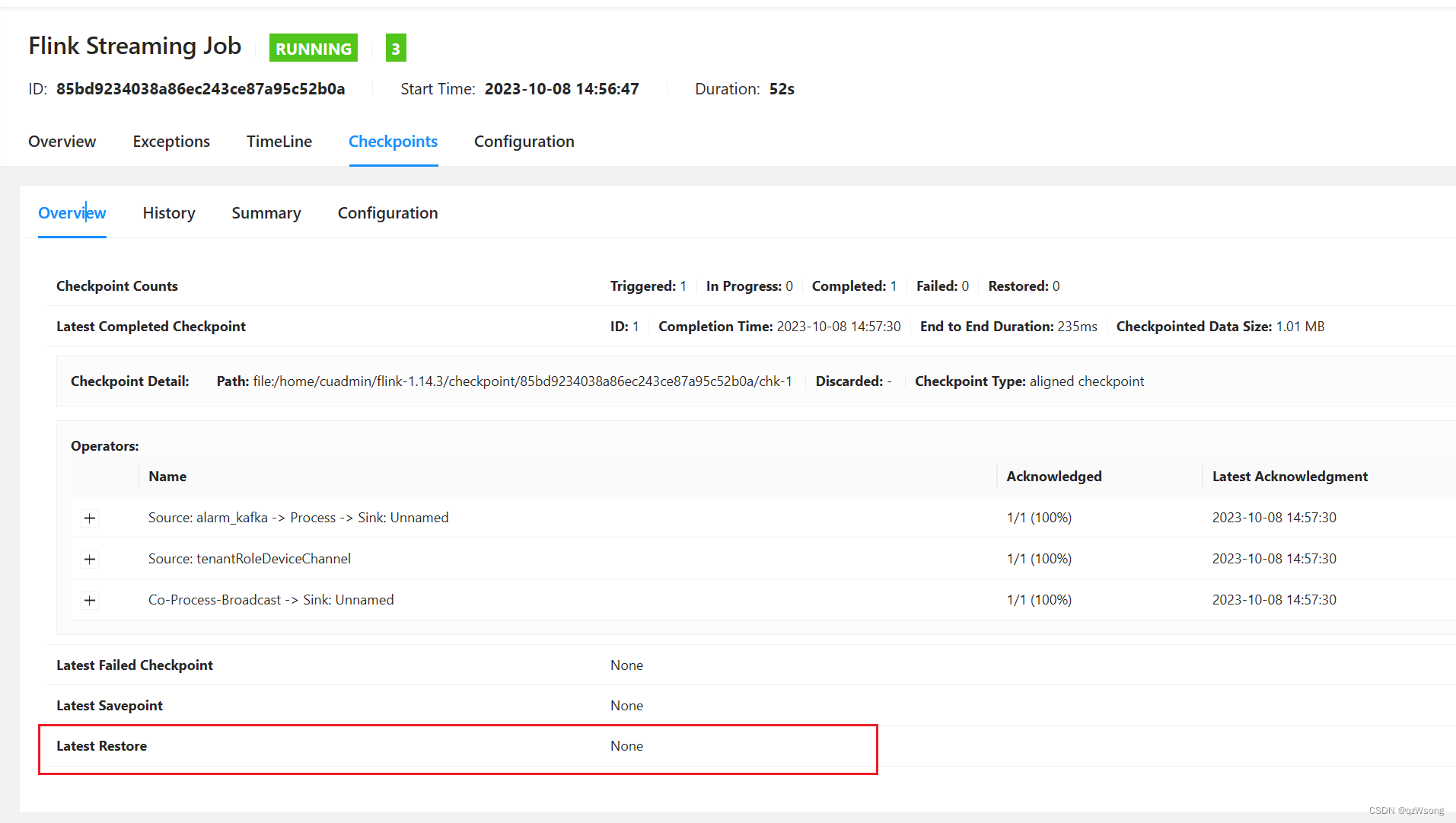
原因
-s的位置有问题,我之前以为没有顺序,把-s 放到了命令最后,结果没报错,也没识别。。
正解
-s 位置要正确
# 指定savepoint启动
/home/cuadmin/flink-1.14.3/bin/flink run -d \
-c cn.flink.ApplicationMaster \
-s file:/home/cuadmin/flink-1.14.3/savepoint/savepoint-033556-251a9e55ed25 \
/home/cuadmin/portal-flink-2021.0.1-SNAPSHOT-shaded.jar
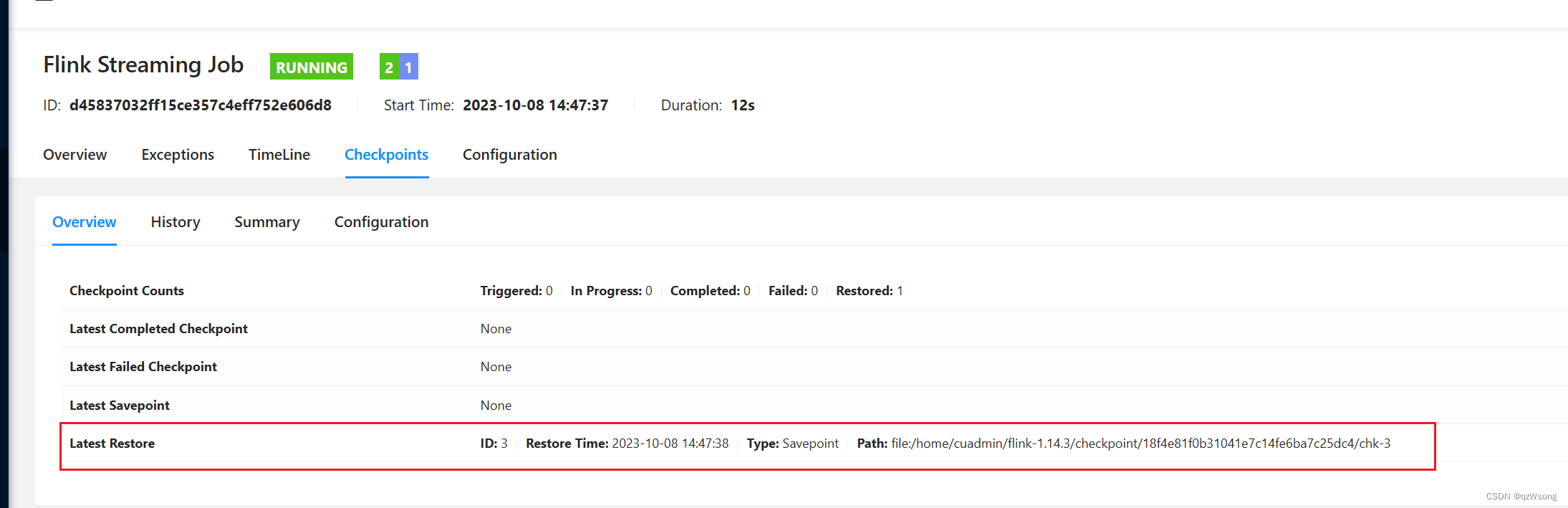
异常现象3
我记得savepoint和checkpoint是都可以用来flink -s 进行恢复点恢复的。但是每次都提示恢复失败,提示文件找不到,savepoint就可以。。。
原因
cancel job会将 checkpoint的数据删掉。。。
正解
测试的时候,直接stop-cluster,这样checkpoint数据就不会被删除了
保留 Checkpoint
Checkpoint 在默认的情况下仅用于恢复失败的作业,并不保留,当程序取消时 checkpoint 就会被删除。当然,你可以通过配置来保留 checkpoint,这些被保留的 checkpoint 在作业失败或取消时不会被清除。这样,你就可以使用该 checkpoint 来恢复失败的作业。
CheckpointConfig config = env.getCheckpointConfig();
config.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
ExternalizedCheckpointCleanup 配置项定义了当作业取消时,对作业 checkpoint 的操作:
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:当作业取消时,保留作业的 checkpoint。注意,这种情况下,需要手动清除该作业保留的 checkpoint。ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:当作业取消时,删除作业的 checkpoint。仅当作业失败时,作业的 checkpoint 才会被保留。
总结
1、savepoint的数据要比checkpoint更加稳定,比如你可以通过移动(拷贝)savepoint 目录到任意地方,然后再进行恢复。checkpoint就不可以,因为他有很多相对路径配置。
2、savepoint和checkpoint一般都能作为恢复点使用,例外情况是使用 RocksDB 状态后端的增量 Checkpoint。他们使用了一些 RocksDB 内部格式,而不是 Flink 的本机 Savepoint 格式。这使他们成为了与 Savepoint 相比,更轻量级的 Checkpoint 机制的第一个实例。
3、任务因为偶然原因内部重启(task级别),通过失败重试机制+checkpoint自动进行重放,任务因重启、断电、死机等外部因素(cluster级别),通过-s 指定checkpoint/savepoint恢复点进行手动重放。这样就可以保证状态数据的稳定