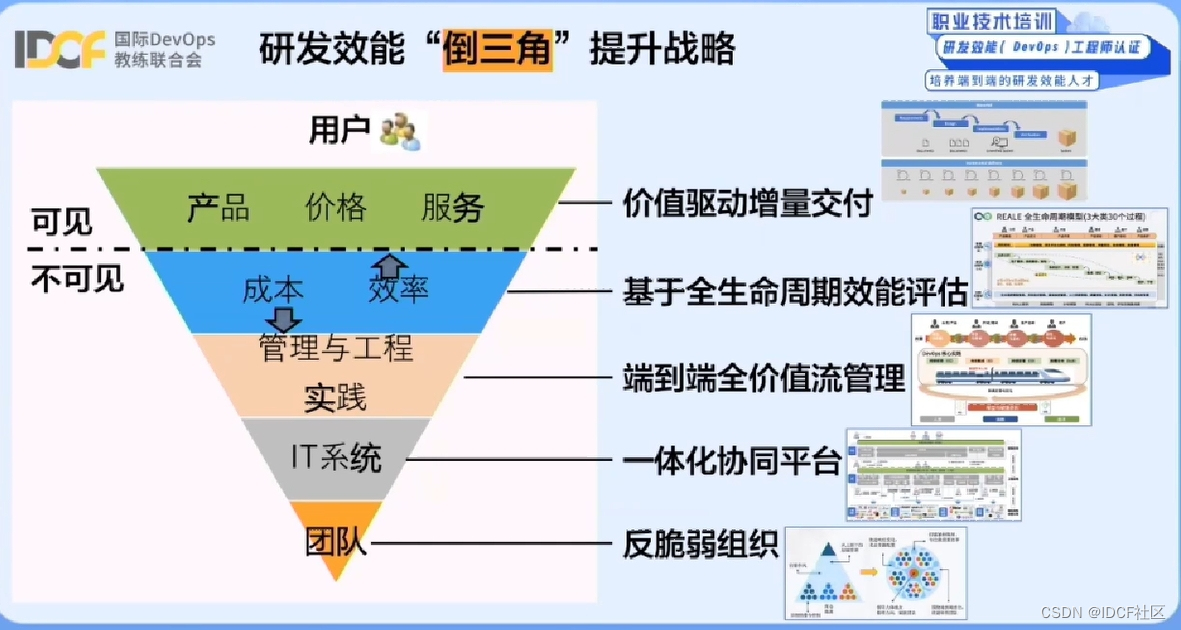
JUC系列整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】深入理解JMM内存模型的底层实现原理 | https://zhenghuisheng.blog.csdn.net/article/details/132400429 |
| 【二】深入理解CAS底层原理和基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/132478786 |
| 【三】熟练掌握Atomic原子系列基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/132543379 |
| 【四】精通Synchronized底层的实现原理 | https://blog.csdn.net/zhenghuishengq/article/details/132740980 |
| 【五】通过源码分析AQS和ReentrantLock的底层原理 | https://blog.csdn.net/zhenghuishengq/article/details/132857564 |
| 【六】深入理解Semaphore底层原理和基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/132908068 |
| 【七】深入理解CountDownLatch底层原理和基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/133343440 |
| 【八】深入理解CyclicBarrier底层原理和基本使用 | https://blog.csdn.net/zhenghuishengq/article/details/133378623 |
| 【九】深入理解ReentrantReadWriteLock 读写锁的底层实现 | https://blog.csdn.net/zhenghuishengq/article/details/133629550 |
| 【十】深入理解ArrayBlockingQueue的底层实现 | https://blog.csdn.net/zhenghuishengq/article/details/133692023 |
深入理解ArrayBlockingQueue的底层实现
- 一,深入理解ArrayBlockingQueue的底层实现
- 1,阻塞队列的api基本使用
- 2,ArrayBlockingQueue的基本使用
- 3,ArrayBlockingQueue的底层源码
- 3.1,ArrayBlockingQueue的基本属性
- 3.2,put入队操作
- 3.3,出队操作
- 4,总结
一,深入理解ArrayBlockingQueue的底层实现
在理解阻塞队列BlockingQueue之前,先理解Queue的特性,Queue是作为一种经典的数据结构使用的,与之相对应的的就是栈。队列采用的是先进先出的策略模式,在Java中也有Queue的具体实现,内部也有着一些对应的api,如add,remove入队出队等
public interface Queue<E> extends Collection<E> {...}
在Queue这个接口内有一个子类,就是本文要讲解的主角 BlockingQueue ,在原来的Queue基础上,新增了两个附加操作put和take ,这两个操作可支持阻塞,而在阻塞队列中有多个阻塞队列的具体实现,因此本文主要是讲解 ArrayBlockingQueue 的具体使用
public interface BlockingQueue<E> extends Queue<E> {
void put(E e) throws InterruptedException;
E take() throws InterruptedException;
}
1,阻塞队列的api基本使用
在阻塞队列中,有以下的api可以使用,如一些入队,出队等操作,但是同一个操作会有多个方法
支持将数据加入到队列,但是不支持阻塞的方法有下面两种
boolean add(E e); //数据入队,队列已满则抛出异常
boolean offer(E e); //数据入队,队列已满则返回false
支持将数据加入到队列,但是支持阻塞的方法有下面两种,表示的是队列未满则插入,队列已满则阻塞
//数据入队,线程阻塞
void put(E e) throws InterruptedException;
//数据入队,线程阻塞一段时间
boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException;
支持数据出队,但是不支持阻塞的方法有以下
boolean remove(Object o); //数据出队,队列为空则抛异常
支持数据出队,同时支持数据阻塞的方法有以下,表示的是队列有数据则删除,队列没有数据则阻塞
//数据出队,允许中断,线程阻塞一段时间
E poll(long timeout, TimeUnit unit) throws InterruptedException;
//数据出队,线程阻塞
E take() throws InterruptedException;
2,ArrayBlockingQueue的基本使用
上面的这些方法是阻塞队列的通用方法,因此下面主要针对这个 ArrayBlockingQueue 来讲解内部的使用。举一个简单的生产者和消费者模型,来描述这个ArrayBlockingQueue的使用
首先定义一个产品类,内部的属性变量比较简单
/**
* @Author: zhenghuisheng
* @Date: 2023/10/8 20:24
*/
@Data
public class Product {
private Integer id;
private String productName;
}
随后定义一个生产者Producer的线程任务类,内部用于生产产品,并将生产的产品加入到阻塞队列中
/**
* 生产者线程
* @Author: zhenghuisheng
* @Date: 2023/10/8 20:21
*/
@Data
public class Producer implements Runnable {
private ArrayBlockingQueue arrayBlockingQueue;
public Producer(ArrayBlockingQueue arrayBlockingQueue){
this.arrayBlockingQueue = arrayBlockingQueue;
}
@Override
public void run() {
for (int i = 0; i < 5; i++) {
Product product = new Product();
product.setId(i);
product.setProductName("商品" + i + "号");
try {
//加入阻塞队列
arrayBlockingQueue.put(product);
System.out.println("生产者" + i + "号生产完毕");
Thread.sleep(50);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
随后创建一个消费者Consumer线程的任务类,主要用于消费者消费线程
/**
* 消费者线程
* @Author: zhenghuisheng
* @Date: 2023/10/8 20:21
*/
@Data
public class Consumer implements Runnable {
private ArrayBlockingQueue arrayBlockingQueue;
public Consumer(ArrayBlockingQueue arrayBlockingQueue){
this.arrayBlockingQueue = arrayBlockingQueue;
}
@Override
public void run() {
for (int i = 0; i < 5; i++) {
try {
//消费者消费
Object take = arrayBlockingQueue.take();
System.out.println(take);
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println("消费者消费完毕");
}
}
随后创建一个线程池的根据类,用于定义线程池的各个参数以及初始化线程池
/**
* 线程池工具
* @author zhenghuisheng
* @date : 2023/3/22
*/
public class ThreadPoolUtil {
/**
* io密集型:最大核心线程数为2N,可以给cpu更好的轮换,
* 核心线程数不超过2N即可,可以适当留点空间
* cpu密集型:最大核心线程数为N或者N+1,N可以充分利用cpu资源,N加1是为了防止缺页造成cpu空闲,
* 核心线程数不超过N+1即可
* 使用线程池的时机:1,单个任务处理时间比较短 2,需要处理的任务数量很大
*/
public static synchronized ThreadPoolExecutor getThreadPool() {
if (pool == null) {
//获取当前机器的cpu
int cpuNum = Runtime.getRuntime().availableProcessors();
log.info("当前机器的cpu的个数为:" + cpuNum);
int maximumPoolSize = cpuNum * 2 ;
pool = new ThreadPoolExecutor(
maximumPoolSize - 2,
maximumPoolSize,
5L, //5s
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(), //数组有界队列
Executors.defaultThreadFactory(), //默认的线程工厂
new ThreadPoolExecutor.AbortPolicy()); //直接抛异常,默认异常
}
return pool;
}
}
最后在创建一个测试类作为主类的入口,随后就可以看到生产者消费者各个的消费信息了
/**
* @Author: zhenghuisheng
* @Date: 2023/10/8 20:27
*/
public class ArrayBlockingQueueDemo {
//创建一个线程池
static ThreadPoolExecutor pool = ThreadPoolUtil.getThreadPool();
//创建一个全局阻塞队列
private static ArrayBlockingQueue queue = new ArrayBlockingQueue(16);
public static void main(String[] args) throws InterruptedException {
//创建生产者线程
Producer producer = new Producer(queue);
//创建消费者线程
Consumer consumer = new Consumer(queue);
//线程加入线程池
pool.execute(producer);
pool.execute(consumer);
Thread.sleep(10000);
System.exit(0);
}
}
其打印结果如下,乱序是没多大问题的
Product(id=0, productName=商品0号)
生产者0号生产完毕
生产者1号生产完毕
Product(id=1, productName=商品1号)
Product(id=2, productName=商品2号)
生产者2号生产完毕
生产者3号生产完毕
Product(id=3, productName=商品3号)
Product(id=4, productName=商品4号)
生产者4号生产完毕
3,ArrayBlockingQueue的底层源码
3.1,ArrayBlockingQueue的基本属性
在讲解这个类的源码之前,先看一下这个类的继承以及这个类中重要的一些属性,该类是继承了一个抽象的队列,并且是BlockingQueue的一个具体的实现
public class ArrayBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>{}
在这个类中,有一个ReentrantLock锁,说明这个ArrayBlockingQueue的底层是通过这个互斥锁实现的,并且还引入了两个条件等待队列,很明显一个是队列满了put的时候阻塞,一个是队列空了take的阻塞。根据前面几篇的AQS的文章的讲解,很容易想到这两个条件队列的作用;用的ReentrantLock锁,也大概得可以知道take和put操作时互斥的,因此在性能上肯定是会出现问题的
//互斥锁
final ReentrantLock lock;
//为空时take的条件队列
private final Condition notEmpty;
//满时put的条件队列
private final Condition notFull;
除了上面这些属性之外,还有一些关于数组的定义,删除到哪个位置,添加到那个数组的索引位置,这些都是有记录的。由于数组是一块连续的空间,并且底层是通过队列的方式实现,因此根据先进先出原则,进来的数据都是在队尾,删除的都是队头的数据,整个操作都是对这个数组进行操作的
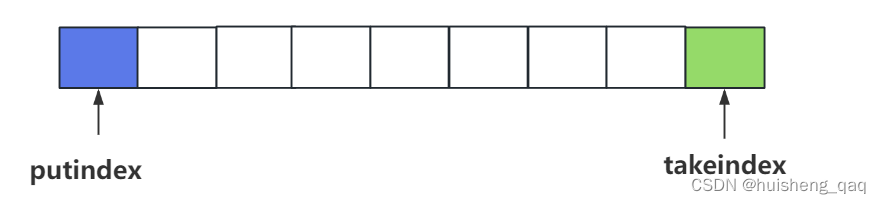
final Object[] items; //数组
int takeIndex; //前驱指针,用于记录删除到了哪个结点
int putIndex; //后继指针,用于记录添加到了哪个结点
int count; //数组数量
大概就是这么回事,takeindex记录的是出队到哪个位置的下标,putindex记录的入队到哪个位置的下标
最后再看看这个类的构造器方法,在初始化一个ArrayBlockingQueue时,就会将数组以及容量,还有两个条件队列全部构建完成,并且这把ReentrantLock互斥锁使用的是公平锁
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity]; //初始化一个数组
lock = new ReentrantLock(fair); //初始化一把互斥锁
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
3.2,put入队操作
在初步的了解完上面的这些属性之后,那么接下来主要讲解一下阻塞队列入队的操作,那么直接看这个put方法
//入队操作
public void put(E e) throws InterruptedException {
checkNotNull(e); //判断是否为空的操作
final ReentrantLock lock = this.lock; //获取全局的互斥锁
lock.lockInterruptibly(); //可中断锁
try {
while (count == items.length) //当队列满的时候
notFull.await(); //线程阻塞
enqueue(e); //如数组没满,则入队
} finally {
lock.unlock(); //解锁
}
}
入队的逻辑也比较简单,将值加入到数组中,并将putindex的值+1,数组中的结点数+1,最后调用signal唤醒数组为空时被阻塞的线程,将Empty条件等待队列的结点加入到同步等待队列中,最后被put中的finally中的unlock方法给唤醒
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
items[putIndex] = x; //添加数据
if (++putIndex == items.length)
putIndex = 0;
count++;
notEmpty.signal();
}
在这里有一个重点方法,就是上面的这一句,当长度达到外部设置的长度之后,不会进行一个扩容操作,而是直接通过追加写的方式,从头开始。这就不禁有一个疑问了,为何这样设计,在印象中通过这种方式设计的结构,那么久只有环状的数组了
if (++putIndex == items.length)
putIndex = 0;
我直接好家伙,简直太精髓了,因为数组在删除数据的时候,那么就会有大量的数据需要移动,那么无论在空间还是时间都会产生一定的成本,因此为了优化这一步骤,直接采用环状的形式。
比如take一个数据,由于是要保证先进先出的原则,那么就需要删除头结点的数据,那么后面的全部数据都要发生一次移动,那不会影响出队的效率问题吗,因此这就不得不说这个takeindex的作用了
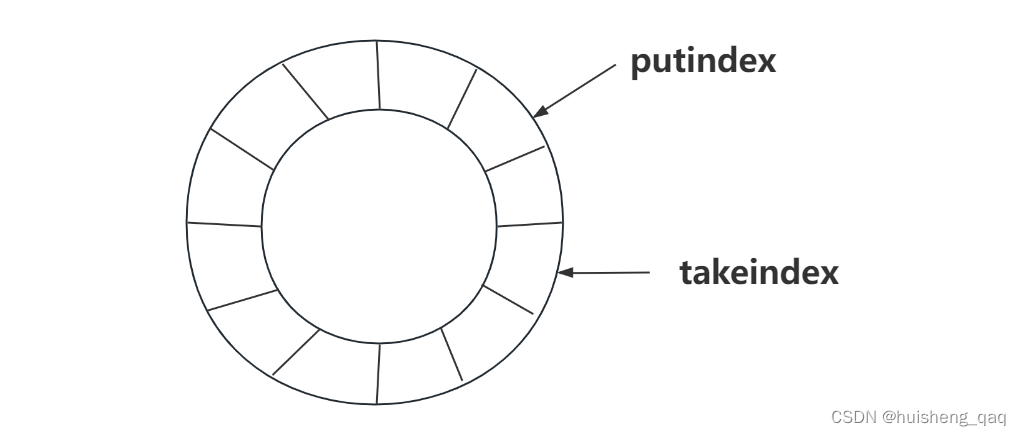
如果在数据出队后,采用环状的数据结构,那么就不需要因为删除数组的前面数据而移动数组后面的数据,只需要修改这个takeindex的指向就可以了,这样就成功的优化了出队的效率,从而减少大量数据的移动,不得不说真的是太强了
详细的可以参考本人写的JUC系列8,循环屏障的的底层实现原理,讲解的更加的详细,从条件队列转换到同步队列的逻辑都讲解的比较清楚
3.3,出队操作
接下来查看数据出队的操作,如下面的take方法,也会先获取这把全局的互斥锁,随后会判断队列是否为空,然后再入队的操作
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock; //获取全局的互斥锁
lock.lockInterruptibly(); //允许锁可中断
try {
while (count == 0) //如果队列中数据为空
notEmpty.await(); //阻塞
return dequeue(); //队列中数据不为空,出队
} finally {
lock.unlock(); //解锁
}
}
如果队列的数据不为空,则进入出队的逻辑,即这个dequeue方法。这里面的逻辑也比较简单,上面说了使用环状+修改下标的位置来解决这个大量数据移动的问题,就是通过这段代码来实现的。在将数据取出完成之后,说明此时队列处于没满的状态,那么就会唤醒因为满了而加入条件队列的数据,从而从条件队列转移到同步队列,最后通过take方法的finally方法中的unlock将结点唤醒
private E dequeue() {
final Object[] items = this.items; //获取这个数组
@SuppressWarnings("unchecked")
E x = (E) items[takeIndex];
items[takeIndex] = null; //将头结点数据置为空
if (++takeIndex == items.length) //takeindex加1,修改指针指向位置
takeIndex = 0; //环状数组
count--;
if (itrs != null)
itrs.elementDequeued();
notFull.signal(); //唤醒因数组满而加入到条件队列的数据
return x;
}
4,总结
ArrayBlockingQueue内部主要是通过数组的方式实现的阻塞队列,内部采用的是环状数组,并且记录了入队和出队的两个下标,从而优化在数据出队时产生数据大量移动的问题。队列保证先进先出原则
ArrayBlockingQueue内部用了ReentrantLock互斥锁和两个条件队列组成,在put加入数据时,如果队列满了则会将这个线程加入条件队列,在take取出数据时,如果数组数据为空也会将这个线程加入条件队列。put和take成功都会唤醒另一个条件队列的线程
ArrayBlockingQueue更加的适用于生产者和消费者的模型,并且生产速度和消费速度比较接近的情况下使用。并且生产者和消费者共用一把互斥锁,没有单一的职责,即不能并行的工作,那么在高并发的场景下,是会会存在的一定的瓶颈的