Transformer
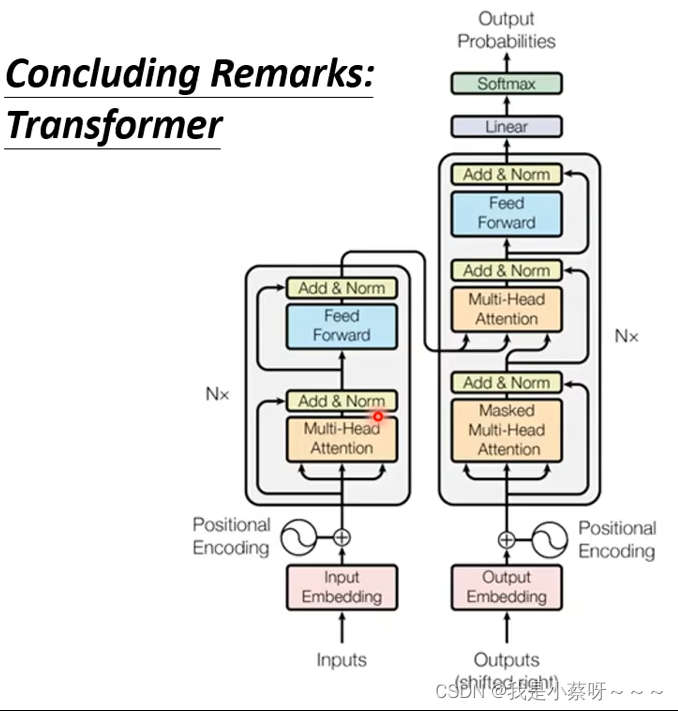
前言
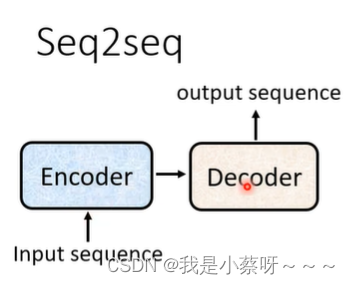
transformer是一个sequence-to-sequence(seq2seq) 的 model
input a sequence,output a sequence.
The output length is determined by model.
例如
语音辨识:
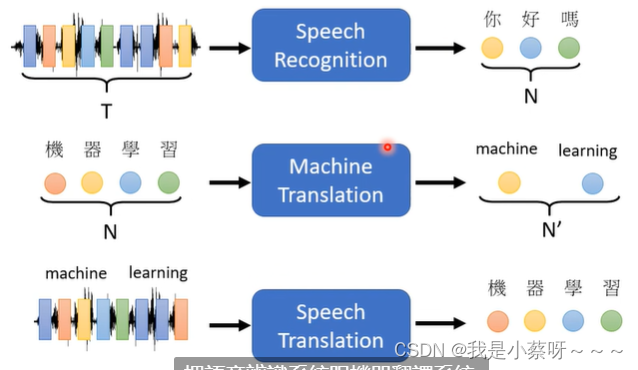
那么为什么不能把以上三种模型结合起来,进行语音识别呢?
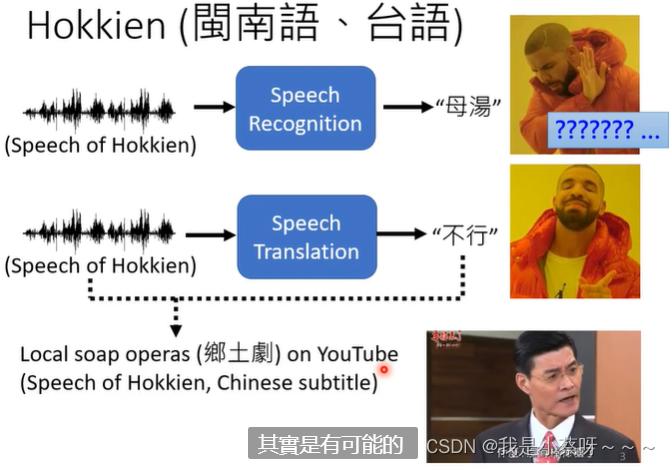
因为有一些语言根本没有文字。Language without text.
台语、闽南语(Hokkien),其方言一般人比较难懂。
所以我们期待说,机器可以做语音的翻译。
第四句上:机器在倒装的句子上没有学习起来。

语音辨识: 语音——>文字
语音合成: 文字——>语音
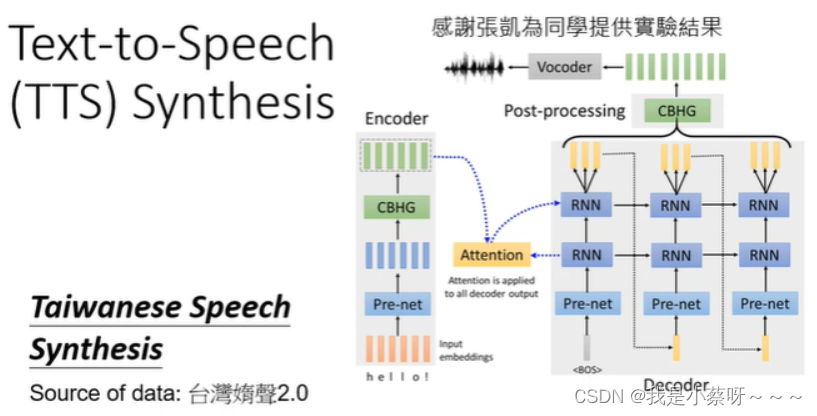
在文字上,也很广泛的使用了Seq2seq

关于语言处理更多的应用:
QA(Question Answering)
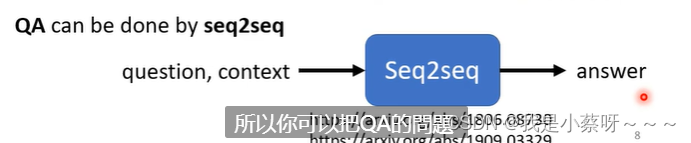
在某些问题上,你可能不认为它是seq2seq model的问题,但是你也可以用seq2seq model去硬解它。
例如:
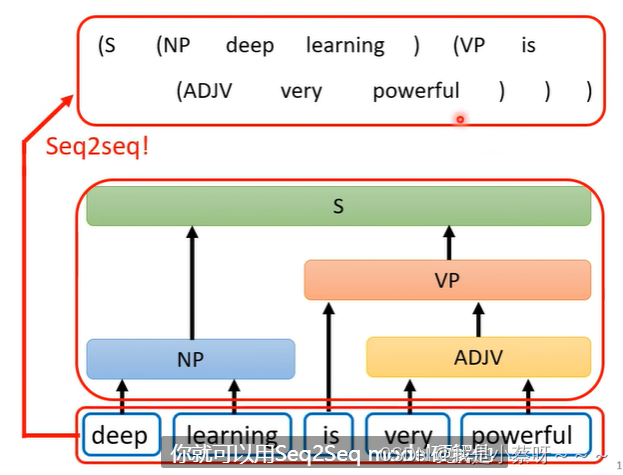
Seq2seq for Syntactic Parsing
输出是一个树状的结构,但是可以硬把它看作一个序列结构
具体可以读 《Grammar as a Foreign Language》
Seq2seq for Multi-label Classification
一个东西可以属于多个class
例如,将一个文章丢到一个分类器中,分类器每次只能输出相同数目的答案,但是这个文章可以属于多个类别,且类别数不固定。这时可以使用seq2seq model硬做。


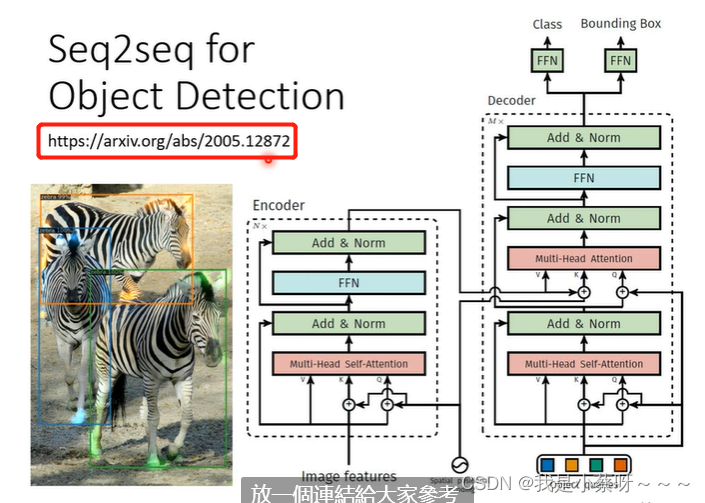
Seq2seq for Object Detection
例如:
给机器一张图片,让机器自动把斑马框起来
怎么做Seq2seq?
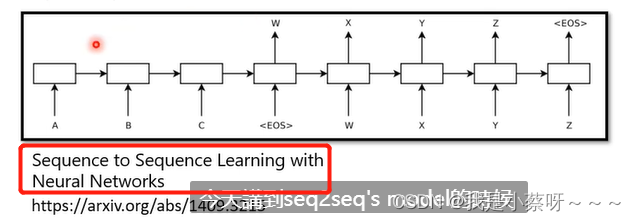
Seq2seq model的起源:《Sequence to Sequence Learning with Neural Networks》
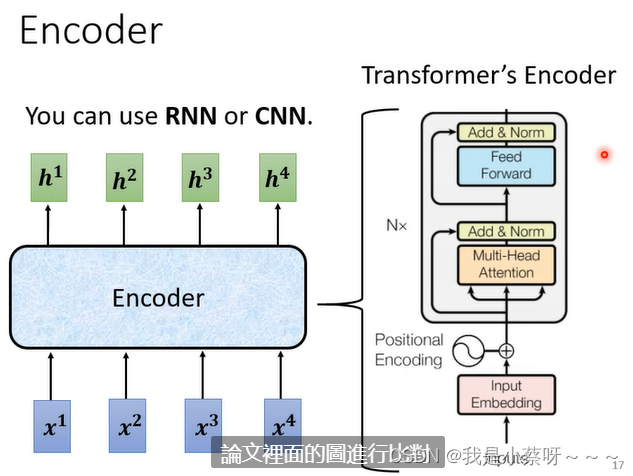
Encoder
其所需要做的事情:给一排向量输出另外一排向量。
这个工作RNN、CNN也可以做。在Transformer 里面,用的encoder是self-attention。
架构解释:
encoder分成了很多个block,每一个block都是输入一排向量、输出一排向量。
注意:不要说每一个block是一个layer,因为一个block是好几个Layer组合。
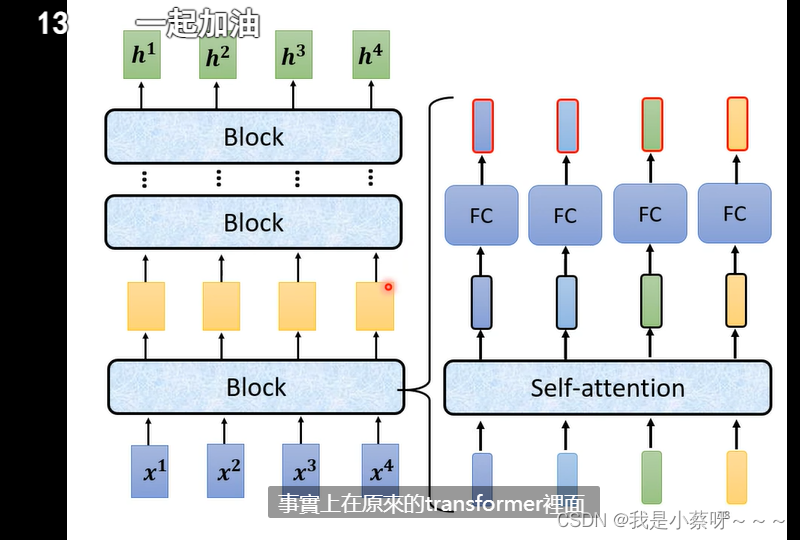
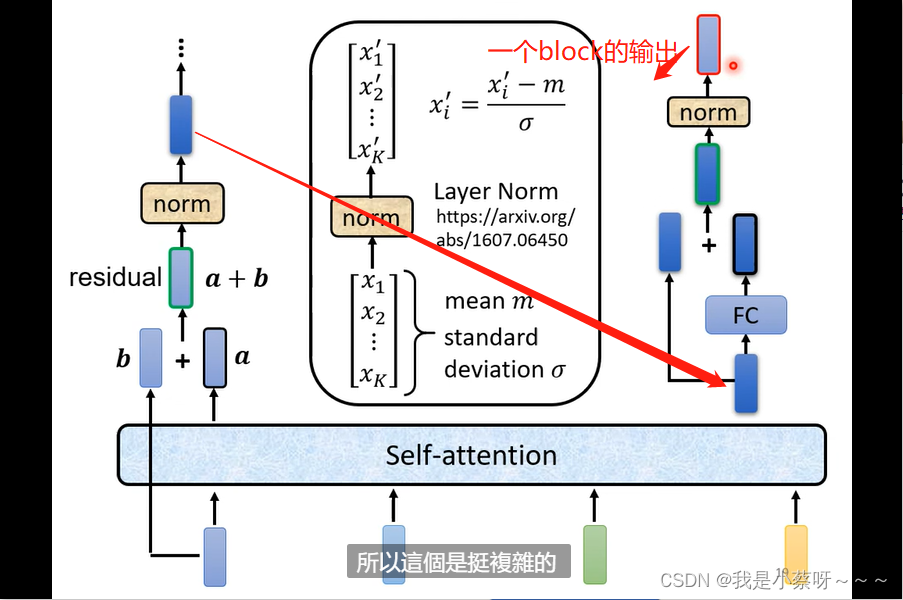
事实上,在原来的transformer里面做的是更复杂的事情:
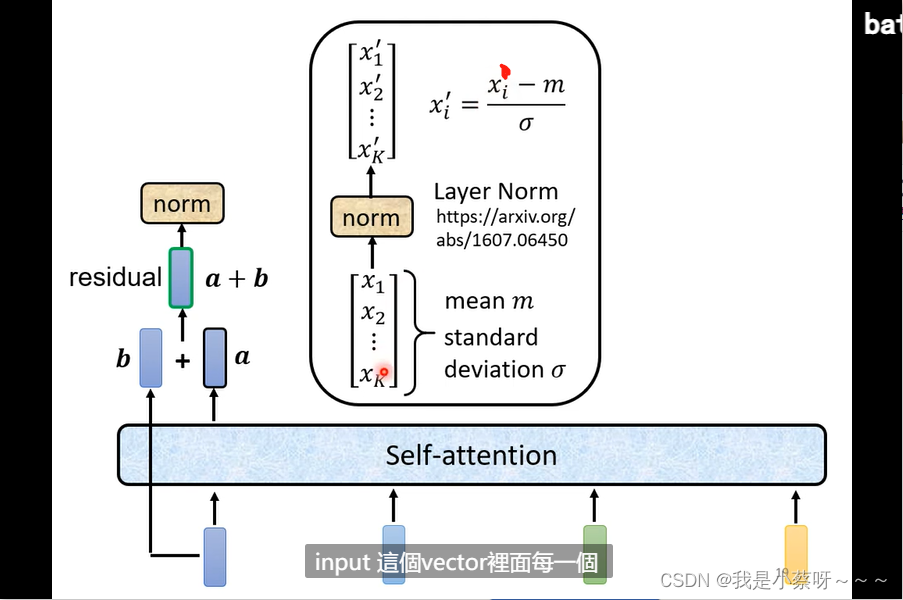
residual connection——残差网络
layer norm——不用考虑batch的资讯,直接去计算不同的维度,同一个example、不同feature的 mean和standard deviation。
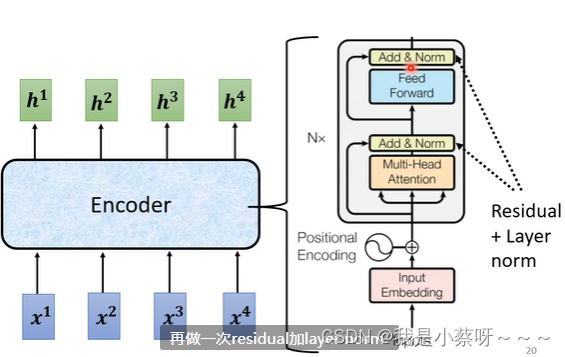
bert其实就是transformer的encoder
transformer的encoder不一定要这么设计,有更多好的设计:
Decoder——Autoregressive(AT)
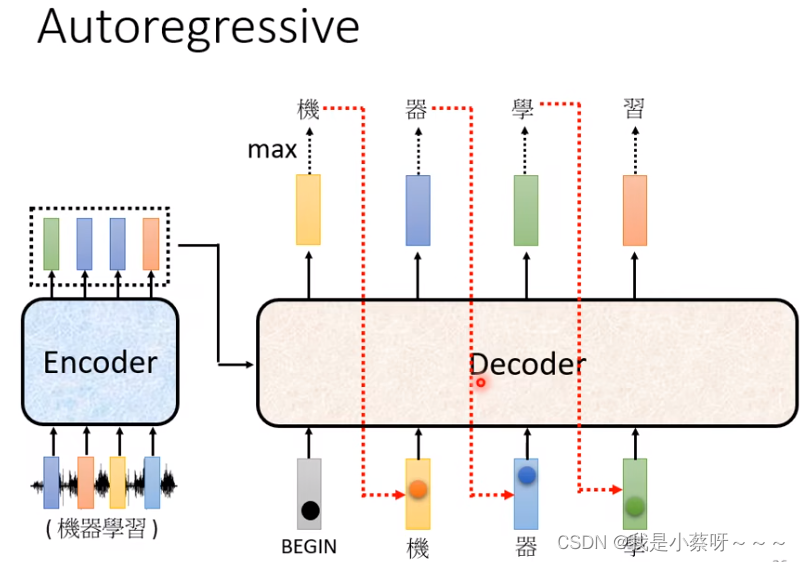
Begin(Special Token)——ESO,代表开始,使用one-hot vector来表示。
decoder首先要读取encoder的输出。
decoder先会输出一个distribution,选取得分最大的值(概率)输出。
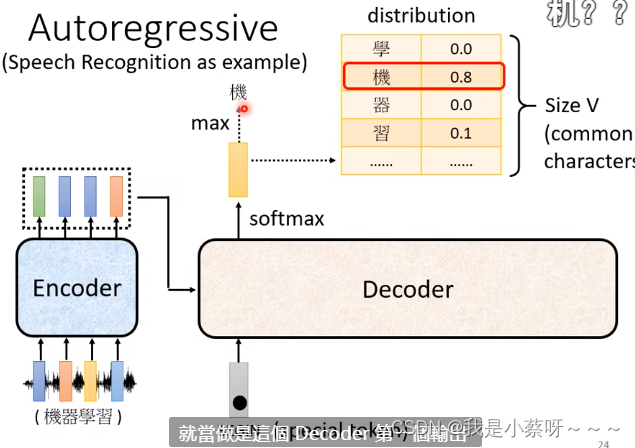
然后把“机”当做他的另一个输入,根据 BEGIN和“机” 来决定输出 “器”,然后过程反复持续下去。
issue:前一个输出错误会影响后续的输出,一步错步步错。 后续会讲如何避免这个问题,先无视这个问题。
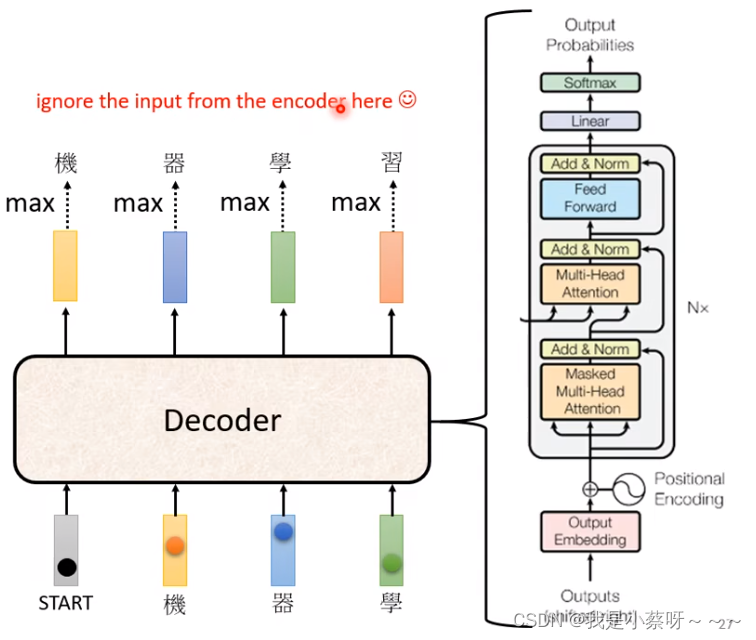
将encoder和decoder部分比较一下,我们发现,把右边红框部分去掉,两者没有太大区别。
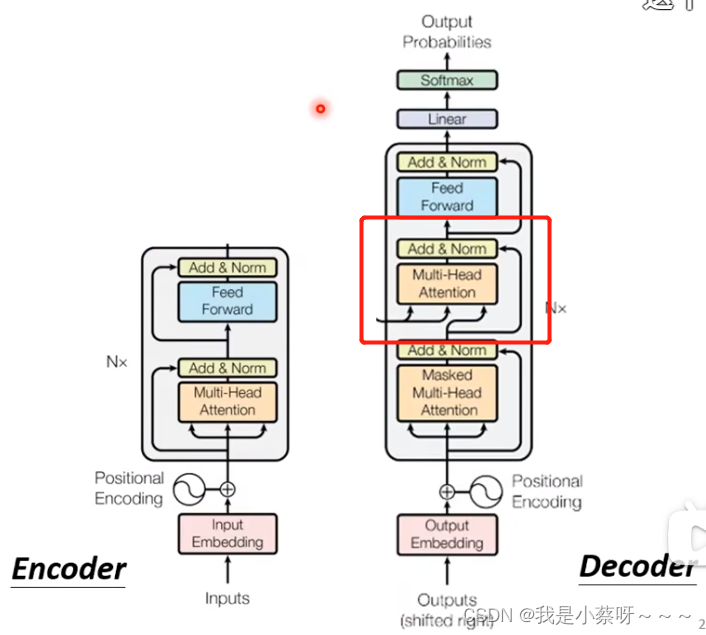
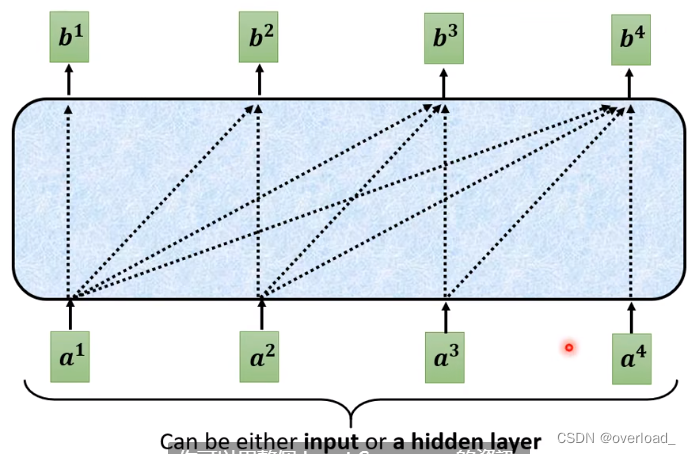
Masked Multi-Head Attention
decoder中Masked Multi-Head Attention中的Masked:
不考虑右边input的资讯
为什么要加masked?
对decoder而言,是现有a1再有a2…,没有办法把后面的考虑起来。
—————————————————————分割线————————————————————
Adding “Stop Token”
Decoder必须自己决定input sequence的长度,但是我们不知道输出的正确的长度为多少。
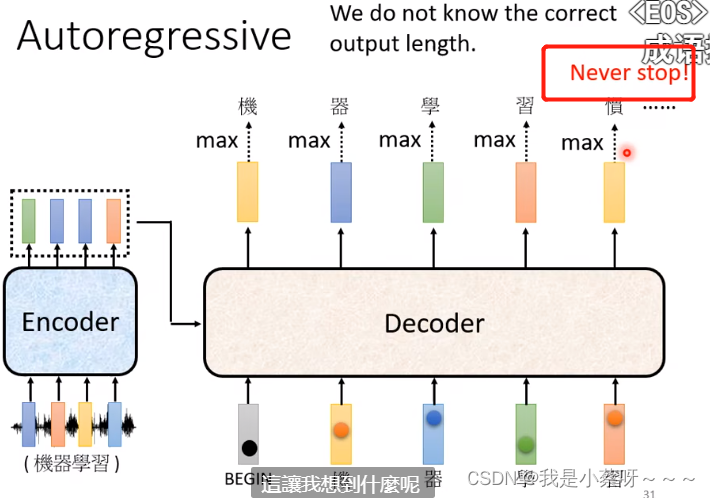
因此 我们加入一个stop token:END(EOS)
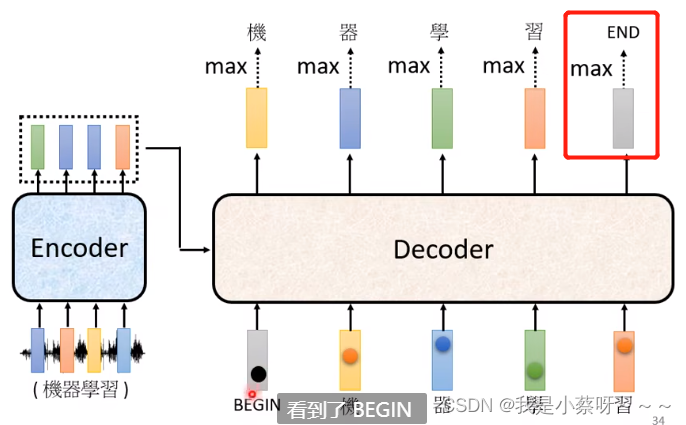
Decoder——Non-autoregressive(NAT)
我们如何决定NAT的输出长度?
方法一:再设一个classifier,吃decoder的input,输出一个数字,代表NAT decoder的输出长度。
方法二:设置一个长度上限,找到END,直接忽略掉其右边的输出。
NAT优点:
(1)NAT可以平行化。AT不可以。因此在速度上NAT较快。
(2)比较可以控制其输出的长度。
NAT的表现往往不如AT。(Why?Muti-modality)
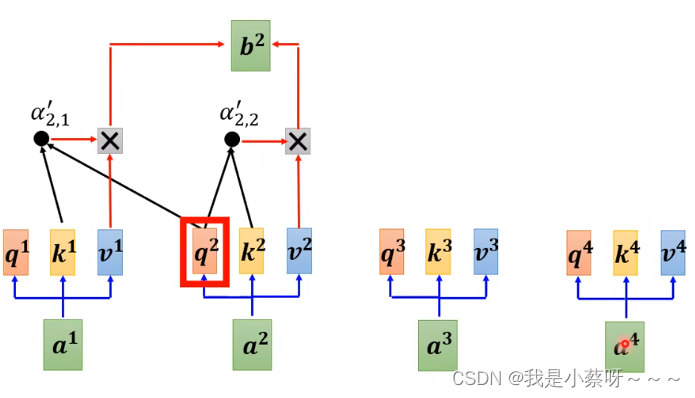
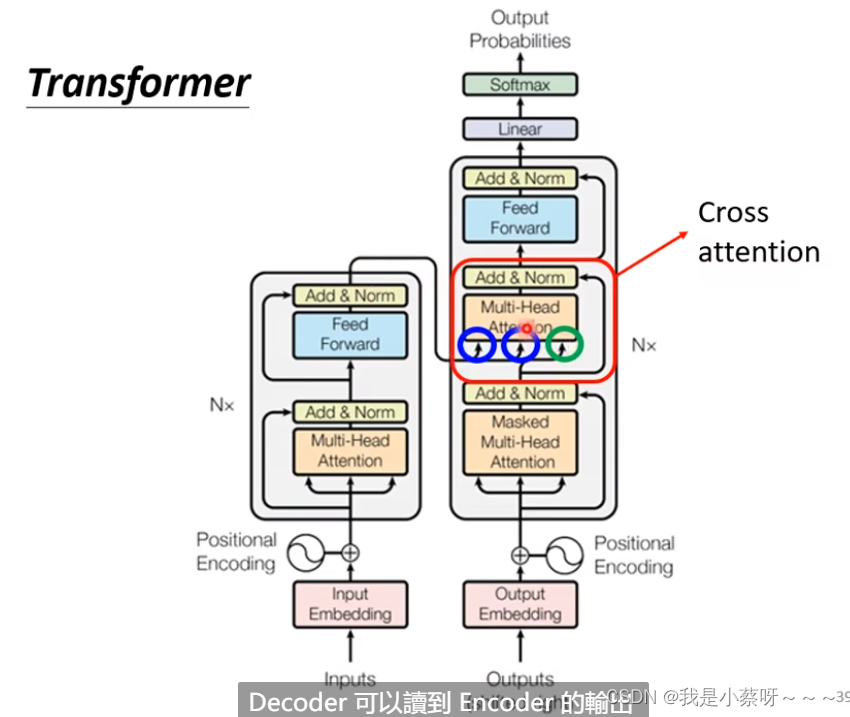
Cross attention
是连接encoder和decoder这一块的桥梁,两个输入k v来自encoder,一个输入query来自decoder
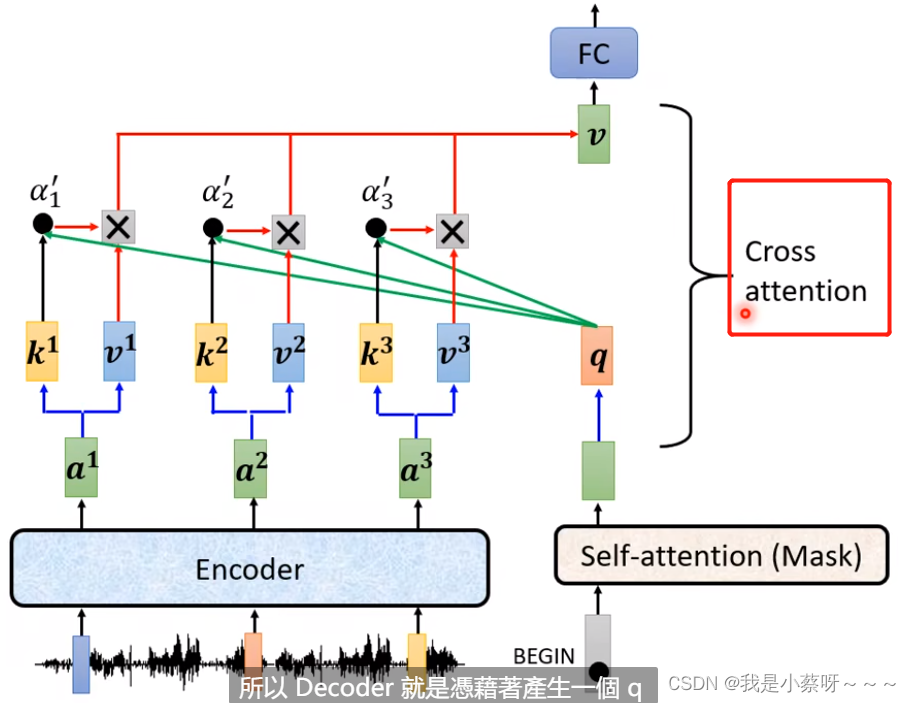
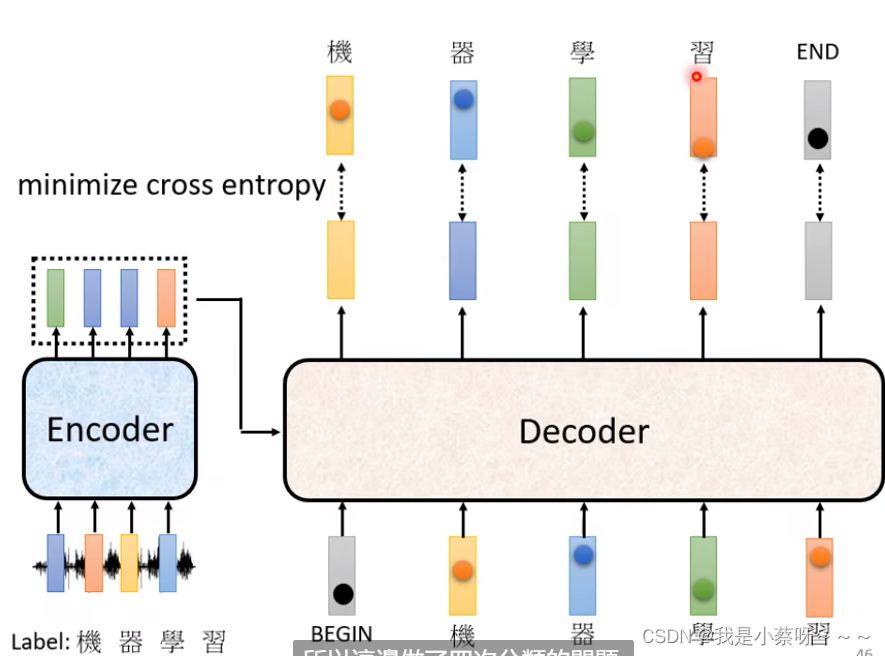
Training
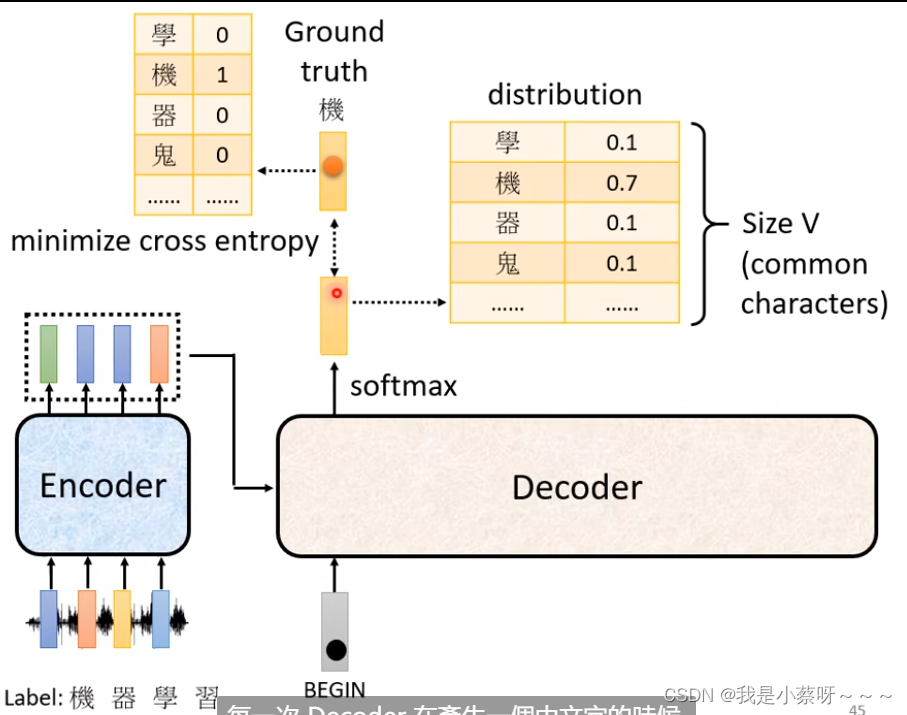
我们希望所有的cross entropy的总和最小
Teacher Forcing:using the ground truth as input. 输出的时候告诉decoder正确答案
Scheduled Sampling
exposure bias:训练时decoder看到的是正确信息,测试时不是。但是如果训练时,decoder只看过正确的东西。则在测试时看到错误的东西的时候可能会导致整个结果坏掉,解决的方向:在训练的时候加入一些错误的东西。
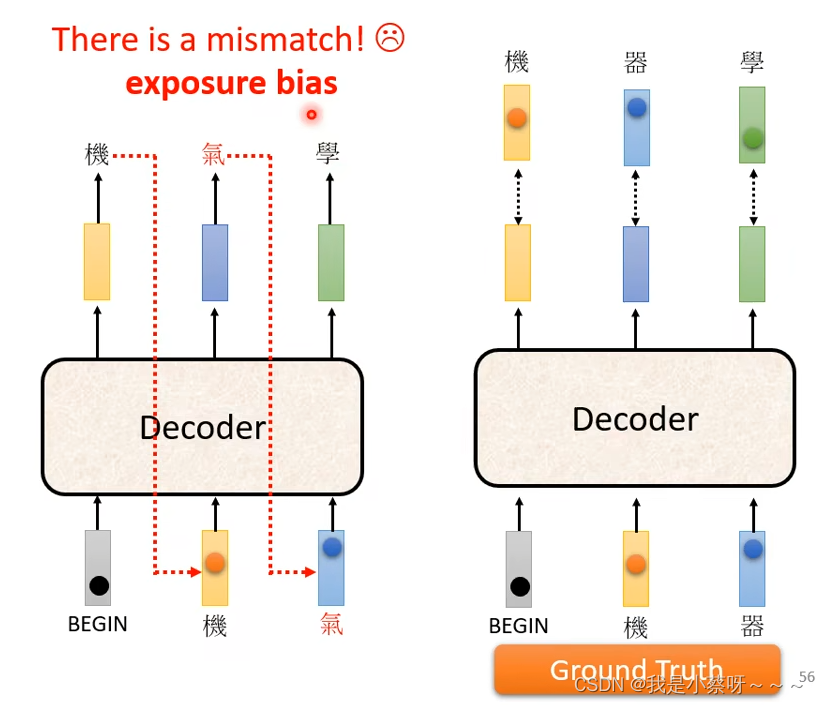
但是传统的scheduled sampling会伤害到transform平行化的能力。具体参考以下文章。