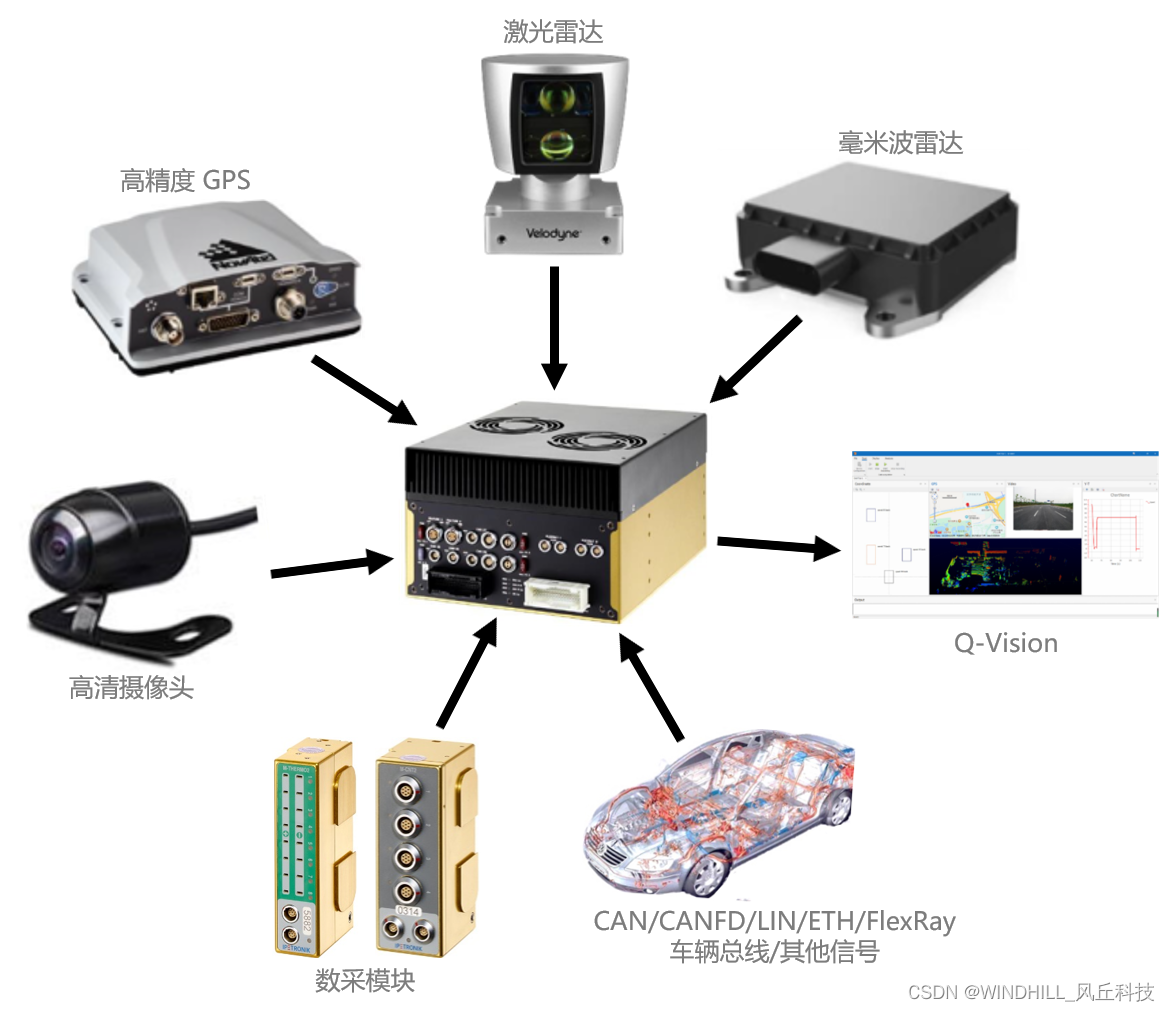
语法格式:
awk [选项参数] ‘/pattern1/{action1} /pattern2/{action2}...’ filename
pattern:表示 awk 在数据中查找的内容,就是匹配模式
action:在找到匹配内容时所执行的一系列命令
awk常见参数选项:

awk常见内置变量:

常用命令:
#过滤2,3行
awk 'NR==2,NR==3' test.txt
#取文件的第一列、第三列和最后一列的内容,并打印行号,awk的取列功能,这是awk的本行,即考$n及NF、NR的用法。
awk -F ":" '{print NR,$1,$3,$NF}' test.txt
#搜索 passwd 文件以 root 关键字开头的所有行,并输出该行的第1列和第7列,中间以“,”号分割
awk -F : '/^root/{print $1","$7}' passwd
#只显示/etc/passwd 的第一列和第七列,以逗号分割,且在所有行前面添加列名 user,shell 在最后一行添加"endfile"
awk -F : 'BEGIN{print "user, shell"} {print $1","$7}END{print "endfile"}' passwd
#将 passwd 文件中的用户 id 增加数值1并输出
awk -v i=1 -F : '{print $3+i}' passwd 切割 ifconfig 中的 ip:
ifconfig ens33 | awk '/netmask/ {print $2}'将域名取出并进行计数排序:
http://www.etiantian.org/index.html
http://www.etiantian.org/1.html
http://post.etiantian.org/index.html
http://mp3.etiantian.org/index.html
http://www.etiantian.org/3.html
http://post.etiantian.org/2.html# 取出每行中的域名:
awk -F '/' '{print $3}' hosts.txt
# 排序(让相同的域名相邻):
awk -F '/' '{print $3}' hosts.txt|sort
# 去重计数:
awk -F '/' '{print $3}' hosts.txt|sort|uniq -c