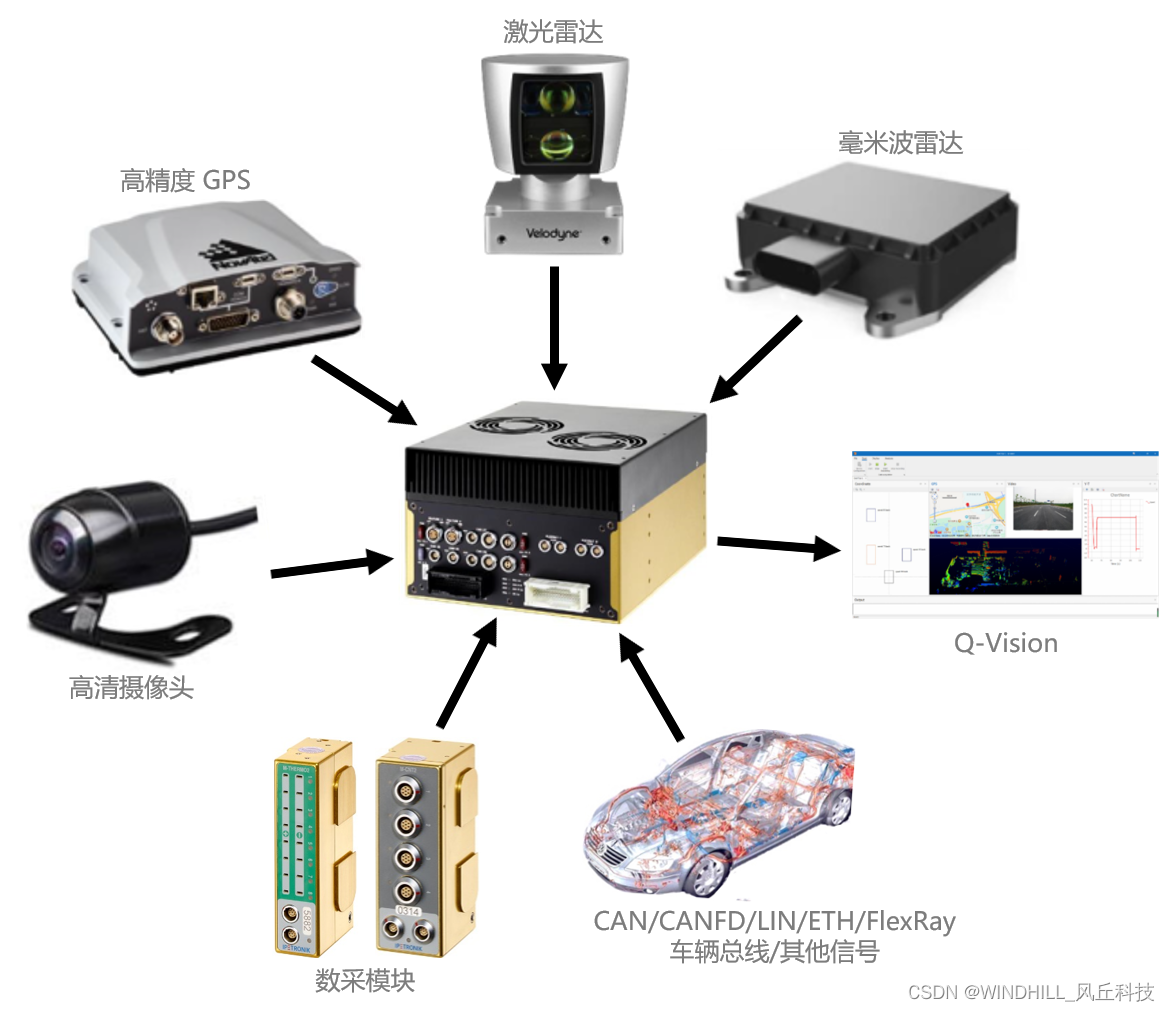
前期的文章,我们介绍过stable-diffusion的相关操作,stable diffusion模型是Stability AI开源的一个text-to-image的扩散模型,其模型在速度与质量上面有了质的突破,玩家们可以在自己消费级GPU上面来运行此模型,本模型基于CompVis 和 Runway 团队的Latent Diffusion Models。stable diffusion模型核心数据集在 LAION-Aesthetics 上进行了训练,该模型在Stability AI 4,000 个 A100 Ezra-1 AI 超集群上进行了训练,能够在消费级10 GB VRAM GPU 上运行,可在几秒钟内生成 512x512 像素的图像。

而stable diffusion模型的缺点是我们需要写很多的prompt,优化关键词,才能输出自己想要的图片。但是这里总感觉怪怪的,其输入的prompt都是一些关键词,并不是一个完整的句子,这跟人类的思路并不一样。能不能不用输入关键词,只是跟模型进行聊天式的操作,让模型输出自己想要的图片?

ChatGPT是一个已经火了大半年的对话聊天模型,当然,此模型不仅仅应用在对话聊天上面,随着GPT-4模型以及相关插件的加持,让ChatGPT系列模型有了质的飞跃。

既然ChatGPT这么了解人类的对话,是否可以直接让ChatGPT用作输入,跟AI绘画模型结合起来,是不是以上的问题就迎刃而解了。近日openAI预发布DALL·E3模型,让ChatGPT加持AI绘画,让文本生图模型又有了一大步的飞跃。

DALL·E2是OpenAI发布的一个绘画模型,但是由于stable diffusion以及midjourney等模型的大火,其DALL·E2绘画模型稍微略显逊色。但随着ChatGPT的大火,OpenAI考虑把ChatGPT的功能与AI绘画结合起来,让模型更加了解人类的需求,且输入的句子,可以按照人类聊天的方式。这就是OpenAI即将发布的DALL·E3模型,虽然模型还没有正式发布,但是官网已经放出了相关的技术细节与样张图片。

与DALL·E2相比,即使输入同样的一句prompt,其DALL·E3输出的图片,更加符合人类的预期,且效果惊人。
“An expressive oil painting of a basketball player dunking,
depicted as an explosion of a nebula.”
左:DALL·E2,右:DALL·E3
DALL·E 3 原生构建于 ChatGPT 之上,我们可以直接使用 ChatGPT 作为输入,并让DALL·E 3输出我们想要的图片,当年ChatGPT发布的时候,很多人诟病说ChatGPT只能输出文字,不能输出图片,还有各路大牛出教程让ChatGPT输出图片。这不,它来了,基于ChatGPT的DALL·E 3可以满足你想要的需求。

ChatGPT 将自动为 DALL·E 3 生成定制的详细提示prompt。 如果你喜欢某个特定的图像,但它不太正确,这里可以在 ChatGPT 中,输入几句话就可以进行调整。DALL·E 3 将于 10 月初向 ChatGPT Plus 和 Enterprise 客户提供。
https://openai.com/dall-e-3 # 参考链接更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:启示AI科技
微信中复制如下链接,打开,免费体验chatgpt
https://wx2.expostar.cn/qz/pages/manor/index?id=1137&share_from_id=79482&sid=24
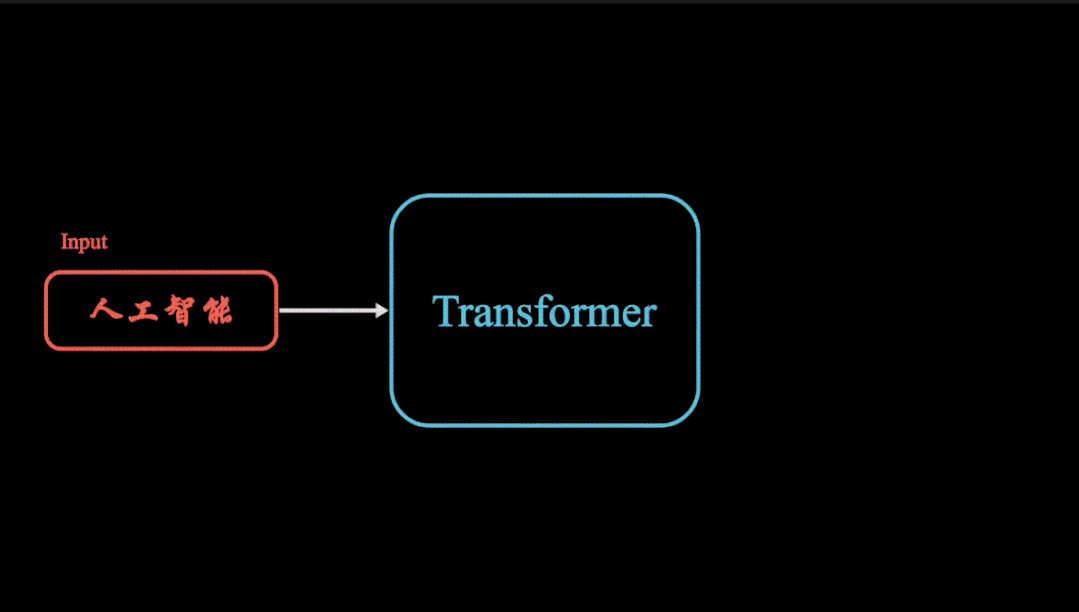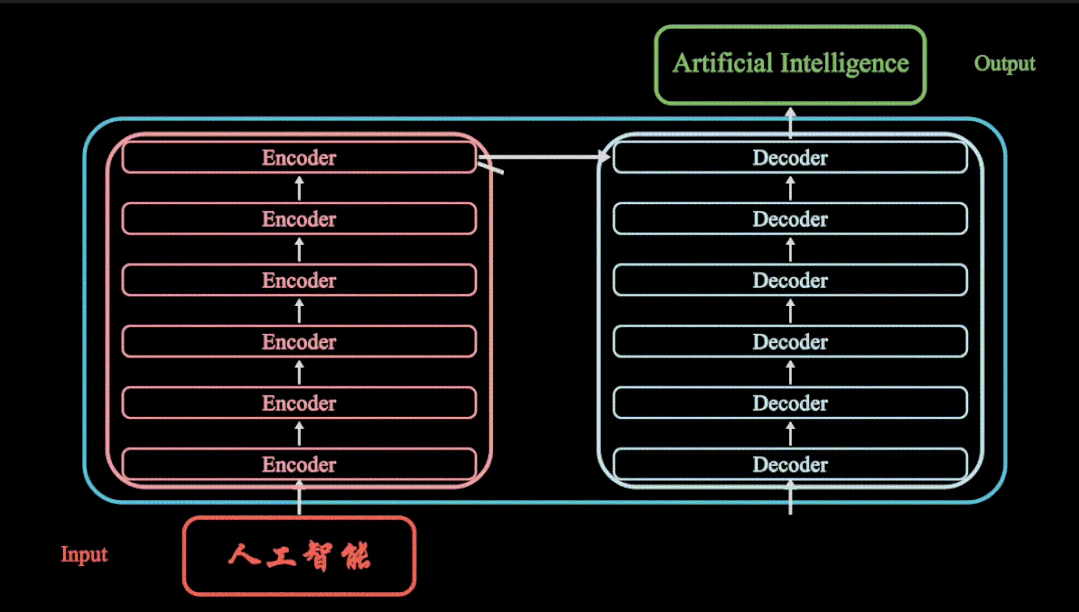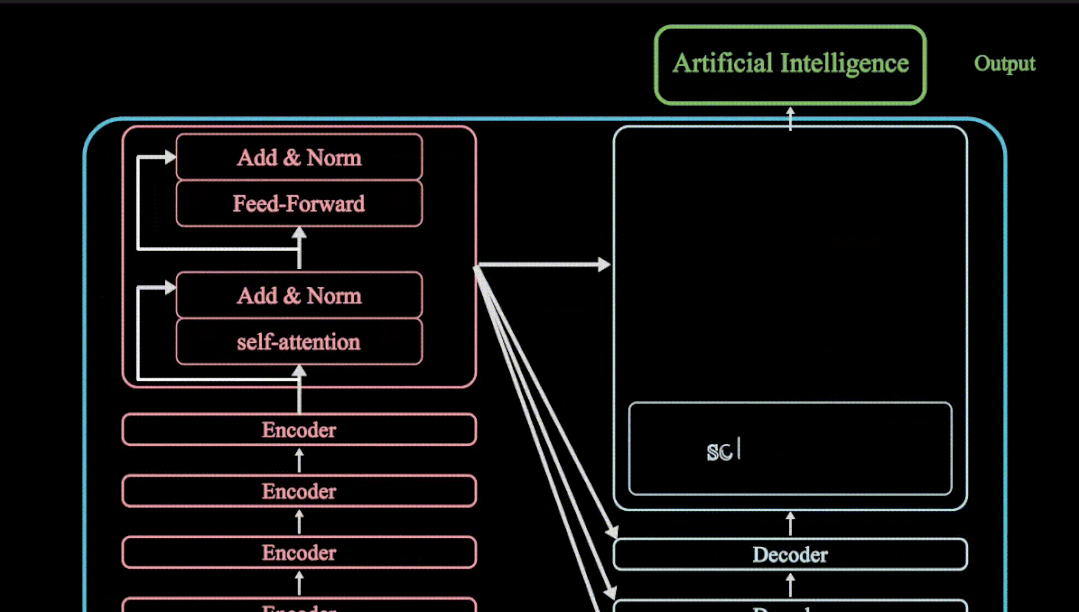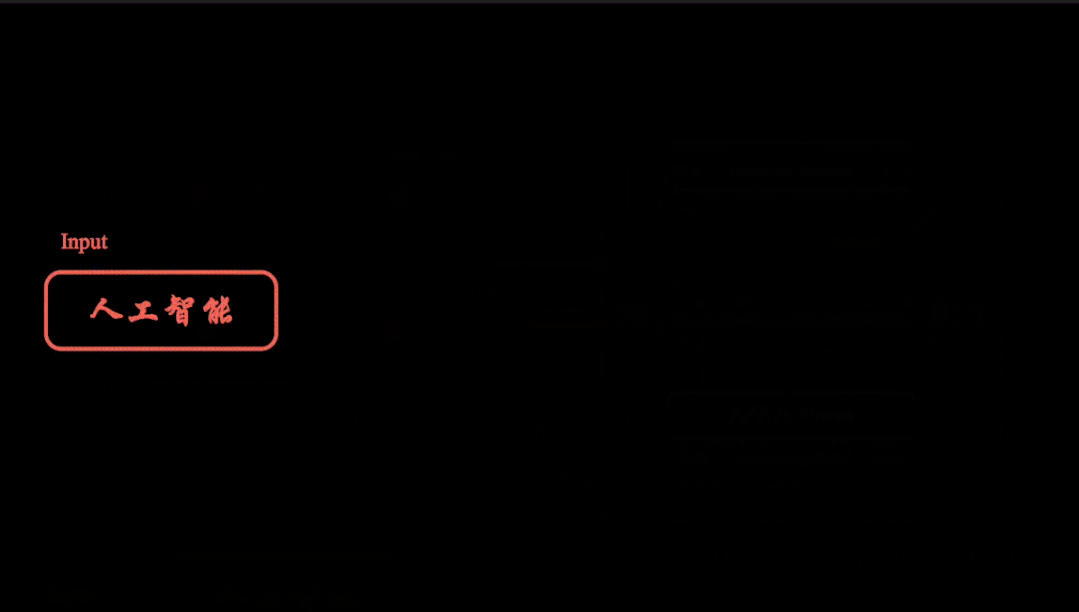
动画详解transformer