🪴 背景
前端的自动化测试主要可以分为以下四种:
-
单元测试(Unit Test):对一个函数/组件进行测试,一般用于公共函数/公共组件的测试维护。常用框架有 Jest、Jasmine、Mocha等; -
集成测试(Integration Test):对多个模块作为一个整体进行测试,一般用于耦合度较高的函数/组件、经过二次封装的函数/组件、多个函数/组件组合而成的函数/组件等。常用的框架有ReactTestUtils、Enzyme、Vue-Test-Utils 、React-Testing-Library等; -
UI测试:是对界面样式和交互的测试。 -
端到端测试(end to end,简称e2e):模拟用户操作的黑盒测试。设定一系列操作,测试系统是否能够按照我们设置的步骤正确执行,可以完整测试整个功能的运行。常用的框架有 Puppeteer、Cypress、Playwright(微软出品,配合vscode插件使用)、Selenium 、cucumber、TestCafe等。
前端开发一般也就单元测试用到比较多,像e2e这种测试几乎不会用到。
确实,因为e2e测试也有一定的开发成本,再好的东西也得适用不是。
那么什么情况下适合引入自动化测试呢?例如以下三个场景:
- 公共类库、公共组件的开发维护;
- 中长期项目的迭代/重构;
- 引用了不可控的第三方依赖;
举个例子,项目中有一个非常重要的下单页面,经过长期的功能迭代重构,核心逻辑可能没变,但是新增了很多新功能,也修改了部分旧功能,已经是一个非常重要的屎山页面。
这时候要你接手这个页面做一些调整,你能保证捋清并且不破坏掉以前的代码逻辑逻辑吗?我敢说你不敢保证,修改点代码生怕造成“事故”,全公司通报。
这时候自动化测试的重要性就体现了,如果在开始就设计好一套核心逻辑的自动化测试脚本,那么在之后迭代的过程中不仅可以通过跑测试脚本缕清逻辑,并且还能在修改代码后用脚本验证自己是否破坏了核心的逻辑。
本文和大家讲解一下e2e自动化测试框架 –
puppeteer的基础使用教程。
🌻 教程
1. Puppeteer是什么?
Puppeteer 是一个 Node.js 库,使用它可以运行一个无头的谷歌浏览器(即不显示图形用户界面的浏览器)。然后我们就可以在运行的浏览器中启动我们的页面,并且通过 Puppeteer 提供的 API 操作页面了。
Puppeteer默认是以 headless 无头模式运行,在写测试脚本的时候,为了方便看到效果,可以配置关闭无头模式,即可正常打开浏览器看到页面自动操作的效果。
2. Puppeteer能做什么?
基本上我们平常在浏览器中进行的操作都可以用 Puppeteer 模拟操作,例如:
- 操作dom,执行dom的各种点击,移动等事件;
- 模拟键盘输入,鼠标操作。触摸移动等一系列操作;
- 捕获网站的
timeline trace,分析网站性能; - 网页截图,生成 PDF;
- 抓取 SPA(单页应用)并生成预渲染内容(即“SSR”(服务器端渲染))
等…
3. Puppeteer怎么上手?
(1) 首先安装 Puppeteer
安装 Puppeteer 时会安装一个内置的 Chromium 浏览器,国内用 npm 安装会报错失败,装不上 Chromium,可以改用 yarn 或者 cnpm 安装。
puppeteer还提供了一个轻量级的包—
puppeteer-core,这个包不需要下载 Chromium,而是直接启动现有浏览器或连接到远程安装。
yarn add puppeteer
//或者
cnpm i puppeteer
(2) 上手
先 require 引入 puppeteer
const puppeteer = require('puppeteer');
然后开始使用 puppeteer 启动一个浏览器并操作页面。首先需要创建一个 Browser 实例,打开页面,然后使用就可以使用 Puppeteer 的 API 进行你想要的操作了。
const puppeteer = require('puppeteer');
(async () => {
//首先创建一个 Browser 实例
const browser = await puppeteer.launch();
//然后创建一个 tab页的 Page 实例
const page = await browser.newPage();
//然后可以打开我们的网页了
await page.goto('https://example.com');
})();
可以看到我们用了 async / await 语法,是的,在 puppeteer 中,几乎所有操作都是异步的,所以一般使用时需要频繁的用到 async / await ,所以使用前要检查 Node 版本大于 v7.6.0。
如果你需要手动下载 Chromium,还可以配置 Chromium 或 Chrome 可执行文件的位置。
const browser = await puppeteer.launch({executablePath: '/path/to/Chrome'});
正如我们上面所说,怎么关闭 puppeteer 的无头模式呢?只需要在实例化时配置即可。
//关闭无头模式
const browser = await puppeteer.launch({headless: false});
配置无头模式之后,我们就可以看到puppeteer会调起一个可视的 Chromium 或 Chrome 浏览器了,这样方便我们直观的看到效果。但是由于puppeteer的操作一步接一步,速度非常快,可能看不清,所以可以使用slowMo参数配置延迟每步操作的时间,如下:
//关闭无头模式
const browser = await puppeteer.launch({
headless: false,
slowMo: 1000
});
4. Puppeteer的 API
puppeteer 常用的实例有以下几种:
- Brower(浏览器实例):Puppeteer通过
launch或
connect方法连接到 Chromium 时创建一个浏览器实例;可以执行浏览器断开连接、重连、关闭浏览器、打开tab页、获取useragent代理信息等操作; - Page(tab页实例):Brower实例通过
newPage方法打开一个tab页。关于页面内容的操作一般都会用到这个实例,例如截图、操作dom、跳转tab页、关闭tab页、延迟操作。凡是和页面元素相关的基本都是用它。 - Keyboard(键盘实例):模拟键盘操作
- Mouse(鼠标实例):模拟鼠标操作
- Touchscreen(触屏操作):模拟触屏操作
- Frame窗口实例
我这里就简单说明几个常用操作,详细的 API 使用可以查看官网文档
(1)获取元素 page.$()、page.$$()
page.$()相当于 document.querySelector,返回匹配的元素节点的第一个。比如获取按钮,然后执行点击事件:
let submitBtn = await page.$("#submit");
submitBtn.click()
page.$$(selector) 相当于 document.querySelectorAll,返回所有匹配的元素节点。
let inputArr = await page.$$('input')
(2)获取元素属性 page.$eval()、page.$$eval()
获取元素属性不能像平常写js那样,获取到元素之后,用dom.value获取它的值或者获取其他属性。可以使用 page.
e
v
a
l
(
)
或
p
a
g
e
.
eval() 或 page.
eval()或page.$eval() 获取元素属性,区别和上面获取元素雷同。
$eval()是对单个元素进行操作。
$$eval()是对匹配到的所有元素进行操作。
//获取输入框的值
const value = await page.$eval('input[name=search]', input => input.value)
//获取输入框的个数
const num = await page.$$eval('input', input => input.length)
(3)脚本注入 page.evaluate()
如果要执行某段自定义的js代码,可以用page.evaluate()方法。
例如按钮点击你也可以这么写:
await page.evaluate(() => document.querySelector("#submit").click() )
(4) 执行等待
有时候可能需要延迟代码执行,例如修改了元素的可见性,需要等元素显示出来再执行操作,就可以用page.waitForSelector延迟代码执行。常用的延迟执行的api有:
page.waitForSelector():等待选择器解析的页面元素出现在页面中;page.waitForNavigation():等待页面跳转后;page.waitForXPath():等待 xpath 解析的页面元素出现在页面中;page.waitForFunction():等待放到页面上下文执行的方法返回真值;page.waitForRequest():等待页面上发起的请求满足判断条件并返回真值;page.waitForResponse():等待页面上接收的请求响应满足判断条件并返回真值;page.waitFor():可充当 page.waitForXPath、page.waitForSelector 、page.waitForFunction 和延时效果用。
(5)page实例分为三个管理模块
- _frameManager : 管理页面相关行为,例如页面跳转(goto),等待加载(waitFor), 元素选择与处理(evaluate)等
- _networkManager : 管理网络相关行为,例如请求拦截(setRequestInterception):离线模式(setOfflineMode)等
- _emulationManager - 管理模拟行为,例如修改浏览器的UserAgent代理信息,修改视窗大小等
👣 实操
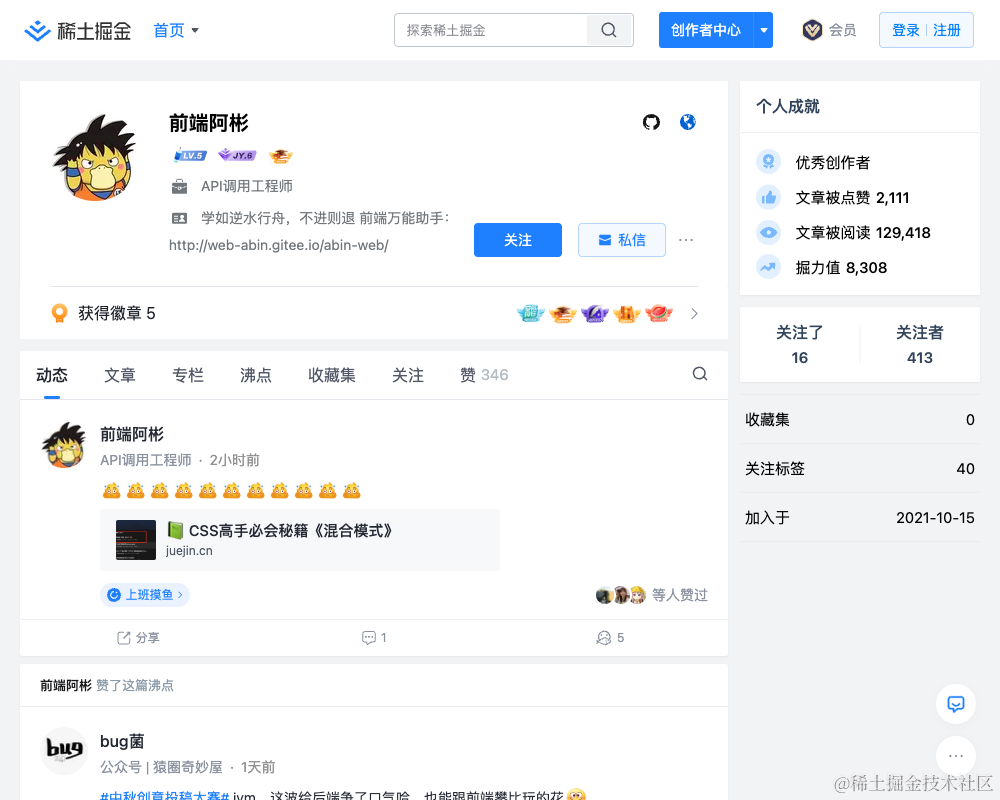
我这里写一个简单的小案例,方便大家理解。
打开掘金搜索到我的主页,进入个人主页并截图
创建 check.js,具体的操作步骤看下面代码里的注释:
const puppeteer = require('puppeteer');
(async () => {
//创建 brower 实例,关闭无头模式,方便查看效果,同时可以设置 slowMo ,放慢自动化操作。
const browser = await puppeteer.launch({
headless: false,
slowMo: 0
});
//创建 page 实例
const page = await browser.newPage();
//设置视口宽高
const viewWidth = 1000
const viewHeight = 800
await page.setViewport({
width: viewWidth,
height: viewHeight,
});
//跳转掘金首页
await page.goto('https://juejin.cn/');
//使用 type 方法向掘金搜索框输入 “前端阿彬”
await page.type('.search-input','前端阿彬',{
delay: 300
})
//使用 keyboard 类的 press 方法模拟键盘按下 "Enter" 键
await page.keyboard.press('Enter');
//这里一定要用 waitForSelector 方法等搜索结果显示出来再继续操作
await page.waitForSelector('.nav-item.route-active')
//点击搜索结果的 “用户” tab
await page.evaluate(() => document.querySelectorAll(".nav-item.route-active>a")[4].click() )
//等用户列表显示出来再继续操作
await page.waitForSelector('.main-list .item')
//获取第一个item,也就是我的个人主页的a链接地址
const href = await page.$$eval('.main-list .item a',link => link[0].href)
//获取到个人主页的href,然后用goto跳转
await page.goto(href);
//等待页面跳转完成再继续操作
page.waitForNavigation()
//调用 screenshot 方法进行截图,并裁减可视区域内的部分
await page.screenshot({
path: '个人主页.png',
clip: {
x: 0,
y: 0,
width: viewWidth,
height: viewHeight,
}
});
//关闭浏览器
await browser.close();
})();
命令行执行 node check.js 执行我们的测试脚本,效果如下:

截图如下:
最后
puppeteer的功能非常强大,基本上平常在浏览器里能手动完成的操作都可以用它模拟。而测试脚本逻辑无非就是调用它的 API,实际逻辑其实还是靠js,所以上手并不难。