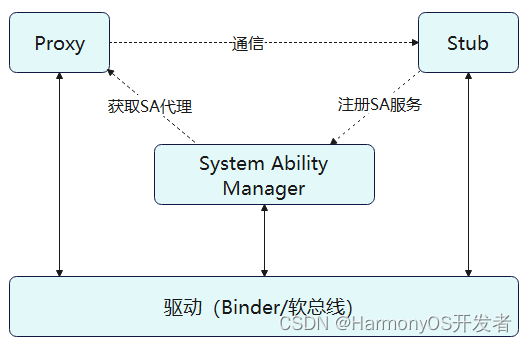
为啥Linux内核对驱动调用要绕这么多弯?
需要去写驱动的,基本是芯片原厂的人。其他的linux驱动从业者,只是调试、改设备树、封装库差不多了。需要“不满足照搬框架去写驱动”的人,应该都是通过芯片原厂面试的人,不会来问这问题。当然要搞清里面的流程还是很有必要的,不能只做api boy,这是值得赞扬和学习的。
简单说说我自己粗浅的理解,就是关于造成现在你看到的认为的绕那么多弯的,我理解原因主要因为四点:最近很多小伙伴找我,说想要一些Linux内核学习资料,然后我根据自己从业十年经验,熬夜搞了几个通宵,精心整理了一份「Linux内核入门到高级教程+工具包」,点个关注,全部无偿共享给大家!!!
评论区回复“888”,关注我之后私信回复“666”,即可拿走。
1.需要面向对象;
2.需要分层管理;
3.需要安全;
4.需要考虑现实中可能会出现的各种“如果”。
面向对象:就是把实体、虚体都抽象出一个归类,求同存异。设备有字符设备、块设备、网络设备,就字符设备都有各种不同的成千上万种实体设备,每个字符设备有除了有字符设备的共性,还有自己的特性,特性包括传输时序、工作方式等等,这些又决定你采用的总线(IIC?UART?CAN?)是不同的。这些就造就了需要不同的驱动去配合,而匹配的方式也各有不同,设备、驱动、总线、数据、内存等等都需要采用面向对象以好去管理,而每个对象,都有不同各自的需要定义和操作方式,这管理起来会很乱,就需要分层管理;
分层管理:分层管理其实说白了就是把做一件事情涉及到的所有对象按照功能、目的去划分步骤,这样管理起来就不会乱,思路会更清晰。例如一个“设备来了,你要去接应它”,看似简单的一句话,可是作为一个好的操作系统内核,你要考虑的是:它是什么设备、从哪里来的、怎么来的、为什么要来、允不允许来、来了要怎么做、它来找谁、它有找那个谁的权限吗、那个谁有空吗、它要来多久、它还带来了什么、它会留下什么、它会改变什么、它可以离开吗、它要怎么离开、它离开了我还要干什么。以上这么多事情,怎么安排内核或者CPU做呢?