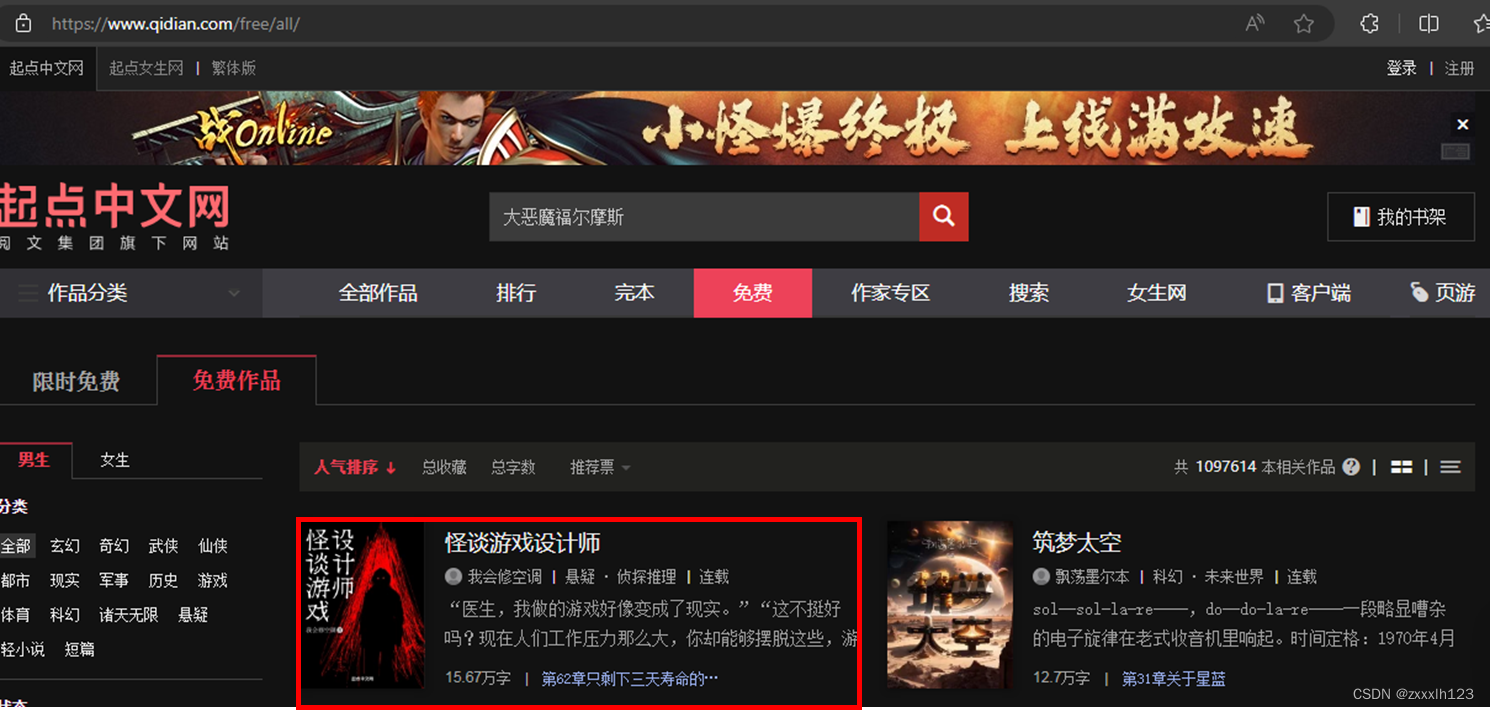
1.用requests和BeautifulSoup爬取起点中文网小说(https://www.qidian.com/free/all/)
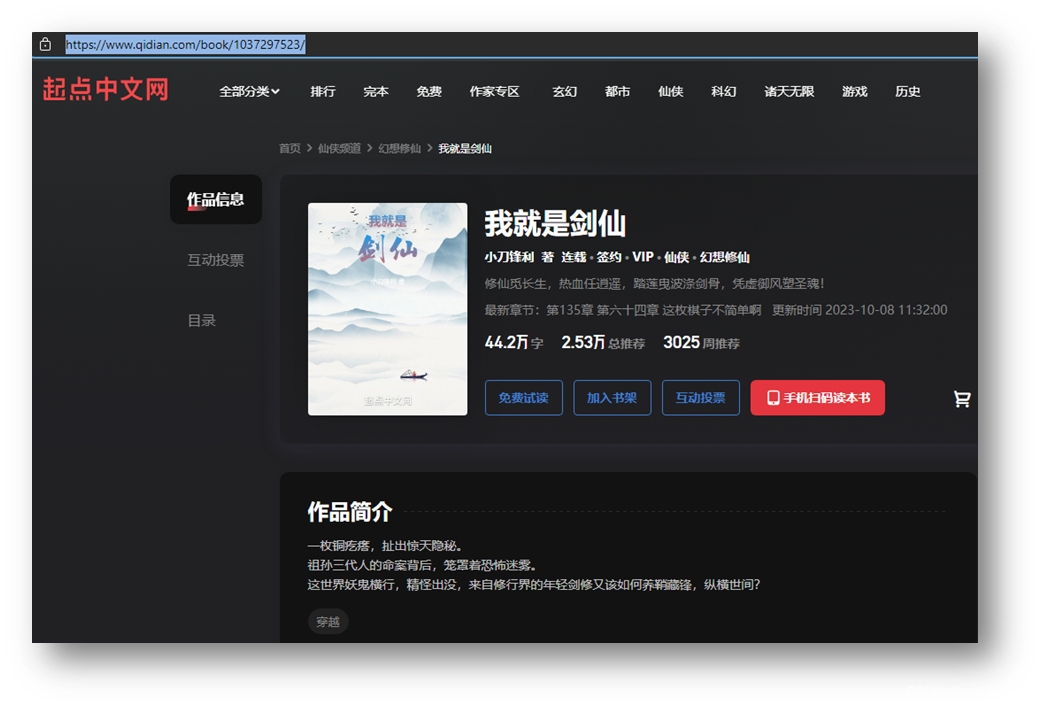
2.选择一篇小说(https://www.qidian.com/book/1037297523/)
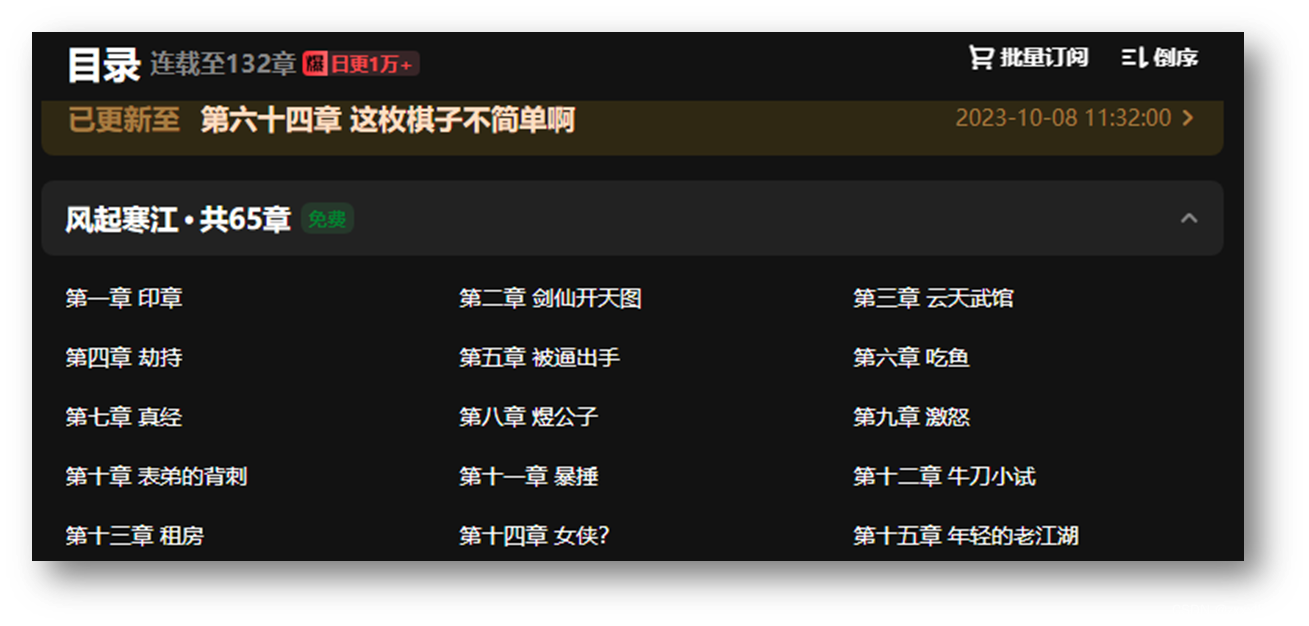
3.查看小说的卷章和每章对应的章节
4.Chrome浏览器,使用F12,打开开发者模式,查看章节对应代码细节
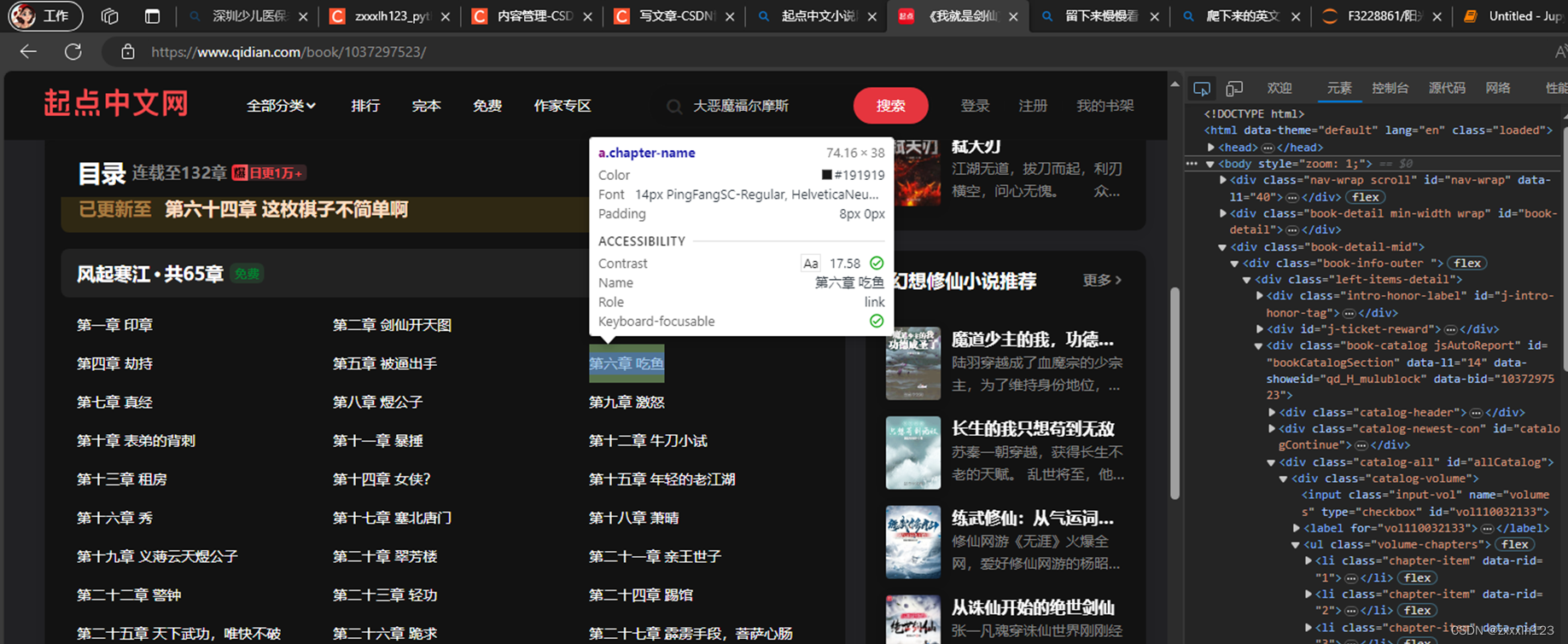
5.查看卷章结构,并创建文件夹
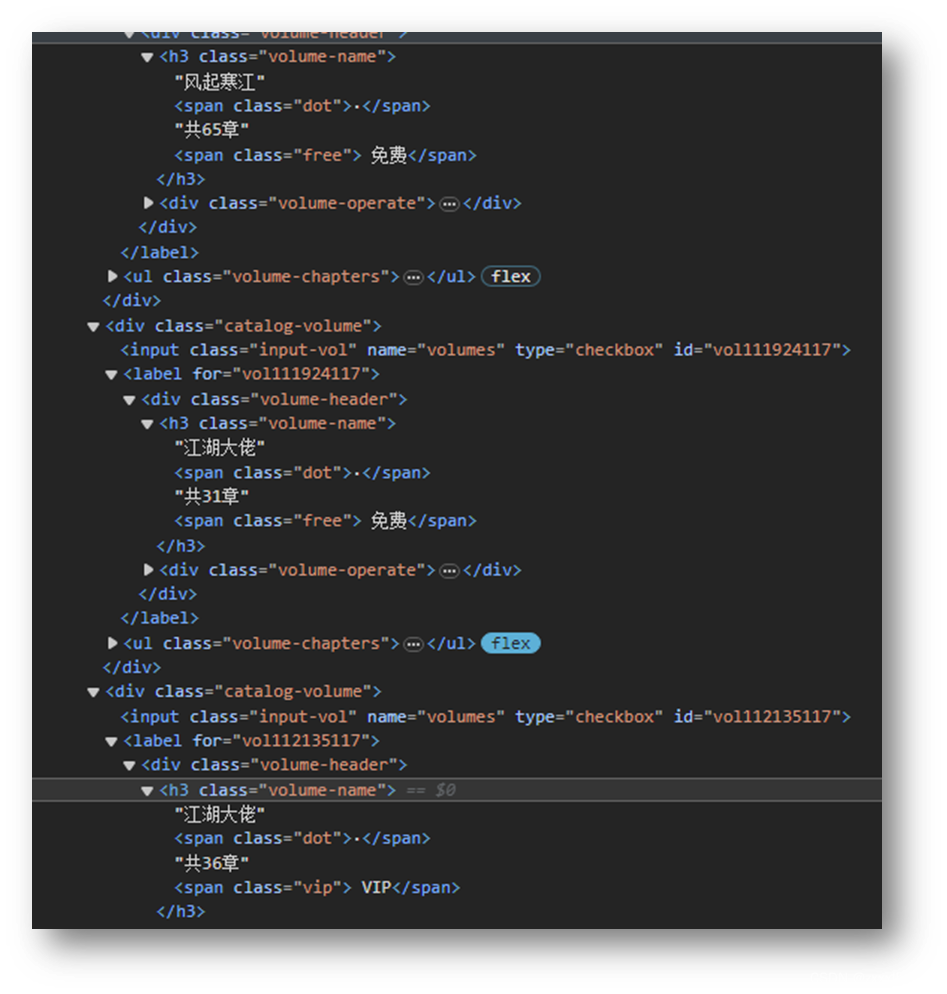
#卷章结构
volums_names = [a.text.strip() for a in soup.find_all('h3', class_='volume-name')]
#创建文件夹存卷章
def create_folders(base_path, folder_names):
for folder_name in folder_names:
try:
# 使用os.makedirs()创建文件夹,如果它不存在
older_path = os.path.join(base_path, folder_name)
os.makedirs(folder_name)
print("文件夹 {}'创建成功!".format(folder_name))
except OSError as e:
print("创建文件夹 {}失败!!!".format(folder_name))

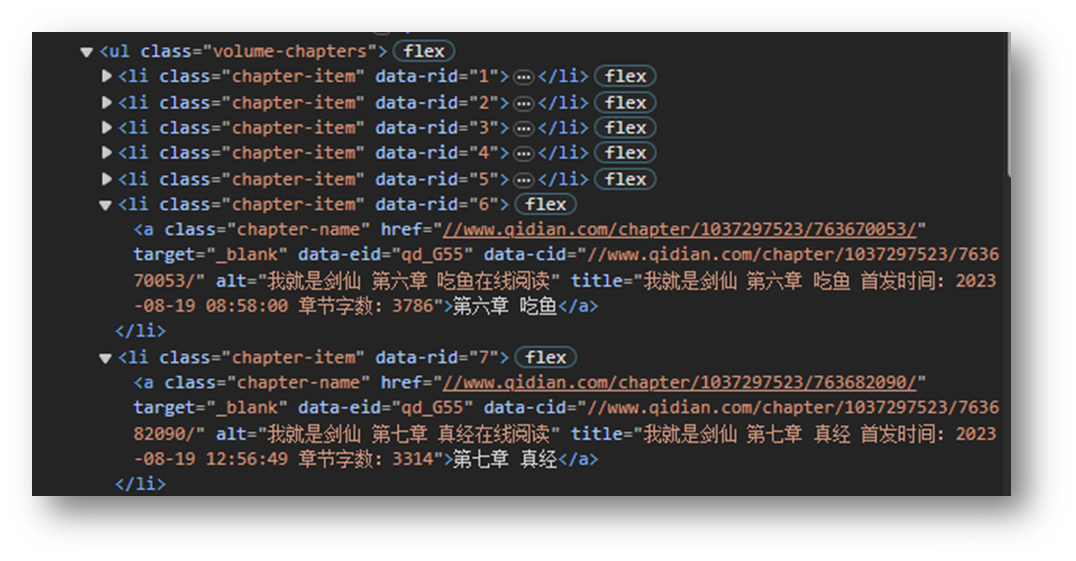
6.章节结构
chapter_names = [a.text.strip() for a in soup.find_all('a', class_='chapter-name')]

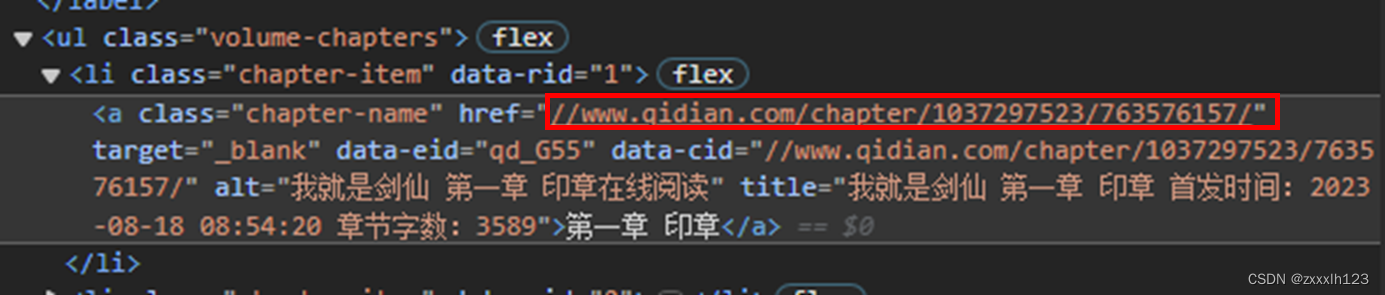
7.章节内容所在页面URL,缺少https:
data_cids = [a['data-cid'] for a in soup.find_all('a', class_='chapter-name')]
8.提取章节内容
def getchacontents(chapter_id,headers):
response = requests.get('https:' + chapter_id, headers = headers)
pattern = r'<p>(.*?)</p>'
matches = re.findall(pattern, response.text, re.DOTALL)
result = '\n'.join(matches)# 使用换行符拼接文本
return result
9.获取章节内容写入txt文件,并将文件存入对应的卷章文件夹
#将章节内容写入文件,存入对应的文件夹
def save2file(filepath, filename , content):
filename = filename.replace(“/”,“-”)#文件名称不可出现-
try:
if not os.path.exists(filepath):
os.makedirs(filepath)
#文件存储地址
file_path = os.path.join(filepath, filename + '.txt')
#爬取内容写入文件
with open(file_path,'a',encoding ='utf-8') as f:
f.write(content +'\n')
f.close()
print('{}写入成功'.format(filename))
except Exception as e:
print('{}写入失败!!!'.format(filename))

10.整体代码
import requests
import json
import os
import re
from bs4 import BeautifulSoup
import random
#提取章节内容
def getchacontents(chapter_id,headers):
response = requests.get('https:' + chapter_id, headers = headers)
pattern = r'<p>(.*?)</p>'
matches = re.findall(pattern, response.text, re.DOTALL)
result = '\n'.join(matches)# 使用换行符拼接文本
return result
#创建文件夹存卷章
def create_folders(base_path, folder_names):
for folder_name in folder_names:
try:
# 使用os.makedirs()创建文件夹,如果它不存在
older_path = os.path.join(base_path, folder_name)
os.makedirs(folder_name)
print("文件夹 {}'创建成功!".format(folder_name))
except OSError as e:
print("创建文件夹 {}失败!!!".format(folder_name))
#将章节内容写入文件,存入对应的文件夹
def save2file(filepath, filename , content):
filename = filename.replace("/","-")
try:
if not os.path.exists(filepath):
os.makedirs(filepath)
#user_home = os.path.expanduser("~")
file_path = os.path.join(filepath, filename + '.txt')
#file_path = os.path.join(filepath,filename +'.txt')
with open(file_path,'a',encoding ='utf-8') as f:
f.write(content +'\n')
f.close()
print('{}写入成功'.format(filename))
except Exception as e:
print('{}写入失败!!!'.format(filename))
#防止被禁,随机返回list_中某个User_Agent设置值
def get_User_Agent():
list_ = ['Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36',\
'Mozilla/5.0 (Windows NT 10.0;Win64;x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36',\
'Mozilla/5.0 (Windows NT 6.3;Win64;x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',\
'Mozilla/5.0 (Windows NT 6.2;Win64;x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',\
'Mozilla/5.0 (Windows NT 6.1;Win64;x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',\
'Mozilla/5.0 (Windows NT 6.3;WOW64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/401.0.2225.0 Safari/537.36',\
'Mozilla/5.0 (Windows NT 6.2;WOW64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/401.0.2225.0 Safari/537.36',\
'Mozilla/5.0 (Windows NT 6.1;WOW64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/401.0.2225.0 Safari/537.36']
return list_[random.randint(0,len(list_)-1]
def main():
headers = {'User-Agent':get_User_Agent()}
response = requests.get('https://www.qidian.com/book/1037297523/',headers = headers)
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有章节名称和章节对应网页
volums_names = [a.text.strip() for a in soup.find_all('h3', class_='volume-name')]
chapter_names = [a.text.strip() for a in soup.find_all('a', class_='chapter-name')]
data_cids = [a['data-cid'] for a in soup.find_all('a', class_='chapter-name')]
# 指定要创建文件夹的基本路径
base_path = '/Users/xinxin/Desktop'
create_folders(base_path ,volums_names)
i = 0; j = 0;m = 0
for chapter_name in chapter_names:
result = getchacontents(data_cids[chapter_names.index(chapter_name)], headers)
save2file(base_path + '/' +volums_names[j] , chapter_name, result)
i += 1;m += 1
print(' -----写入{}已完成{}/{}----'.format(volums_names[j],m,volums_names[j][6:8]))
if i == volums_names[0][6:8]:
j += 1;m = 0
elif i == volums_names[0][6:8] + volums_names[0][6:8]:
j += 1;m =1
print("小说爬取完毕")
if __name__=='__main__':
main()




![2023年中国家用智能微投市场销售概况分析:家用智能微投销量为727万台,销售额为131亿元[图]](https://img-blog.csdnimg.cn/img_convert/786693cf959d930901b4ebf91d8bd87a.png)