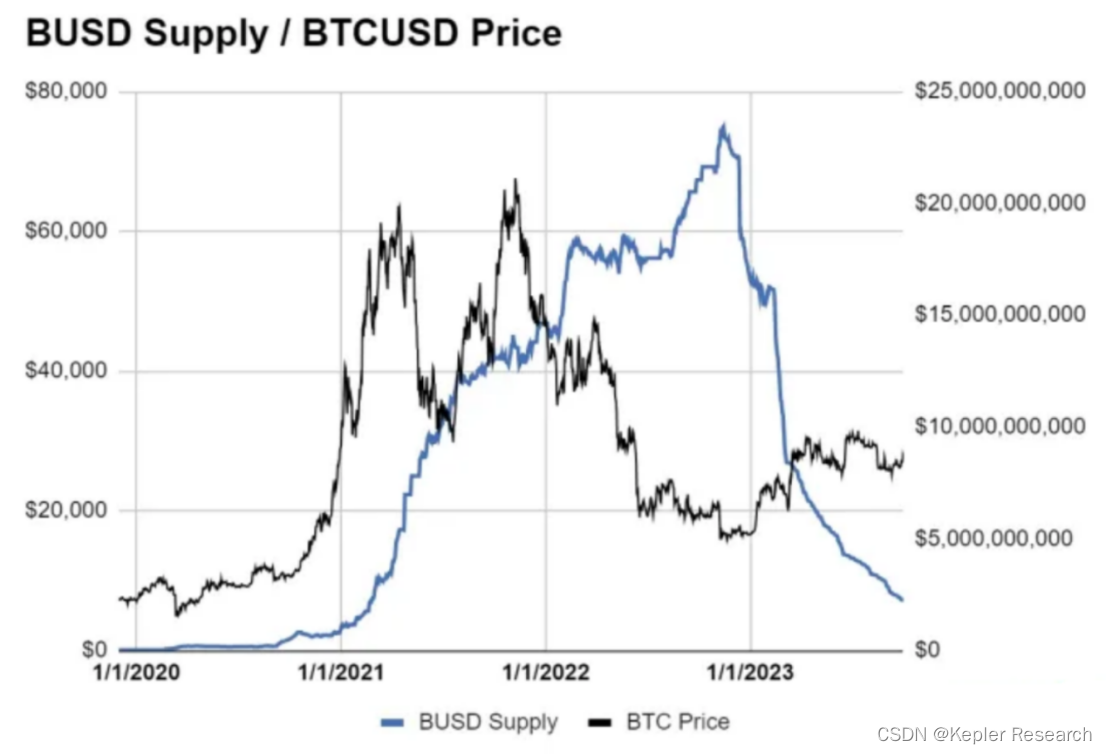
xi 优于 xj ==> 则称 xi 非支配于 xj
一、NSGA
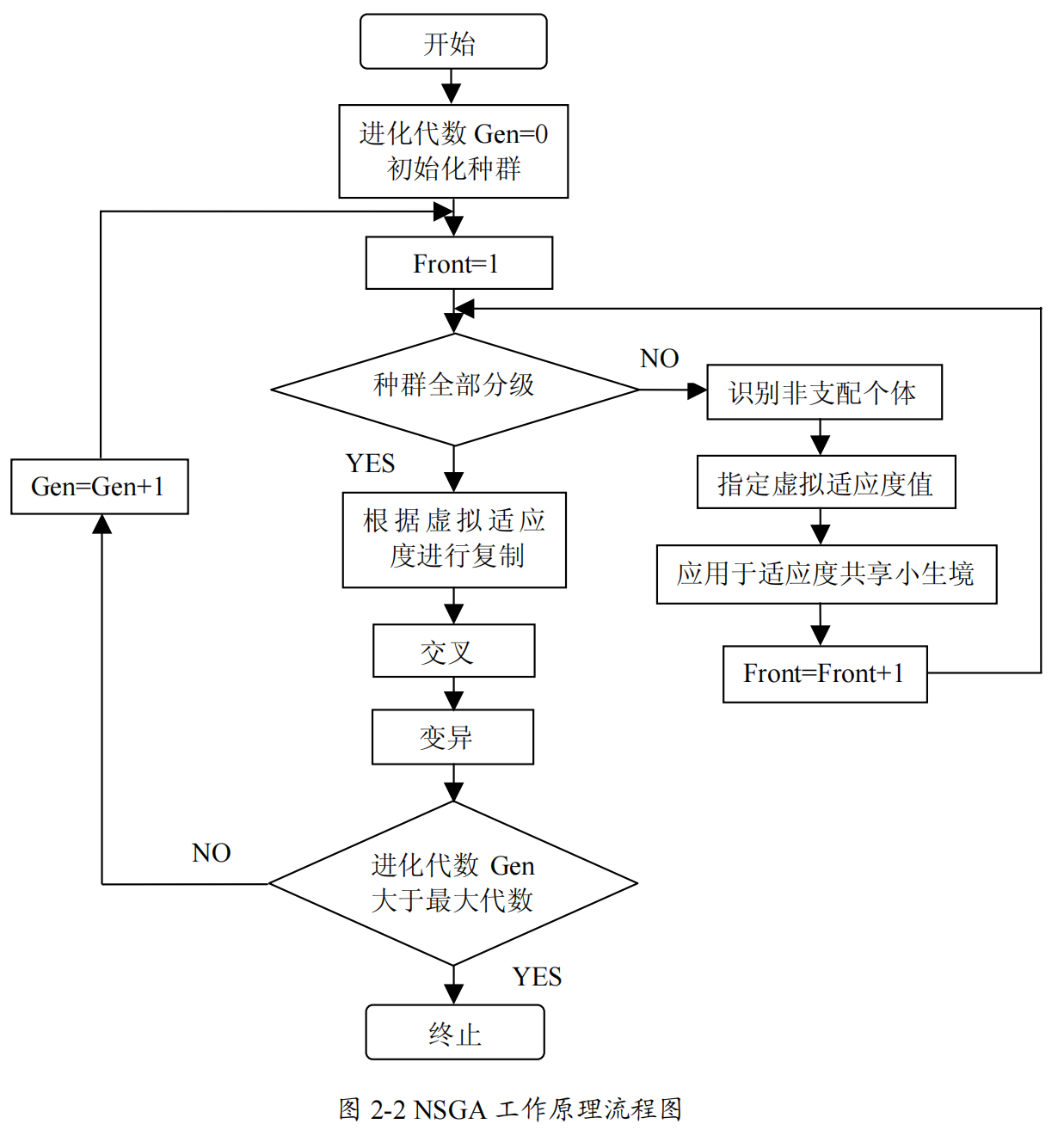
1、识别非支配个体(使用非支配排序算法) -> 从而将种群分为多层
通过非支配排序算法对这个规模为
n
的种群进行分层的具体步骤如下:
(
1
)设
i
=
1
;
(
2
)对于所有的
j =1,2, ,n "
且
j
≠
i
,按照以上定义比较个体
x
i
和个体
x
j 之间的支配与非支配关系;
(
3
)如果不存在任何一个个体
x
j
优于
x
i
,则
x
i
标记为非支配个体;
(
4
)令
i
= i +
1
,转到步骤
(2)
,直到找到所有的非支配个体。
通过上述步骤得到的非支配个体集是种群的第一级非支配层,然后,忽略这些已经标记的非支配个体
(
即这些个体不再进行下一轮比较
)
,再遵循步骤
(1)-(4),就会得到第二级非支配层。依此类推,直到整个种群被分层。
2、指定虚拟适应度值
种群分层结束后,需要给每级指定一个虚拟适应度值,级别越小,说明其中的个体越优,赋予越高的虚拟适应值,反之级别越大,赋予越低的虚拟适应值。这样可以保证在复制操作中级别越小的非支配个体有更多的机会被选择进入下一代,使得算法以最快的速度收敛于最优区域。比如第一级非支配层的个体标上虚拟适应值为 1,第二级非支配层的个体标上虚拟适应值为 0.9(或其他),以此类推,直到所有的个体都被标上虚拟适应值。
3、应用于适应度共享的小生境 -> 保证最优解集具有多样性
但是由于同一级非支配层中的个体拥有相同的适应度值,某些个体在遗传操作中可能被遗弃,导致最优解集不具有多样性,为了得到分布均匀的 Pareto 最优解集,就要保证当前非支配层上的个体具有多样性。NSGA 中引入了基于拥挤策略的共享小生境(Niche)技术(使非支配层的每个个体都拥有各自不同的适应度值),对同一级上原先指定的虚拟适应度值进行重新指定。
二、NSGA-Ⅱ
NSGA的缺点
NSGA 通过非支配排序算法保留了优良的个体,并且利用适应度共享函数的方法保 持了群体的多样性,效果非常好。但是实际应用中发现
NSGA
还是存在着明显的不足,
这主要体现在如下三个方面:
(
1
)非支配排序的
高计算复杂性
。非支配排序遗传算法一般要进行
mN
3
次搜索
(
m
是目标数量,
N
是种群大小
)
,搜索次数随着目标数量和种群大小的增大而增多。
(
2
)
缺少精英策略
。近年来的研究结果
[45,46]
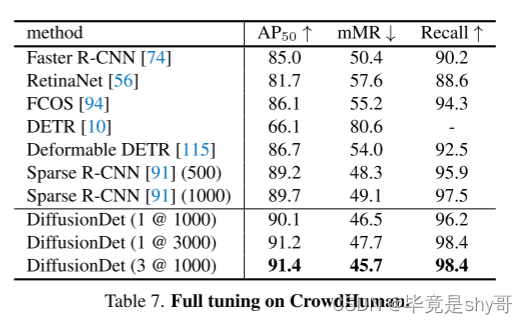
表明,精英策略可以加快 GA 的执行, 还有助于防止好的解丢失。
(
3
)
需要指定特殊的共享参数σshare
,
NSGA 的保持种群和解的多样性的策略都是依赖于共享的概念,共享的主要问题就是需要有一个共享参数
σ
share。正是由于要对共享参数作额外的工作,所以就需要一种不依赖共享参数的方法。
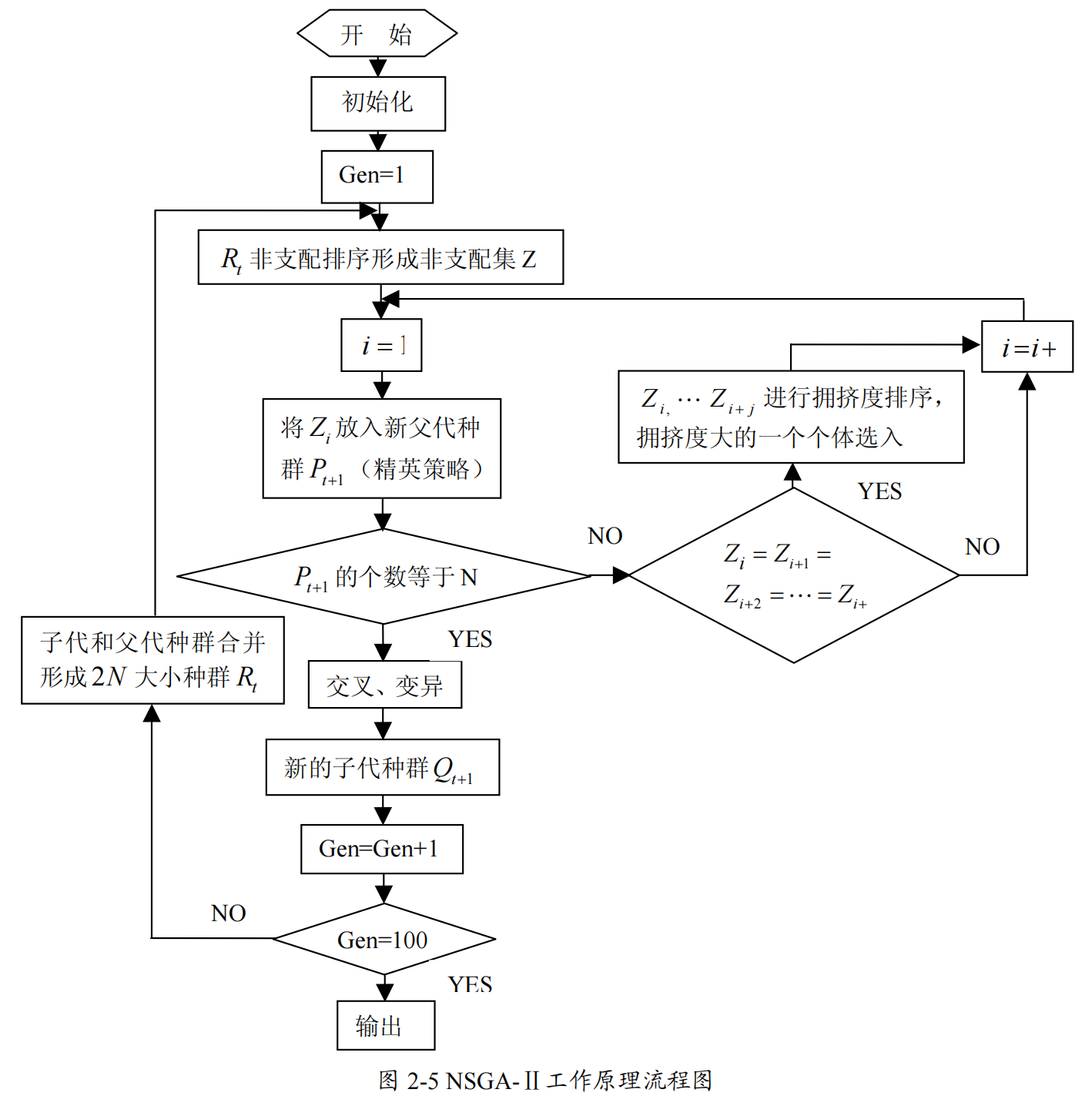
NSGA-II 对NSGA 进行改进
NSGA-II
算法针对
NSGA
的缺陷通过以下三个方面进行了改进
:
(
1)提出了快速非支配排序算法,降低了计算的复杂度,使得算法的复杂度由原来的
mN
3
降到
mN
2
(
m
为目标函数个数,
N
为种群大小
)
。
(2)引入精英策略,扩大采样空间。将父代种群与其产生的子代种群组合,共同竞争产生下一代种群,有利于保持父代中的优良个体进入下一代,保证某些优良的种群个体在进化过程中不会被丢弃,从而提高了优化结果的精度。并通过对种群中所有个体的分层存放,使得最佳个体不会丢失,迅速提高种群水平。
(
3
)采用拥挤度和拥挤度比较算子,不但克服了
NSGA 中需要人为指定共享参数的缺陷,而且将其作为种群中个体间的比较标准,使得准
Pareto 域中的个体能均匀地扩展到整个
Pareto 域,保证了种群的多样性。
方法:
1、快速非支配排序 -> 增加排序速度
2、拥挤度比较算子 -> 解决共享小生境技术中需要人为指定共享半径σshare的问题
3、精英策略 -> 防止优秀个体的流失
待看视频:
纯小白超详细的非支配排序遗传算法原理讲解_哔哩哔哩_bilibili
待读文章:
进化计算(四)——NSGA/NSGA II算法详解_nsga 求解单目标_南木长的博客-CSDN博客
进化计算(五)——NSGA-II论文阅读笔记(二)_实数编码的遗传算法中 多项式变异分布参数_南木长的博客-CSDN博客
多目标遗传算法NSGA-CSDN博客
NSGA-II:快速精英多目标遗传算法(论文+代码解读)_nsgaii算法代码_bujbujbiu的博客-CSDN博客
多目标优化算法评价指标(performance metrics)_bujbujbiu的博客-CSDN博客