本文仅给出最基础的baseline进行图像分类训练,后续可在此代码基础上对模型结构进行修改。
一、图像分类数据集
现有一份图像类别数据集,类别为Y和N,数据目录如下:
/datasets/data/
|-- train/
| |-- Y/
| |-- N/
划分训练集和测试集
split_dataset.py
import os
import random
import shutil
import argparse
# 创建命令行参数解析器
parser = argparse.ArgumentParser(description='移动验证集样本到验证集文件夹')
parser.add_argument('--name', required=True, help='数据集名称')
parser.add_argument('--val_ratio', type=float, default=0.2, help='验证集比例')
args = parser.parse_args()
# 数据集路径
dataset_name = args.name
dataset_path = f'/datasets/{dataset_name}'
train_path = os.path.join(dataset_path, 'train')
val_path = os.path.join(dataset_path, 'val')
# 创建验证集文件夹
os.makedirs(val_path, exist_ok=True)
os.makedirs(os.path.join(val_path, 'Y'), exist_ok=True)
os.makedirs(os.path.join(val_path, 'N'), exist_ok=True)
# 计算验证集的数量
val_ratio = args.val_ratio # 验证集比例
val_size_Y = int(len(os.listdir(os.path.join(train_path, 'Y'))) * val_ratio)
val_size_N = int(len(os.listdir(os.path.join(train_path, 'N'))) * val_ratio)
# 随机选择验证集样本
random.seed(42)
val_samples_Y = random.sample(os.listdir(os.path.join(train_path, 'Y')), val_size_Y)
val_samples_N = random.sample(os.listdir(os.path.join(train_path, 'N')), val_size_N)
# 将验证集样本移动到验证集文件夹
for sample in val_samples_Y:
src_path = os.path.join(train_path, 'Y', sample)
dst_path = os.path.join(val_path, 'Y', sample)
shutil.move(src_path, dst_path)
for sample in val_samples_N:
src_path = os.path.join(train_path, 'N', sample)
dst_path = os.path.join(val_path, 'N', sample)
shutil.move(src_path, dst_path)
调用方式:
# 按9:1划分训练集和验证集,并整理好数据目录
python split_dataset.py --name data --val_ratio 0.1
切分后的样式
/datasets/data/
|-- train/
| |-- Y/
| |-- N/
|-- val/
| |-- Y/
| |-- N/
二、模型构建
调用Resnet模型
class ClassifyModel(nn.Module):
def __init__(self, num_classes):
super(ClassifyModel, self).__init__()
# Load the pre-trained ResNet model
self.model = models.resnet50(pretrained=True)
num_features = self.model.fc.in_features
self.model.fc = nn.Linear(num_features, num_classes) # Replace the final fully connected layer
def forward(self, x):
return self.model(x)
三、模型训练
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, models, transforms
# Set device
device = torch.device('cuda')
# Define data transformations
data_transforms = {
'train': transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(), # Randomly flip images horizontally for data augmentation
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]),
}
# Set the path to the train directory
data_dir = './data/train'
# Create train dataset
train_data = datasets.ImageFolder(data_dir, transform=data_transforms['train'])
# Set the batch size and create a data loader
batch_size = 16
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True, num_workers=8)
# Load the pre-trained model
model = ClassifyModel(num_classes=2).to(device) # Instantiate the model
model.train() # Set the model to training mode
# Define the loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# Training loop
num_epochs = 10
for epoch in range(num_epochs):
model.train() # Set the model to training mode
running_loss = 0.0
for images, labels in train_loader:
images = images.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# Print training progress
train_loss = running_loss / len(train_loader)
print(f"Epoch [{epoch+1}/{num_epochs}], Train Loss: {train_loss:.4f}")
# Save the trained model
torch.save(model.state_dict(), './model/Resnet-ClassifyModel.pth')
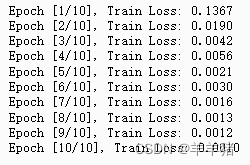
训练结果展示如下:
四、模型验证
# Set device
device = torch.device('cuda')
# Define data transformations
data_transforms = {
'val': transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
}
# Set the path to the validation directory
val_dir = './data/val'
# Create validation dataset
val_data = datasets.ImageFolder(val_dir, transform=data_transforms['val'])
# Set the batch size and create a data loader
batch_size = 16
val_loader = DataLoader(val_data, batch_size=batch_size, shuffle=False, num_workers=0)
# Load the pre-trained ResNet model
model = ClassifyModel(num_classes=2)
model = model.to(device)
# Load the trained model
model.load_state_dict(torch.load('./model/Resnet-ClassifyModel.pth'))
model.eval() # Set the model to evaluation mode
# Define class names
class_names = val_data.classes
# Validation loop
correct_predictions = 0
total_images = 0
true_positives = 0
false_negatives = 0
with torch.no_grad():
# Iterate through the validation images
for images, labels in val_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
# Process each image in the batch
for i in range(images.size(0)):
image_path = val_data.imgs[total_images + i][0]
predicted_label = predicted[i].item()
true_label = labels[i].item()
# Calculate accuracy and recall
if predicted_label == true_label:
correct_predictions += 1
if true_label == class_names.index('Y'):
true_positives += 1
elif true_label == class_names.index('Y'):
false_negatives += 1
# Print the predicted label with the complete image path
print(f"Image: {image_path}, Predicted Label: {class_names[predicted_label]}")
total_images += images.size(0)
# Calculate accuracy and recall
accuracy = correct_predictions / total_images
recall = true_positives / (true_positives + false_negatives)
# Print accuracy and recall
print(f"Accuracy: {accuracy:.4f}")
print(f"Recall: {recall:.4f}")
验证结果展示: