目录
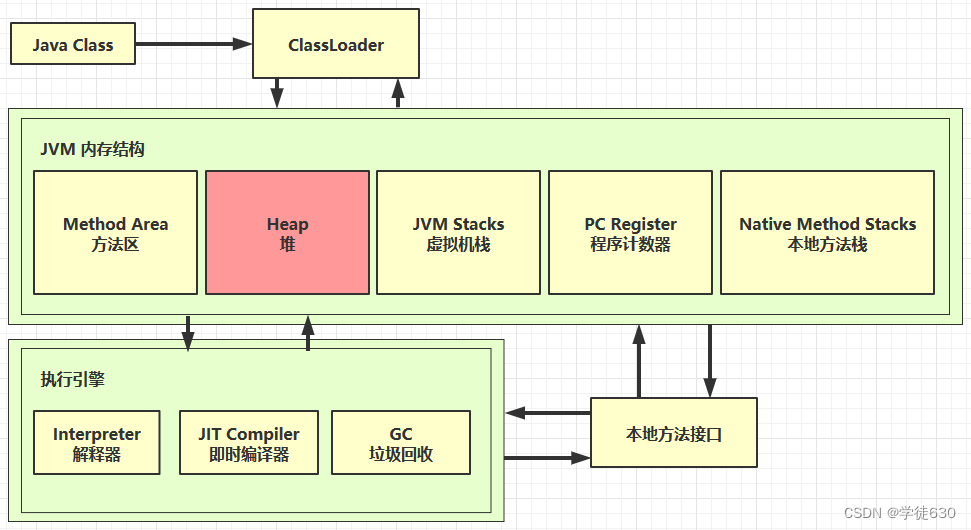
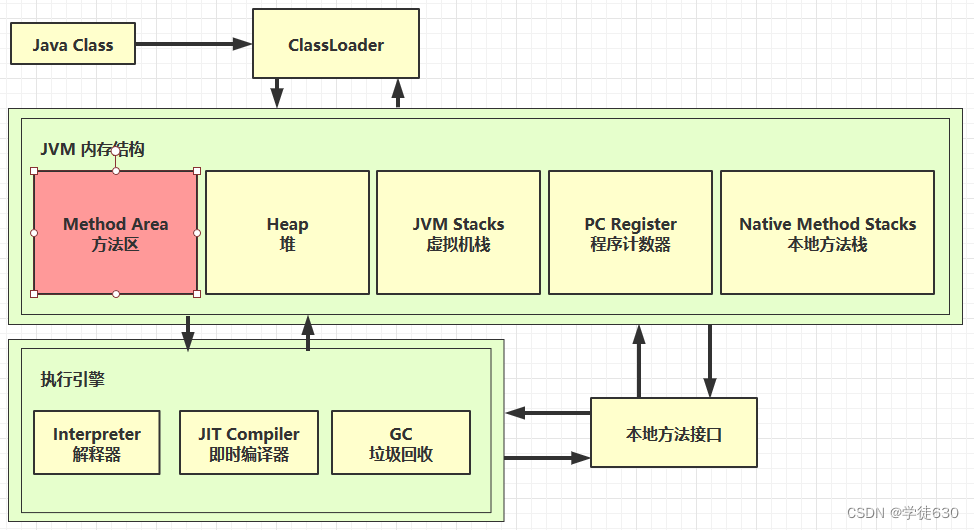
内存结构
程序计数器
概述:
为什么私有化?
性能优化
安全性高
成本较低
为什么程序计数器不会存在内存溢出?
虚拟机栈
概述:
问题辨析:
垃圾回收是否涉及栈内存?
栈内存分配越大越好吗?
方法内的局部变量是否线程安全?
栈内存溢出
多级递归:
栈帧过大:
第三方类库操作
解决和避免Java中的栈内存溢出问题
线程运行诊断
cpu 占用过多
程序运行很长时间没有结果(死锁)
方案一:
方案二:
本地方法栈
概述:
堆
概述
主要特点
堆内存溢出
堆内存诊断
JPS工具
jmap工具
jconsole工具
可视化的工具jvisualvm工具
方法区
概述:
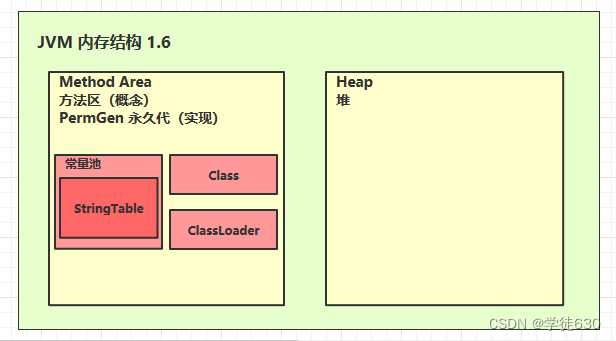
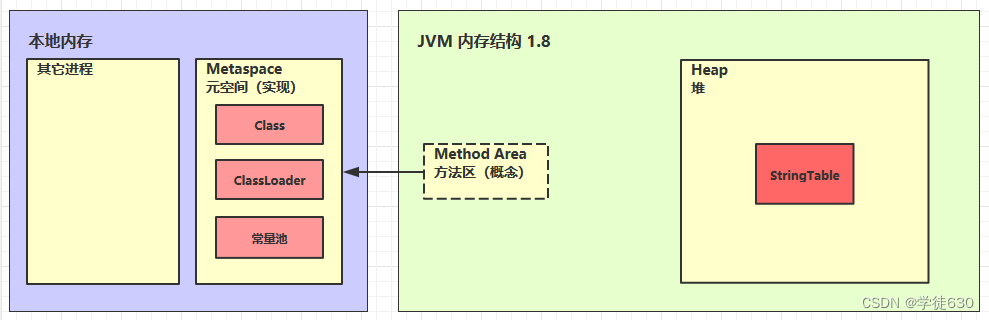
JDK1.6和JDK1.8后的方法区变化
JDK 1.6中的方法区实现:
JDK 1.8后的方法区实现:
元空间与永久代的区别:
运行时常量池
StringTable
面试笔试:
StringTable 的位置
StringTable 性能调优
调整 StringTable 大小
减少字符串的 intern() 调用
使用 StringBuilder 或 StringBuffer
使用字符串常量或字面量:
注意字符串引用的作用域:
注意字符串拼接的方式:
直接内存
概述:
特点:
分配方式:
效率:
内存使用:
垃圾回收:
内存溢出:
为什么直接内存的io比堆内存的io快?
直接内存回收原理
内存结构
程序计数器
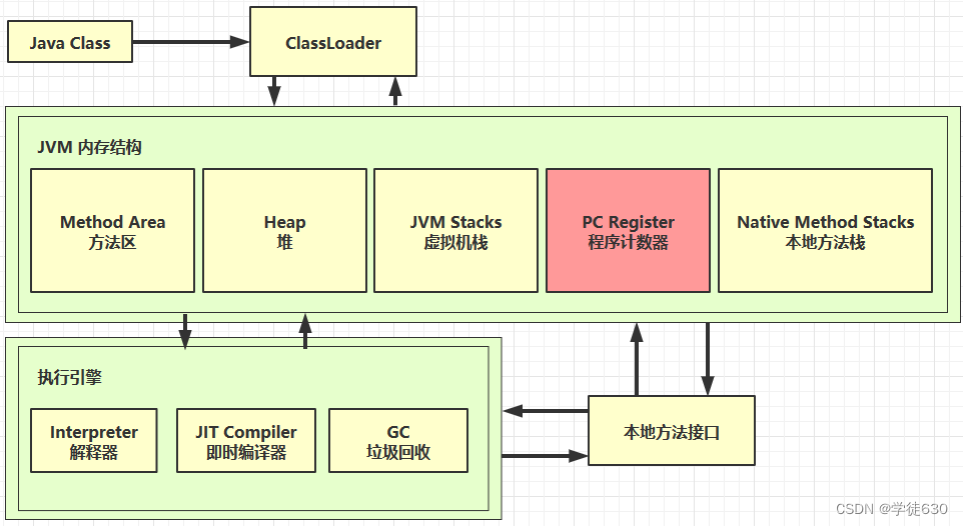
概述:
Java程序计数器是Java虚拟机中的一项非常重要的内部数据结构,用于记录每个线程当前执行的字节码指令地址。它是虚拟机实现多线程支持的关键之一,也是极其频繁使用的内存区域。
为了保证程序计数器的正确性和高效性,Java虚拟机为每个线程分配了一个私有的程序计数器。这意味着,在同一进程中运行的不同线程之间,程序计数器是相互独立的、隔离的。 在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
需要注意的是,如果执行的是 native 方法,那么程序计数器记录的是 undefined 地址,只有执行的是 Java 代码时程序计数器记录的才是下一条指令的地址。
具体来说,当一个线程开始执行一个方法时,它的程序计数器被设置为该方法的第一条指令的地址,然后根据这个地址继续执行代码序列。由于每个线程都有自己独立的程序计数器,因此它们之间可以并发执行而不会出现冲突。
为什么私有化?
将程序计数器设计为私有的还可以优化Java虚拟机的执行效率。在多线程环境下,如果程序计数器被设计成共享的,所有线程都需要对它进行竞争和同步,这将导致相当大的开销和延迟。因此,将程序计数器设计成私有的,使得每个线程都能够快速高效地访问和更新自己的程序计数器数据,从而提高整个系统的处理能力和并发性能。
由于多个线程可以并发运行,如果它们共享同一个程序计数器,在切换执行时就需要进行同步,否则可能会出现竞态条件等问题,导致程序出错或者崩溃。因此,为了避免这种情况的发生,Java虚拟机采用了将程序计数器设计为私有的方法,确保每个线程都拥有自己独立的程序计数器,从而避免了线程间的竞争和同步问题。
程序计数器还有一个特点,它所占用的内存空间比较小,通常只需要几个字节,这使得每个线程都可以很容易地创建和维护自己的程序计数器,并且不会对JVM的整体内存占用产生过大的负担。同时,由于程序计数器属于线程独立的状态信息,对它的读写操作也相对简单,能够快速高效地更新和使用。
0: getstatic #20 // PrintStream out = System.out;
3: astore_1 // --
4: aload_1 // out.println(1);
5: iconst_1 // --
6: invokevirtual #26 // --
9: aload_1 // out.println(2);
10: iconst_2 // --
11: invokevirtual #26 // --
14: aload_1 // out.println(3);
15: iconst_3 // --
16: invokevirtual #26 // --
19: aload_1 // out.println(4);
20: iconst_4 // --
21: invokevirtual #26 // --
24: aload_1 // out.println(5);
25: iconst_5 // --
26: invokevirtual #26 // --
29: return
为什么程序计数器不会存在内存溢出?
Java 的程序计数器用来存储当前执行的字节码指令的地址或索引。它不是用来存储程序数据的,而是和线程绑定的一块内存区域。
程序计数器的大小是固定的,一般是与操作系统的位数相关联,比如在 32 位系统上是 32 位,64 位系统上是 64 位。由于它只用来记录指令地址,因此它的范围有限,无法表示过大的数值。
因为程序计数器的范围是有限的,所以它不会发生内存溢出。当程序计数器达到最大值后,会循环回到最小值,继续执行指令。这种循环的性质保证了程序计数器的有效性,同时也使得 Java 虚拟机可以高效地切换线程执行。
需要注意的是,Java 中的内存溢出通常指的是堆内存溢出或栈溢出,这是由于程序运行过程中申请的堆内存或栈空间超出了其限制导致的。程序计数器并不存储堆内存或栈空间的数据,所以不会导致内存溢出的问题。
虚拟机栈
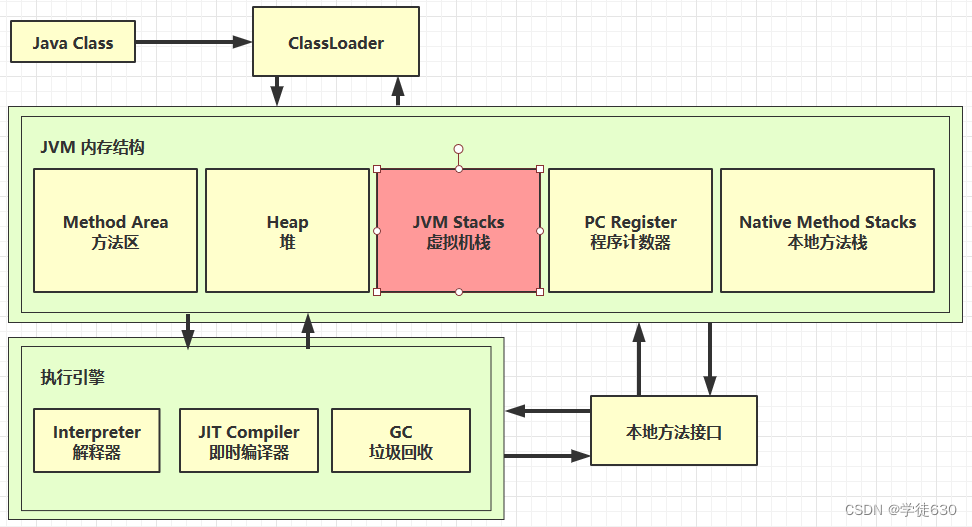
概述:

意思就是说,每个线程在创建启动后,虚拟机就会为其分配一个栈内存,这块栈内存被该线程执行的多个方法所切割调用,每个方法切割出去的内存叫做栈帧,对于一个线程来说,一个线程只能有一个活动的栈帧。
栈帧的空间只有在调用到该方法的时候才会创建,该方法执行后就会释放该栈帧的空间
注意:递归调用同一个方法会在内存中产生多个相同的栈帧

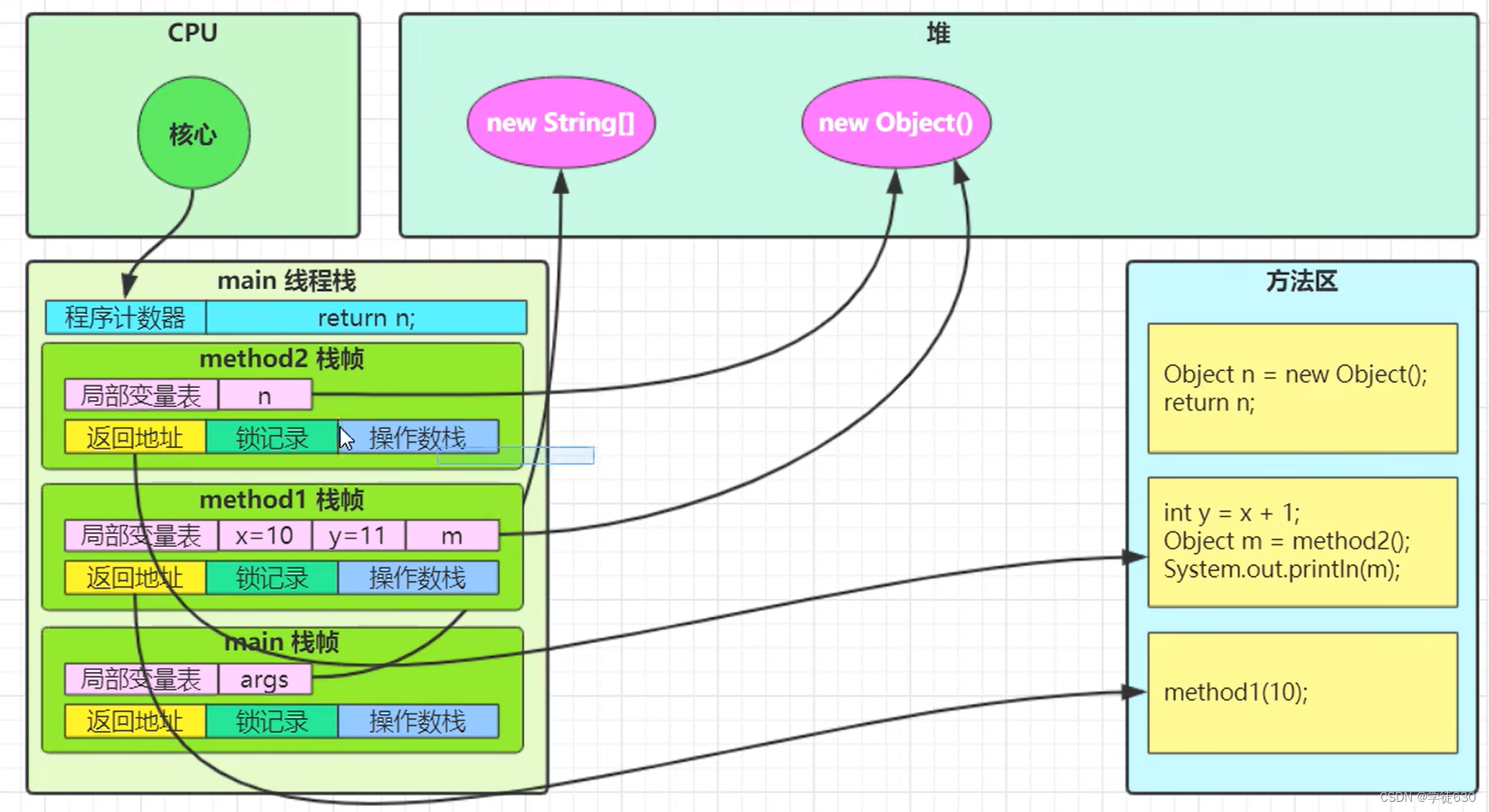
问题辨析:
垃圾回收是否涉及栈内存?
Java 的垃圾回收主要涉及到堆内存的管理,而与栈内存没有直接关系。
栈内存用于保存方法调用时的局部变量、方法参数、方法返回值以及方法调用的上下文信息。栈内存的分配和释放是由编译器自动进行的,因此它的生命周期非常短,随着方法的结束而自动释放。当一个方法调用结束时,它所占用的栈帧就会被弹出,对应的栈内存也会被回收。
栈内存分配越大越好吗?
不是。因为物理内存是一定的,栈内存越大,可以支持更多的递归调用,但是可执行的线程数就会越少。因为每个线程占用的内存空间多了,那么在一定的空间下,可支持的线程数就少了。
方法内的局部变量是否线程安全?
- 如果方法内部的变量没有逃离方法的作用访问,它是线程安全的。因为它此时对其他线程是隔离的。
- 如果是局部变量引用了对象,并逃离了方法的访问,那就要考虑线程安全问题。因为此时它对其他线程而已也许是共享的。
栈内存溢出
栈内存溢出(StackOverflowError)是指在程序执行过程中,栈内存的使用超过了其分配的容量限制,导致无法继续向栈内存中压入新的栈帧而引发的错误。
栈内存溢出(StackOverflowError)通常发生在以下情况:
多级递归:
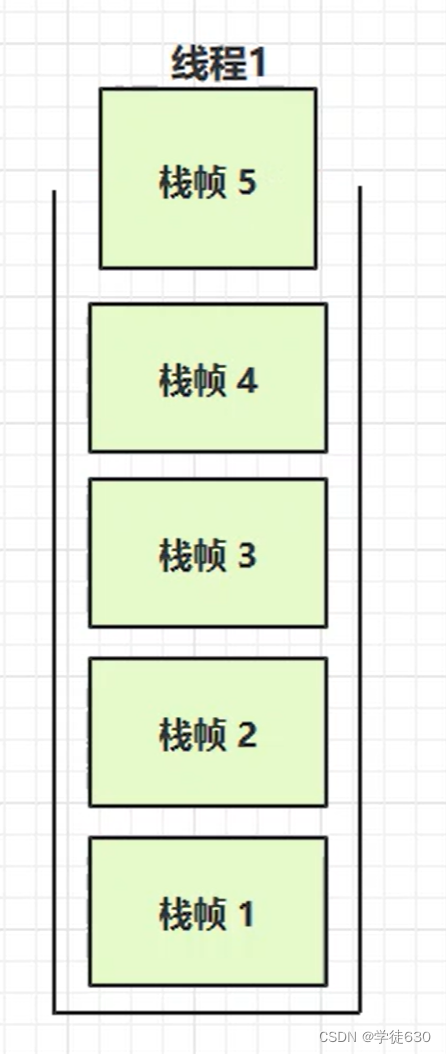
当一个方法不断地递归调用其他方法,并且没有合适的停止条件时,栈帧每个方法带来的栈帧逐渐累积消耗栈内存的空间,当栈空间用尽时就会导致栈内存溢出。
栈帧过大:
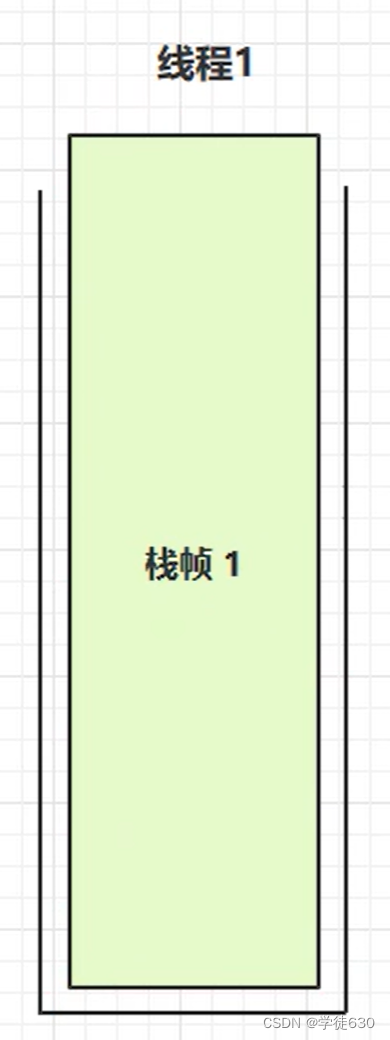
如果在一个方法中定义了大量的局部变量,尤其是占用内存较大的对象,这样每个方法调用都会在栈帧中分配一定的内存空间来存储局部变量,在方法调用过程中可能会导致栈内存溢出。其实就是说一个栈帧的空间直接占满了整个栈内存的情况
第三方类库操作
- 递归调用:第三方类库中的某些方法可能使用了递归算法,当递归调用没有合适的停止条件时,会导致无限递归调用,从而消耗栈内存的空间,并最终引发栈内存溢出。
方法调用层级过深:第三方类库可能存在复杂的方法调用结构,当方法调用的层级过深时,每个方法调用都会在栈上分配一个新的栈帧,如果栈内存空间不足以容纳这些栈帧,就会引发栈内存溢出。
大量的局部变量:第三方类库的方法可能定义了大量的局部变量,特别是占用内存较大的对象。当方法调用时,每个栈帧都需要为这些局部变量分配内存空间,如果局部变量过多,会消耗栈内存资源,进而导致栈内存溢出。
解决和避免Java中的栈内存溢出问题
可以考虑以下几个方法:
-
优化递归算法:确保递归调用有合适的停止条件,避免无限递归。递归算法可以分析并确定最终的递归结果,从而减少递归调用的层级。
-
减少方法调用层级:分析代码结构,减少方法调用的层级。可以尝试将复杂的方法拆分为多个简单的方法,减少方法调用层级。
-
减少局部变量和对象的使用:避免在方法中定义过多的局部变量和大对象,这样能减少栈内存消耗。可以考虑合理使用成员变量或静态变量。
-
增加栈内存大小:通过设置虚拟机参数
-Xss来增加栈内存的大小。例如:-Xss2m,将栈内存大小增加到2MB。需要注意的是,增加栈内存可能占用更多的系统资源,需要根据实际情况进行调整。 -
优化代码结构和内存使用:评估代码结构和内存使用情况,可能存在一些有待优化的部分。优化代码结构、减少不必要的资源占用有助于减少栈内存溢出的风险。
-
使用循环替代递归:在一些情况下,可以将递归调用转换为循环迭代的方式,从而减少方法调用层级和栈内存的使用
线程运行诊断
cpu 占用过多
采用top命令定位进程
登录服务器,执行top命令,查看CPU占用情况,找到进程的pid
<span style="color:#000000"><span style="background-color:#fafafa"><code class="language-shell"><span style="color:#dd4a68">top</span>
</code></span></span>
很容易发现,PID为29706的java进程的CPU飙升到700%多,且一直降不下来,很显然出现了问题。
top -Hp命令定位线程
使用 top -Hp <pid> 命令(为Java进程的id号)查看该Java进程内所有线程的资源占用情况
tip: 按shft+p按照cpu占用进行排序,按shift+m按照内存占用进行排序
<span style="color:#000000"><span style="background-color:#fafafa"><code class="language-shell"><span style="color:#dd4a68">top</span> -Hp <span style="color:#986801">29706</span>
</code></span></span>
不难发现,多个线程的CPU占用达到了90%多。我们挑选线程号为30309的线程继续分析
使用jstack命令定位代码
线程号转换为16进制
可以使用 printf “%x\n” 命令(tid指线程的id号)将以上10进制的线程号转换为16进制
<span style="color:#000000"><span style="background-color:#fafafa"><code class="language-shell"><span style="color:#50a14f">printf</span> <span style="color:#50a14f">"%x<span style="color:#a67f59">\n</span>"</span>
</code></span></span>
转换后的结果分别为7665,由于导出的线程快照中线程的nid是16进制的,而16进制以0x开头,所以对应的16进制的线程号nid为0x7665
采用jstack命令导出线程快照
通过使用jdk自带命令jstack获取该java进程的线程快照并输入到文件中
注意:open jdk不带该命令|没有注册环境变量的,需要对应的java目录执行jstack命令
<span style="color:#000000"><span style="background-color:#fafafa"><code class="language-shell"> jstack -l 进程ID <span style="color:#a67f59">></span> ./jstack_result.txt
</code></span></span>命令(为Java进程的id号)来获取线程快照结果并输入到指定文件
<span style="color:#000000"><span style="background-color:#fafafa"><code class="language-shell">jstack -l <span style="color:#986801">29706</span> <span style="color:#a67f59">></span> ./jstack_result.txt
</code></span></span>根据线程号定位具体代码
在jstack_result.txt 文件中根据线程好nid搜索对应的线程描述
<span style="color:#000000"><span style="background-color:#fafafa"><code class="language-shell"><span style="color:#dd4a68">cat</span> jstack_result.txt <span style="color:#a67f59">|</span><span style="color:#dd4a68">grep</span> -A <span style="color:#986801">100</span> <span style="color:#986801">7665</span>
</code></span></span>
如果说一个Java线程出现了内存溢出状态,也可以先通过 jps 找到该java病态线程的PID,然后通过 taskkill /F PID PID值 来杀死该线程
程序运行很长时间没有结果(死锁)
方案一:
先用jps查看所有的java进程id
jstack + 进程id定位死锁
从这里已经看出, 两个线程的状态都是BLOCKED,表示它们当前被阻塞等待某个对象的锁定。
"Thread-0"正在等待锁定资源2,因为它已经占用了资源1,而"Thread-1"正在等待锁定资源1,因为它已经占用了资源2。这就是死锁发生的情况。
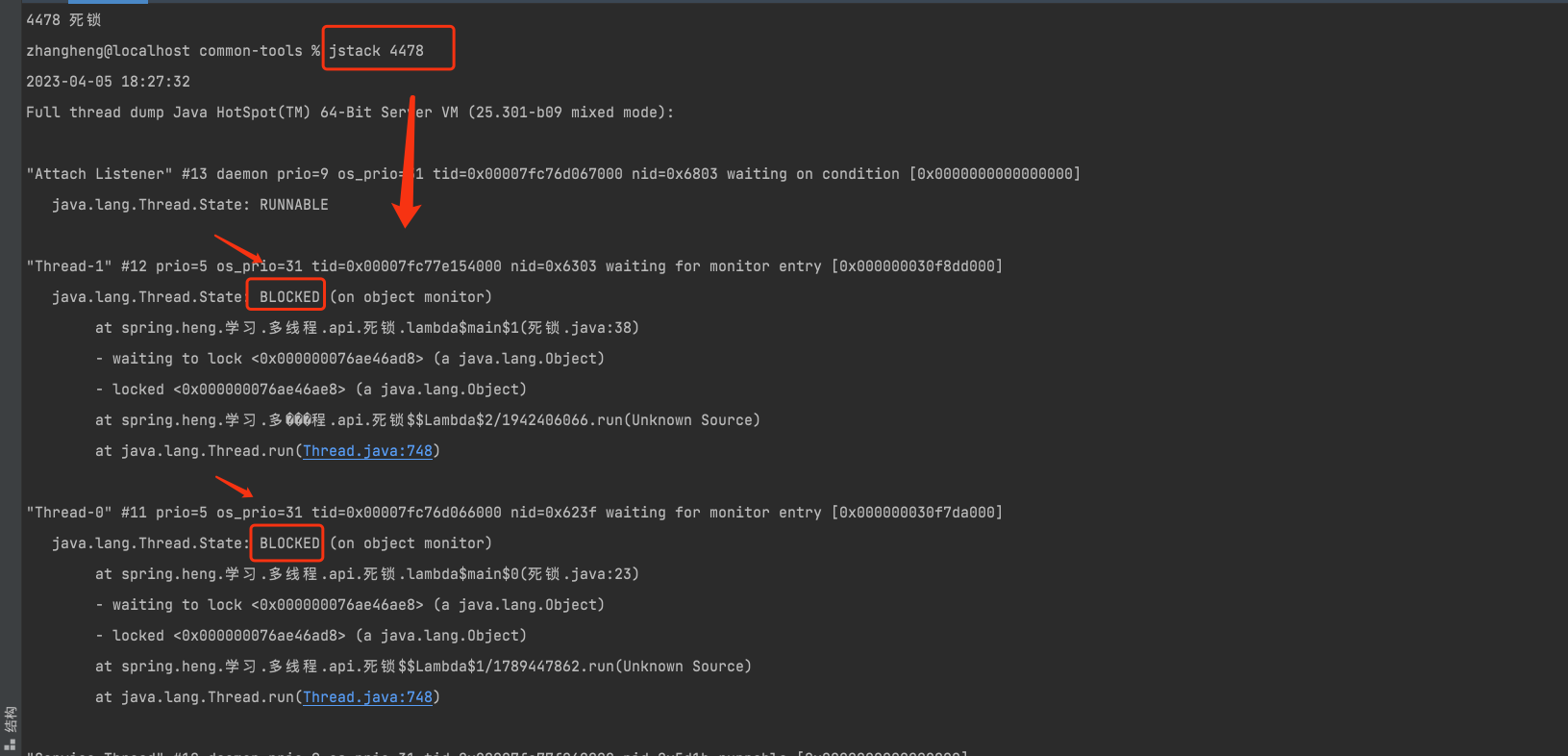
Found one Java-level deadlock的意思就是 发现一个Java级别的死锁
对应的线程分别为 Thread-1 和 Thread-0

并且在下方还会提示你代码中死锁的位置 (死锁.java:38)
方案二:
从jdk的安装路径中找到bin目录, 点击jconsole
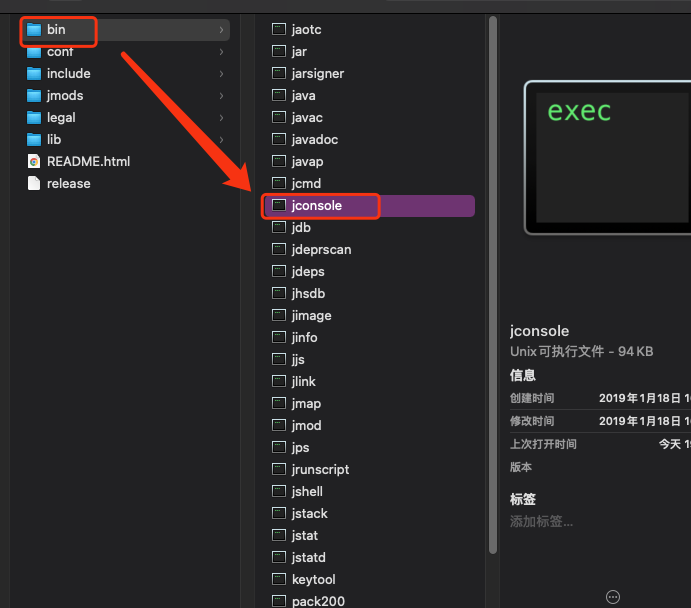
切换到线程, 点击检测死锁
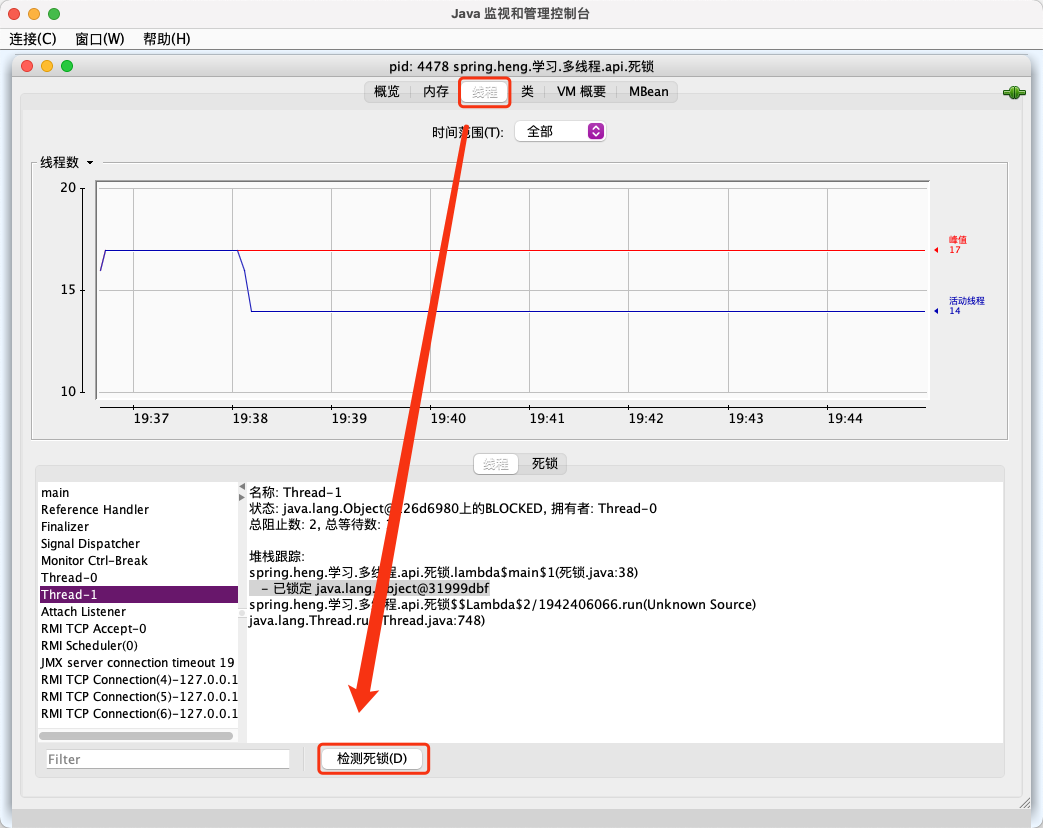
通过以上两种方法, 我们就能很轻松的定位死锁的信息~
本地方法栈

概述:
一些带有 native 关键字的方法就是需要 JAVA 去调用本地的C或者C++方法,因为 JAVA 有时候没法直接和操作系统底层交互,所以需要用到本地方法栈,服务于带 native 关键字的方法。
堆
概述
Java的堆(Heap)是一种用于动态分配对象的内存区域,主要用于存储Java程序中创建的对象实例。堆是Java虚拟机(JVM)管理的最大的一块内存区域,被所有线程共享。
主要特点
-
动态分配和释放:堆内存的分配和释放是动态进行的,Java程序可以在堆上创建和销毁对象实例,无需手动管理内存。JVM负责根据对象的生命周期自动分配内存和执行垃圾回收。
-
对象存储:堆内存主要用于存储Java程序中创建的对象,包括类实例、数组和字符串等。对象在堆上分配内存,以便能够动态地增长和缩小空间,满足程序的需要。
-
垃圾回收:堆内存是Java垃圾回收机制的主要工作区域。垃圾回收器负责定期检查堆内存中的对象,回收不再被引用的对象,并释放相应的内存空间。这种自动内存管理的机制大大简化了程序员对内存的管理工作。
堆内存溢出
java.lang.OutofMemoryError :java heap space. 堆内存溢出
当Java程序在堆内存中动态分配对象时,如果内存不够容纳新的对象,就会发生Java堆内存溢出。下面从多个角度深入讲解Java堆内存溢出的原因和解决方法:
-
堆内存大小限制:Java堆内存的大小通过启动JVM时的
-Xmx参数 进行设置。如果分配给堆内存的大小不足以满足程序运行时的对象需求,就会导致堆内存溢出。解决方法:增加堆内存大小,可以通过调整按需分配内存的最大值
-Xmx来扩大堆内存。例如,-Xmx2g可将堆内存大小设置为2GB。 -
内存泄漏:内存泄漏指的是程序中的对象无法被垃圾回收器识别为垃圾,从而无法释放掉。如果产生大量无法被回收的无用对象,则会导致堆内存被耗尽。
解决方法:审查代码,确认是否存在内存泄漏的情况。可以使用内存分析工具(如MAT、JProfiler等)来检测内存泄漏,并通过修复代码问题来解决。
-
对象过多:当程序中创建了过多的对象,并且这些对象都保持在堆内存中,会导致堆内存耗尽。
解决方法:优化代码,避免不必要的对象创建和持有。例如,及时释放不再使用的对象引用、使用对象池或缓存来控制对象的创建和销毁。
-
堆中数据过大:如果堆中单个对象或对象图的数据量过大,会耗尽堆内存。
解决方法:考虑将大对象进行分割、压缩或使用其他数据结构进行存储,以减少单个对象所占用的堆内存空间。
-
频繁的全局垃圾回收:堆内存中对象的垃圾回收是通过全局垃圾回收器进行的,如果频繁发生全局垃圾回收,会导致堆内存的使用速度远大于垃圾回收的速度,最终耗尽堆内存。
解决方法:优化垃圾回收策略,例如调整垃圾回收算法、调整垃圾回收器的配置参数等,以提高垃圾回收的效率。
堆内存诊断
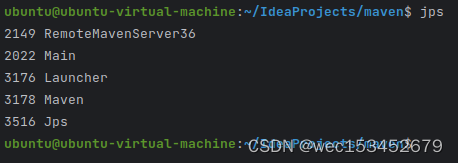
JPS工具
查看当前系统中有哪些java进程
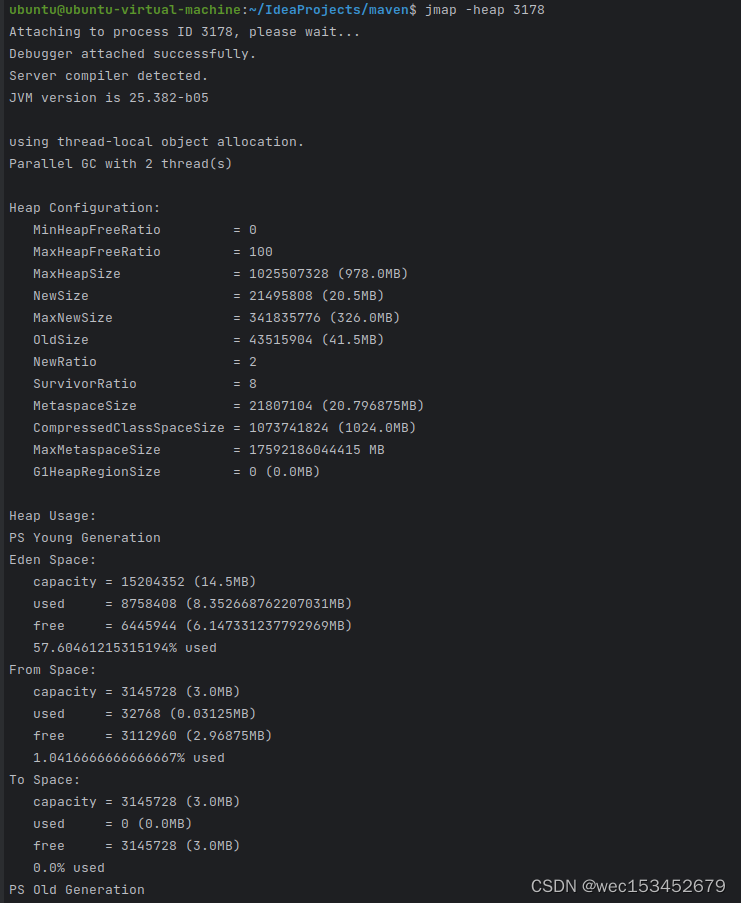
jmap工具
查看堆内存占用情况
命令:jmap -heap pid # 查看堆内存的占用情况
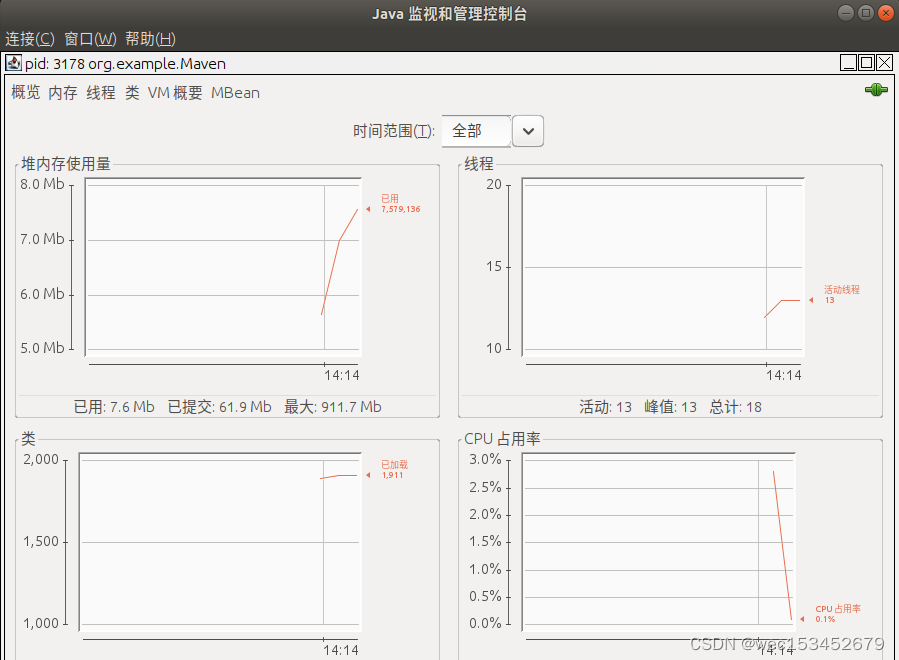
jconsole工具
图形界面的,多功能的监测工具,可以连续检测;
可视化的工具jvisualvm工具
方法区
概述:
Java内存结构中的方法区(Method Area),是JVM中的一块特殊区域,用于存储类信息、常量、静态变量、即时编译器编译后的代码等数据(JDK1.6)。下面从多个角度深入讲解Java方法区的特点和作用:
-
存储类信息:方法区用来存储所有已被加载的类的信息,包括类的结构信息(如字段、方法、构造函数等)、父类、实现的接口、访问权限等。这些类信息对于Java运行时的类加载、链接和运行非常重要。
-
常量池:方法区包含一个常量池(Constant Pool),用于存储编译器生成的字面量(如字符串、数字)、符号引用和其他编译器生成的常量。这些常量在方法区中存储一次,然后可以在整个程序中共享使用。
-
静态变量:所有类的静态变量(static variables)都存储在方法区中。静态变量在类加载时被初始化,并且在整个程序执行期间都可以访问。
-
即时编译器编译后的代码:方法区存储即时编译器(Just-In-Time Compiler,JIT)编译后的代码,包括优化后的本地机器代码(native machine code)。这些代码在运行时会被直接执行,提高程序的执行效率。
-
运行时常量池:方法区包含每个类的运行时常量池(Runtime Constant Pool),在类加载时进行动态生成,用于存储类中使用的符号引用、字符串字面量等等。运行时常量池与编译时常量池类似,但是它在运行时的内容可以进行更改。
-
GC回收目标:方法区被Java垃圾回收器管理,未被使用的类信息、常量和静态变量会被垃圾回收器自动清理。在一些老版的JVM中,方法区使用的是永久代(PermGen)来实现,但在Java 8及以后的版本中,永久代被元空间(Metaspace)所取代。
需要注意的是,方法区是线程共享的,因此需要保证多线程访问的安全性。
随着Java版本的升级,方法区的实现会有所变化,比如Java 8及以后的版本使用元空间作为方法区的存储区域。
JDK1.6和JDK1.8后的方法区变化
JDK 1.6中的方法区实现:
在JDK 1.6及之前的版本中,方法区的实现采用了永久代(Permanent Generation)。永久代是堆内存的一个逻辑分区,其主要目的是存储类的相关元数据、常量池、静态变量等。
然而,永久代的分配是固定的,一旦分配过程中遇到方法区内存不足的情况,会抛出 OutOfMemoryError: PermGen space 错误。开发者往往需要手动管理永久代的大小,而且在特定场景下容易出现性能问题。
JDK 1.8后的方法区实现:
JDK 1.8后,Oracle对JVM内存模型进行了重大调整,其中一个重要的改变是彻底移除了永久代。取而代之的是一个称为元空间(Metaspace)的新的方法区的实现。
元空间与永久代的区别:
元空间与永久代有着明显的区别。首先,元空间不再是虚拟机内存的一部分,而是直接使用本地内存(Native Memory)来存储类的元数据。这意味着元空间的大小受限于操作系统的可用内存,避免了永久代大小固定的问题。
其次,元空间中的类元数据和符号引用信息被存储在本地内存中,并且会根据需要进行动态分配和回收。这消除了在永久代中需要手动管理内存大小的需求。
另外,元空间支持动态扩展和收缩,以适应应用程序的需要。在达到默认阈值后,会触发垃圾回收来清理无效的类元数据。
总结起来,JDK 1.8后的方法区采用元空间取代了永久代,解决了永久代固定内存大小和手动调整内存的问题,并提供了更好的性能和可靠性。开发者无需再关注方法区的大小设置,而是需要根据应用程序需求来调整整个堆内存的大小。
运行时常量池
二进制字节码包含(类的基本信息,常量池,类方法定义,包含了虚拟机的指令)
首先看看常量池是什么,编译如下代码:
public class Test {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}
然后使用 javap -v Test.class 命令反编译查看结果。
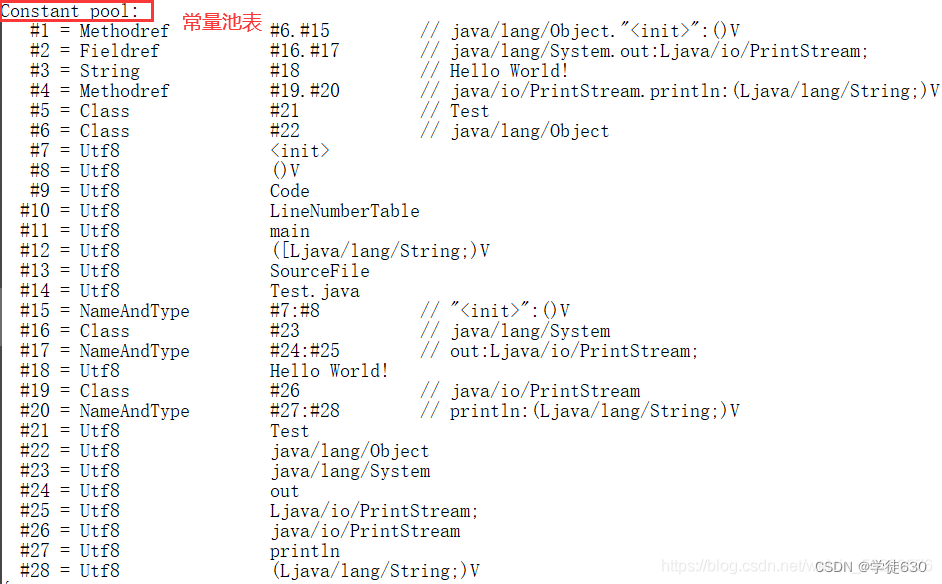
每条指令都会对应常量池表中一个地址,常量池表中的地址可能对应着一个类名、方法名、参数类型等信息。

常量池:
就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量信息
运行时常量池:
常量池是 *.class 文件中的,当该类被加载以后,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址
StringTable
- 常量池中的字符串仅是符号,只有在被用到时才会转化为对象,就是说在生成字节码文件的时候并不会将常量写入串池中,而是执行到了才会写入(懒加载)
- 利用串池的机制,来避免重复创建字符串对象
- 字符串变量拼接的原理是StringBuilder + new String(xxx);
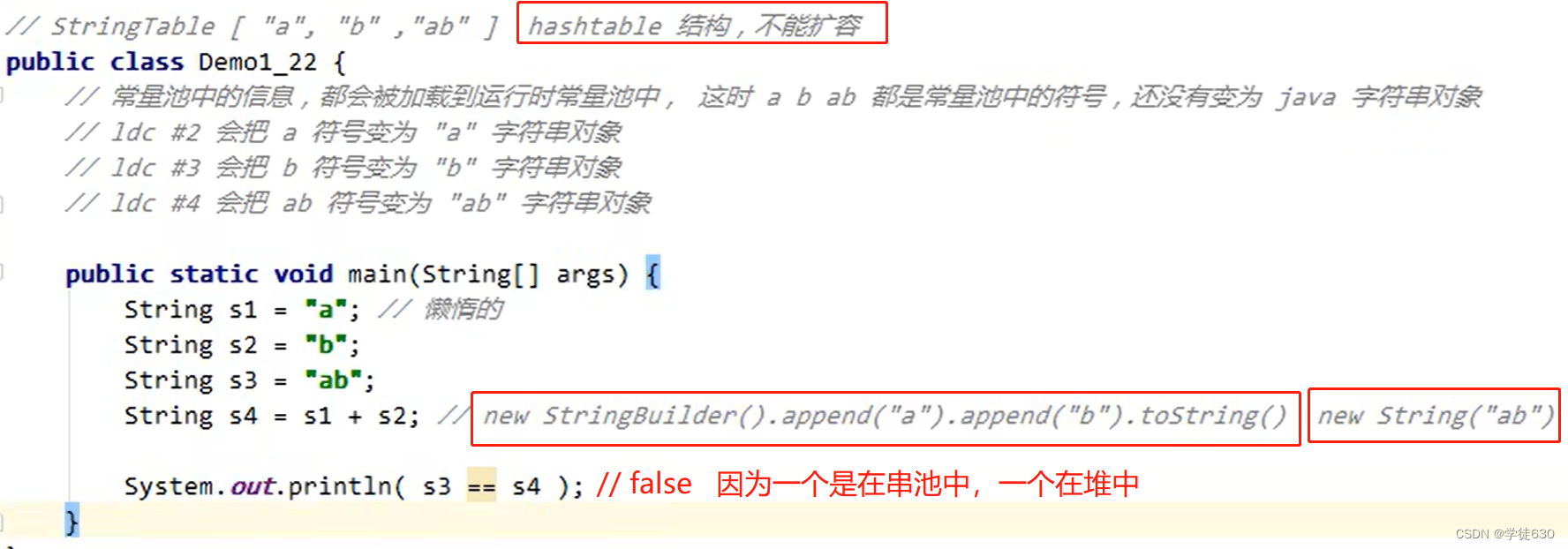
- 字符串常量拼接的原理是编译器优化

在Java中,调用
System.out.println("1")的代码不会在堆中生成对象。而是将字符串字面量"1"写入到字符串常量池(String Pool)中。new String("a")操作会生成一到两个对象,当执行
new String("a")时,会在堆中创建一个新的字符串对象,内容为 “a”。此时,字面量 “a” 如果在字符串常量池中不存在,会在字符串常量池中创建一个字符串常量对象。
- 可以使用intern方法,主动将串池中还没有的字符串对象放入串池中
intern方法 1.8
调用字符串对象的 intern 方法,会将该字符串对象尝试放入到串池中
- 如果串池中没有该字符串对象,则放入成功
- 如果有该字符串对象,则放入失败
无论放入是否成功,都会返回串池中的字符串对象
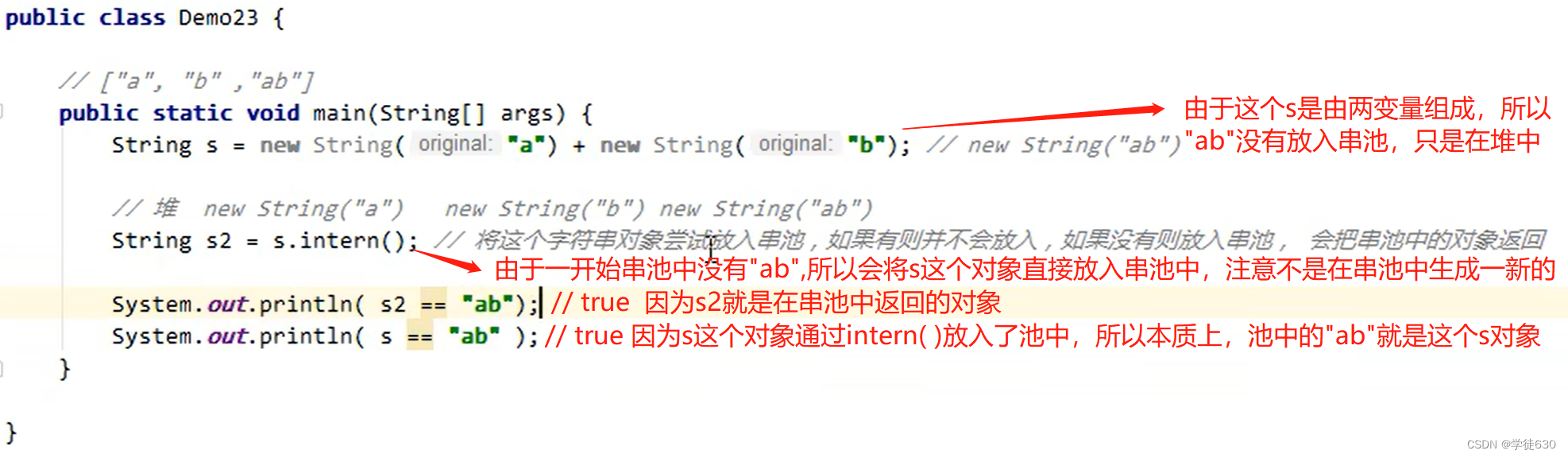
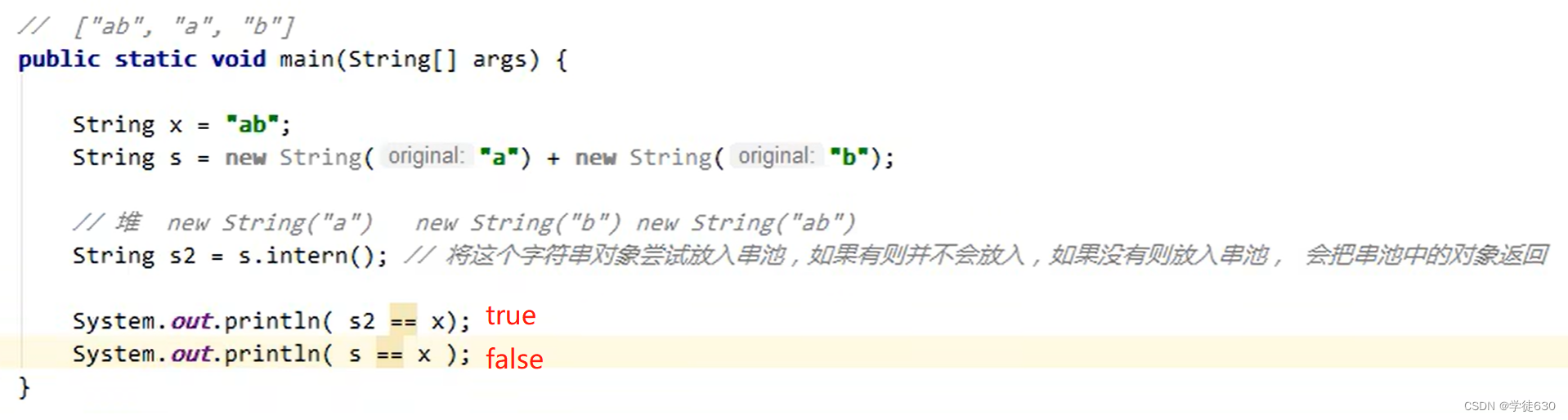
- 1.6 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份, 放入串池, 会把串池中的对象返回

面试笔试:

StringTable 的位置
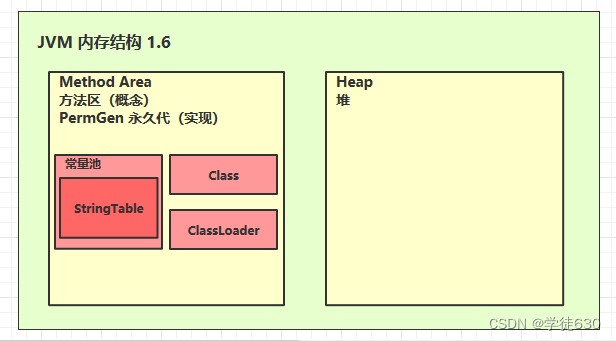

jdk1.6 StringTable 位置是在永久代中,1.8 StringTable 位置是在堆中。
转移的原因在于,StringTable中积累了很多字符串对象,如果不交到堆中的话,不能很好的杯垃圾回收释放内存
StringTable 性能调优
调整 StringTable 大小
StringTable 默认的大小是在启动时根据最大堆内存动态计算的。可以通过 JVM 参数
-XX:StringTableSize=桶个数(最少设置为 1009 以上)
来手动调整 StringTable 的大小,以满足应用程序的需求。较大的 StringTable 大小可以减少哈希冲突和哈希碰撞,提高查找字符串的性能。
减少字符串的 intern() 调用
intern() 方法会将字符串添加到字符串常量池中,但过多的 intern() 调用会导致 StringTable 的过度膨胀,可能增加了哈希冲突和哈希碰撞的概率。因此,在设计应用程序时,可以避免不必要的 intern() 调用,只对确实需要在全局范围内共享的字符串使用 intern()。
使用 StringBuilder 或 StringBuffer
在处理大量字符串拼接或修改操作时,使用 StringBuilder (在单线程环境下)或 StringBuffer (在多线程环境下)可以避免不必要的字符串对象的创建和销毁,以提高性能。
使用字符串常量或字面量:
对于不需要修改的字符串,尽量使用字符串常量或字面量,避免创建新的字符串对象和进行 intern() 调用。
注意字符串引用的作用域:
确保字符串对象只在需要的范围内存在,尽早释放不再使用的字符串引用,以便垃圾回收器能够及时回收这些对象。
注意字符串拼接的方式:
避免过多的字符串拼接操作,尤其是在循环中。可以使用 StringJoiner、String.format() 或 StringBuilder 来提高效率。
直接内存
概述:
当我们谈论Java内存结构时,除了Java堆、栈、方法区和程序计数器之外,还有一块重要的内存区域被称为"直接内存"(Direct Memory)。
直接内存并不是Java虚拟机提供的内存区域,而是通过使用Java NIO(New Input/Output)库中的ByteBuffer来直接分配的一块内存空间。它与Java堆不同,属于操作系统管理的内存,是通过Native函数库进行分配和释放。
直接内存可以使用ByteBuffer的allocateDirect()方法进行分配,而不是使用普通的Java堆内存。它的主要优势是可以直接在Java程序和操作系统的内存之间进行数据传输,提升数据处理的效率。
特点:
分配方式:
直接内存的分配并不受到Java堆大小的限制,它直接使用操作系统的函数进行内存分配。分配过程中使用的是系统调用,这对于大量的内存分配来说可以比Java堆更高效。
效率:
直接内存的读写效率相对较高,因为它可以通过操作系统的DMA(Direct Memory Access)机制,直接将数据从操作系统的内存复制到直接内存中,而不需要通过中间的Java堆来传输。这对于IO操作,特别是大量数据的IO操作,可以显著提升性能
内存使用:
直接内存的分配并不受到堆内存大小的限制,因此可以分配比Java堆更大的内存空间。但是需要注意的是,直接内存的分配和释放过程中并不会触发垃圾回收,需要手动调用System.gc()或者显式地释放分配的直接内存来确保其回收。
垃圾回收:
直接内存并不被Java虚拟机所管理,因此也不会受到Java堆垃圾回收器的管理。但是,当Java虚拟机内存不足时,垃圾回收器会触发全局的垃圾回收,包括直接内存的回收。
内存溢出:
直接内存也可能发生内存溢出,当我们分配了过多的直接内存而没有释放时,会导致直接内存耗尽。这种情况一般会抛出OutOfMemoryError,并且不能通过调整Java堆内存大小来解决,需要释放或调整直接内存的分配。
为什么直接内存的io比堆内存的io快?
我们可以通过以下的io操作剖析得到答案
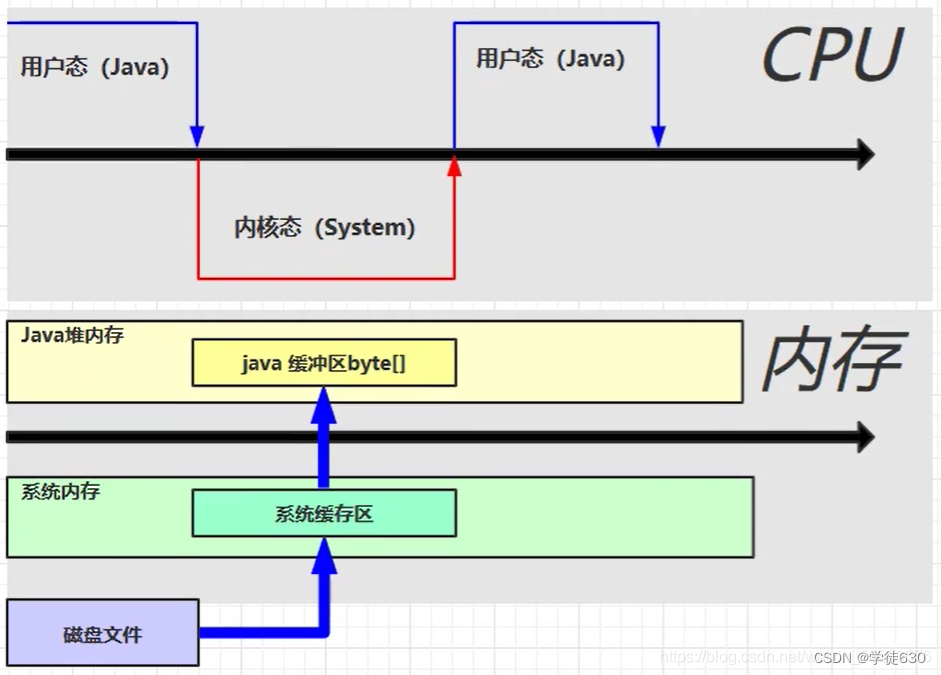
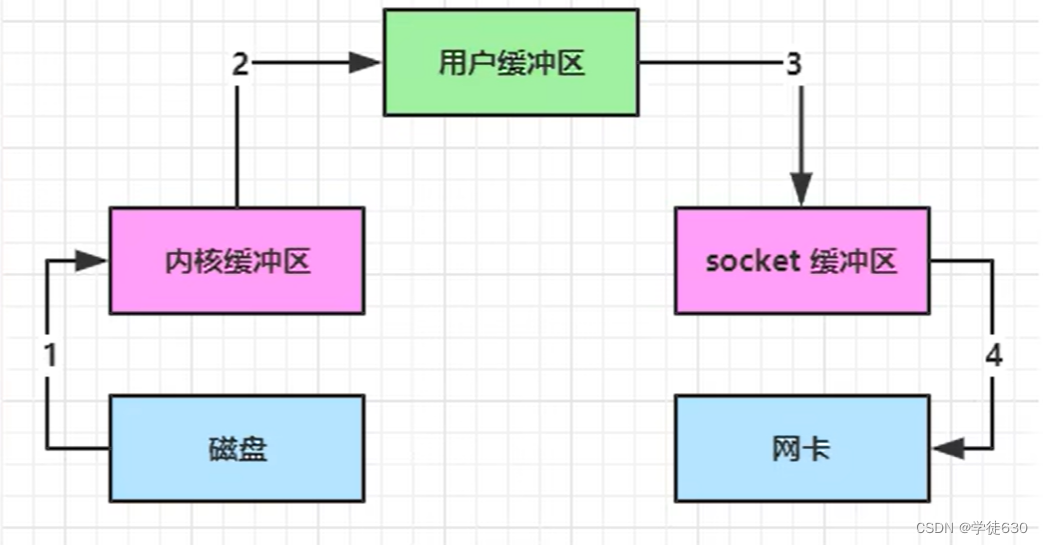


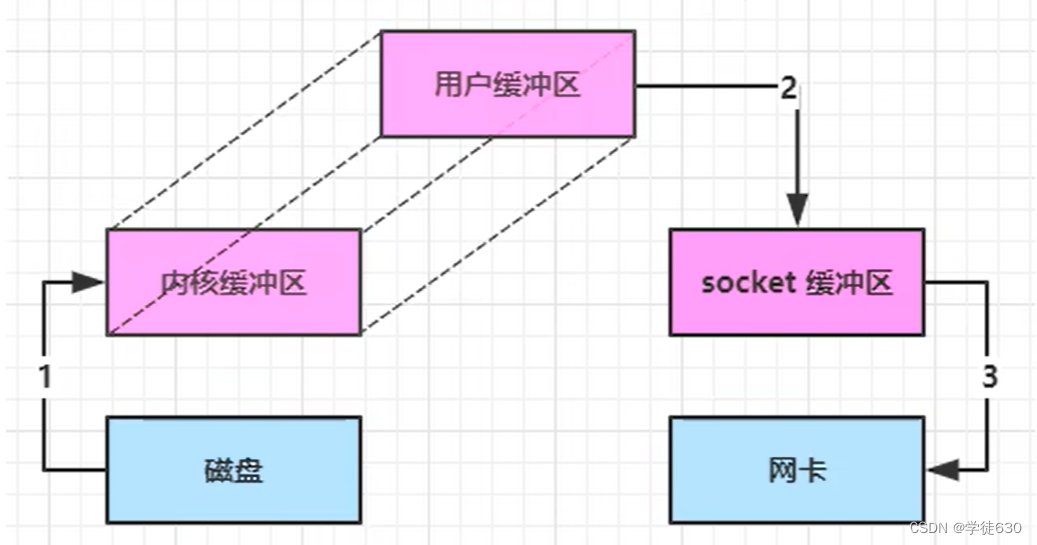


直接内存是操作系统和 Java 代码都可以访问的一块区域,无需将代码从系统内存复制到 Java 堆内存,从而提高了效率。
直接内存回收原理
public class Code_06_DirectMemoryTest {
public static int _1GB = 1024 * 1024 * 1024;
public static void main(String[] args) throws IOException, NoSuchFieldException, IllegalAccessException {
// method();
method1();
}
// 演示 直接内存 是被 unsafe 创建与回收
private static void method1() throws IOException, NoSuchFieldException, IllegalAccessException {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
Unsafe unsafe = (Unsafe)field.get(Unsafe.class);
long base = unsafe.allocateMemory(_1GB);
unsafe.setMemory(base,_1GB, (byte)0);
System.in.read();
unsafe.freeMemory(base);
System.in.read();
}
// 演示 直接内存被 释放
private static void method() throws IOException {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1GB);
System.out.println("分配完毕");
System.in.read();
System.out.println("开始释放");
byteBuffer = null;
System.gc(); // 手动 gc
System.in.read();
}
}
直接内存的回收不是通过 JVM 的垃圾回收来释放的,而是通过unsafe.freeMemory 来手动释放。
第一步:allocateDirect 的实现
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size); // 申请内存
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap)); // 通过虚引用,来实现直接内存的释放,this为虚引用的实际对象, 第二个参数是一个回调,实现了 runnable 接口,run 方法中通过 unsafe 释放内存。
att = null;
}
这里调用了一个 Cleaner 的 create 方法,且后台线程还会对虚引用的对象监测,如果虚引用的实际对象(这里是 DirectByteBuffer )被回收以后,就会调用 Cleaner 的 clean 方法,来清除直接内存中占用的内存。
public void clean() {
if (remove(this)) {
try {
// 都用函数的 run 方法, 释放内存
this.thunk.run();
} catch (final Throwable var2) {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
if (System.err != null) {
(new Error("Cleaner terminated abnormally", var2)).printStackTrace();
}
System.exit(1);
return null;
}
});
}
}
}
可以看到关键的一行代码, this.thunk.run(),thunk 是 Runnable 对象。run 方法就是回调 Deallocator 中的 run 方法
public void run() {
if (address == 0) {
// Paranoia
return;
}
// 释放内存
unsafe.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
直接内存的回收机制总结
- 使用了 Unsafe 类来完成直接内存的分配回收,回收需要主动调用freeMemory 方法
- ByteBuffer 的实现内部使用了 Cleaner(虚引用)来检测 ByteBuffer 。一旦ByteBuffer 被垃圾回收,那么会由 ReferenceHandler(守护线程) 来调用 Cleaner 的 clean 方法调用 freeMemory 来释放内存
注意:
/**
* -XX:+DisableExplicitGC 显示的
*/
private static void method() throws IOException {
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(_1GB);
System.out.println("分配完毕");
System.in.read();
System.out.println("开始释放");
byteBuffer = null;
System.gc(); // 手动 gc 失效
System.in.read();
}
一般用 jvm 调优时,会加上下面的参数:
-XX:+DisableExplicitGC // 静止显示的 GC
意思就是禁止我们手动的 GC,比如手动 System.gc() 无效,它是一种 Full GC,会回收新生代、老年代,会造成程序执行的时间比较长。所以我们就通过 unsafe 对象调用 freeMemory 的方式释放内存。
释放内存
unsafe.freeMemory(base);





![[UUCTF 2022 新生赛]ezpop - 反序列化+字符串逃逸【***】](https://img-blog.csdnimg.cn/359f4593e22e4f1eb296ff45741ac968.png)