一、说明
EfficientNets是目前最强大的卷积神经网络(CNN)模型之一。随着视觉变压器的兴起,它实现了比高效网络更高的精度,出现了CNN现在是否正在消亡的问题。EfficientNetV2 不仅通过提高准确性,还通过减少训练时间和延迟来证明这是错误的。
在本文中,我详细讨论了这些CNN的开发,它们有多强大,以及它对CNN在计算机视觉中的未来有何看法。
二、EfficientNet网络简介
EfficientNet模型是使用神经架构搜索设计的。第一个神经架构搜索是在2016年的论文中提出的——“强化学习的神经架构搜索”。
这个想法是使用控制器(如RNN的网络)并从概率为“p”的搜索空间中采样网络架构。然后通过首先训练网络,然后在测试集上验证它以获得准确性“R”来评估此架构。“p”的梯度由精度“R”计算和缩放。结果(奖励)被馈送到控制器RNN。控制器充当代理,网络的训练和测试充当环境,结果充当奖励。这是常见的强化学习 (RL) 循环。该循环运行多次,直到控制器找到提供高奖励(高测试精度)的网络架构。如图 1 所示。
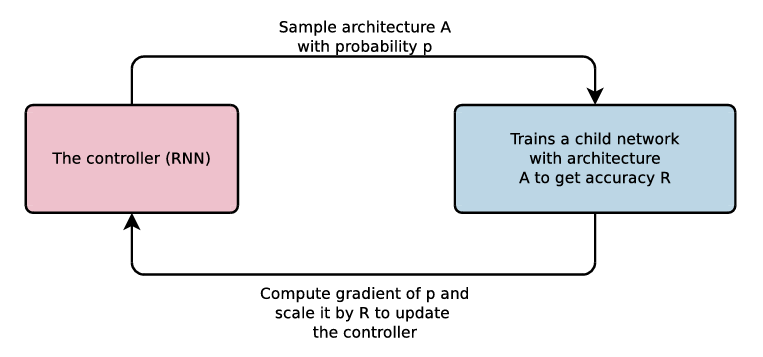
图1.神经架构搜索概述(来源:图片来自神经架构检索论文)
控制器 RNN 对各种网络架构参数进行采样,例如每层的滤波器数量、滤波器高度、滤波器宽度、步幅高度和步幅宽度。对于网络的每一层,这些参数可能不同。最后,选择奖励最高的网络作为最终的网络架构。如图 2 所示。
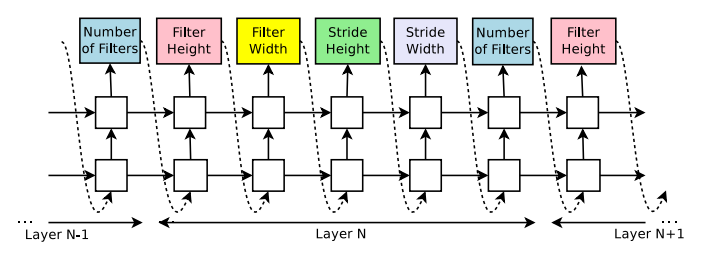
图2.控制器在网络的每一层中搜索的所有不同参数
尽管这种方法效果很好,但这种方法的问题之一是这需要大量的计算能力和时间。
为了克服这个问题,2017年,论文中提出了一种新的方法——“学习可扩展图像识别的可转移架构”。
在本文中,作者研究了以前著名的卷积神经网络(CNN)架构,如VGG或ResNet,并认为这些架构在每一层中没有不同的参数,而是有一个具有多个卷积和池化层的块,并且在整个网络架构中,这些块被多次使用。作者使用这个想法使用RL控制器找到这样的块,并且只是重复这些块N次来创建可扩展的NASNet架构。
这在2018年的“MnasNet:移动平台感知神经架构搜索”论文中得到了进一步改进。
在这个网络中,作者选择了7个区块,并对每个区块进行一层采样和重复。如图 3 所示。
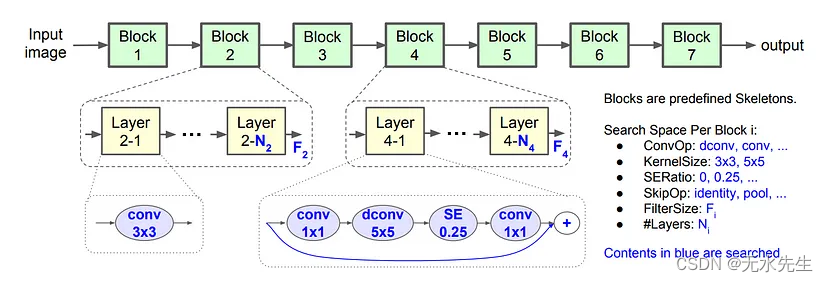
图3.在 MnasNet 架构中采样的参数。所有用蓝色书写的内容均使用RL进行搜索(来源:图片来自MnasNet论文)
除了这些参数之外,在决定奖励时还考虑了一个非常重要的参数,该参数进入控制器,即“延迟”。因此,对于MnasNet,作者考虑了准确性和延迟,以找到最佳的模型架构。如图 4 所示。这使得架构很小,它可以在移动或边缘设备上运行。
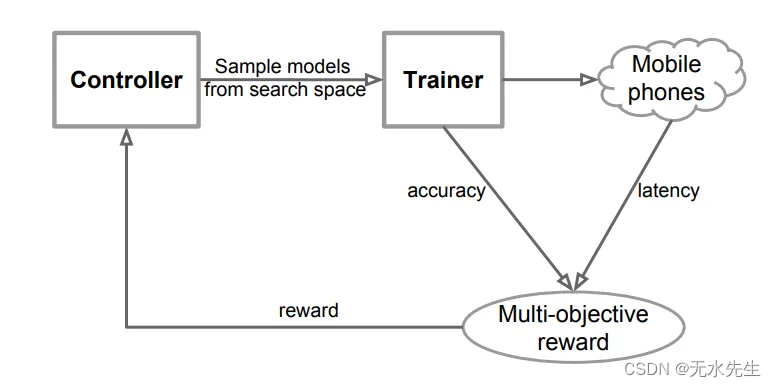
图4.寻找模型架构的工作流程,考虑准确性和延迟来决定控制器的最终奖励(来源:图片来自MnasNet论文)
最后,EfficientNet 架构在 2020 年的论文“EfficientNet:重新思考卷积神经网络的模型缩放”中提出。
查找 EfficientNet 架构的工作流程与 MnasNet 非常相似,但不考虑将“延迟”作为奖励参数,而是考虑“FLOP(每秒浮点操作数)”。这种标准搜索为作者提供了一个基本模型,他们称之为EfficientNetB0。接下来,他们放大了基本模型的深度、宽度和图像分辨率(使用网格搜索),以创建另外 6 个模型,从 EfficientNetB1 到 EfficientNetB7。这种缩放如图 5 所示。
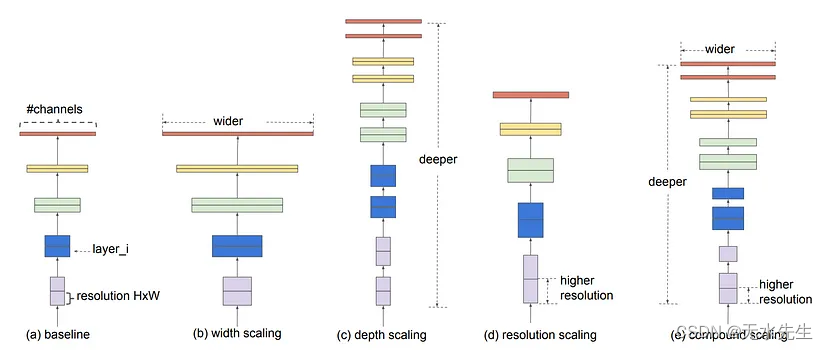
图5.缩放深度,宽度和图像分辨率以创建EfficientNet模型的不同变体(来源:图片来自EfficientNet论文)
我单独写了一篇关于EfficientNet版本1的文章。要了解有关此版本的详细信息,请单击下面的链接—参考文章:
了解 EfficientNet — 最强大的 CNN 架构
了解目前最好和最有效的CNN模型 - 高效网络
medium.com
三、高效网络V2
纸质高效NetV2:更小的模型和更快的训练(2021 年)
EfficientNetV2比EfficientNet更进一步,提高了训练速度和参数效率。此网络是使用缩放(宽度、深度、分辨率)和神经架构搜索的组合生成的。主要目标是优化训练速度和参数效率。此外,这次的搜索空间还包括新的卷积块,如Fused-MBConv。最后,作者获得了EfficientNetV2架构,该架构比以前和更新的最先进的模型快得多,并且更小(高达6.8倍)。如图 6 所示。
图6(b)清楚地显示,EfficientnetV2有24万个参数,而视觉变压器(ViT)有86万个参数。V2版本的参数也接近原始EfficientNet的一半。虽然它确实显著减小了参数大小,但它与 ImageNet 数据集上的其他模型保持了相似或更高的精度。
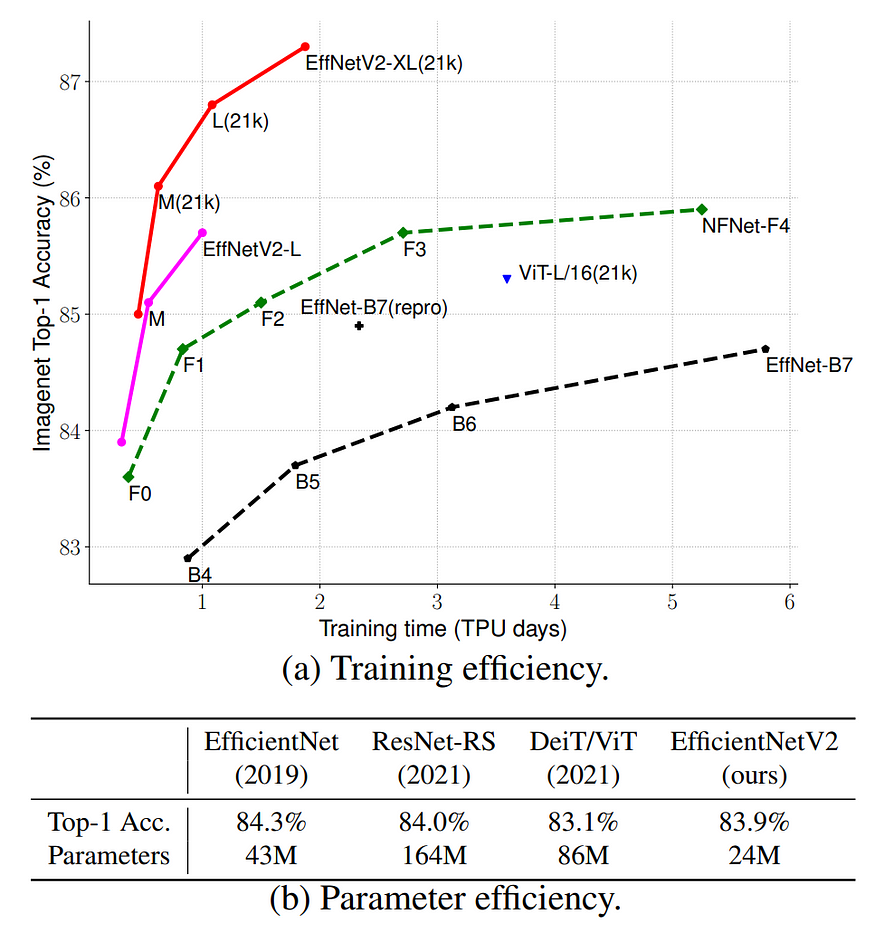
图6.与其他最新模型相比,EfficientNetV2模型的训练和参数效率(来源:EfficientNetV2论文))
作者还进行渐进式学习,即一种逐步增加图像大小以及正则化(如dropout和数据增强)的方法。这种方法进一步加快了训练速度。
3.1 EfficientNet的问题(版本1)
EfficientNet(原始版本)有以下瓶颈——
一个。EfficientNets通常比其他大型CNN模型训练得更快。但是,当使用大图像分辨率来训练模型(B6或B7模型)时,训练速度很慢。这是因为较大的 EfficientNet 模型需要更大的图像大小才能获得最佳结果,而当使用较大的图像时,需要减小批量大小以将这些图像放入 GPU/TPU 内存中,从而使整个过程变慢。
b.在网络架构的早期层,深度卷积层(MBConv)很慢。深度卷积层通常比常规卷积层具有更少的参数,但问题是它们无法充分利用现代加速器。为了克服这个问题,EfficientNetV2 使用 MBConv 和融合 MBConv 的组合,在不增加参数的情况下使训练更快(本文稍后讨论)。
c. 对高度、宽度和图像分辨率应用相等缩放,以创建从 B0 到 B7 的各种 EfficientNet 模型。所有图层的这种相等缩放不是最佳的。例如,如果深度缩放 2,则网络中的所有块都会放大 2 倍,从而使网络非常大/深。将一个块缩放两次,另一个块缩放 1.5 倍(非均匀缩放)可能更优化,以减小模型大小,同时保持良好的精度。
3.2 EfficientNetV2 — 为克服问题和进一步改进而进行的更改
一个。添加 MBConv 和熔融 MBConv 块的组合
如2.1(b)所述,MBConv块通常不能充分利用现代加速器。融合MBConv层可以更好地利用服务器/移动加速器。
MBConv层最初是在MobileNets中引入的。如图7所示,MBConv和Fused-MBConv的结构之间的唯一区别是最后两个模块。虽然 MBConv 使用深度卷积 (3x3) 后跟 1x1 卷积层,但 Fused-MBConv 用简单的 3x3 卷积层替换/融合这两层。
融合的MBConv层可以在参数数量仅略有增加的情况下使训练更快,但如果使用其中的许多块,则可以使用更多附加参数来大大减慢训练速度。为了克服这个问题,作者在神经架构搜索中同时通过了MBConv和Fused-MBConv,它会自动决定这些模块的最佳组合,以获得最佳性能和训练速度。

图7.MBConv和融合MBConv模块的结构(来源:EfficientNetV2论文)
b. NAS 搜索以优化准确性、参数效率和训练效率
通过神经架构搜索,共同优化精度、参数效率和训练效率。EfficientNet模型被用作骨干,搜索是使用不同的设计选择进行的,例如卷积块,层数,过滤器大小,扩展率等。对近1000个模型进行样本并训练了10个时期,并比较了它们的结果。选择在准确性、训练步骤时间和参数大小方面进行最佳优化的模型作为EfficientNetV2的最终基础模型。
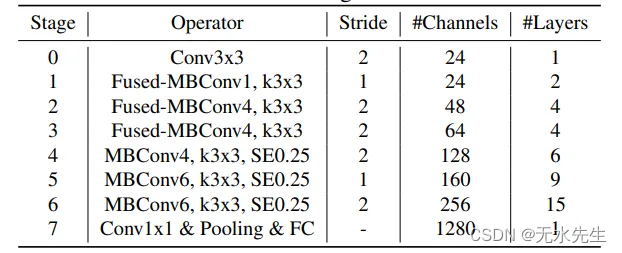
图8.EfficientNetV2-S的架构(来源:EfficientNetV2论文))
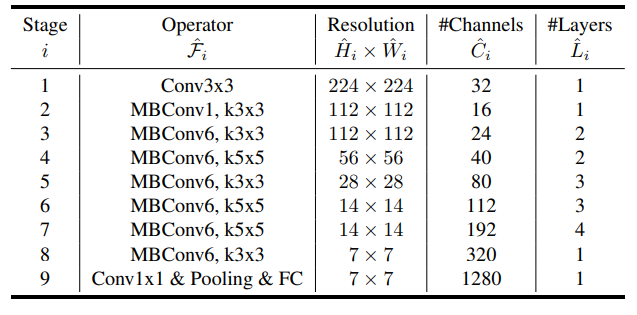
图9.EfficientNet-B0的架构(来源:EfficientNet论文))
图 8 显示了 EfficientNetV2 模型 (EfficientNetV2-S) 的基本模型体系结构。该模型一开始包含融合 MBConv 层,但后来切换到 MBConv 层。为了进行比较,我还在图 9 中展示了上一篇 EfficientNet 论文的基本模型架构。以前的版本只有MBConv层,没有融合MBConv层。
与EfficientNet-B2相比,EfficientNetV0-S的膨胀率也更小。EfficeinetNetV2不使用5x5过滤器,只使用3x3过滤器。
c. 智能模型缩放
一旦获得EfficientNetV2-S模型,就可以将其放大以获得EfficientNetV2-M和EfficientNetV2-L模型。使用了一种复合缩放方法,类似于 EfficientNet,但进行了更多更改以使模型更小、更快——
i. 最大图像大小限制为 480x480 像素,以减少 GPU/TPU 内存使用,从而提高训练速度。
ii. 在后期阶段(图 5 中的阶段 6 和 8)中添加了更多层,以增加网络容量,而不会增加太多运行时开销。
d. 渐进式学习
较大的图像尺寸通常倾向于提供更好的训练结果,但会增加训练时间。一些论文之前提出了动态改变图像大小,但它通常会导致训练准确性的损失。
EfficientNetV2的作者表明,由于图像大小在训练网络时是动态变化的,因此正则化也应该相应地改变。更改图像大小,但保持相同的正则化会导致准确性下降。此外,较大的模型比较小的模型需要更多的正则化。
作者使用不同的图像大小和不同的增强来测试他们的假设。如图 10 所示,当图像尺寸较小时,较弱的增强效果更好,但当图像尺寸较大时,较强的增强效果更好。

图 10.ImageNet top-1 精度测试了不同图像尺寸和不同增强参数(来源:EfficientNetV2 论文)
考虑到这一假设,EfficientNetV2的作者使用了自适应正则化的渐进式学习。这个想法很简单。在前面的步骤中,网络在小图像和弱正则化上进行了训练。这允许网络快速学习特征。然后图像大小逐渐增加,正则化也是如此。这使得网络难以学习。总体而言,这种方法提供了更高的准确性,更快的训练速度和更少的过度拟合。

图 11.自适应正则化的渐进式学习算法(来源:EfficientNetV2论文))
初始图像大小和正则化参数由用户定义。然后应用线性插值以增加图像大小和特定阶段(M)后的正则化,如图11所示。图 12 对此进行了更好的直观解释。随着纪元数量的增加,图像大小和增强也逐渐增加。EfficicentNetV2 使用三种不同类型的正则化——Dropout、RandAugment 和 Mixup。

图 12.具有自适应正则化视觉解释的渐进式学习(来源:EfficientNetV2论文))
3.3 结果
i. EfficientNetV2-M实现了与EfficientNetB7(以前最好的EfficientNet模型)相似的精度。此外,EfficientNetV2-M的列车速度比EfficientNetB11快近7倍。
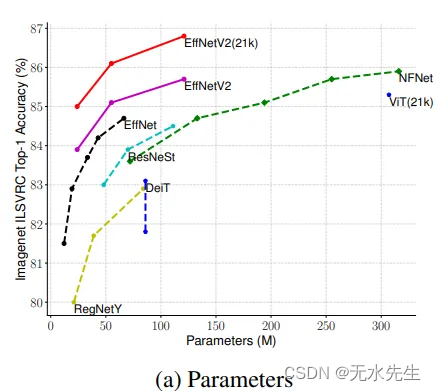
图 13 a.参数效率与其他最新模型的比较(来源:EfficientNetV2论文)
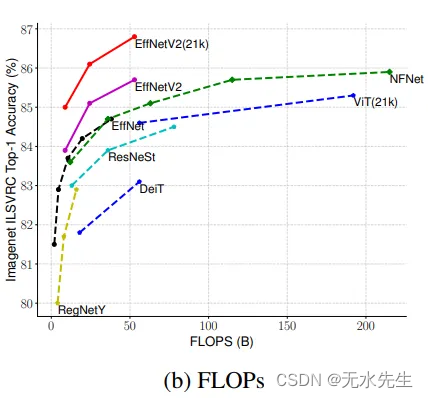
图13 b. FLOPs与其他最新模型的效率比较(来源:EfficientNetV2论文))
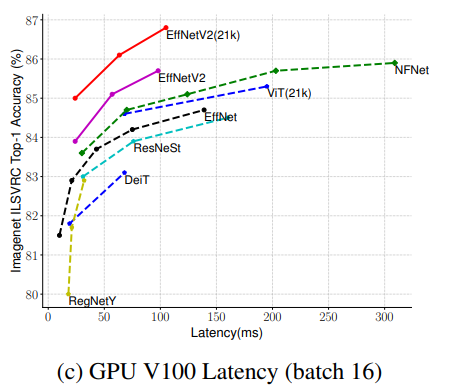
Figure 13 c. Latency comparison with other state-of-the-art models (Source: EfficientNetV2 paper)
如图 13 a、13 b 和 13 c 所示,EfficientNetV2 模型优于所有其他最先进的计算机视觉模型,包括视觉变压器。
要了解有关视觉变压器的更多信息,请访问下面的链接 —
四、变形金刚在图像识别方面比CNN更好吗?
towardsdatascience.com
图 2 显示了在 ImageNet21k 上预训练的 EfficientNetV13 模型(包含 2012 万张图像)和在 ImageNet ILSVRC1上预训练的 28 万张图像与所有其他最先进的 CNN 和转换器模型的详细比较。除了ImageNet数据集外,这些模型还在其他公共数据集(如CIFAR-14,CIFAR-10,Flowers数据集和Cars数据集)上进行了测试,并且在每种情况下,模型都显示出非常高的准确性。
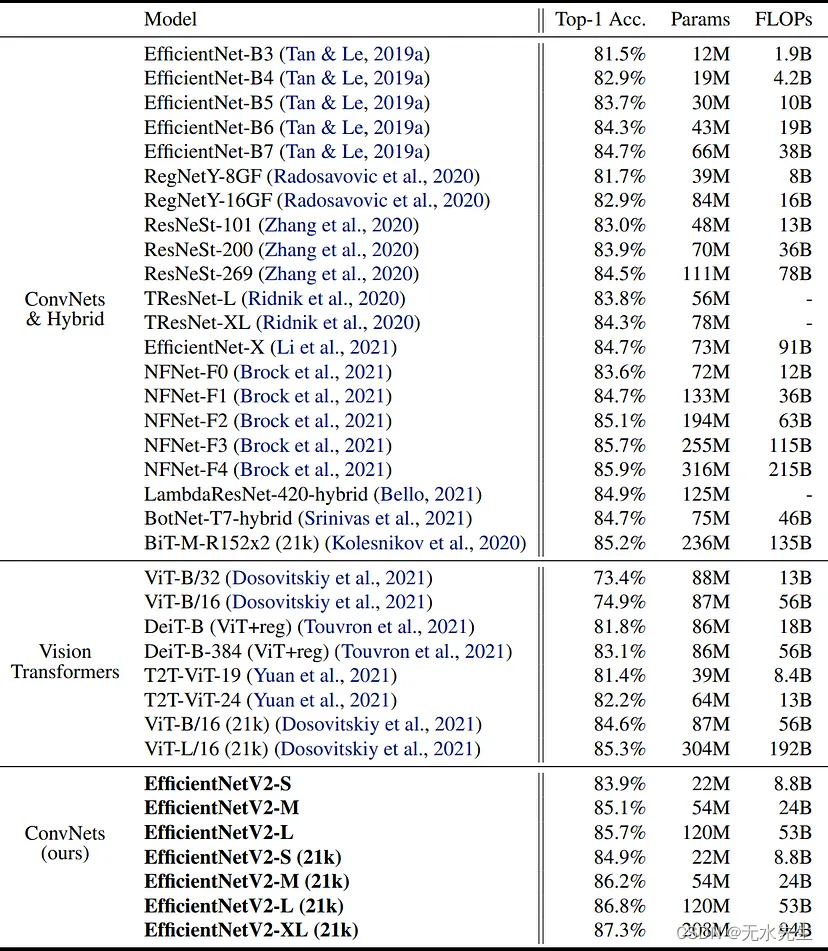
图 14.EfficientNetV2模型在精度,参数和FLOP方面与其他CNN和变压器模型的比较(来源:EfficientNetV2论文)
五、 结论
EfficientNetV2 型号比大多数最先进的型号更小、更快。这个CNN模型表明,尽管视觉变形金刚已经席卷了计算机视觉世界,但通过获得比其他CNN更高的精度,结构更好的CNN模型和改进的训练方法仍然可以比变形金刚获得更快更好的结果,进一步证明CNN将继续存在。
参考资料 —
谭明兴和乐,郭。(2021). 高效网络V2:更小的模型和更快的训练.arXiv, doi: 10.48550/ARXIV.2104.00298 https://arxiv.org/abs/2104.00298
阿琼·萨卡尔