Java字节码
概述
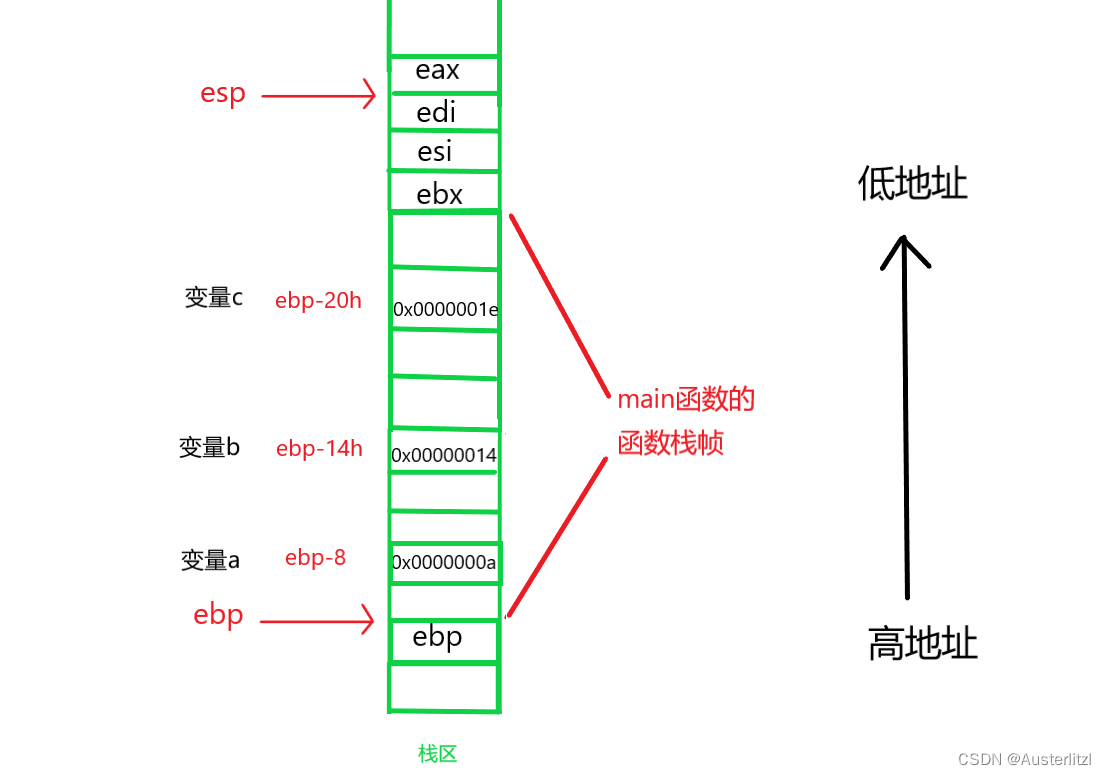
学习 Java 的都知道,我们所编写的 .java 代码文件通过编译将会生成 .class 文件,最初的方式就是通过 JDK 的 javac 指令来编译,再通过 java 命令执行 main 方法所在的类,从而执行我们的 Java 程序。而在这中间所生成的 .class 文件中的内容,就是 JVM 可以处理运行的字节码(Byte Code),它由 JVM 解释为对应系统可运行的机器指令,这也是我们的 Java 程序能够做到一处编译处处执行的原理。
什么是字节码
Java之所以可以“一次编译,到处运行”。
- 一是因为JVM针对各种操作系统、平台都进行了定制。
- 二是因为无论在什么平台,都可以编译生成固定格式的字节码(.class文件)供JVM使用。
因此,也可以看出字节码对于Java生态的重要性。之所以被称之为字节码,是因为字节码文件由十六进制值组成,而JVM以两个十六进制值为一组,即以字节为单位进行读取。在Java中一般是用javac命令编译源代码为字节码文件,一个.java文件从编译到运行的示例如下:
对于 Java 开发人员来说,平时需要阅读 Byte Code 的场景比较少,但和阅读框架源码能够了解到框架的设计思路一样,阅读 Java Byte Code 也有利于我们理解 Java 一些深层的东西,提高我们解决问题的能力。能够阅读 Byte Code 也有利于我们去理解 Kotlin 或其它运行在 JVM 上的语言,是如何扩展 Java 所没有的特性或语法。
字节码文件结构
首先我们先编写一个简单的 Java 代码作为演示例子,然后编译这个 Hello.java 文件得到 Hello.class 文件。我们知道 .class 是二进制文件,它无法被直接查看,当然我们可以通过一些二进制文件查看工具来阅读里面的内容。

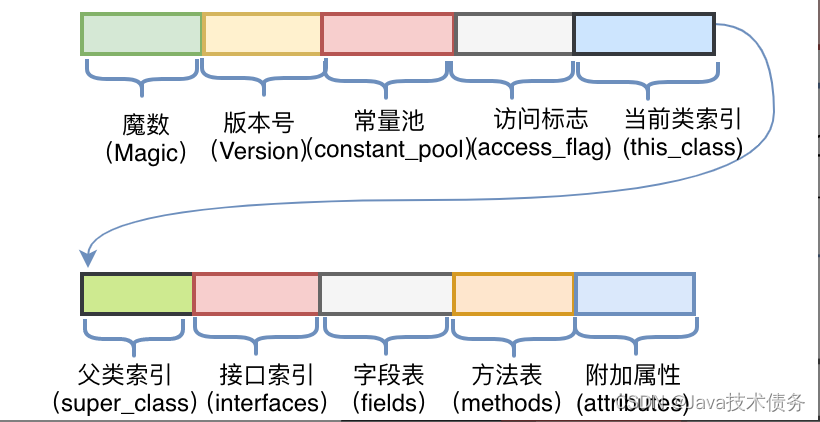
编译后生成.class文件,打开后是一堆十六进制数,按字节为单位进行分割后展示如上图右侧部分所示。上文提及过,JVM对于字节码是有规范要求的,那么看似杂乱的十六进制符合什么结构呢?JVM规范要求每一个字节码文件都要由十部分按照固定的顺序组成,整体结构如下图:
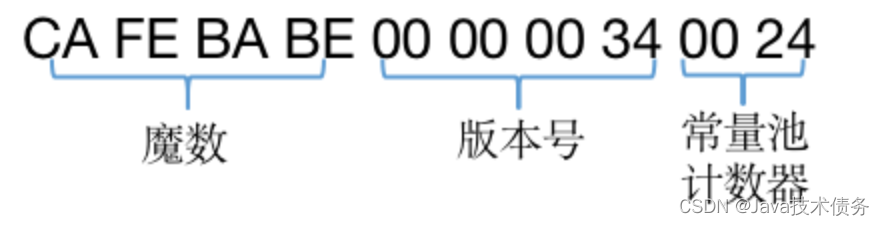
魔数
一个符合标准的 .class 文件是以 CA FE BA BE 开头,这个四个字节均为魔数,JVM 根据这个开头来判断一个文件是否可能为 .class 文件,如果是才会继续执行。
有趣的是,魔数的固定值是Java之父James Gosling制定的,为CafeBabe(咖啡宝贝),而Java的图标为一杯咖啡。
版本号
魔数后面四个字节 00 00 00 34 是版本号,前两个字节为次版本号,后两个字节为主版本号,在对主版本号进行转换可以得到 52,该序号对应的Java 版本为1.8。
常量池(Constant Pool)
在版本号后面则是常量池(Constant Pool),它包含常量池计数器和常量池数据区两个部分。
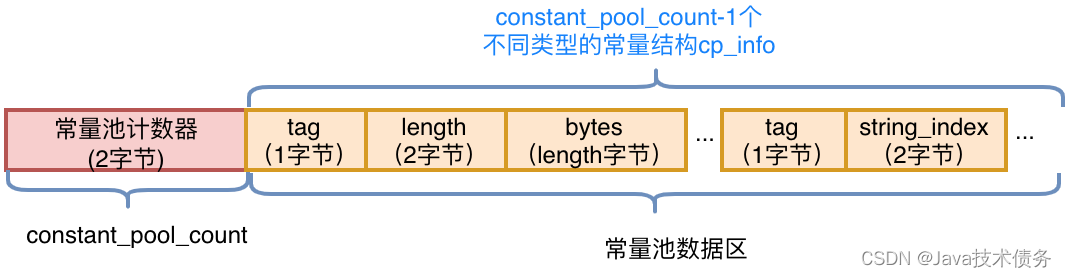
- 常量池计数器(constant_pool_count):由于常量的数量不固定,所以需要先放置两个字节来表示常量池容量计数值。图2中示例代码的字节码前10个字节如下图所示,将十六进制的24转化为十进制值为36,排除掉下标“0”,也就是说,这个类文件中共有35个常量。
-
常量池数据区:数据区是由(constant_pool_count-1)个cp_info结构组成,一个cp_info结构对应一个常量。在字节码中共有14种类型的cp_info,每种类型的结构都是固定的。
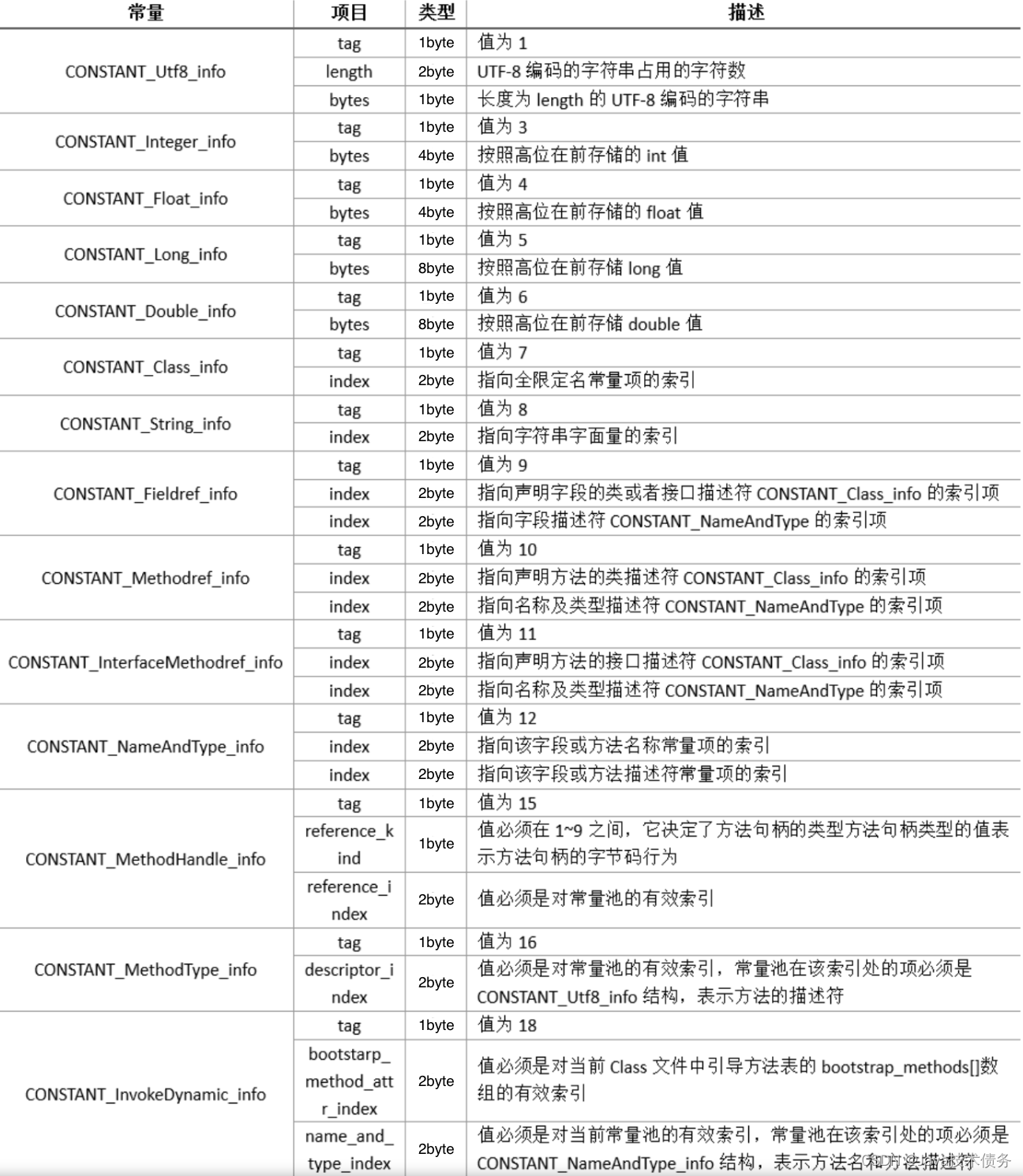
访问标志
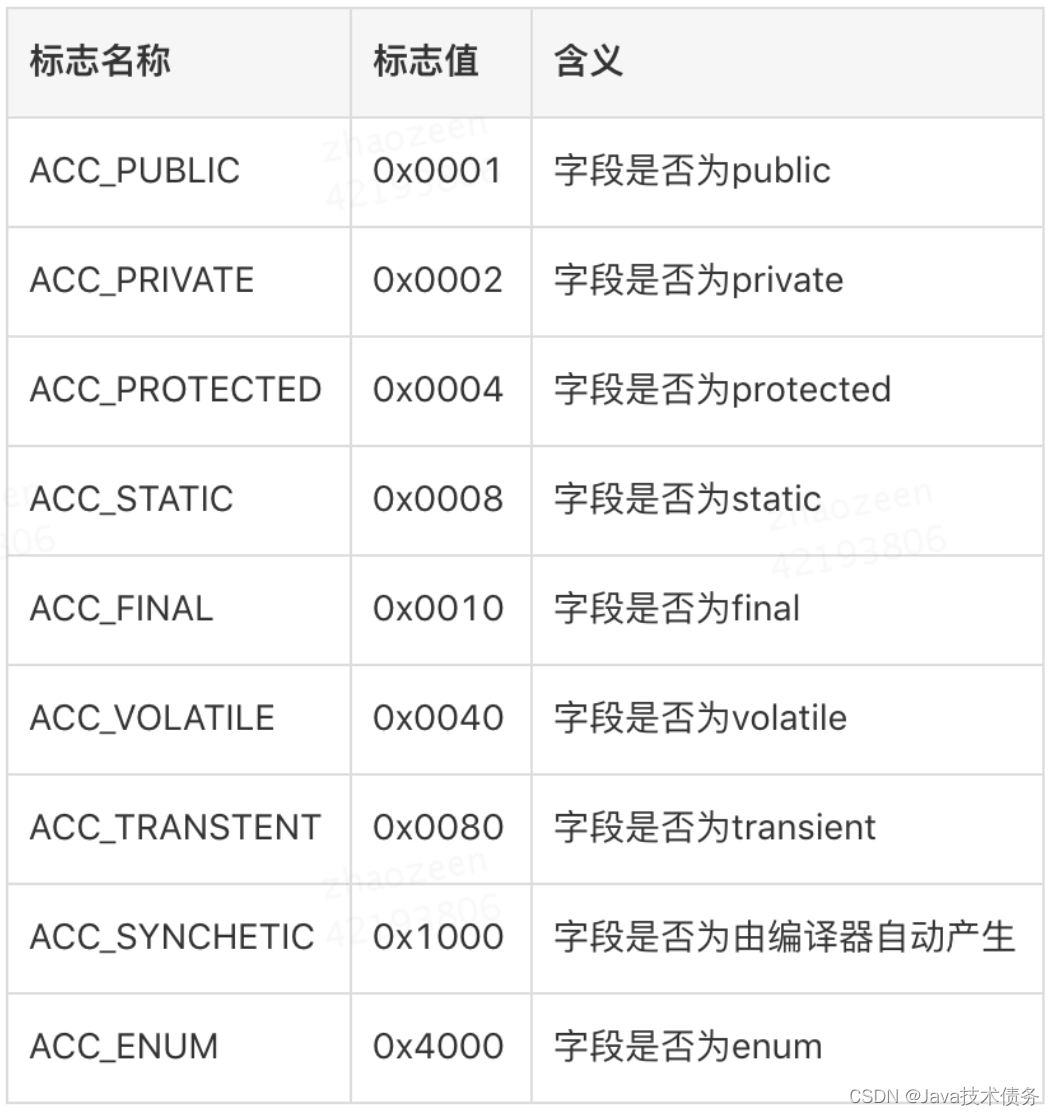
常量池结束之后的两个字节,描述该Class是类还是接口,以及是否被public、abstract、final等修饰符修饰。JVM规范规定了如下图的访问标志(Access_Flag)。
需要注意的是,JVM并没有穷举所有的访问标志,而是使用按位或操作来进行描述的,比如某个类的修饰符为public final,则对应的访问修饰符的值为ACC_PUBLIC | ACC_FINAL,即0x0001 | 0x0010=0x0011。
当前类名
访问标志后的两个字节,描述的是当前类的全限定名。这两个字节保存的值为常量池中的索引值,根据索引值就能在常量池中找到这个类的全限定名。
父类名称
当前类名后的两个字节,描述父类的全限定名,同上,保存的也是常量池中的索引值。
接口信息
父类名称后为两字节的接口计数器,描述了该类或父类实现的接口数量。紧接着的n个字节是所有接口名称的字符串常量的索引值。
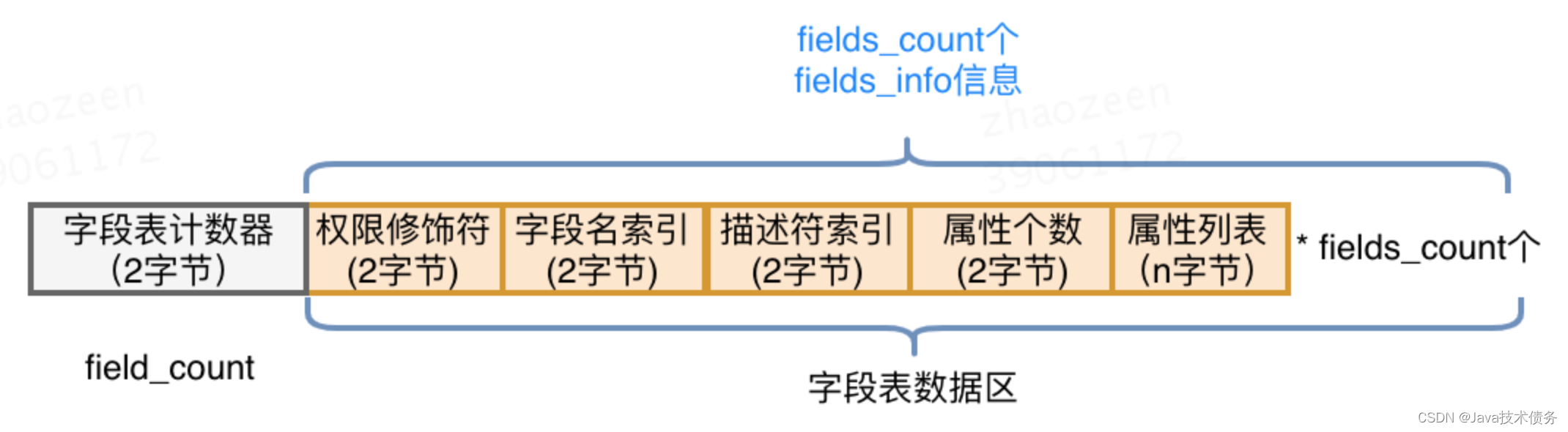
字段表
字段表用于描述类和接口中声明的变量,包含类级别的变量以及实例变量,但是不包含方法内部声明的局部变量。
字段表也分为两部分,
- 第一部分为两个字节,描述字段个数;
- 第二部分是每个字段的详细信息fields_info。
字段表结构如下图
方法表
字段表结束后为方法表,方法表也是由两部分组成,第一部分为两个字节描述方法的个数;第二部分为每个方法的详细信息。方法的详细信息较为复杂,包括方法的访问标志、方法名、方法的描述符以及方法的属性,如下图所示:
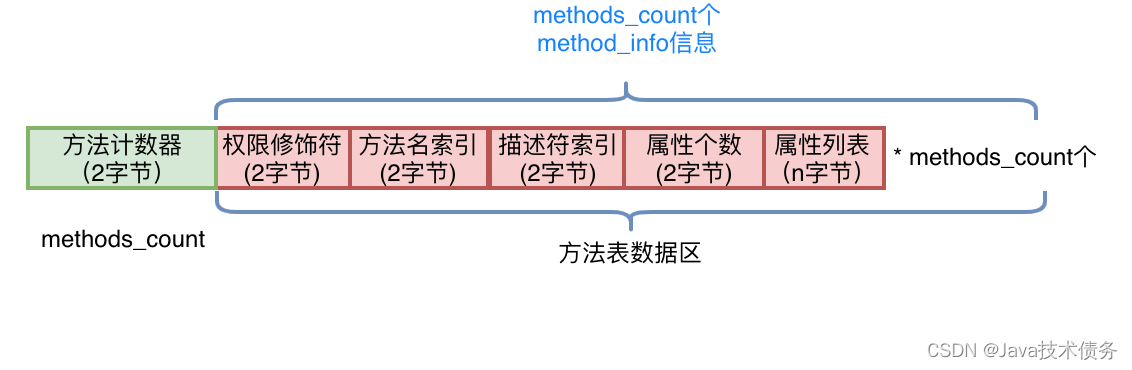
方法的权限修饰符依然可以通过访问标志查询得到,方法名和方法的描述符都是常量池中的索引值,可以通过索引值在常量池中找到。
当我们拥有一个 .class 文件时,我们可以通过 javap 来将字节码指令转换为助记符,这个命令有一些参数,你可以通过 javap -help 来查看所有参数的说明,这里为了显示尽量详细的内容,使用 javap -verbose,其效果如下,但由于内容太长,我们不一次性展示所有内容,而是分区域来进行阅读。
而“方法的属性”这一部分较为复杂,直接借助javap -verbose将其反编译为人可以读懂的信息进行解读,如下图所示。可以看到属性中包括以下三个部分:
-
Code区:源代码对应的JVM指令操作码,在进行字节码增强时重点操作的就是“Code区”这一部分。
args_size 是参数数量,在主函数中,因为有 args 这个参数,所以在这里 args_size 为 1;
locals 是该方法中的本地变量有多少个,在我们的主函数里面有定义了 3 个变量,加上一个参数,因此有 4 个变量;
stack 是方法在执行过程中,操作数栈中最大深度,这个在之后讲解指令执行过程时可以看出。
在这一行信息之后是字节码指令,一条指令包括偏移量以及执行的指令码,PC Register 利用偏移量来判断指令执行位置。
-
LineNumberTable:行号表,将Code区的操作码和源代码中的行号对应,Debug时会起到作用(源代码走一行,需要走多少个JVM指令操作码)。
LineNumberTable: line 3: 0 line 4: 2 line 5: 4 line 6: 10 line 7: 17line 3: 0 代表 Java 源码文件中的第三行代码从偏移量为 0 的位置开始,而继续往下看可以看到第四行代码从偏移量为 2 的位置开始,也就是说第三行代码所对应的字节码指令有 iconst_1 和 istore_1 两条。这也可以让 JVM 执行指令出现错误时,帮助我们定位到对应的源码位置。
-
LocalVariableTable:本地变量表,包含This和局部变量,之所以可以在每一个方法内部都可以调用This,是因为JVM将This作为每一个方法的第一个参数隐式进行传入。当然,这是针对非Static方法而言。
第一个属性 start 为这个变量可见的起始偏移位置,它的值必须是在Code 中存在的偏移量值。
第二个属性 length 为该变量的有效长度,在这个例子中,我们的变量直到方法末尾都有效,因此你会发现 start + lenth 的值都是 18 (方法中执行的指令数)。当我们在一个局部的代码块里面声明一个变量,那么它的有效期长度将会更短。
Slot 为变量在 local variable 中的位置,这可以帮助我们在指令中确定对应的变量,而 Name 则是变量名,Signature 为该变量的类型。

附加属性表
字节码的最后一部分,该项存放了在该文件中类或接口所定义属性的基本信息。
操作数栈和字节码
JVM的指令集是基于栈而不是寄存器,基于栈可以具备很好的跨平台性(因为寄存器指令集往往和硬件挂钩),但缺点在于,要完成同样的操作,基于栈的实现需要更多指令才能完成(因为栈只是一个FILO结构,需要频繁压栈出栈)。另外,由于栈是在内存实现的,而寄存器是在CPU的高速缓存区,相较而言,基于栈的速度要慢很多,这也是为了跨平台性而做出的牺牲。
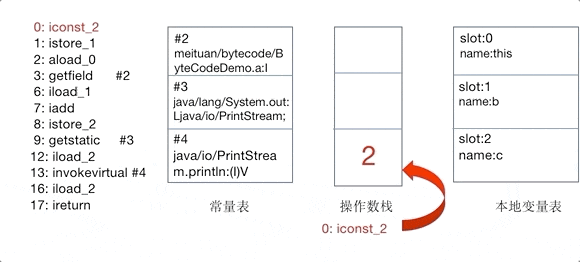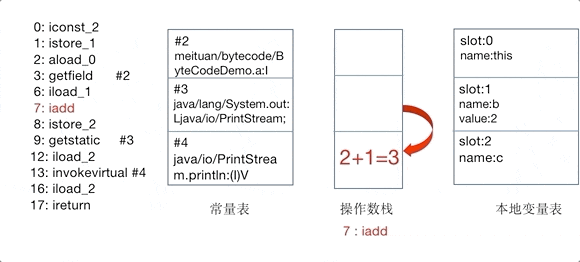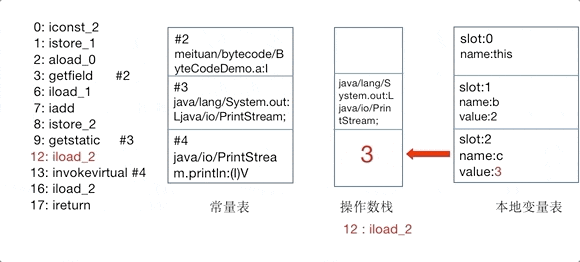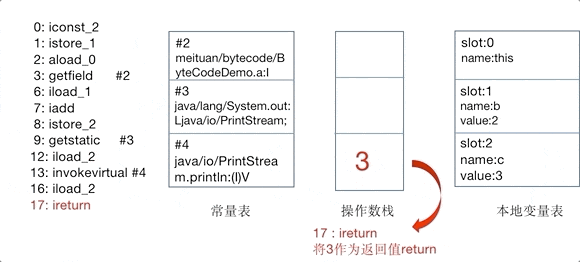
我们在上文所说的操作码或者操作集合,其实控制的就是这个JVM的操作数栈。为了更直观地感受操作码是如何控制操作数栈的,以及理解常量池、变量表的作用,将add()方法的对操作数栈的操作制作为GIF,如下图14所示,图中仅截取了常量池中被引用的部分,以指令iconst_2开始到ireturn结束。
JVM 内存结构
我们的Java程序在运行时是通过 main() 方法启动,它是程序的入口,我们的进程在启动时会为该方法创建一个主线程来执行代码。当我们使用多线程时,那么程序的进程将会拥有多个线程。每个线程的资源都拥有独自的资源,当然它们也可以共享进程的资源,那么在 JVM 中,根据资源的可用范围,可将内存区域分为线程独占和线程共享两个类别。JVM内存布局
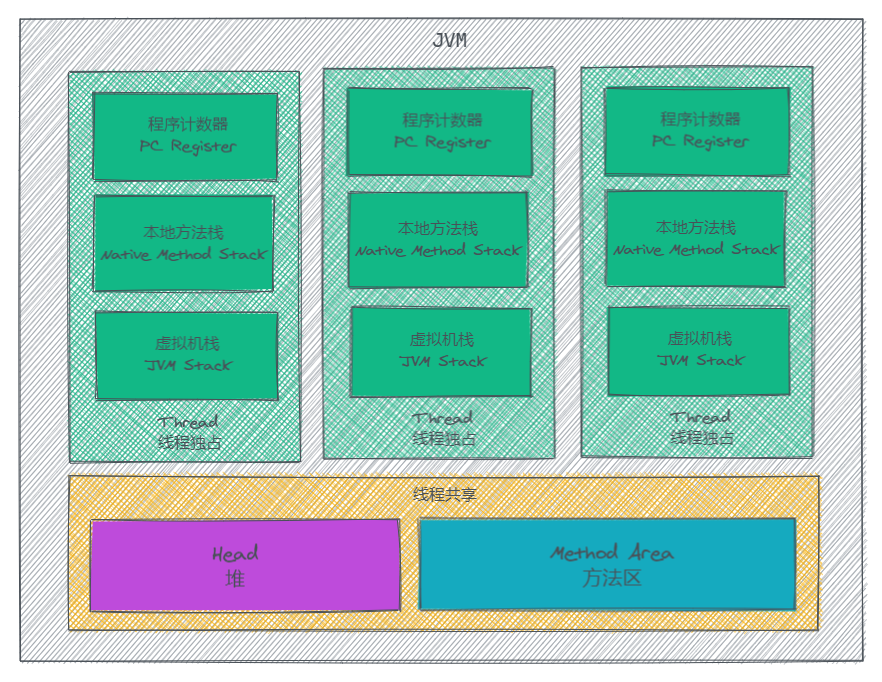
对于每一个线程,都可将其拥有的内存空间分为 PC Register、Native Method Stack、JVM Stack 这3个区域,这3个区域对于线程来说都是独占的,其它线程无法进行访问。
- PC Register 用于记录当前线程指令的执行位置。由于一个进程可能有多个线程,而CPU会在不同线程之间切换,为了能够记录各个线程的当前执行的指令,每个线程都需要有一个 PC Register,来保证各个线程都可以进行独立运算。
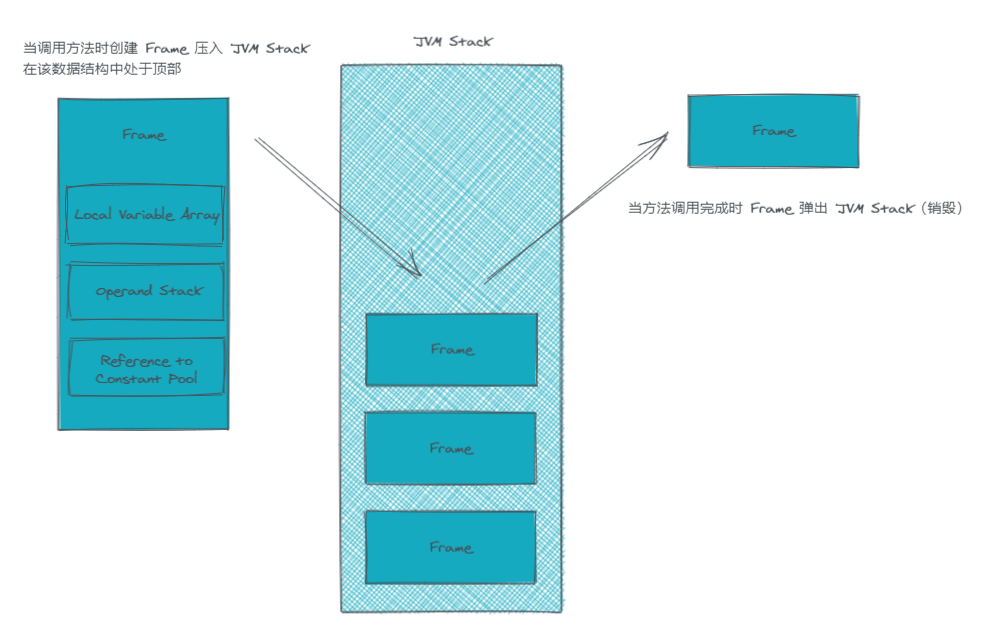
- JVM Stack 用于存放调用方法时压入栈的栈帧。相信学过数据结构的对栈应该不陌生,JVM Stack 压入的单位为栈帧(Frame),用于存储数据、动态链接、方法返回值和调度异常等。每次调用一个方法都会创建一个新的栈帧压入 JVM Stack 来存储该方法的信息,当该方法调用完成时,对应的栈帧也会跟着被销毁。一个栈帧都有自己的局部变量数组、操作数栈、对当前方法类的运行常量池的引用。
- Native Method Stack 则是用于调用操作系统本地方法时使用的栈空间。
每个线程都可用访问的内存空间为线程共享区域,它包含 Head 和 Method Area 两个部分,Head 用于存放实例对象,也是 GC 回收的主要区域,而 Method Area 用于存放类结构与静态变量。
现在我们初步了解了 JVM 内存的布局,那么接下来可以继续看指令的执行过程了。
指令的执行过程
由于 Java 程序从 main() 方法开始,我们也是从这个方法的指令开始进行分析。
假设程序运行 0 号指令前的状态如下,在 mian 方法栈帧里面,有着 operand stack(操作数栈),它的最大长度为 2(与 Code 下的 stack 的值一致),此外还有一个 local variable(本地变量表)来存放变量的值,其中下标为 0 的变量为主方法的参数 args,我们直接用这个字符串填充在那里来做一个标识(实际的值可能是一个空数组)。
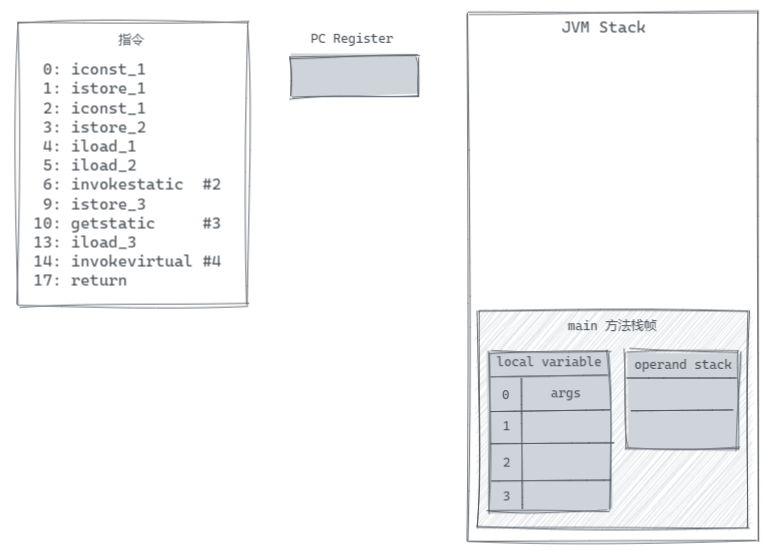
接下来我们一步步执行方法中的指令,在这里我们先对出现的几个指令做一个简单的介绍:
iconst_<i>放一个 int 常量(-1, 0, 1, 2, 3, 4 or 5) 到 operand stack 中istore_<n>从 operand stack 中获取一个 int 到 local variable 的 n 中iload_<n>从 local variable 中读取 int 变量 n 的值到操作数栈中invokestatic调用一个 class 的 static 方法getstatic从 class 中获取一个 static 字段invokevirtual调用一个实例方法,基于类的调度return从方法中返回一个 void,ireturn从方法中返回 operand stack 栈顶的 int
更多的指令与详细的说明请查看文章最后参考中的官方指令文档
现在我们开始分析指令的执行,我们在上面知道了,我们的 Java 代码所对应的指令分别是偏移量为 0 和 1 的两个,最开始执行的是 0: iconst_1,该指令会把 int 常量 1 放置到 operand stack 中,之后执行的是 1: istore_1,把 operand stack 栈顶的 int 常量取出放到 local variable 下标为 1 的变量中,该过程图示如下。
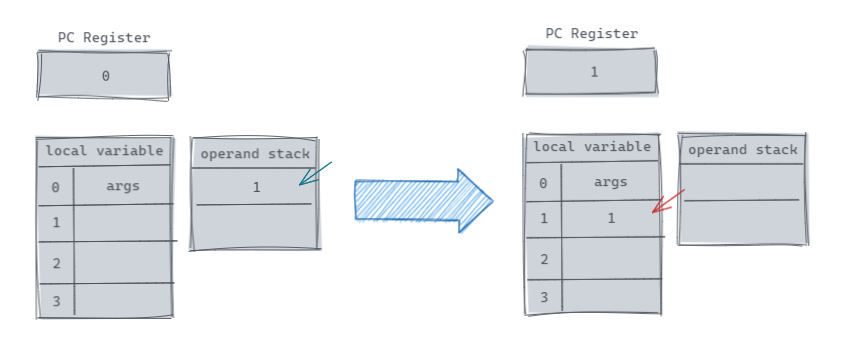
我们可以通过查看 LocalVariableTable 得知下标为 1 的变量在我们的 Java 程序中是 int 变量 a,因此上面这两条指令常量 1 赋值给变量 a。同样的,后面两条指令则是将常量 1 赋值给变量 b。这里要注意,操作数栈的数是被取出操作,被取出的数将不会继续在 operand stack 里面。
执行完 0~3 这 4 条指令后,就来到了本例中最为关键的方法调用了。在执行 iload_1 和 iload_2 后,operand stack 中将会存放着变量 a 和 b 的值,作为 invokestatic 调用函数时传入的参数。
而执行到 invokestatic #2 这个指令的时候,该指令为调用一个 class 的 static 方法,也就是调用常量池中 #2 的方法,该方法为 Hello.add:(II)I 。
当执行 invokestatic 时会依次读取 operand stack 的数据作为方法的参数,并创建一个新的栈帧来执行方法,将数据放到 local variable 对应变量位置。
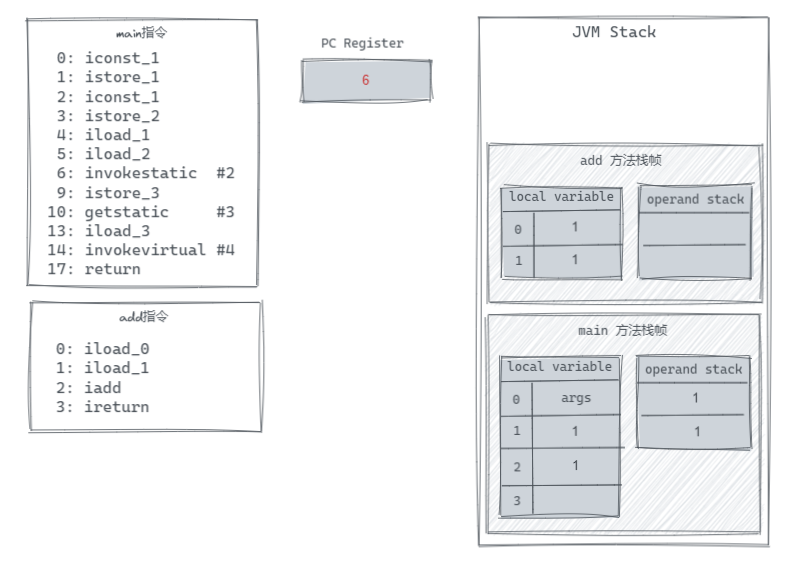
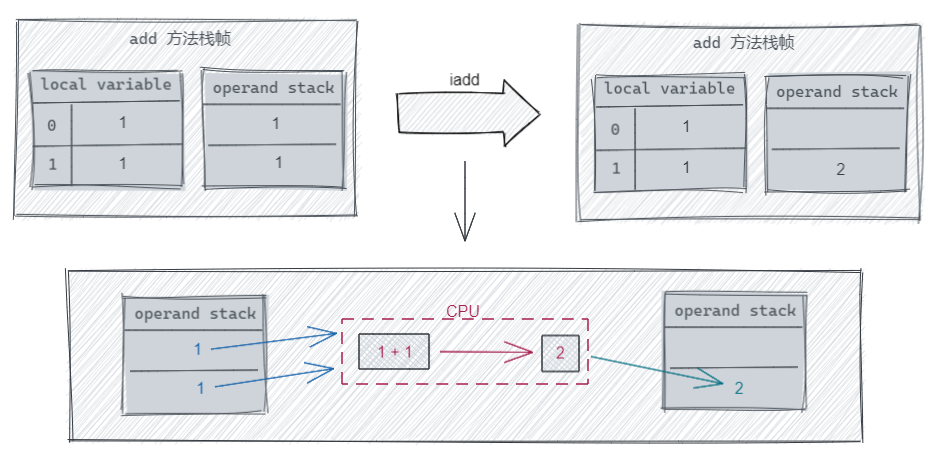
之后开始执行 add() 方法中的指令,首先执行的是两个 iload 指令,将 loca variable 对应下标的变量的值放到 operand stack 中,之后执行 iadd 取出 operand stack 中的值并进行加法运算,再把结果放到,最后执行 ireturn 取出 operand stack 顶部的 int 值进行返回。
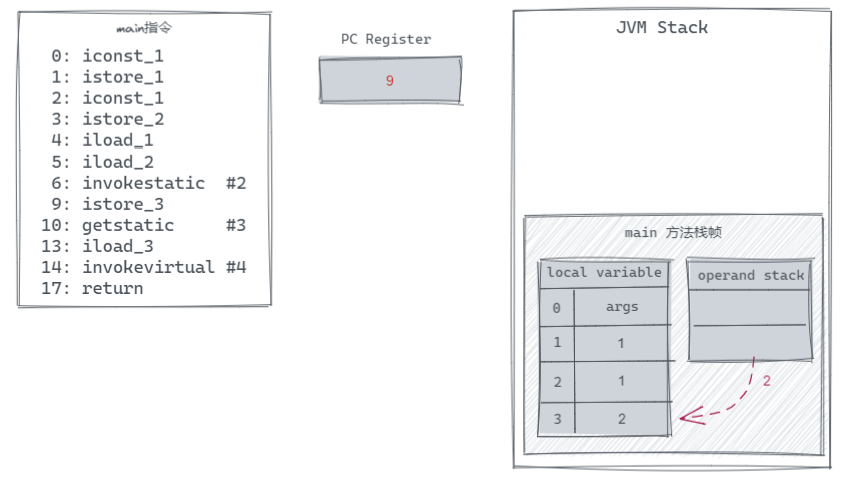
当执行完 ireturn 后,add 方法也就执行完成了,对应的栈帧也会跟着销毁。之后回到 main 方法中继续往下执行,到 istore_3 指令,该指令将栈顶的 int 值取出放到了 local variable 中 Solt 为 3 的地方,这样执行完 4~9 这几条指令后就完成了我们代码中的 int c = add(a, b); 这一行代码。那么接下来就是执行 System.out.println(c); 对应的指令将 2 打印到控制台了。
到这里其实我们就已经知道如何去阅读我们代码生成的 Byte Code 了,这里我就不继续往下分析本文例子的代码了,阅读过程中如果遇到了没见过的指令,我们可以在 Oracle 官方指令文档里面查阅对应的说明。
查看字节码工具
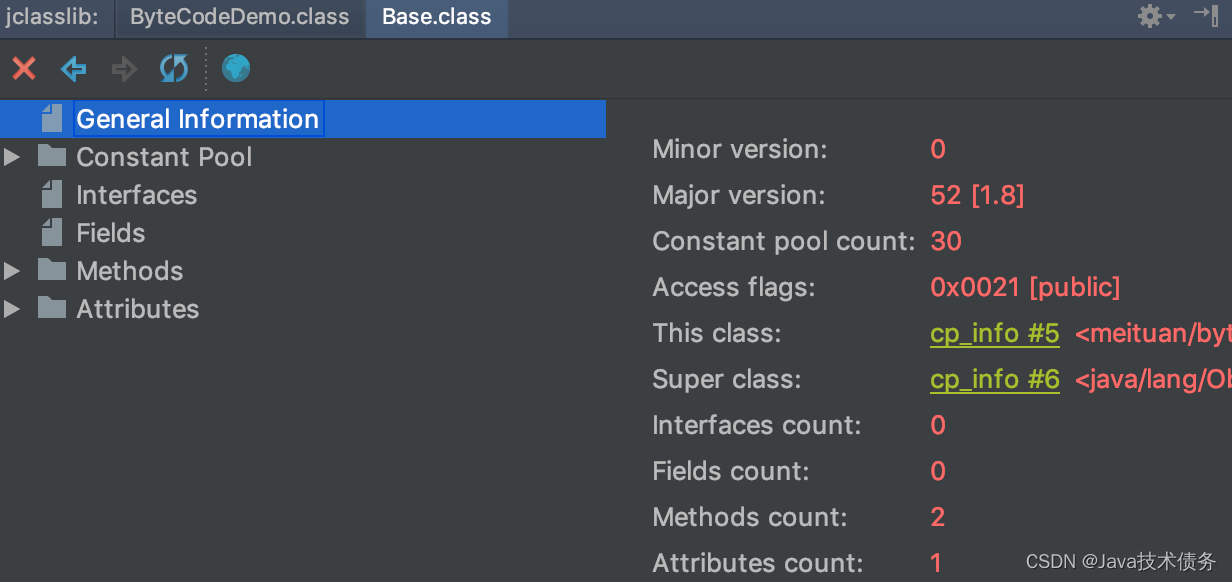
如果每次查看反编译后的字节码都使用javap命令的话,好非常繁琐。这里推荐一个Idea插件:jclasslib
。使用效果如图15所示,代码编译后在菜单栏”View”中选择”Show Bytecode With jclasslib”,可以很直观地看到当前字节码文件的类信息、常量池、方法区等信息。
--------------------------------------欢迎叨扰此地址---------------------------------------
本文作者:Java技术债务
原文链接:https://cuizb.top/myblog/article/1671634067
版权声明: 本博客所有文章除特别声明外,均采用 CC BY 3.0 CN协议进行许可。转载请署名作者且注明文章出处。
参考
- 字节码增强技术探索:https://tech.meituan.com/2019/09/05/java-bytecode-enhancement.html
- 一文看懂 JVM 内存布局及 GC 原理:https://www.infoq.cn/article/3wyretkqrhivtw4frmr3
- Oracle 官方说明文档:https://docs.oracle.com/javase/specs/jvms/se16/html/jvms-4.html#jvms-4.10
- Oracle 官方指令文档:https://docs.oracle.com/javase/specs/jvms/se16/html/jvms-6.html