博文开发测试环境:
- Unity:Unity 2022.3.10f1,URP 14.0.8,Burst 1.8.8,Jobs 0.70.0-preview.7,热更HybridCLR 4.0.6
- PC:Win11,CPU i7-13700KF,GPU 3070 8G,RAM 32G;
- 移动端:Android,骁龙8 gen2,RAM 12G;
上篇博文通过最基本的自定义BRG(Batch Renderer Group) + RVO避障实现了10万人同屏动态避障:【Unity】十万人同屏寻路? 基于Dots技术的多线程RVO2避障_TopGames的博客-CSDN博客
这里的BRG功能并不完善,不支持多种Mesh和Material渲染,没有拆分Batch,没有Culling处理,不会剔除相机视口外的物体。并且没有根据渲染数量拆分多个Draw Command。
BRG代码写起来并不容易,此博文基于Unity中国DOTS技术主管开源的一个BRG示例工程修改,这里仅描述主要的实现原理:
参考文章:Unity Open Day 北京站-技术专场:深入理解 Entities Gr - 技术专栏 - Unity官方开发者社区
BRG示例工程:
https://github.com/vinsli/batch-renderer![]() https://github.com/vinsli/batch-renderer
https://github.com/vinsli/batch-renderer
实现目标:
为了方便使用BRG功能,需要封装一个BatchRenderComponent脚本。不使用ECS,仅使用传统创建GameObject的方式与BRG无缝衔接,最大程度上不改变传统工作流的同时使用BRG合批渲染大幅提升性能;
其中GameObject是只有Transform组件的空物体,不使用Unity渲染组件,通过封装后的BatchRenderComponent进行合批渲染。
最终效果:
PC端5W人, AOT模式(不使用HybridCLR),开启阴影:

Android端5K人,AOT模式(不使用HybridCLR),开启阴影:
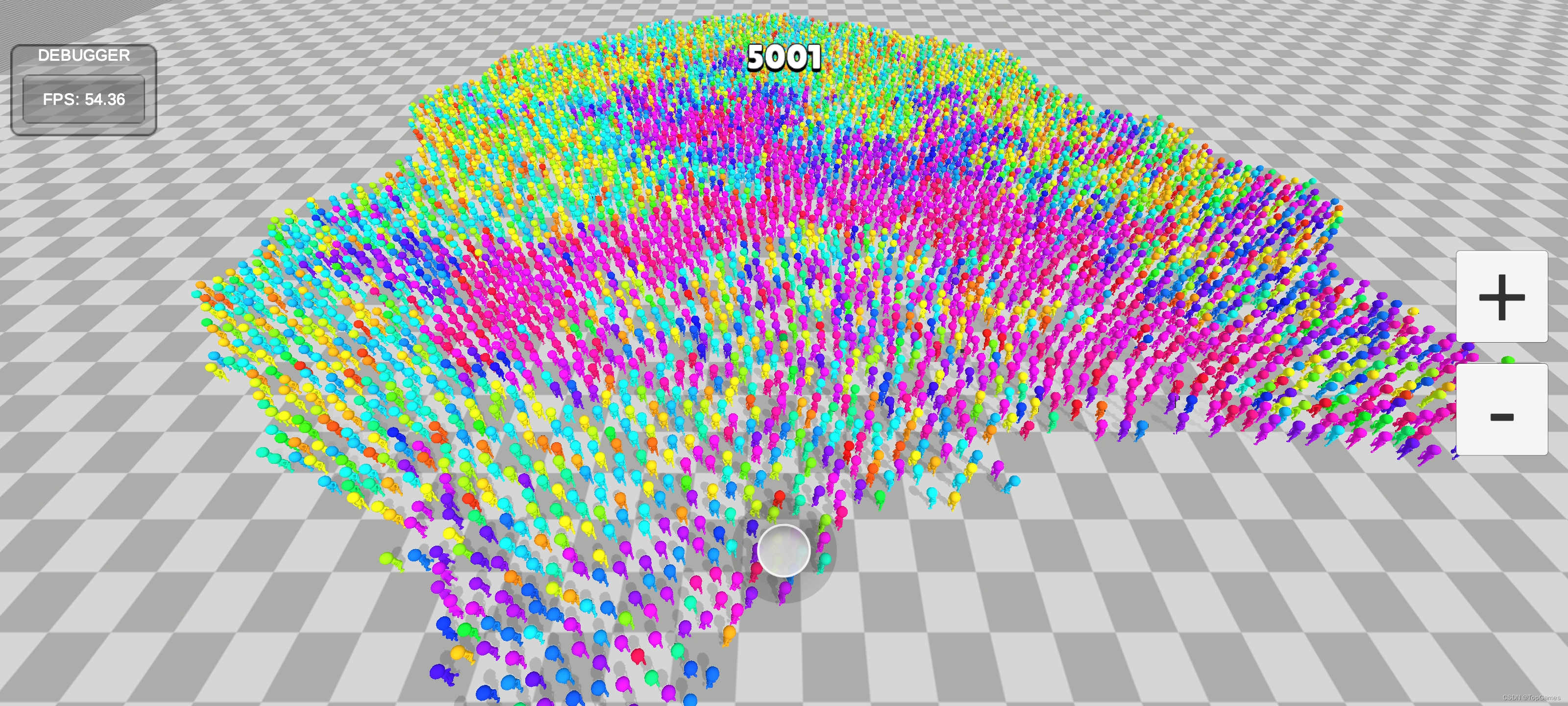
Android端5K人, HybridCLR热更模式,开启阴影:

由于HybridCLR不支持Burst加速,Jobs代码以解释方式执行,所以相比AOT性能大打折扣。
一,支持多Mesh/多Material
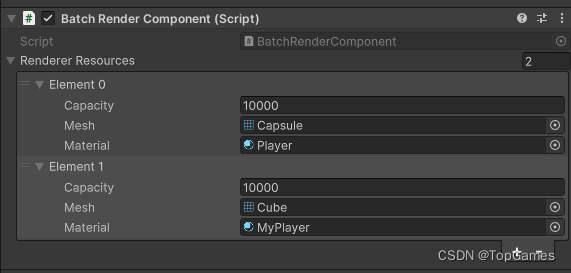
使用BRG必须开启SRP Batcher, SRP支持相同Material合批。因此支持多Material就需要根据不同Material拆分Batch,针对不同Material使用多个Batch渲染。
每个物体需要向GPU上传以下数据:
- 两个3x4矩阵,决定物体渲染的位置/旋转/缩放;
- _BaseColor,物体混合颜色;
- _ClipId, GPU动画id, 用于切换动画;
int objectToWorldID = Shader.PropertyToID("unity_ObjectToWorld");
int worldToObjectID = Shader.PropertyToID("unity_WorldToObject");
int colorID = Shader.PropertyToID("_BaseColor");
int gpuAnimClipId = Shader.PropertyToID("_ClipId");如果Shader还需要动态修改其它参数需要自行扩展,根据参数所占内存还需要重新组织内存分配;
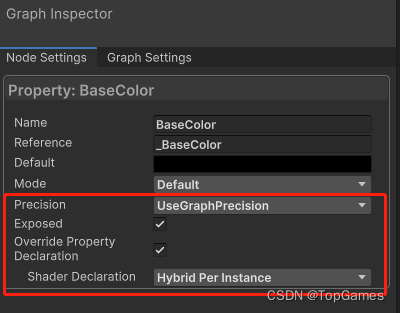
注意,必须在Shader Graph中把参数类型设置为Hybrid Per Installed,否则无法正常将数据传递给shader:
将每个物体依赖的数据组织成一个struct便于管理RendererNode,由于要在Jobs中使用所以必须为struct类型:
using Unity.Mathematics;
using static Unity.Mathematics.math;
using Unity.Burst;
[BurstCompile]
public struct RendererNode
{
public RendererNodeId Id { get; private set; }
public bool Enable
{
get
{
return active && visible;
}
}
/// <summary>
/// 是否启用
/// </summary>
public bool active;
/// <summary>
/// 是否在视口内
/// </summary>
public bool visible;
/// <summary>
/// 位置
/// </summary>
public float3 position;
/// <summary>
/// 旋转
/// </summary>
public quaternion rotation;
/// <summary>
/// 缩放
/// </summary>
public float3 localScale;
/// <summary>
/// 顶点颜色
/// </summary>
public float4 color;
/// <summary>
/// 动画id
/// </summary>
public float4 animClipId;
/// <summary>
/// Mesh的原始AABB(无缩放)
/// </summary>
public AABB unscaleAABB;
/// <summary>
/// 受缩放影响的AABB
/// </summary>
public AABB aabb
{
get
{
//var result = unscaleAABB;
//result.Extents *= localScale;
return unscaleAABB;
}
}
public bool IsEmpty
{
get
{
return unscaleAABB.Size.Equals(Unity.Mathematics.float3.zero);
}
}
public static readonly RendererNode Empty = new RendererNode();
public RendererNode(RendererNodeId id, float3 position, quaternion rotation, float3 localScale, AABB meshAABB)
{
this.Id = id;
this.position = position;
this.rotation = rotation;
this.localScale = localScale;
this.unscaleAABB = meshAABB;
this.color = float4(1);
this.active = false;
this.visible = true;
this.animClipId = 0;
}
/// <summary>
/// 构建矩阵
/// </summary>
/// <returns></returns>
[BurstCompile]
public float4x4 BuildMatrix()
{
return Unity.Mathematics.float4x4.TRS(position, rotation, localScale);
}
}
初始化渲染数据Buffer列表:
为了维护数据简单,并避免物体数量变化后频繁重新创建列表,所以根据RendererResource的Capacity大小,维护一个固定长度的列表。并且根据不同的RendererResource拆分多个渲染批次:
private void CreateRendererDataCaches()
{
m_BatchesVisibleCount.Clear();
int index = 0;
foreach (var rendererRes in m_RendererResources)
{
var drawKey = rendererRes.Key;
m_BatchesVisibleCount.Add(drawKey, 0);
NativeList<int> perBatchNodes;
if (!m_DrawBatchesNodeIndexes.ContainsKey(drawKey))
{
perBatchNodes = new NativeList<int>(2048, Allocator.Persistent);
m_DrawBatchesNodeIndexes.Add(drawKey, perBatchNodes);
NativeQueue<BatchDrawCommand> batchDrawCommands = new NativeQueue<BatchDrawCommand>(Allocator.Persistent);
m_BatchDrawCommandsPerDrawKey.Add(drawKey, batchDrawCommands);
}
else
{
perBatchNodes = m_DrawBatchesNodeIndexes[drawKey];
}
for (int i = 0; i < rendererRes.capacity; i++)
{
var color = SpawnUtilities.ComputeColor(i, rendererRes.capacity);
var aabb = rendererRes.mesh.bounds.ToAABB();
var node = new RendererNode(new RendererNodeId(drawKey, index), Unity.Mathematics.float3.zero, Unity.Mathematics.quaternion.identity, float3(1), aabb);
node.color = color;
perBatchNodes.Add(index);
m_AllRendererNodes[index++] = node;
}
}
}组织拆分后每个Batch的数据:
由于不同硬件性能不同,单个Draw Command数量是有上限的,所以还需要根据渲染数量拆分至多个BatchDrawCommand。
private void GenerateBatches()
{
#if UNITY_ANDROID || UNITY_IOS
int kBRGBufferMaxWindowSize = 16 * 256 * 256;
#else
int kBRGBufferMaxWindowSize = 16 * 1024 * 1024;
#endif
const int kItemSize = (2 * 3 + 2); //每个物体2个3*4矩阵,1个颜色值,1个动画id,内存大小共8个float4
m_MaxItemPerBatch = ((kBRGBufferMaxWindowSize / kSizeOfFloat4) - 4) / kItemSize; // -4 "float4" for 64 first 0 bytes ( BRG contrainst )
// if (_maxItemPerBatch > instanceCount)
// _maxItemPerBatch = instanceCount;
foreach (var drawKey in m_DrawBatchesNodeIndexes.GetKeyArray(Allocator.Temp))
{
if (!m_BatchesPerDrawKey.ContainsKey(drawKey))
{
m_BatchesPerDrawKey.Add(drawKey, new NativeList<int>(128, Allocator.Persistent));
}
var instanceCountPerDrawKey = m_DrawBatchesNodeIndexes[drawKey].Length;
m_WorldToObjectPerDrawKey.Add(drawKey, new NativeArray<float4>(instanceCountPerDrawKey * 3, Allocator.Persistent));
m_ObjectToWorldPerDrawKey.Add(drawKey, new NativeArray<float4>(instanceCountPerDrawKey * 3, Allocator.Persistent));
var maxItemPerDrawKeyBatch = m_MaxItemPerBatch > instanceCountPerDrawKey ? instanceCountPerDrawKey : m_MaxItemPerBatch;
//gather batch count per drawkey
int batchAlignedSizeInFloat4 = BufferSizeForInstances(kBytesPerInstance, maxItemPerDrawKeyBatch, kSizeOfFloat4, 4 * kSizeOfFloat4) / kSizeOfFloat4;
var batchCountPerDrawKey = (instanceCountPerDrawKey + maxItemPerDrawKeyBatch - 1) / maxItemPerDrawKeyBatch;
//create instance data buffer
var instanceDataCountInFloat4 = batchCountPerDrawKey * batchAlignedSizeInFloat4;
var instanceData = new GraphicsBuffer(GraphicsBuffer.Target.Raw, GraphicsBuffer.UsageFlags.LockBufferForWrite, instanceDataCountInFloat4, kSizeOfFloat4);
m_InstanceDataPerDrawKey.Add(drawKey, instanceData);
//generate srp batches
int left = instanceCountPerDrawKey;
for (int i = 0; i < batchCountPerDrawKey; i++)
{
int instanceOffset = i * maxItemPerDrawKeyBatch;
int gpuOffsetInFloat4 = i * batchAlignedSizeInFloat4;
var batchInstanceCount = left > maxItemPerDrawKeyBatch ? maxItemPerDrawKeyBatch : left;
var drawBatch = new SrpBatch
{
DrawKey = drawKey,
GraphicsBufferOffsetInFloat4 = gpuOffsetInFloat4,
InstanceOffset = instanceOffset,
InstanceCount = batchInstanceCount
};
m_BatchesPerDrawKey[drawKey].Add(m_DrawBatches.Length);
m_DrawBatches.Add(drawBatch);
left -= batchInstanceCount;
}
}
int objectToWorldID = Shader.PropertyToID("unity_ObjectToWorld");
int worldToObjectID = Shader.PropertyToID("unity_WorldToObject");
int colorID = Shader.PropertyToID("_BaseColor");
int gpuAnimClipId = Shader.PropertyToID("_ClipId");
var batchMetadata = new NativeArray<MetadataValue>(4, Allocator.Temp, NativeArrayOptions.UninitializedMemory);
for (int i = 0; i < m_DrawBatches.Length; i++)
{
var drawBatch = m_DrawBatches[i];
var instanceData = m_InstanceDataPerDrawKey[drawBatch.DrawKey];
var baseOffset = drawBatch.GraphicsBufferOffsetInFloat4 * kSizeOfFloat4;
int gpuAddressOffset = baseOffset + 64;
batchMetadata[0] = CreateMetadataValue(objectToWorldID, gpuAddressOffset, true); // matrices
gpuAddressOffset += kSizeOfPackedMatrix * drawBatch.InstanceCount;
batchMetadata[1] = CreateMetadataValue(worldToObjectID, gpuAddressOffset, true); // inverse matrices
gpuAddressOffset += kSizeOfPackedMatrix * drawBatch.InstanceCount;
batchMetadata[2] = CreateMetadataValue(colorID, gpuAddressOffset, true); // colors
gpuAddressOffset += kSizeOfFloat4 * drawBatch.InstanceCount;
batchMetadata[3] = CreateMetadataValue(gpuAnimClipId, gpuAddressOffset, true);
if (BatchRendererGroup.BufferTarget == BatchBufferTarget.ConstantBuffer)
{
drawBatch.BatchID = m_BRG.AddBatch(batchMetadata, instanceData.bufferHandle, (uint)BatchRendererGroup.GetConstantBufferOffsetAlignment(), (uint)BatchRendererGroup.GetConstantBufferMaxWindowSize());
}
else
{
drawBatch.BatchID = m_BRG.AddBatch(batchMetadata, instanceData.bufferHandle);
}
m_DrawBatches[i] = drawBatch;
}
}二,Culling剔除视口外物体渲染
使用Jobs判定物体AABB包围盒是否在相机视口内,把视口外RendererNode的visible标记为false
[BurstCompile]
private unsafe struct CullingJob : IJobParallelFor
{
[ReadOnly]
public NativeArray<Plane> CullingPlanes;
[DeallocateOnJobCompletion]
[ReadOnly]
public NativeArray<SrpBatch> Batches;
[ReadOnly]
public NativeArray<RendererNode> Nodes;
[ReadOnly]
public NativeList<int> NodesIndexes;
[ReadOnly]
[NativeDisableContainerSafetyRestriction]
public NativeArray<float4> ObjectToWorldMatrices;
[ReadOnly]
public int DrawKeyOffset;
[WriteOnly]
[NativeDisableUnsafePtrRestriction]
public int* VisibleInstances;
[WriteOnly]
public NativeQueue<BatchDrawCommand>.ParallelWriter DrawCommands;
public void Execute(int index)
{
var batchesPtr = (SrpBatch*)Batches.GetUnsafeReadOnlyPtr();
var objectToWorldMatricesPtr = (float4*)ObjectToWorldMatrices.GetUnsafeReadOnlyPtr();
ref var srpBatch = ref batchesPtr[index];
int visibleCount = 0;
int batchOffset = DrawKeyOffset + srpBatch.InstanceOffset;
int idx = 0;
for (int instanceIdx = 0; instanceIdx < srpBatch.InstanceCount; instanceIdx++)
{
idx = srpBatch.InstanceOffset + instanceIdx;
int nodeIndex = NodesIndexes[idx];
var node = Nodes[nodeIndex];
if (!node.active) continue;
//Assume only have 1 culling split and have 6 culling planes
var matrixIdx = idx * 3;
var worldAABB = Transform(ref objectToWorldMatricesPtr[matrixIdx], ref objectToWorldMatricesPtr[matrixIdx + 1], ref objectToWorldMatricesPtr[matrixIdx + 2], node.aabb);
if (!(node.visible = (Intersect(CullingPlanes, ref worldAABB) != FrustumPlanes.IntersectResult.Out)))
continue;
VisibleInstances[batchOffset + visibleCount] = instanceIdx;
visibleCount++;
}
if (visibleCount > 0)
{
var drawKey = srpBatch.DrawKey;
DrawCommands.Enqueue(new BatchDrawCommand
{
visibleOffset = (uint)batchOffset,
visibleCount = (uint)visibleCount,
batchID = srpBatch.BatchID,
materialID = drawKey.MaterialID,
meshID = drawKey.MeshID,
submeshIndex = (ushort)drawKey.SubmeshIndex,
splitVisibilityMask = 0xff,
flags = BatchDrawCommandFlags.None,
sortingPosition = 0
});
}
}
}三,添加/移除渲染物体:
添加Renderer,实际上就是从RendererNode列表中找出空闲的RendererNode用来存放数据。
移除Renderer,就是把RendererNode的active设置为false置为空闲状态
public RendererNodeId AddRenderer(int resourceIdx, float3 pos, quaternion rot, float3 scale)
{
if (resourceIdx < 0 || resourceIdx >= m_RendererResources.Count)
{
return RendererNodeId.Null;
}
var rendererRes = m_RendererResources[resourceIdx];
var nodesIndexes = m_DrawBatchesNodeIndexes[rendererRes.Key];
var tempOutputs = new NativeList<int>(Allocator.TempJob);
var jobs = new GetInvisibleRendererNodeJob
{
Nodes = m_AllRendererNodes,
NodesIndexes = nodesIndexes,
RequireCount = 1,
Outputs = tempOutputs
};
jobs.Schedule().Complete();
if (jobs.Outputs.Length < 0)
{
Log.Warning("添加Renderer失败, Output Index invaluable");
tempOutputs.Dispose();
return RendererNodeId.Null;
}
int index = jobs.Outputs[0];
tempOutputs.Dispose();
var renderer = m_AllRendererNodes[index];
renderer.position = pos;
renderer.rotation = rot;
renderer.localScale = scale;
renderer.active = true;
m_AllRendererNodes[index] = renderer;
m_BatchesVisibleCount[rendererRes.Key]++;
m_TotalVisibleCount++;
return renderer.Id;
}
/// <summary>
/// 移除渲染节点
/// </summary>
/// <param name="id"></param>
public void RemoveRenderer(RendererNodeId id)
{
var node = m_AllRendererNodes[id.Index];
node.active = false;
m_AllRendererNodes[id.Index] = node;
m_BatchesVisibleCount[id.BatchKey]--;
m_TotalVisibleCount--;
}
[BurstCompile]
private struct GetInvisibleRendererNodeJob : IJob
{
[ReadOnly]
public NativeArray<RendererNode> Nodes;
[ReadOnly]
public NativeList<int> NodesIndexes;
[ReadOnly]
public int RequireCount;
public NativeList<int> Outputs;
public void Execute()
{
int num = 0;
for (int i = 0; i < NodesIndexes.Length; i++)
{
int curIndex = NodesIndexes[i];
var node = Nodes[curIndex];
if (!node.Enable)
{
Outputs.Add(curIndex);
if (++num >= RequireCount)
{
break;
}
}
}
}
}四,同步RVO位置数据到RendererNode:
由于已经把所有RendererNode组织到了一个NativeArray里,所以可以非常容易得使用Jobs批量同步渲染位置、旋转等信息;
/// <summary>
/// 通过JobSystem更新渲染数据
/// </summary>
/// <param name="agents"></param>
internal void SetRendererData(NativeArray<AgentData> agentsData)
{
var job = new SyncRendererNodeTransformJob
{
AgentDataArr = agentsData,
Nodes = m_AllRendererNodes
};
job.Schedule(agentsData.Length, 64).Complete();
}
[BurstCompile]
private struct SyncRendererNodeTransformJob : IJobParallelFor
{
[ReadOnly] public NativeArray<AgentData> AgentDataArr;
[NativeDisableParallelForRestriction]
public NativeArray<RendererNode> Nodes;
public void Execute(int index)
{
var agentDt = AgentDataArr[index];
var node = Nodes[agentDt.rendererIndex];
node.position = agentDt.worldPosition;
node.rotation = agentDt.worldQuaternion;
node.animClipId = agentDt.animationIndex;
Nodes[agentDt.rendererIndex] = node;
}
}未完待续...
![[SWPUCTF 2022 新生赛]善哉善哉题目解析](https://img-blog.csdnimg.cn/4412e055a07c40d0999c151473c7b848.png)







![练[BJDCTF2020]EasySearch](https://img-blog.csdnimg.cn/img_convert/fd76e2bd0f3b7135b9b21a79bd79cd22.png)