文章目录
- MVDiffusion
- 1. 自回归 生成 全景图
- 1.1 错误积累
- 1.2 角度变换大
- 2. 模型结构
- 2.1 多视图潜在扩散模型(mutil-view LDM)
- 2.1.1 Text-conditioned generation model
- 2.1.2 Image&text-conditioned generation model
- 2.1.3 额外的卷积层
- 2.2 Correspondence-aware Attention(CAA)
- 3. Train 阶段
- 3.1 全景生成任务
- 3.2 多视图图像生成任务
- 4. 应用场景
- 5. 代码部分
MVDiffusion
论文链接:https://arxiv.org/pdf/2307.01097.pdf
项目地址:https://huggingface.co/spaces/tangshitao/MVDiffusion
代码仓库:https://github.com/Tangshitao/MVDiffusion
MVDiffusion的目标是产生内容高度一致且全局语义统一的多视角图片,其方法的核心思想是同步去噪(simultaneous denoising)和基于图片之间对应关系的全局意识(global awareness)。
1. 自回归 生成 全景图
自回归生成过程时,可以将其类比为一种逐步构建图像的方式。其中第n个图像的生成取决于第n-1图像,通过图像变形和修复技术来实现。这种自回归方法会导致 错误的累积,并且 不能处理循环闭合。
1.1 错误积累
构建一张全景图:
- 通过文本描述生成视图A
- 基于视图A的内容进行变形和修复,进而生成视图B
- 参照前一张图片,持续过程2
例如,在视图A中有一张桌子;生成B时,可能会将桌子的一部分移到另一个位置,以模拟从不同角度看到的效果。这个过程会一直持续,生成视图C、D、E,以及其他可能的视图,每次都依赖于前一个视图。如果在视图A中对桌子的变形不准确,那么这个错误将在生成视图B、C、D等时逐渐累积,导致最终的多视图图像可能看起来不真实或不连贯。这就是所谓的"错误累积"问题。
1.2 角度变换大
视图之间的角度变化很大,比如从一个房间的一侧到另一侧,那么自回归方法可能会遇到困难。
因为它依赖于前一个视图,要正确地生成从一个角度到另一个角度的视图,需要处理复杂的角度变化和背景内容的改变,这可能会导致生成的结果不准确。
2. 模型结构
全景图像是由8张重叠的透视图像组成的。每一对相邻的图像之间,像素之间的对应关系是通过一个3x3的单应矩阵来确定的。在全景图像中,不同的透视图像需要通过这个矩阵来进行像素级的对应,以便它们能够正确地拼接在一起,形成一个连续的全景图。
在文中,水平视场角为90度,这意味着每两张连续的图像之间有45度的重叠。这种设置通常用于全景图像拼接,其中每张图像捕获了一个广阔的水平视野,并且为了确保图像之间的连续性,它们有一定的重叠部分,以便在拼接时能够正确对齐。
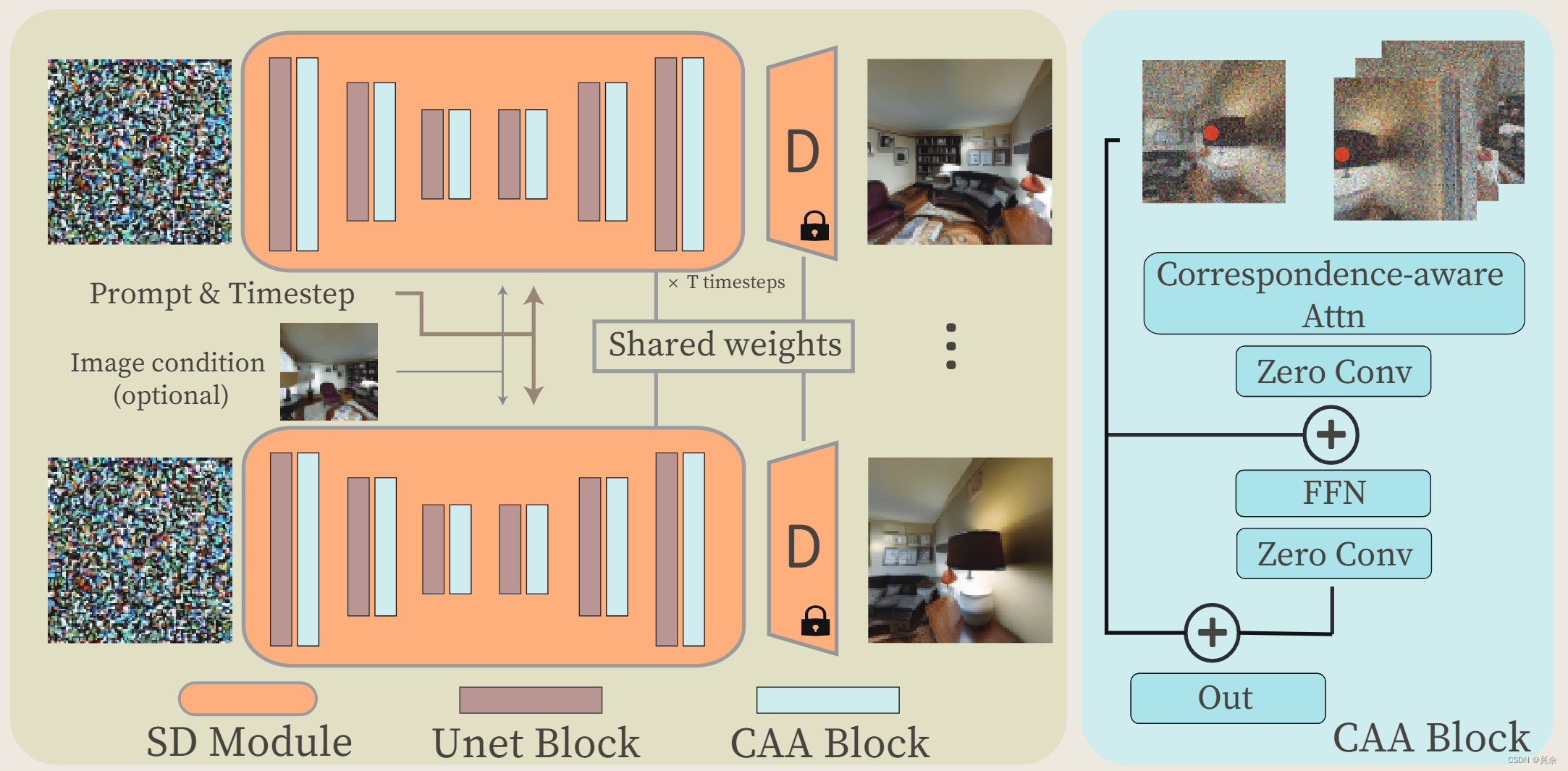
- 多视图图像的潜变量同时(即并行)通过共享的UNet进行去噪。
- 将新的对应感知注意(CAA)块插入到UNet中,学习跨视图几何一致性,实现全局感知。
2.1 多视图潜在扩散模型(mutil-view LDM)
MVDiffusion设计了两种模型变体。文本条件的生成模型将文本提示作为条件;图像和文本条件的生成模型将文本提示以及一个或两个附加源图像作为条件。
全景图生成
根据用户输入的类型,将只使用两个模型中的一个。
- 如果只提供文本,文本条件模型将并行生成八个多视图。
- 如果提供了附加的源视图,则文本和图像条件模型可以考虑图像和文本条件,从而生成七个多视图。
多视图深度到图像生成
文本条件生成模型首先 将稀疏的深度图集子采样为“关键帧” 并生成纹理图像。然后,图像和文本条件模型 就像 插值模型一样,它以两个连续的关键帧图像作为附加条件,生成中间的图像。这些生成的图像应该与深度图和两个条件图像一致,同时还与文本提示对齐。
2.1.1 Text-conditioned generation model
对于全景图像生成任务,图像分辨率为512×512,而对于多视图深度到图像的任务,图像分辨率为192×256。
全景图生成
多个图像的潜在表示(latent)使用独立的高斯噪声进行初始化。在每个去噪步骤中,这些带噪声的潜在表示被送入多分支的UNet,以同时对所有多视图的潜在表示进行去噪。
生成全景图像需要同时合成多个视图,以覆盖整个全景。这可能需要更高的图像分辨率512 ×512,以确保生成的图像在细节上足够清晰,并且不会出现明显的像素化。
CAA块的使用:
SD UNet包括多个下采样和上采样块,每个块都伴随着一个CAA块,用于强化多视图一致性。CAA块的作用是确保生成的多视图图像在外观和几何上保持一致。
CAA块初始化:
将CAA块的最终线性层初始化为零,这是根据ControlNet 的建议,以确保修改不会破坏SD模型的原始功能。
多视图深度到图像生成
从深度信息生成多个视图,通常用于文本生成多视图图像。相对于全景图像,这个任务可能对图像分辨率的要求较低,因为生成的图像通常不需要涵盖整个全景。
2.1.2 Image&text-conditioned generation model
全景图生成
在这个任务中,图像&文本条件生成模型的目标是基于单个透视图像(一个条件图像)和每个视角的文本提示生成完整的360度全景视图(七个目标图像)。
在生成全景图像时,模型需要使用一个条件图像作为参考,以便在生成新视角的图像时保留一些内容的一致性。
为了做到这一点,将一个由1组成的掩码连接到条件图像的通道中,这样掩码的像素值就变成了1,而条件图像的原始像素值则保持不变 (改变阿尔法通道)。这个操作将条件图像与生成的图像的一些像素对应起来,以确保在新生成的图像中保留了与条件图像相同的内容。
在目标图像的UNet分支中,我们将一个由零值像素组成的黑色图像与一个由零组成的掩码连接在一起作为输入,因此需要修复模型基于文本条件和与条件图像的对应关系生成全新的图像。
多视图深度到图像生成
这个任务中的目标是在文本条件生成模型生成的关键帧图像之间进行稠密化,并且附加条件是一对关键帧图像。由于SD的图像修复模型不支持深度条件,因此我们必须在这里采用不同的方法。
受到VideoLDM的启发,我们重用了深度条件UNet,该UNet带有CAA块,来自文本条件生成模型,已经训练用于生成给定深度图和相机姿态的稀疏关键帧图像。额外的卷积层被插入以注入两个条件图像的信息。
2.1.3 额外的卷积层
条件图像分支(两个条件图像)
首先,将条件图像本身与一个由1组成的掩码(总共4个通道)连接起来。然后,使用零卷积操作来降采样连接后的图像,使其与UNet块的特征图大小相匹配。降采样后的条件图像与UNet块的输入相加。这个过程的目的是训练模型,当掩码为1时,分支可以重新生成条件图像;而当掩码为0时,分支可以生成两者之间的目标图像。这种方法通过卷积层的操作,使模型能够根据掩码的不同值来执行不同的生成任务。
目标图像分支
对于目标图像分支,将一个由零值像素组成的黑色图像与一个由零组成的掩码连接在一起,然后使用相同的零卷积操作来降采样图像,使其与UNet块的特征图大小相匹配。降采样后的条件图像与UNet块的输入相加。这个过程的目的与条件图像分支类似,根据掩码的值来执行不同的生成任务,其中掩码为1时生成条件图像,为0时生成目标图像。
零卷积操作通常用于降采样或上采样中的填充操作,它的作用是将输入的特征图的分辨率减小到与UNet块期望的特征图大小相匹配。
2.2 Correspondence-aware Attention(CAA)
(CAA)机制是 MVDiffusion 在多视图特征图之间强制对应约束的关键。
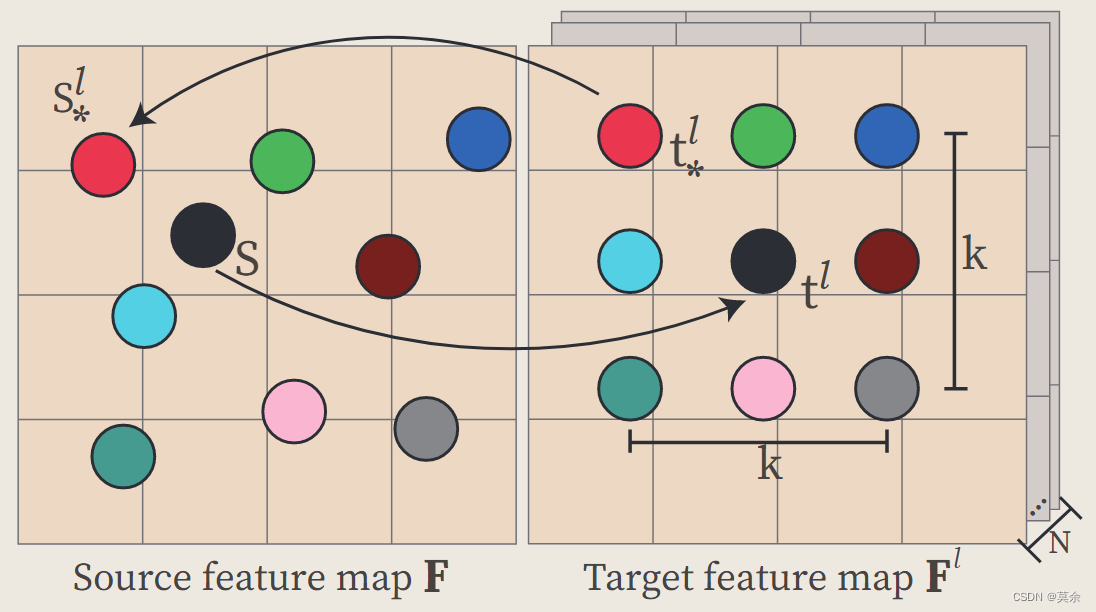
相关原理这里就不过多解释了,直接看原文吧。这里举个简单易懂的例子吧。
假设正在生成一个全景图像,其中包括 8 个透视图像。对于 CAA,我们关注其中一个像素位置( S S S)在源特征图中,现在我们想要计算这个像素与目标特征图(8 个透视图像的其中一个)之间的注意力。
- 首先,我们选择一个目标特征图( F l F^l Fl),然后选择目标图像中的一个像素位置( t l t^l tl)
- 在这个位置附近形成一个局部邻域,假设 k = 3 k=3 k=3 考虑以目标像素 t l t^l tl 为中心的 3x3 邻域
- 对于源特征图中的像素位置( s s s)计算一个消息( m m m),该消息利用源特征图中的信息与目标特征图中的 t l t^l tl以及其周围的像素进行交互
- 消息 m 帮助我们确定在生成目标图像的过程中,如何受到源图像中相应位置的影响。
3. Train 阶段
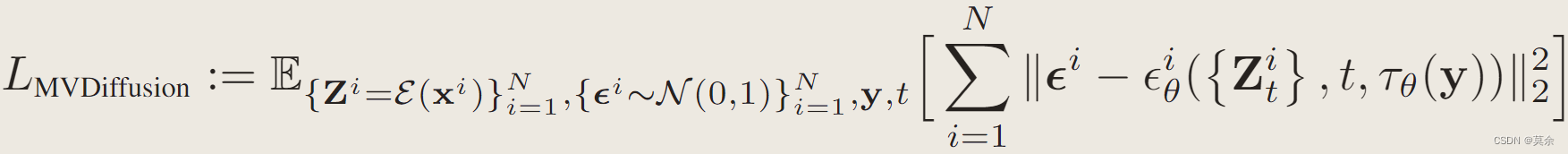
ϵ
θ
i
{\epsilon_\theta^i}
ϵθi 表示第 i 个图像的估计噪声。
Z
t
i
Z_t^i
Zti是第 i 张图像的噪声潜在值。由于训练数据集远小于 SD 模型的预训练数据集,因此尽可能地冻结训练中的原始 SD 参数以保留原始泛化能力。
3.1 全景生成任务
只训练插入的 CAA 块。
3.2 多视图图像生成任务
(与原始 SD 的 512 × 512 相比,这部分任务的分辨率为192 × 256),SD 模型必须进行微调。
在第一阶段,我们使用所有ScanNet数据微调SD UNet模型,以调整分辨率。此阶段是没有 CAA 块的单视图训练(等式 1)。
在第二阶段,我们将CAA块和图像条件块集成到UNet中,只训练这些添加的参数。
4. 应用场景
全景生成 and 多角度深度图像生成
在使用过程中,推荐使用ChatGPT进行强化https://huggingface.co/spaces/tangshitao/MVDiffusion。
Text:
This bedroom is a harmonious fusion of classic and contemporary elements. It boasts a spacious reclaimed wood bed frame with a plush upholstered headboard, creating a cozy yet stylish centerpiece. On one side of the bed, there's a sleek modern nightstand with a minimalist lamp, while on the other side, a vintage-inspired dresser adds a touch of timeless charm. The color palette is soothing, with soft neutral tones that promote relaxation. Sunlight filters in through sheer curtains, casting a gentle glow on the room. This bedroom offers a perfect balance between comfort and elegance, making it an inviting space for rest and relaxation.

5. 代码部分
由于dropbox官网的预训练权重确实比较难下载,我将把权重放至网盘链接,稍后给出。
亮点工作的CAA机制代码详解后期更新……



![练[BJDCTF2020]EasySearch](https://img-blog.csdnimg.cn/img_convert/fd76e2bd0f3b7135b9b21a79bd79cd22.png)




![2023年中国铁路通信系统发展历程、市场规模及行业发展趋势分析[图]](https://img-blog.csdnimg.cn/img_convert/c45e59bf08107457a33ba9cec9b5e33a.png)