论文地址:https://arxiv.org/pdf/2306.14289.pdf
代码地址:https://github.com/ChaoningZhang/MobileSAM
一、概要简介
SAM是一种prompt-guided的视觉基础模型,用于从其背景中剪切出感兴趣的对象。自Meta研究团队发布SA项目以来,SAM因其令人印象深刻的零样本传输性能和与其他模型兼容的高度通用性而备受关注,用于高级视觉应用,如具有细粒度控制的图像编辑。

许多这样的用例需要在资源受限的边缘设备上运行,比如移动应用程序。今天分享中,我们的目标是通过用轻量级图像编码器取代重量级图像编码器,使SAM对移动友好。原始SAM文件中训练这种新SAM的方式会导致性能不令人满意,尤其是当可用的训练来源有限时。
我们发现,这主要是由图像编码器和掩模解码器的耦合优化引起的,因此提出了解耦蒸馏。具体地说,将原始SAM中的图像编码器ViT-H的知识提取到一个轻量级的图像编码器中,该编码器可以自动与原始SAM中的掩码解码器兼容。
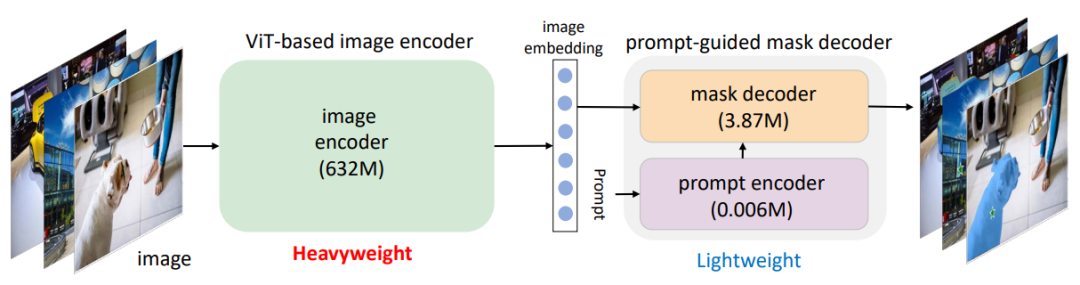
The overview of Segment Anything Model
Parameters SAM with different image encoders

训练可以在不到一天的时间内在单个GPU上完成,由此产生的轻量级SAM被称为MobileSAM,它比原始SAM小60多倍,但性能与原始SAM相当。就推理速度而言,MobileSAM每幅图像运行约10ms:图像编码器运行8ms,掩码解码器运行2ms。凭借卓越的性能和更高的通用性,我们的MobileSAM比并发的FastSAM小7倍,快4倍,更适合移动应用。
二、新框架
1.Background on SAM
在这里,我们首先总结SAM的结构及其工作原理。SAM由一个基于ViT的图像编码器和一个提示引导掩码解码器组成。图像编码器将图像作为输入并生成嵌入,然后将嵌入提供给掩码解码器。掩码解码器生成一个掩码,根据点(或框)等提示从背景中剪切出任何对象。此外,SAM允许为同一提示生成多个掩码,以解决模糊性问题,这提供了宝贵的灵活性。考虑到这一点,这项工作保持了SAM的流水线,首先采用基于ViT的编码器来生成图像嵌入,然后采用提示引导解码器来生成所需的掩码。这条管道是为“分段任何东西”而优化设计的,可用于“分段所有东西”的下游任务。
SAM的耦合知识蒸馏。左图表示完全耦合蒸馏,右图表示半耦合蒸馏。
2.Project goal
该项目的目标是生成一个移动友好型SAM(MobileSAM),以轻量级的方式实现令人满意的性能,并且比原始SAM快得多。原始SAM中的提示引导掩码解码器的参数小于4M,因此被认为是轻量级的。给定编码器处理的图像嵌入,如他们的公开演示中所示,SAM可以在资源受限的设备中工作,因为掩码解码器是轻量级的。然而,原始SAM中的默认图像编码器是基于ViT-H的,具有超过600M的参数,这是非常重量级的,并使整个SAM管道与移动设备不兼容。因此,获得移动友好SAM的关键在于用轻量级的图像编码器取代重量级的图像编码器,这也自动保持了原始SAM的所有功能和特性。
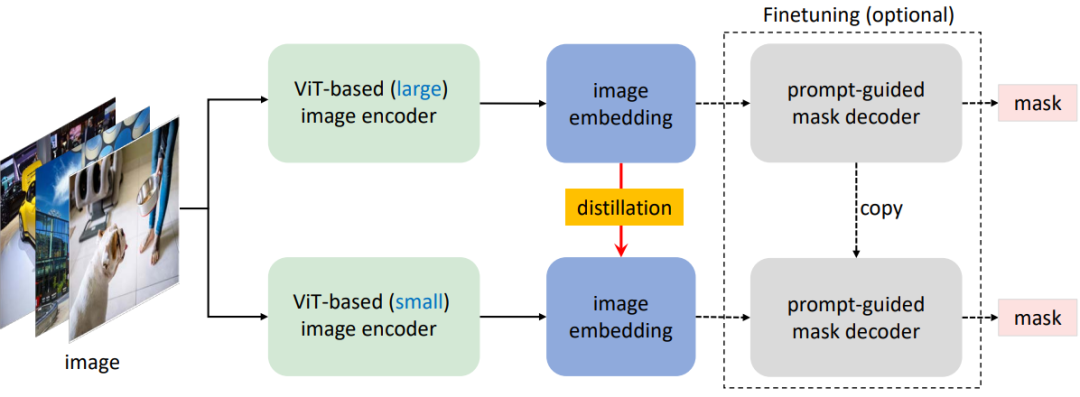
Decoupled distillation for SAM

以ViT-B为图像编码器的SAM的耦合蒸馏和解耦蒸馏的比较。与耦合蒸馏相比,解耦蒸馏性能更好,所需计算资源少于1%。
三、实验
下图给出了point与bbox提示词下MobileSAM与原生SAM的结果对比,可以看到:MobileSAM可以取得令人满意的Mask预测结果。


下图从Segment everything角度对比了SAM、FastSAM以及MobileSAM三个模型,可以看到:
-
MobileSAM与原生SAM结果对齐惊人的好,而FastSAM会生成一些无法满意的结果
-
FastSAM通常生成非平滑的边缘,而SAM与MobileSAM并没有该问题