数据结构与算法-前缀树详解
- 1 何为前缀树
- 2 前缀树的代码表示及相关操作
1 何为前缀树
前缀树 又称之为字典树,是一种多路查找树,多路树形结构,是哈希树的变种,和hash效率有一拼,是一种用于快速检索的多叉树结构。
性质:不同字符串的相同前缀只保存一份。
操作:查找,插入,删除
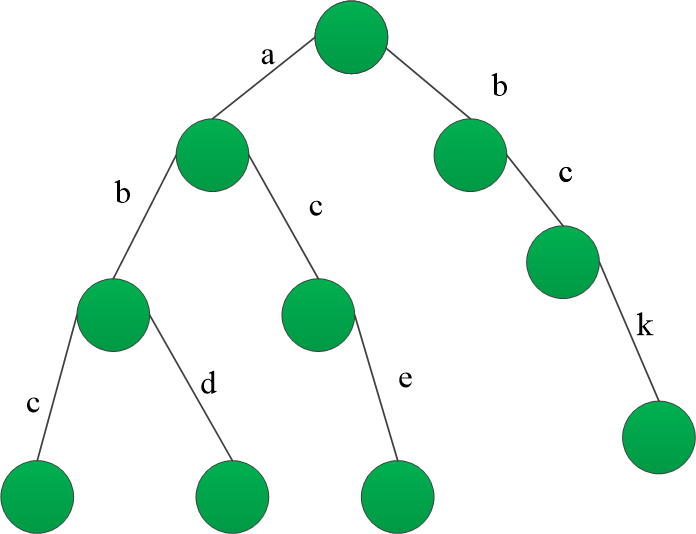
例如 字符数组
[“abc”,“bck”,“abd”,“ace”]
构建成一颗前缀树
2 前缀树的代码表示及相关操作
前缀树中的节点
coding
public static class TrieNode {
public int pass;//前缀树节点被经过的次数
public int end;// 多少个字符串在此点结尾
public TrieNode[] nexts;// 下一个节点
// 当字符种类很多的时候 可以使用HashMap
// public Map<Character,TrieNode> trieNodeMap;// key 某条图 value 指向的下一个节点
public TrieNode(){
// trieNodeMap = new HashMap<>();//无序使用Hash表
// trieNodeMap = new TreeMap<>();// 有序使用有序表
this.pass = 0;
this.end = 0;
nexts = new TrieNode[26];
}
}
前缀树代码表示及相关操作
public static class Trie {
private TrieNode root;//头结点
public Trie() {
this.root = new TrieNode();
}
/**
* 将字符串word加入到前缀树中
*
* @param word
*/
public void insert(String word) {
if (word == null) {
return;
}
char[] chars = word.toCharArray();
TrieNode node = root;
node.pass++;
int index = 0;
// 从左往右遍历字符串
for (int i = 0; i < chars.length; ++i) {
// 由字符计算得出 该走哪条路
index = chars[i] - 'a';
//如果没有此字符的路 则新建
if (node.nexts[index] == null) {
node.nexts[index] = new TrieNode();
}
//来到下一个节点
node = node.nexts[index];
node.pass++;
}
node.end++;
}
/**
* @param word
* @return 字符串在前缀树中加入过几次
*/
public int search(String word) {
if (word == null) {
return 0;
}
// 临时前缀树节点 用于遍历前缀树
TrieNode node = root;
char[] chars = word.toCharArray();
int index = 0;
for (int i = 0; i < chars.length; ++i) {
index = chars[i] - 'a';
// 没有通往当前字符串的路 则说明没有加入过这个字符串 直接返回 0
if (node.nexts[index] == null) {
return 0;
}
// 下一个节点
node = node.nexts[index];
}
// 所有字符的路都有 则返回最后一个节点的 end 值
return node.end;
}
/**
* @param pre
* @return 有多少个字符串是以 pre开头的
*/
public int prefixNumber(String pre) {
if (pre == null) {
return 0;
}
TrieNode node = root;
int index = 0;
char[] chars = pre.toCharArray();
for (int i = 0; i < chars.length; ++i) {
index = chars[i] - 'a';
if (node.nexts[index] == null) {
return 0;
}
node = node.nexts[index];
}
return node.pass;
}
/**
* 删除前缀树中的字符串word
*
* @param word
*/
public void delete(String word) {
if (search(word) != 0) { // 前缀树中存在字符串再删除
char[] chars = word.toCharArray();
TrieNode node = root;
node.pass--;
int index = 0;
// 遍历每一个节点 将节点的pass值减 1
for (int i = 0; i < chars.length; ++i) {
index = chars[i] - 'a';
if (--node.nexts[index].pass == 0) {
node.nexts[index] = null;
return;
}
node = node.nexts[index];
}
node.end--;
}
}
}