文章目录
- 1.安装JDK 环境
- 2.系统配置
- 2.1修改本地hosts文件
- 2.2创建hadoop 用户
- 2.2 设置ssh免密(使用hadoop 用户生成)
- 3.安装 hadoop 3.2.4
- 3.1 安装hadoop
- 3.1.1 配置Hadoop 环境变量
- 3.2配置 HDFS
- 3.2.1 配置 workers 文件
- 3.2.2 配置hadoop-env.sh
- 3.2.3 配置core-site.xml
- 3.2.3 配置 hdfs-site.xml
- 3.2.4 启动hdfs
- 3.3 配置MapReduce
- 3.3.1 配置 mapred-env.sh
- 3.3.2配置 mapred-site.xml
- 3.4配置yarn
- 3.4.1配置 yarn-env.sh
- 3.4.2 配置 yarn-site.xml
- 3.4.3启动yarn 集群
- 3.5hadoop集群启动
1.安装JDK 环境
JDK1.8下载链接
使用wget 下载到liunx 主机
#创建文件夹
mkdir /usr/app
# 进入文件夹
cd /usr/app
#下载java
wget https://repo.huaweicloud.com/java/jdk/8u202-b08/jdk-8u202-linux-x64.tar.gz
#解压
tar -zvxf jdk-8u181-linux-x64.tar.gz
#修改名称
mv jdk-8u181-linux-x64 jdk.18
//配置环境变量
vim /etc/profile
export JAVA_HOME=/usr/app/jdk1.8 # java解压的路径
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JRE_HOME=$JAVA_HOME/jre
//加载
source /etc/profile
每台节点都安装jdk
2.系统配置
2.1修改本地hosts文件
配置本地hosts文件,后面我们直接使用hostname 去连接主机 不再输入ip地址
每个节点都执行
#编辑host文件
vi /etc/hosts
#文件末尾添加自己的主机和hostname
192.168.56.103 hadoop01
192.168.56.104 hadoop02
192.168.56.105 hadoop03
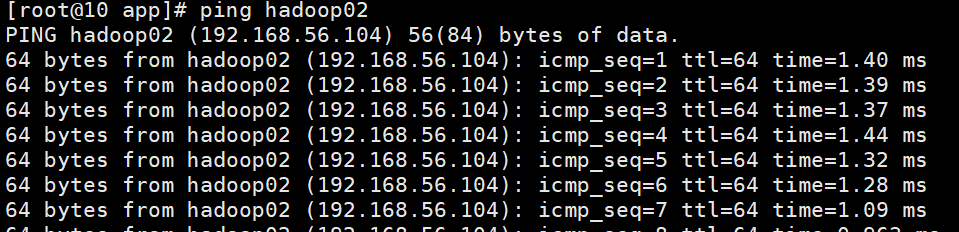
保存后ping hadoop02 网络正常
2.2创建hadoop 用户
每台机器都指向
#新增用户
useradd hadoop
#设置hadoop 用户密码为 123456
passwd hadoop 123456
#切换到hadoop 用户
su - hadoop
2.2 设置ssh免密(使用hadoop 用户生成)
由于hadoop 一般为集群,我们安装时 直接使用ssh 命令 复制安装 hadoop 效率会更高
我们一般使用ssh 命令时会遇到输入密码验证的问题 我们可以提前配置免密操作
全部节点 执行该命令生成密钥,执行后一直按Enter 即可
#生成密钥
ssh-keygen -t rsa -b 4096
将密钥拷贝到其他两个子节点,命令如下:
ssh-copy-id -i hadoop01
ssh-copy-id -i hadoop02
ssh-copy-id -i hadoop03
结果打印
3.安装 hadoop 3.2.4
国内下载地址 华为镜像
官网下载地址 官网链接
3.1 安装hadoop
在hadoop01 服务器下载hadoop安装包,如果不能连接外网请下载后上传到服务器
cd /usr/app
#下载
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz
#解压
tar -zvxf hadoop-3.2.4.tar.gz
mv hadoop-3.2.4 hadoop
3.1.1 配置Hadoop 环境变量
在/etc/profile文件底部追加如下内容
export HADOOP_HOME=/usr/app/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
从hadoop01 将hadoop安装文件夹远程复制到hadoop02、hadoop03
3.2配置 HDFS
配置HDFS集群,我们主要涉及到如下文件的修改
| 修改文件 | 作用 |
|---|---|
| workers | 配置从节点(DataNode)有哪些 |
| hadoop-env.sh | 配置Hadoop的相关环境变量 |
| core-site.xml | Hadoop核心配置文件 |
| hdfs-site.xml | HDFS核心配置文件 |
这些文件均存在与$HADOOP_HOME/etc/hadoop文件夹中。
ps:$HADOOP_HOME是后续我们要设置的环境变量,其指代Hadoop安装文件夹即/app/hadoop
3.2.1 配置 workers 文件
# 进入配置文件目录
cd etc/hadoop
# 编辑workers文件
vim workers
# 填入如下内容
hadoop01
hadoop02
hadoop03
3.2.2 配置hadoop-env.sh
# 填入如下内容
#JAVA_HOME,指明JDK环境的位置在哪
export JAVA_HOME=/usr/jdk
#HADOOP_HOME,指明Hadoop安装位置
export HADOOP_HOME=/usr/hadoop
#HADOOP_CONF_DIR,指明Hadoop配置文件目录位置
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
#HADOOP_LOG_DIR,指明Hadoop运行日志目录位置
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
3.2.3 配置core-site.xml
<configuration>
<!--含义:HDFS文件系统的网络通讯路径
协议为hdfs:// namenode为hadoop01 namenode通讯端口为8020 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<!--含义:io操作文件缓冲区大小值:131072 bit-->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
3.2.3 配置 hdfs-site.xml
<configuration>
<!--hdfs文件系统,默认创建的文件权限设置 值:700,即:rwx-->
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<!--NameNode元数据的存储位置 值:/data/nn,在hadoop01节点的/data/nn目录下 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<!--NameNode允许哪几个节点的DataNode连接(即允许加入集群)hadoop01,hadoop02,hadoop03,这三台服务器被授权-->
<property>
<name>dfs.namenode.hosts</name>
<value>hadoop01,hadoop02,hadoop03</value>
</property>
<!--hdfs默认块大小 值:268435456(256MB) -->
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<!--namenode处理的并发线程数 以100个并行度处理文件系统的管理任务-->
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<!--NameNode元数据的存储位置 值:/data/nn,在所有节点的/data/nn目录下-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
</configuration>
目前,已经基本完成Hadoop的配置操作,可以从hadoop01 将hadoop安装文件夹远程复制到hadoop02、hadoop03
3.2.4 启动hdfs
# 确保以hadoop用户执行
su - hadoop
# 格式化namenode
hadoop namenode -format
# 一键启动hdfs集群
start-dfs.sh
# 一键关闭hdfs集群
stop-dfs.sh
# 如果遇到命令未找到的错误,表明环境变量未配置好,可以以绝对路径执行
/export/server/hadoop/sbin/start-dfs.sh
/export/server/hadoop/sbin/stop-dfs.sh
3.3 配置MapReduce
3.3.1 配置 mapred-env.sh
# 设置JDK路径
export JAVA_HOME=/usr/app/jdk1.8
# 设置JobHistoryServer进程内存为1G
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
#设置日志级别为INFO
export HADOOP_MAPRED_ROOT_LOGGER=INFORFA
3.3.2配置 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>MapReduce 的运行框架设置为YARN</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
<description> 历史服务器通讯地址设置为hadoop01:10020</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
<description>历史服务器web端口为hadoop01:19888</description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mr-history/tmp</value>
<description>历史信息在hdfs的记录临时路径</description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mr-history/done</value>
<description>历史信息在hdfs的记录路径</description>
</property>`在这里插入代码片`
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>设置环境变量地址</description>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>设置环境变量地址</description>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
<description>设置环境变量地址</description>
</property>
</configuration>
3.4配置yarn
3.4.1配置 yarn-env.sh
#设 置 JDK路径的环境变量
export JAVA_HOME=/usr/jdk1.8
#设置 HADOOP HOME的环境变量
export HADOOP_HOME=/export/server/hadoop
#设置配置文件路径的环境变量
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
#设置日志文件路径的环境变量
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
3.4.2 配置 yarn-site.xml
<configuration>
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop01:19888/jobhistory/logs</value>
<description>历史服务器URL </description>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>hadoop01:8089</value>
<description> 代理服务器主机和端口</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description> 开启聚合日志</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<descriptionn>程序日志HDFs的存储路径</description>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
<description>>ResourceManager设置在hadoop01节点</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>选择公平调度</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
<description>NodeManger中间数据本地存储路径</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
<description>NodeManagers数据日志本地存储路径</description>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
<description>在NodeManager上保留日志文件的时间</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>为MapReduce 程序开启Shuffle服务</description>
</property>
</configuration>

3.4.3启动yarn 集群
- 一键启动YARN集群
$HADOOP_HOME/sbin/start-yarn.sh
会基于yarn-site.xml中配置的yarn.resourcemanager.hostname来决定在哪台机器上启动resourcemanager
会基于workers文件配置的主机启动NodeManager
- 一键停止YARN集群
$HADOOP_HOME/sbin/stop-yarn.sh
- 在当前机器,单独启动或停止进程
$HADOOP_HOME/bin/yarn --daemon start|stop resourcemanager|nodemanager|proxyserver
start和stop决定启动和停止 可控制resourcemanager、nodemanager、proxyserver三种进程
- 历史服务器启动和停止
$HADOOP_HOME/bin/mapred --daemon start|stop historyserver
3.5hadoop集群启动
一键启动hadoop 集群:
$HADOOP_HOME/sbin/start-all.sh
一键停止hadoop 集群
$HADOOP_HOME/sbin/stop-all.sh