- 若出现乱码page_text = page_text.encode('iso-8859-1').decode('gbk')
- 或者查看源码head里面的说明,设置成相同的即可

- 数据解析原理概述
- 解析的局部的文本内容都会在标签之间或者标签对应的属性中进行储存
- 数据解析就是
- 1、进行指定标签的定位
- 2、标签或者标签对应的属性中存储的数据值进行获取(解析)
- 编码流程
- 1、指定url
- 2、发起请求
- 3、获取响应数据
- 4、数据解析
- 5、持久化存储
- 正则
- 练习
- 爬取煎蛋中无聊图板块下所有的图片
-
# 爬取图片 import json import re import requests if __name__ == '__main__': # url='https://tiebapic.baidu.com/forum/w%3D580%3B/sign=778fd1cb54dfa9ecfd2e561f52ebf603/500fd9f9d72a6059a07152cd6d34349b023bba80.jpg?tbpicau=2022-12-21-05_344dce9c8cf09b1124ad41710692f68a' # img_data=requests.get(url=url).content # content返回的是二进制形式的图片数据、text是字符串、json是对像 # with open('01.jpg','wb') as wstream: # wstream.write(img_data) url='http://jandan.net/pic' headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54' } # 使用通用爬虫对url对应的一整张页面进行爬取 page_date=requests.get(url=url,headers=headers).text # print(page_date) ''' <div class="text"> <span class="righttext"> <a href="/t/5376295">5376295</a></span><p><a href="//tva2.sinaimg.cn/large/0070CEx3ly1h990memuvgj30u013y0yz.jpg" target="_blank" class="view_img_link" referrerPolicy="no-referrer">[查看原图]</a> <br /> <img src="//tva2.sinaimg.cn/mw600/0070CEx3ly1h990memuvgj30u013y0yz.jpg" referrerPolicy="no-referrer" /> </p> </div> ''' ex='<div class="text">.*?<img src="(.*?)" refer.*?<div>' imgsrc_list=re.findall(ex,page_date,re.S) #re.S:单行匹配、re.M:多行匹配 print(imgsrc_list) i=0 for img in imgsrc_list: img='http:'+img img_data = requests.get(url=img,headers=headers).content imgName='img/img'+str(i)+'.jpg' with open(imgName,'wb') as wstream: wstream.write(img_data) i+=1
- 获取一个网站的图片,可以分页获取
-
import re import requests if __name__ == '__main__': # 设置img=0,用来后面设置图片名称 imgs = 0 # 指定url,先找到主页,p后面是指定的页码 url = 'https://www.nyato.com/forum/f2?post_type=1&p={}' # 设置ua伪装 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54' } # 取第一页的数据 for i in range(1, 2): # 更新url new_url = url.format(i) # print(new_url) # 获取网页数据 page_text = requests.get(url=new_url, headers=headers).text # print(page_text) ''' <a class="w100s fl liti h80 w80"> <img src="https://img.nyato.com/data/upload/2020/0908/20/5f5772d05c5ce.jpg!360x360cut" class="w100s fl h80" onclick="FWDRL.show('gallery_1884527', 1);" /> </a> ''' # 根据网页查询可以看出所需要的图片位置,注意不需要!360*360cut,否则得到的图片会很小 ex = '<a class="w100s fl liti h80 w80">.*?<img src="(.*?)!360.*?</a>' # 利用正则找寻,得到图片链接的列表 imgs_src = re.findall(ex, page_text, re.S) # print(imgs_src) # 利用循环,下载该页图片 for img in imgs_src: # 注意要是content才可以,要获取的是图片的二进制文件 img_l = requests.get(url=img, headers=headers).content # 拼接,设置图片路径和名称 imgs_name = 'cos/img' + str(imgs) + '.jpg' # imgs+1,每个图片按顺序保存 imgs += 1 # 进行保存 with open(imgs_name, 'wb') as wstream: wstream.write(img_l) print('over!!!')
- 练习
- bs4
- 原理
- 1、实例化一个BeautifulSoup对象,并将页面源码数据加载到该对象中
- 2、通过调用BeautifulSoup对象中的相关属性或者方法,进行标签定位和数据提取
- 如何实例化Beautiful Stop对象
- from bs4 import BeautifulSoup
- 两种形式
- 1、将本地的HTML文档中的数据加载到该对象中
-

- 2、将互联网上获取的页面源码加载到该对象中

- 提供提供的用于数据解析的方法和属性
- soup.tagName:返回的是文档中第一次出现的tagName对应的标签
- soup.find('tagName')相当于soup.tagNam
- soup.find('tagName',class_/id/attr='xxx'):属性定位,返回也是第一个
- soup.find_all('tagName') # 返回符合要求的所有标签,形式是列表
- soup.select('某种选择器(id、class、标签...选择器)'):返回的是一个列表,只支持属性定位,不支持索引定位

- soup.tagName.text/string/get_text():获取标签之间的文本数据,可以结合find使用
- text/get_text():可以获取某一个标签中所有的文本内容
- string:只可以获取该标签下直系的文本内容
- soup.a['helf']:获取标签中属性值,可以结合find使用
- 实际案例
- 爬取小说所有的章体标题和章节内容
-
# 爬取三国演义小说所有的章体标题和章节内容 import time import requests from bs4 import BeautifulSoup if __name__ == '__main__': url = 'http://www.ujxsw.com/read/35958/' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54' } # 对首页页面数据进行爬取 page_text = requests.get(url=url, headers=headers).text # 在首页解析出章节的标题和详情页的URL。 soup = BeautifulSoup(page_text, 'lxml') a_list = soup.select('#readerlist > ul > li > a') i = 0 fp = open('./xiaoshuo.txt', 'w', encoding='utf-8') for a in a_list: if i == 200: break i += 1 time.sleep(2) title = a.string detail_url = 'http://www.ujxsw.com/' + a['href'] # 对详情页发起请求。 解析出章节内容。 datail = requests.get(url=detail_url, headers=headers).text # 解析出详情页相关的章节内容。 soup2 = BeautifulSoup(datail, 'lxml') datail_text = soup2.find('div', class_='read-content').text print(datail_text) datail_text.replace(u' ', u'') fp.write(title + ':' + datail_text + '\n\n') print(title, '爬取成功!!!')import requests from bs4 import BeautifulSoup import time if __name__ == '__main__': # 指定url url = 'https://www.513gp.org/book/4961/' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54' } # 获取该页的响应数据 page_text = requests.get(url=url, headers=headers).text # 手动设定响应数据的编码格式 page_text = page_text.encode('iso-8859-1').decode('gbk') # 实例化Beautiful Stop对象 soup = BeautifulSoup(page_text, 'lxml') # 找到a标签,放到列表里面 a_list = soup.select('a[href]') # 截取需要的a标签 a_list = a_list[1:] # 打开文件 fp = open('./红寿寺.txt', 'w', encoding='utf-8') # 打印 for a in a_list: time.sleep(2) # 找到a标签里面的标题 titie = a.string # 获取url detail_url = 'https://www.513gp.org/book/4961/' + a['href'] # 获取该页数据,并指定编码格式 detail_page = requests.get(url=detail_url, headers=headers).text detail_page = detail_page.encode('iso-8859-1').decode('gbk') # 创建实例化对象 soup2 = BeautifulSoup(detail_page, 'lxml') # 找到内容并获取 detail = soup2.find('div', class_='bookcontent clearfix').text fp.write(titie + ':' + detail + '\n\n') print(titie + '爬取成功!!!')
- 原理
- xpath
- 最常用且最便捷高效的一种解析方式
- (5条消息) 爬虫数据提取-xpath_黑马蓝汐的博客-CSDN博客_xpath爬取数据
- (5条消息) lxml.etree.XMLSyntaxError解决方法_sjyOvO的博客-CSDN博客
- 解析原理
- 1、需要去实例化一个etree的对象,并且需要将被解析的页面源码数据加载到该对象中
- 2、通过调用etree对象中的xpath方法,结合xpath表达式实现标签的定位和内容的捕获
- 如何实例化一个etree对象
- from lxml import etree
- 1、将本地的html文档中的源码数据加载到etree对象中
- etree.prase(filepath)
- 2、将从互联网是获取的源码数据加载到该对象中
- etree.HTML('page_text')
- xpath表达式
- /:表示的是从根节点开始进行定位,表示的是一个层级
- //:表示的的是多个层级,定位HTML标签下的所有div标签
- //tag[@attrName="attrValue"]:属性定位
- //tag[@attrName="attrValue"][number]:索引定位
- eg:r=tree.xpath('//div[@class="top-nav"]/ul/li[3]')
- /text():获取的是标签里的直系的文本内容

- //text():获取的是标签里的所有的文本内容

- /@attrName :获取对应属性值
- 实践
- 爬取二手房当中的房源信息
-
#爬取房屋标题信息 import requests from lxml.html import etree if __name__ == '__main__': # 爬取页面源码数据。 url = 'https://zhoukou.esf.fang.com/' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54' } page_text = requests.get(url=url, headers=headers).text # 数据解析 tree = etree.HTML(page_text) assert isinstance(tree, etree._Element) div_list=tree.xpath('//div[@class="shop_list shop_list_4"]/dl[@class="clearfix"]') # print(div_list) fp=open('58.txt','w',encoding='utf-8') for dl in div_list: title=dl.xpath('./dd/h4/a/span/text()') title=title[0] print(title) fp.write(title+'\n') fp.close() - 爬取高清图片
-
# 解析下载图片数据 import requests from lxml.html import etree if __name__ == '__main__': # 指定该网站的url # url = 'https://pic.netbian.com/4kmeinv/' # url='https://pic.netbian.com/4kmeinv/index_3.html' url = input('输入url:') # 进行UA伪装 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54' } # 先获取这一页的数据 page_text = requests.get(url=url, headers=headers).text # 手动指定编码格式 page_text = page_text.encode('iso-8859-1').decode('gbk') # 实例化etree对象 tree = etree.HTML(page_text) # 提取这个网站的缩略图集合的li标签 li_list = tree.xpath('//div/ul[@class="clearfix"]/li') # 循环 i = int(input('图片从数字几开始命名:')) # i = 40 for li in li_list: # 将src提取出来,并进行合并,形成大图页网站 src = li.xpath('./a/@href')[0] new_page = 'https://pic.netbian.com' + src # 获取大图页的响应数据,并指定编码格式 page = requests.get(url=new_page, headers=headers) page.encoding = 'gbk' page = page.text # 再次实例化etree对象 tree2 = etree.HTML(page) # 提取出来img的属性,并进行拼接 img = tree2.xpath('//div[@class="photo-pic"]/a/img/@src')[0] zuihou_page = 'https://pic.netbian.com' + img # 保存图片地址 img_local = 'meinv/img' + str(i) + '.jpg' # 获取图片的二进制形式 img_zuizong = requests.get(url=zuihou_page, headers=headers).content # 持久化保存 fp = open(img_local, 'wb') fp.write(img_zuizong) fp.close() i += 1 print('图片' + str(i) + '下载完成!!!') - 获取所有城市名称
-
from lxml import etree import requests if __name__ == '__main__': # # UA伪装 # headers = { # 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54' # } # # 指定url # url = 'https://www.aqistudy.cn/historydata/' # # 获取页面响应数据 # page_text = requests.get(url=url, headers=headers).text # # print(page_text) # # 实例化etree对象 # tree = etree.HTML(page_text) # # 获取热门城市所在的li标签 # hot_list_li = tree.xpath('//div[@class="bottom"]/ul/li') # # print(hot_list_li) # # 创建空外表,用来放城市名字 # all_city_names = [] # # 循环获取城市名字 # for li in hot_list_li: # # 获取城市名子,并添加到列表 # hot_li = li.xpath('./a/text()')[0] # all_city_names.append(hot_li) # # print(all_city_names) # # 获取所有普通城市所在的ul # all_list_ul = tree.xpath('//div[@class="bottom"]/ul') # # print(all_list_ul) # for ul in all_list_ul: # 循环遍历ul # all_city = ul.xpath('./div/li/a/text()') # 拿到该ul分类下,所有的城市名字 # # print(all_city) # all_city_names.extend(all_city) # 将城市名字添加到列表 # print(all_city_names) # with open('./city.txt', 'w') as fp: # 持久化储存 # for city_name in all_city_names: # # print(city_name) # fp.write(city_name + '|') ############################################################################################### # UA伪装 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54' } # 指定url url = 'https://www.aqistudy.cn/historydata/' # 获取页面响应数据 page_text = requests.get(url=url, headers=headers).text # print(page_text) # 实例化etree对象 tree = etree.HTML(page_text) # 一次性解析出热门和所有城市所在的a标签 # //div[@class="bottom"]/ul/li/a # //div[@class="bottom"]/ul/div[2]/li/a a_list = tree.xpath('//div[@class="bottom"]/ul/li/a | //div[@class="bottom"]/ul/div[2]/li/a') city_names = [] for a in a_list: # print(a) city_name = a.xpath('./text()')[0] city_names.append(city_name) print(city_names) city_names = set(city_names) print(city_names) -
免费简历模板素材
-
# 爬取站长素材中所有免费简历模板 import requests from lxml import etree import time if __name__ == '__main__': # https://sc.chinaz.com/jianli/free.html url = input('输入url:') i = int(input('请输入从几开始储存:')) # UA伪装 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54' } # 获取页面响应源码 page_text = requests.get(url=url, headers=headers).text # 创建实例化对象 tree = etree.HTML(page_text) # 获取每个模板的页面链接 a_srcs = tree.xpath('//*[@id="container"]/div/a/@href') # print(a_srcs) for a in a_srcs: # 文件名 filename = '模板/简历' + str(i) + '.rar' i += 1 # 获取模板页面响应数据 a_page_text = requests.get(url=a, headers=headers).text # 实例化etree对象 a_tree = etree.HTML(a_page_text) # 获取下载链接 src = a_tree.xpath('//*[@id="down"]/div[2]/ul/li[1]/a/@href')[0] # print(src) # 获取数据,进行持久化保存 rar = requests.get(url=src, headers=headers).content time.sleep(1) with open(filename, 'wb') as fp: fp.write(rar) print('简历' + str(i) + '爬取完毕!')
爬虫学习-数据解析三种方式:正则、bs4、xpath,以及一些实例操作
news2026/2/13 2:11:36
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/106633.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
设计模式之美总结(结构型篇)
title: 设计模式之美总结(结构型篇) date: 2022-12-21 09:59:11 tags:
设计模式 categories:设计模式 cover: https://cover.png feature: false 文章目录1. 代理模式(Proxy Design Pattern)1.1 原理解析1.2 动态代理1.3 应用场景…
排查Java服务CPU使用率高达100%的原因
排查Java服务CPU使用率高达100%的原因 Java服务在服务器运行一段时间,有一天CPU使用率突然高达100%,通过jstack工具分别在CPU使用率为100%时执行了一次堆线程dump和cpu使用率降下来后执行了一次堆线程dump 目录排查Java服务CPU使用率高达100%的原因一、环…

【SQL】一文详解嵌入式SQL(建议收藏)
💂作者简介: THUNDER王,一名热爱财税和SAP ABAP编程以及热爱分享的博主。目前于江西师范大学会计学专业大二本科在读,同时任汉硕云(广东)科技有限公司ABAP开发顾问。在学习工作中,我通常使用偏后…
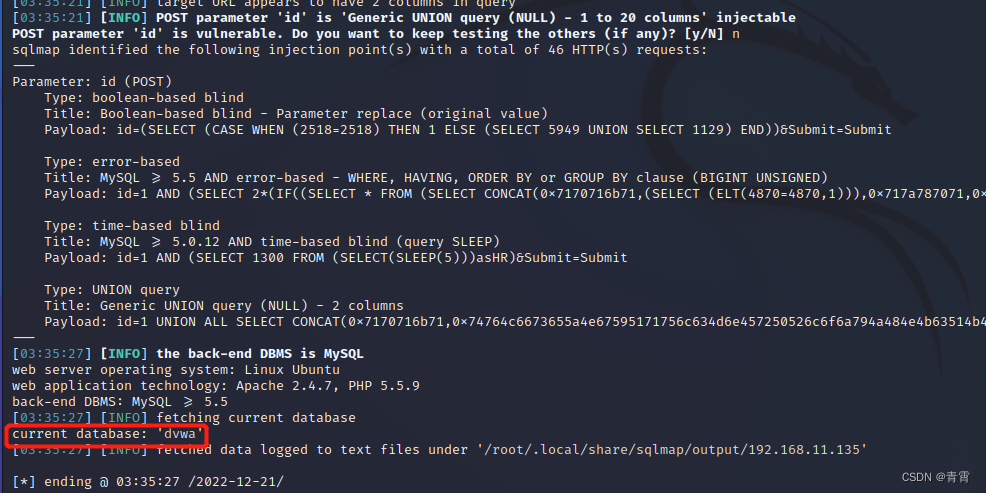
SQLMap 扫描利用SQL注入
一、SQLMap介绍 SQLMap 是一个自动化的SQL注入工具,其主要功能是扫描、发现并利用给定URL的SQL注入漏洞,内置了很多绕过插件,支持的数据库是MySQL 、Oracle 、PostgreSQL 、Microsoft SQL Server、Microsoft Access 、IBM DB2, SQ Lite 、Fir…
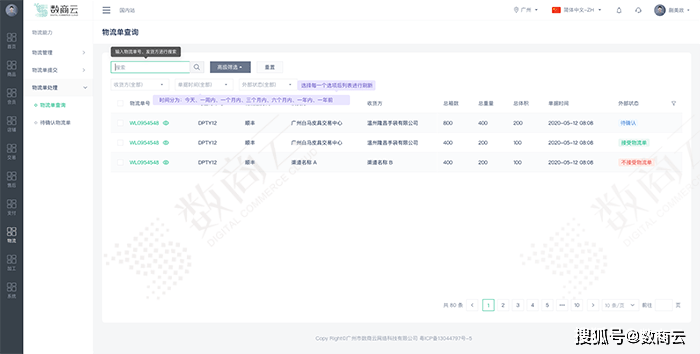
光伏行业管理亟待变革,数商云供应链系统订单流程自动化流转助力企业降本增效
作为实现“3060”双碳目标的主力军,光伏产业正迎来空前的政策、市场、资本三重加持的红利期。有业内人士预测,到2025年全球新增光伏装机量将达到270-330GW,国内新增光伏装机量将达到90-110GW,十四五期间年均新增光伏装机量将达到7…
用React做一个音乐播放器
介绍
任何正在学习 React 并想使用 React 构建项目的人。有各种博客和文章可以为开发人员指导此类项目。我确实浏览过这些文章,但其中总是缺少一种项目。缺少的项目是音乐播放器和视频播放器。这两个项目都会让您有机会处理音频和视频。您将学到很多东西࿰…
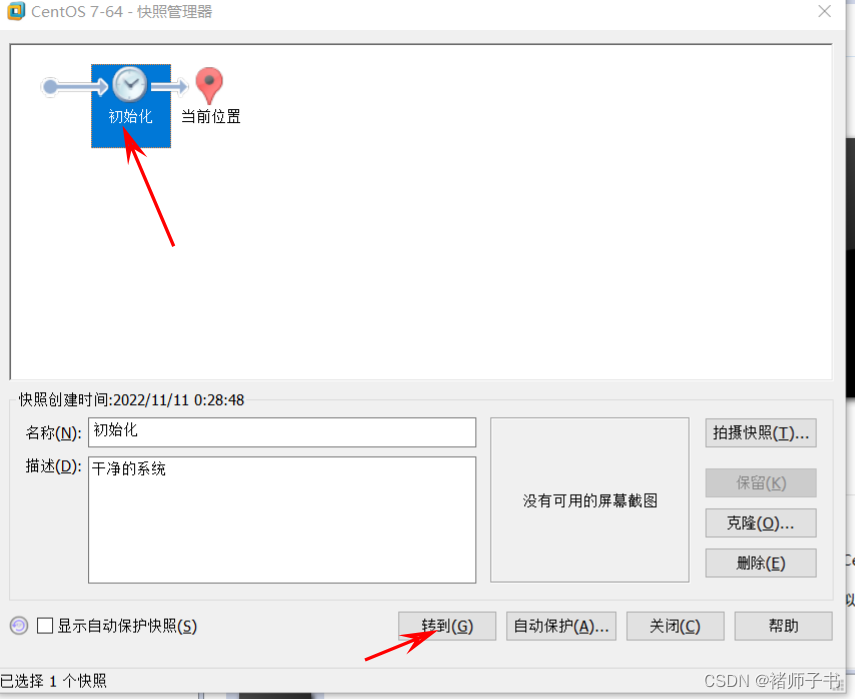
Linux学习-97-vmware网络桥接模式配置和vmware快照操作
19.3 vmware网络桥接模式配置
桥接:需要保证Linux虚拟机和本机处在同一个网段!
#win平台输入ipconfig查看主机的ip地址Linux也必须要配置到对应的网段 桥接模式:主机ip 和虚拟机ip映射到同一块物理网卡(光纤,无线…

达梦数据库-centos7安装
参考官方文档
1.环境
操作系统CPU数据库CentOS7x86_64dm8_20221121_x86_rh6_64.iso
2.安装前准备
2.1 关闭防火墙 或 开放5236端口
# 关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
# 开放5236端口(推荐使用)
firewall-cmd --pe…
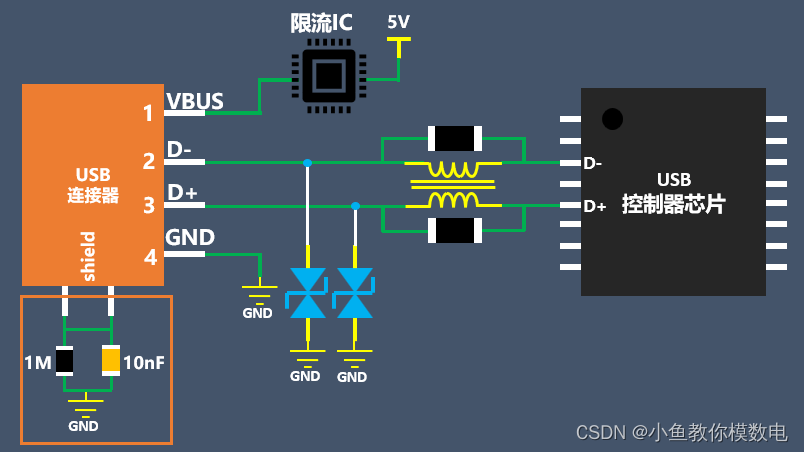
TYPE A USB2.0电路设计
TYPE A USB2.0连接器可以分为公座和母座,放在供电端PCB板上的一般是母座, 2.0的母座有四个信号引脚。今天就来和大家分享下TYPE A USB2.0的板级电路设计, 首先来看到 TYPE A USB2.0四个引脚的信号定义,1脚是VBUS,需要…
Kafka系列之入门(荣耀典藏版)
目录
一、为什么要用消息中间件?
1、异步处理
2、应用解耦
3、流量削峰
4、日志处理
二、为什么选择Kafka?
消息中间件的编年史
1、Kafka的外在表现和内在设计
2、市场主流消息中间件对比
三、Kafka中的基本概念
1、消息和批次
2、主题和分区…

【笔记:模拟CMOS集成电路】两级运算放大器设计与仿真(带版图)
【笔记:模拟CMOS集成电路】两级运算放大器设计与仿真(带版图)前言1.电路分析1.1电路结构电路描述:1.2小信号分析1.3公式2指标设计2.1预期设计指标参数2.2参数分析(1)确定gm1、gm6(2)分配电流(3)确定M1尺寸(4)确定M6尺寸(5)共模输入…
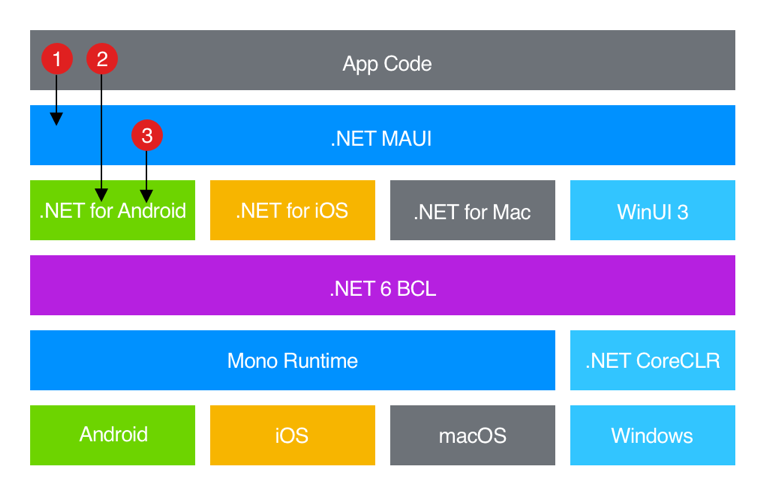
学习.NET MAUI Blazor(二)、MAUI是个啥
随着.NET 7的发布,MAUI也正式发布了。那么MAUI是个啥?我们先来看看官方解释: .NET 多平台应用 UI (.NET MAUI) 是一个跨平台框架,用于使用 C# 和 XAML 创建本机移动和桌面应用。 目录关于MAUIMAUI的工作原理如何开发MAUI该如何选择…
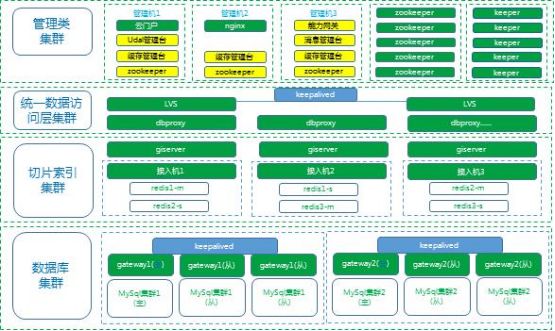
5万字企业数字化运营管理平台软件开发框架项目技术方案
目录
1 项目总体概述
项目总体技术方案保障
系统设计
系统体系结构设计
系统指标保障
系统质量
系统健壮性
系统应具备安全性
系统易用性
系统可维护性
系统完备性
系统可扩展性
系统可测试性
系统可移植性
系统可追踪性
系统易安装性
2 项目技术方案
2.1 系统…

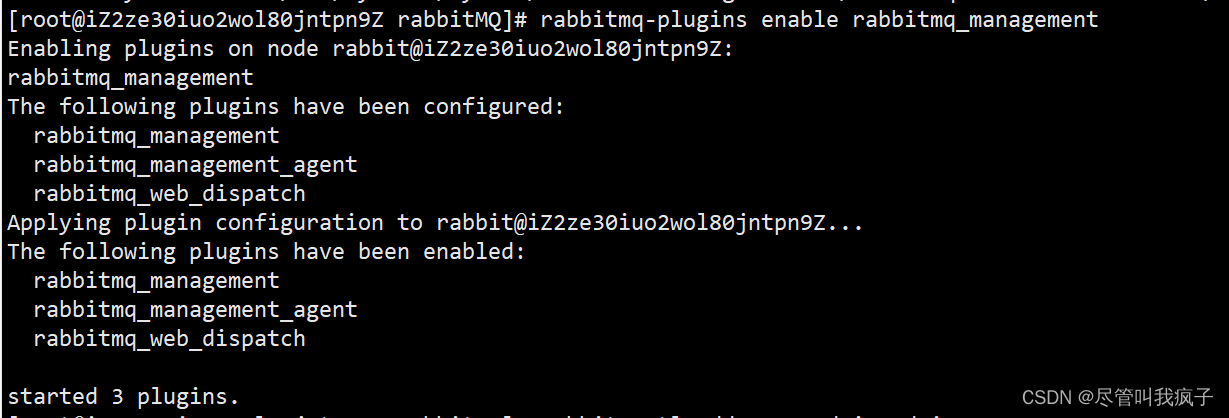
Linux上RabbitMQ安装使用
文章目录安装安装erlang安装rabbitMQ管理指令安装
官网 由于需要对应erlang和rabbitMQ两者版本的关系,先确定好下载哪个版本,版本关系表,以下教程以Erlang 23.3.4.11和RabbitMQ 3.9.14为例 安装erlang
略,进入对应版本下载安装…
【YApi接口管理平台】在Linux上使用Docker搭建YApi (亲测完美运行)
本期目录前言1. 创建MongoDB容器数据卷2. 安装Node.js3. 拉取MongoDB镜像4. 启动Mongo容器5. 拉取YApi镜像6. 初始化YApi7. 运行YApi容器8. 访问前言
博主想在自己的 Linux 虚拟机上使用 Docker 搭建 API 接口管理平台来团队开发一个项目,跟着网上的教程硬是装了好…

Unreal Engine的编译类型和命名规则
目录
编译类型
命名规则
资源命名规则
文件夹命名规则 编译类型 debug game只能调试你的项目,不能调试编辑器项目
多加了一个editor,就可以调试编辑器了。
不同的编译类型可以理解为引擎在不同的类型下的监管程度,用以不同的场景 Te…
树莓派驱动水星无线网卡(MW150UH)教程指南
目录
1.树莓派版本
2.无线网卡
查询无线网卡 1.如果为 Bus 001 Device 005: ID 0bda:b711 Realtek Semiconductor Corp. RTL8188GU 802.11n WLAN Adapter (After Modeswitch)
2.如果为 Bus 001 Device 007: ID 148f:7601 Ralink Technology, Corp. MT7601U Wireless Adapte…

深度学习计算广告(更新中)
本文转自王喆的《深度学习计算广告》,仅用于学习。 文章目录一、计算广告系统简介二、经典的广告系统架构三、dl时代广告系统各模块技术演进1. Ad Ranking - 从大刀阔斧的革命到精雕细琢的改进(1)模型发展图(2)张俊林&…
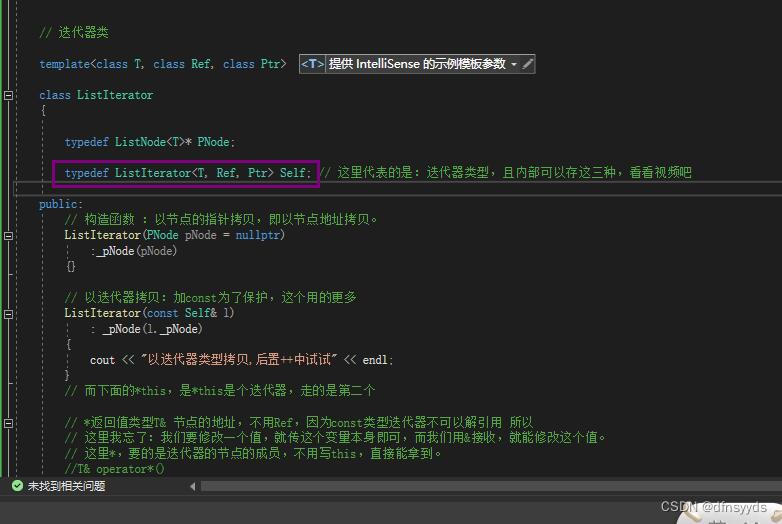
STL之list模拟实现
list常识
list迭代器不支持【】,所以不支持随机访问。也不支持>、<,没有意义,因为iterator是地址,地址并不连续。 重要的说三遍: list不支持随机访问,因为没有重写[]。 list不支持随机访问。 list不…