目录
前言
一.查看进程的pid
二.父子进程
三.查看进程的第二种方式
四.代码创建进程——fork
1.fork的功能
2.fork的返回值
3.fork代码的一般写法
五.对于fork的理解
1.fork干了些什么?
2.fork为什么给子进程返回0,给父进程返回子进程的pid?
3.fork之后父子进程谁先运行?
4.fork为什么会有两个返回值?
5.一个变量怎么可能会有两个值?
前言
本篇文章会以fork函数为切入点,引入父子进程的概念,并研究fork函数的返回值,带你了解创建进程时的诸多细节。
友情提示:本篇文章的所有操作都是基于Linux操作系统的,想要验证文中的操作请使用LInux环境
一.查看进程的pid
介绍一个LInux命令
ps -axj
ps查看进程,-axj查看所有进程的详细信息
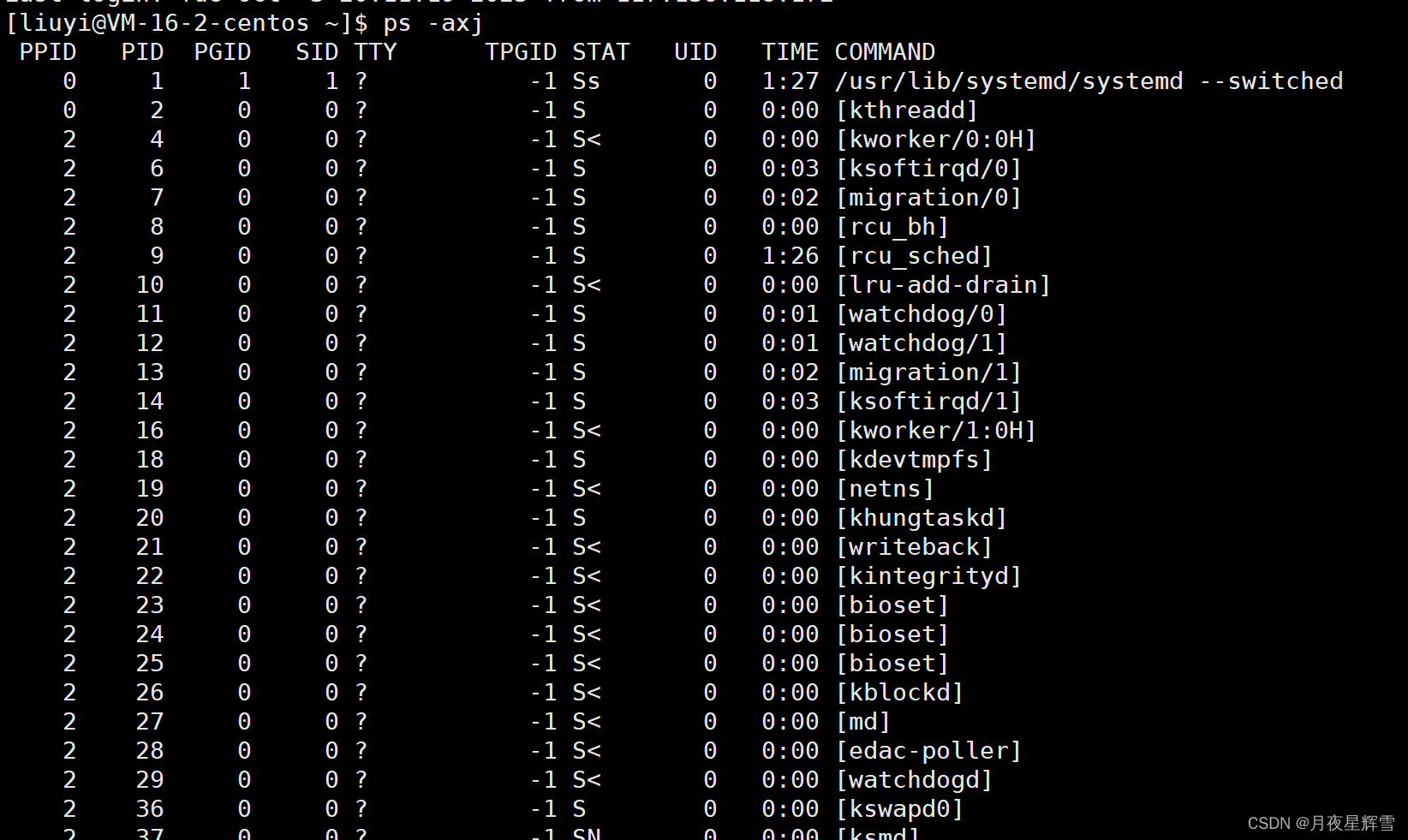
显示这么一大片,这些都是启动起来的进程。第一行的标签栏有一个pid,这个pid(process id)就是用来标识一个进程的,操作系统会给每一个启动起来的进程一个编号,类似于每个学生有自己的学号。
再来认识一个系统调用函数getpid,大家可以用man手册查一下这个函数的用法
man getpid
这个函数的功能就是返回当前进程的pid,需要包含<unistd> 和 <sys/types.h>这两个头文件。
(友情提示:这是LInux的系统调用函数哈,不是C标准库里的,Windows下的返回pid的函数是什么有兴趣自行查找。)
下面我写了这样一段C语言代码
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
while (1)
{
printf("我是一个进程,我的pid是%d\n", getpid());
sleep(1);
}
return 0;
} 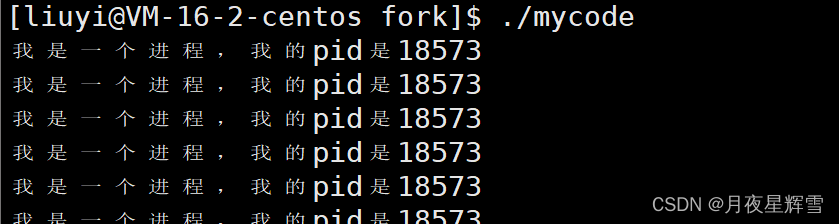
我们将它运行起来,getpid函数返回的结果是18573
再重新打开一个窗口,查找一下mycode对应的进程

我们发现mycode进程的pid果然是18573,但下面一行是个什么玩意呢?那个其实是grep指令,在我们用grep,由此可见指令也就是一个可执行程序。
pid就是用来标识一个进程的,我们也可以用这个pid来杀死这个进程
kill -9 18573
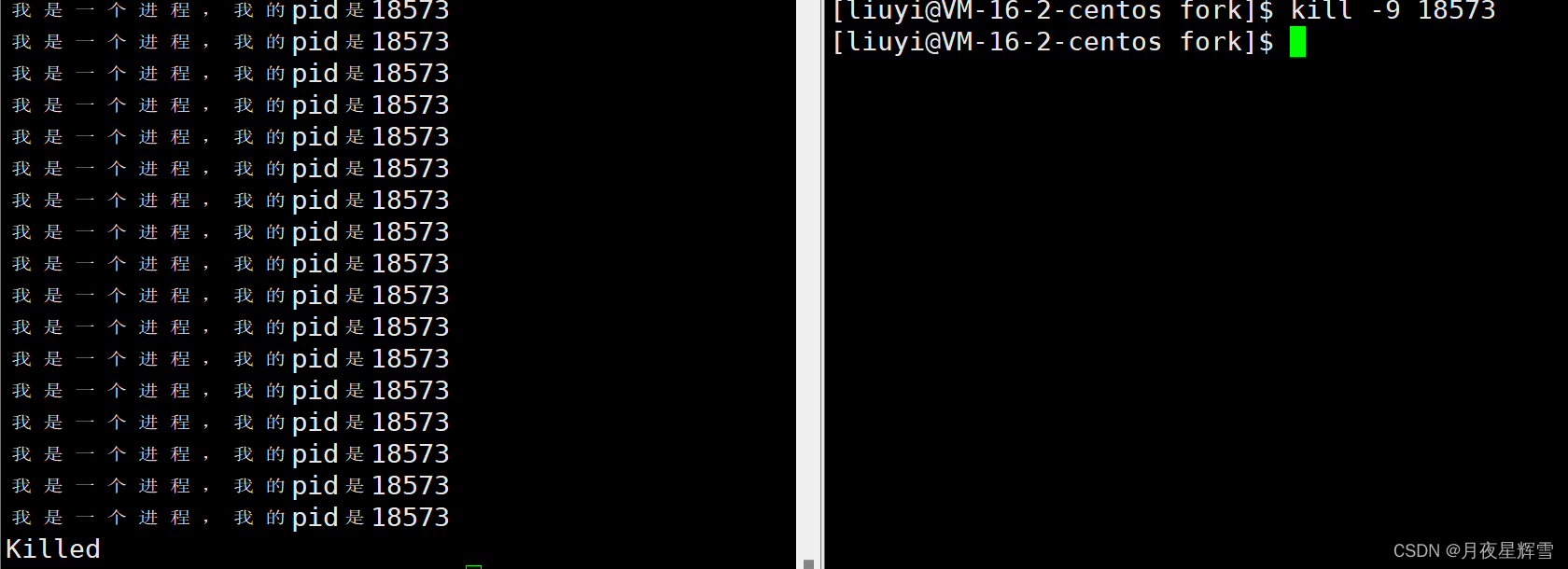
kill指令还有很多用法,例如暂停进程 ,后续会讲到。
二.父子进程
首先认识一个系统调用函数getppid,它的作用是返回当前进程的ppid(parent process id)
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
while (1)
{
printf("我是一个进程,我的pid是%d, 我的ppid是%d\n", getpid(), getppid());
sleep(1);
}
return 0;
}
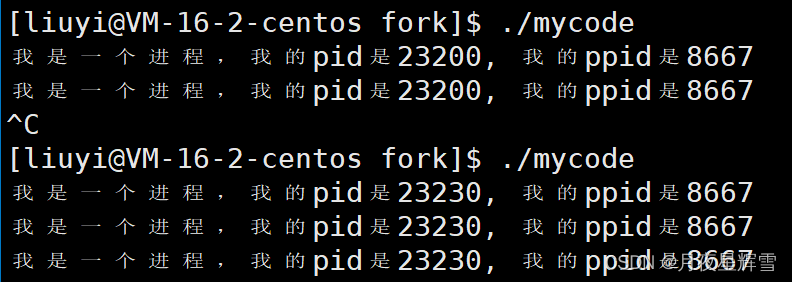
先后两次启动mycode程序,发现pid变了,但是ppid没有变。ppid是什么呢?是父进程的pid。啊?父进程又是个什么玩意儿?且听我慢慢道来。
在LInux中创建进程的方式有两种:
- 命令行中直接启动进程--手动启动
- 通过代码来创建进程
而启动进程,本质就是创建进程,一般是通过父进程创建的。
诶?不对吧,以前不是说进程是由操作系统创建的吗?操作系统首先要把程序加载到内存中,然后为其创建PCB,这个进程就被操作系统管理起来了。
这两种说法都是对的,创建一个进程就得创建一个PCB,但你别忘了PCB是一个对象,是一个结构体,里面有很多字段要填充的,那操作系统怎么知道要怎么初始化呢?所以一般情况下都是以父进程PCB为模版,很多属性内容直接赋给子进程,所以子进程是由父进程创建的说法是没错的。
所以,进程关系中注定会有一种关系,叫做父子关系
回到上面的现象,父进程的pid一直没变,那么这个父进程到底是谁呢?这个进程就是bash(命令行解释器)。所以,当我们登录LInux系统后,我们在命令行中敲的所有指令,点斜杆运行的所有程序,这些进程的父进程都是bash
三.查看进程的第二种方式
前面我们已经学会了用ps指令来查看进程,下面再扩展一个方法:
先把程序跑起来,记住它的pid,5304

在另一个窗口进入/proc目录,查看里面有些什么
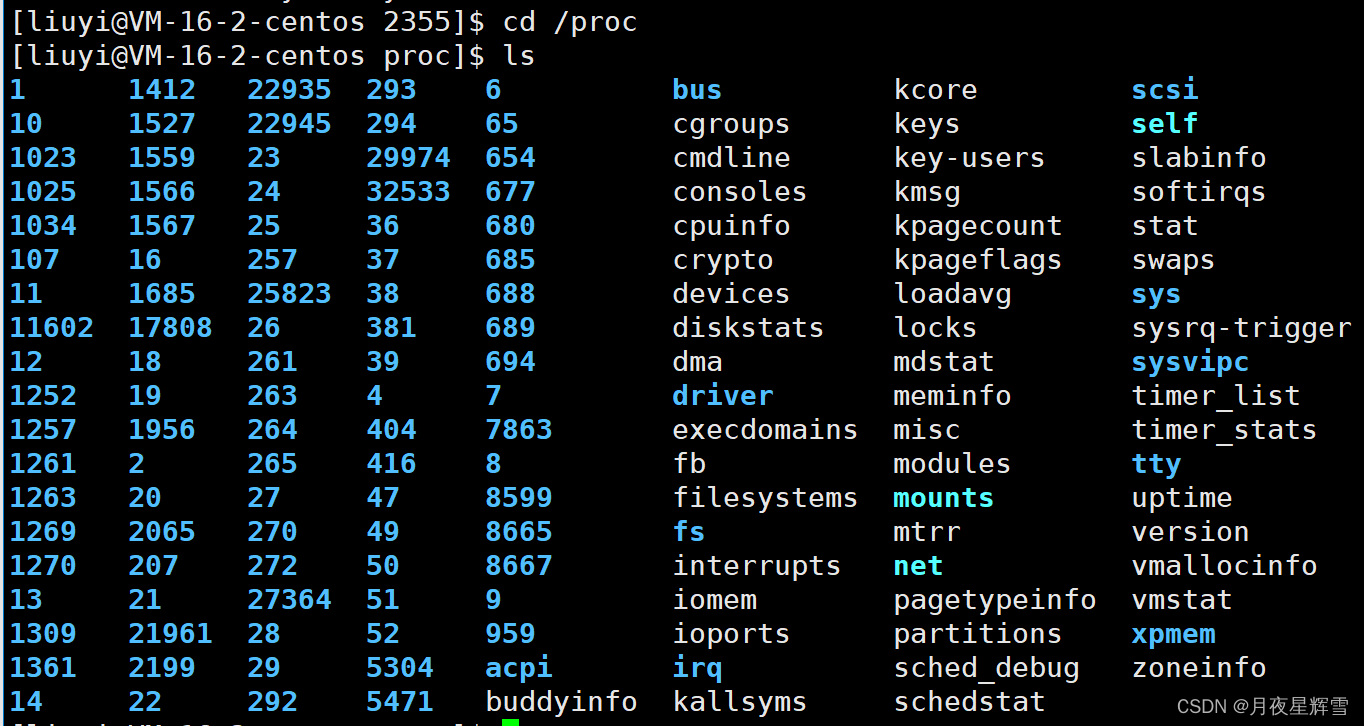
看到这些蓝色的数字心里大概有了猜想,这些是不是启动起来进程呢?猜对了!!!/proc目录是一个动态的目录,里面是操作系统的内核数据结构信息,也就是内存中的信息,是会实时变动的,它并不像普通目录占用磁盘空间。
我们进入5304这个目录,然后就会看到这些乌泱泱的一大片
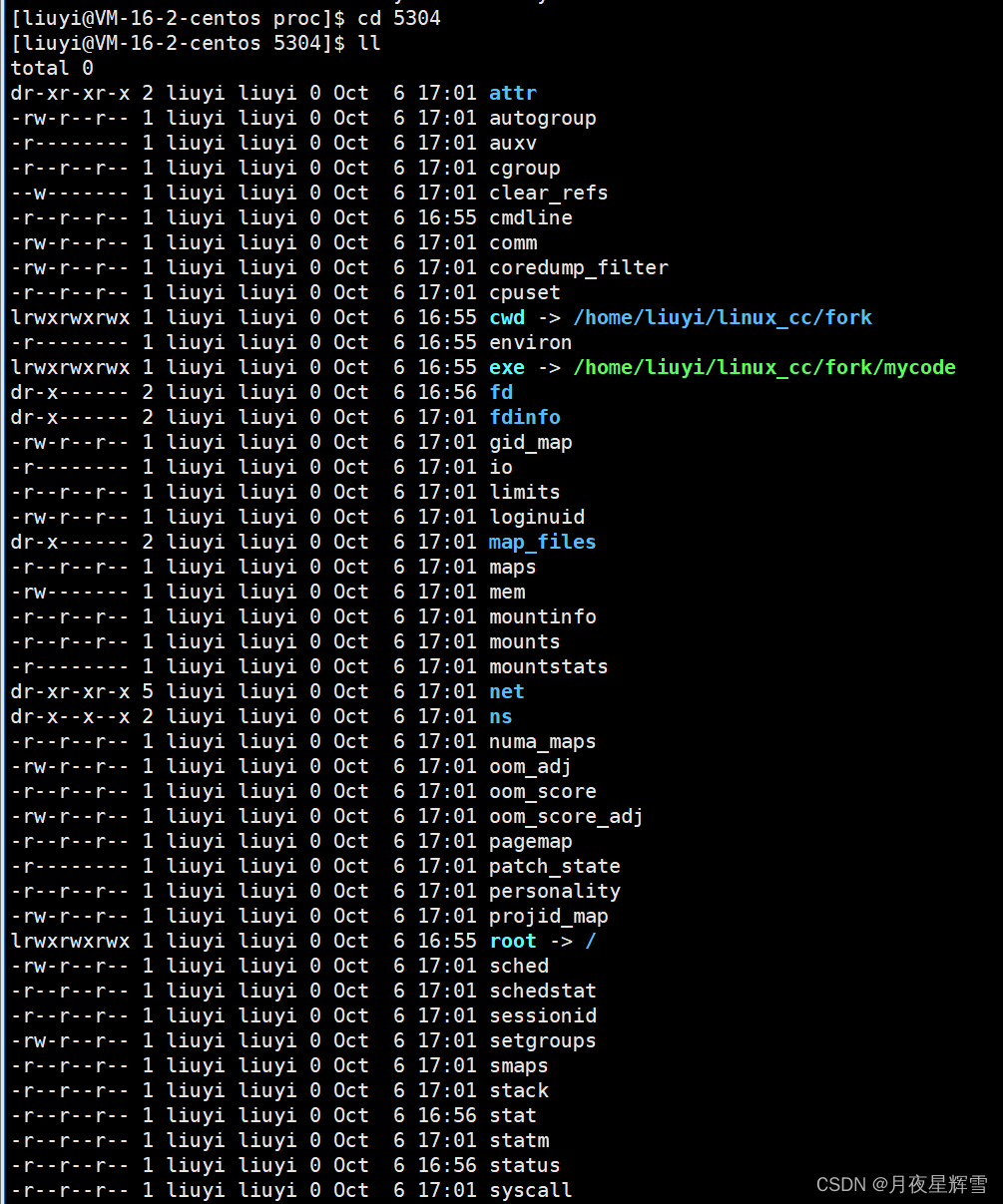
主要讲两个东西,一个cwd,一个exe。
exe的文件属性是l(链接文件),这个路径就是这个进程在磁盘上对应的可执行程序啊!进程并没有忘记它是从哪来的,也就是说通过进程的PCB实际上是可以找到在磁盘上找到对应的可执行程序的。如果在这个进程运行时,你把可执行程序删了,它也能检测到。
cwd的文件属性也是l(链接文件),这不就是可执行程序所在的目录吗?这个目录叫做工作目录,也叫当前目录。进程运行时,如果遇到要创建文件的函数,例如fopen,如果你指定了路径,他就在你给的路径下创建,如果你没有指定,那么就在这个工作目录下创建。Linux下的工作目录默认就是可执行程序所在目录,而Windows默认是在源文件所在目录。所以我们在VS上写代码,文件就默认创建在.c或.cpp目录下。
这个工作目录是可以修改的,用到chdir这个系统调用函数即可,传入一个字符串,即你要设定的工作目录。
四.代码创建进程——fork
目前为止,我们通常是用手动的方式来启动一个进程。我们该如何理解启动进程这种行为呢?
启动一个进程,本质就是系统多了一个进程,操作系统要管理的进程就多了一个。
进程=可执行程序+task_struct对象(内核对象),创建一个进程,就是系统中要申请内存,保存当前进程的可执行程序+task_struct对象,并将task_struct对象添加到进程列表中。
接下来介绍如何用fork这个系统调用函数来创建进程。
1.fork的功能
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
printf("我是一个进程,我的pid是%d\n", getpid());//这个函数只执行了一次
//创建子进程
fork();
printf("我是一个进程,我的pid是%d, 我的父进程pid是%d\n", getpid(), getppid());
sleep(1);
return 0;
}
看执行结果:

诶?奇了怪了,两条printf语句,怎么打印了三句话。这正是fork造成的
小结:fork会创建一个子进程,只有父进程执行fork之前的代码,fork之后,父子进程都要执行后续代码
emmm,匪夷所思,是不是打破你的认知,先把问题搁一边,接着往下看。
2.fork的返回值
man手册是这样说的:

大概就是说,如果创建子进程失败了就会返回-1,如果创建成功,在父进程中会返回子进程的pid,在子进程中会返回0。
…………
什么鬼?一个函数怎么可能有两个返回值?简直是危言耸听!!!话不多说,来验证一下。
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
printf("我是一个进程,我的pid是%d\n", getpid());//这个函数只执行了一次
pid_t id = fork();
printf("我是一个进程,我的pid是%d, 我的父进程pid是%d, fork return id: %d\n", getpid(), getppid(), id);
sleep(1);
return 0;
}
执行结果如下:

确实是这样的,系统层面的代码和语言层面有很大的差异,请先按捺住疑惑,接着往下看。
3.fork代码的一般写法
先抛出两个问题:我们为什么要创建子进程?我们创建子进程是为了让子进程和我父进程做一样的事吗?
我们之前写的都是单进程代码,但当我们使用fork之后,这就已经是一个多进程代码了。上面的问题换句话说,你为什么要编写多进程代码?
原因就是我们想让子进程协助父进程完成一些工作,这些工作是单进程完成不了的。
例如我们下载视频时,我想让它下载,那么单进程就OK了。但我想一边下载,一边播放,那么就可以让一个进程去下载,一个进程去播放,这样的话父子进程就能完成不同的工作,满足用户的需求。
所以我们创建子进程,就是为了让父子进程执行不一样的代码。
你怎么保证父子进程执行不同的代码呢?可以通过判断fork的返回值来判断当前是父还是子,让后让它他们执行不同的代码片段,通常用if else语句来分流。
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
printf("我是一个进程,我的pid是%d\n", getpid());//这个函数只执行了一次
pid_t id = fork();
if (id == -1)
{
return -1;
}
else if (id == 0)
{
while (1)
{
printf("我是子进程,我的pid是%d, ppid是%d, 我正在执行下载任务\n", getpid(), getppid());
sleep(1);
}
}
else
{
while (1)
{
printf("我是父进程,我的pid是%d, ppid是%d, 我正在执行播放任务\n", getpid(), getppid());
sleep(1);
}
}
return 0;
}
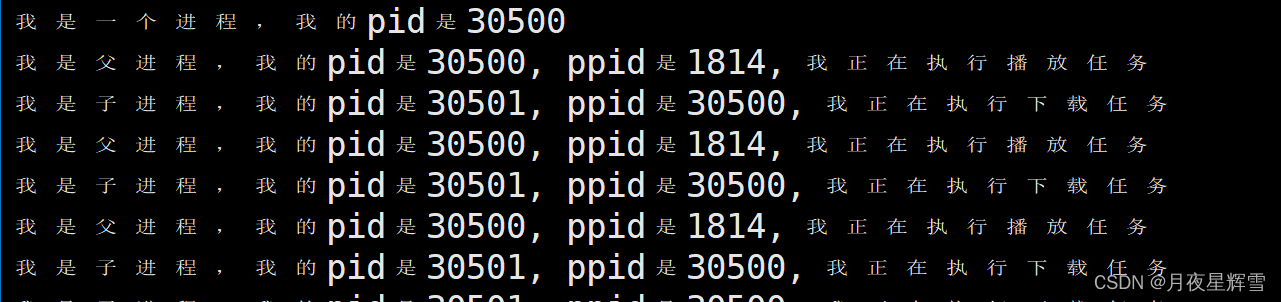
五.对于fork的理解
看完fork的用法后,大家可能会存在以下的疑问:
- fork干了什么事情?
- 为什么fork会有两个返回值?
- 为什么fork的两个返回值,会给父进程返回子进程的pid,给子进程返回0?
- 如何理解同一个变量,会有不同的值?
- fork之后,父子进程谁先运行?
1.fork干了些什么?
fork创建子进程,系统会多一个子进程:
1.以父进程为模版,为子进程创建PCB
2.但是fork创建的子进程,是没有代码和数据的,只能暂时共享父进程的代码和数据,所以fork之后父子进程会执行一样的代码
等一下!子进程会执行fork之后的代码,那fork之前呢?子进程看不到fork之前的代码吗?答案是都能看到。那么为什么子进程不从头开始执行呢?
还记得我们以前学语言的时候吗?我们被老师告知,程序是从上到下按顺序执行的。这是因为当一个进程运行时,CPU内有一个寄存器eip,这个寄存器中保存着当前正在执行的指令的下一条指令(代码就是一条条指令),当执行完一个指令时,它会自动更新到下一个。
因为父进程已经执行fork完毕,eip指向的是fork后续的代码,而eip也会被子进程继承!!!
2.fork为什么给子进程返回0,给父进程返回子进程的pid?
(注意这个问题不是说为什么fork有两个返回值,我们先接受有两个返回值的事实。)
一个父进程可能有多个子进程,而子进程只有一个父进程。如果父进程要管理子进程,就要标识子进程的唯一性,而子进程要访问父进程则不需要
例如一个父亲有三个儿子,父亲喊:”儿子,过来一下!“。三个儿子蒙了,到底是喊的谁呢?所以父亲只能喊名字,”张三,你过来一下!“ 老大张三就知道是在喊他了。但是任意一个儿子要找父亲直接喊”爸爸,你过来一下“。这样父亲就明白是在喊他,儿子不用喊父亲的名字。
3.fork之后父子进程谁先运行?
创建完成子进程,只是一个开始,创建完成子进程之后,系统的其它进程,父进程,和子进程,接下来是要被调度执行的。
当父子进程的PCB都被创建并在运行队列中排队的时候,哪一个进程的PCB先被选择调度,哪个进程就先运行。
换句话说,父子进程哪个先运行我们用户是不确定的,这个是由各自PCB中的调度信息(时间片,优先级)+ 调度算法决定的,简单地说,由操作系统决定
4.fork为什么会有两个返回值?
如果一个函数已经执行到return了,它的核心工作做完了吗?答案是肯定的。
而fork就是一个函数,它执行了以下的工作:
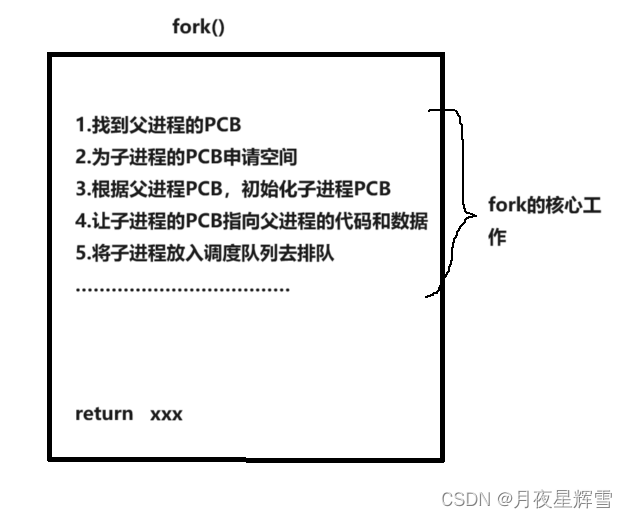
前面说过,父子进程都要执行fork之后的代码。那么return语句是代码吗?肯定是的。而在return之前进程创建进程的工作已经完成了,所以fork会return两次!!!实际上操作系统是通过一些寄存器做到的,一个寄存器接收一个返回值。
5.一个变量怎么可能会有两个值?
在代码中,我们用id这个变量来接受fork的返回值,怎么在子进程中是0,在父进程中又是别的值了呢?
在解释这个问题之前,先做个铺垫。
如果父进程被杀掉,子进程还在吗?子进程被杀掉,父进程还在吗?大家可以通过kill -9指令杀掉进程,然后用ps指令查看,来验证一下。我直接给出结论,进程之间运行的时候,是有独立性的,无论什么关系
进程的独立性,首先表现在有各自的PCB,其次进程之间不会互相影响。
但是前面说过子进程会共享父进程的代码和数据,怎么不会相互影响呢?
第一,代码本身是只读的,不会影响。如果父进程被杀掉,本来要释放代码,但是发现子进程也在用这份代码,所以代码留着,只释放自己的PCB,所以子进程还能运行。又因为父子进程都不会修改代码,所以互不影响。
但是,数据父子是会修改的呀!例如有一个全局变量,父进程里把它从1修改成0,然后子进程里有一段逻辑:如果这个变量是0就直接退出,那么父进程不就影响子进程了吗?
所以,得到的结论就是,代码共享,数据各个进程必须想办法各自私有一份!
那么操作系统是如何保证进程的数据私有呢?理论上来说,在创建子进程时,直接把父进程的数据拷贝一份,让子进程PCB指向新的数据,这样肯定是能行的。但有可能父进程里有100个变量,但子进程只需要修改2个变量的值,剩下的98个变量只需读一下,或者压根用不到,那么直接拷贝岂不是血亏?
所以操作系统采用一种写时拷贝的技术,如果不修改数据我就让父子共享,否则就把要修改的变量给子进程单独拷贝一份。
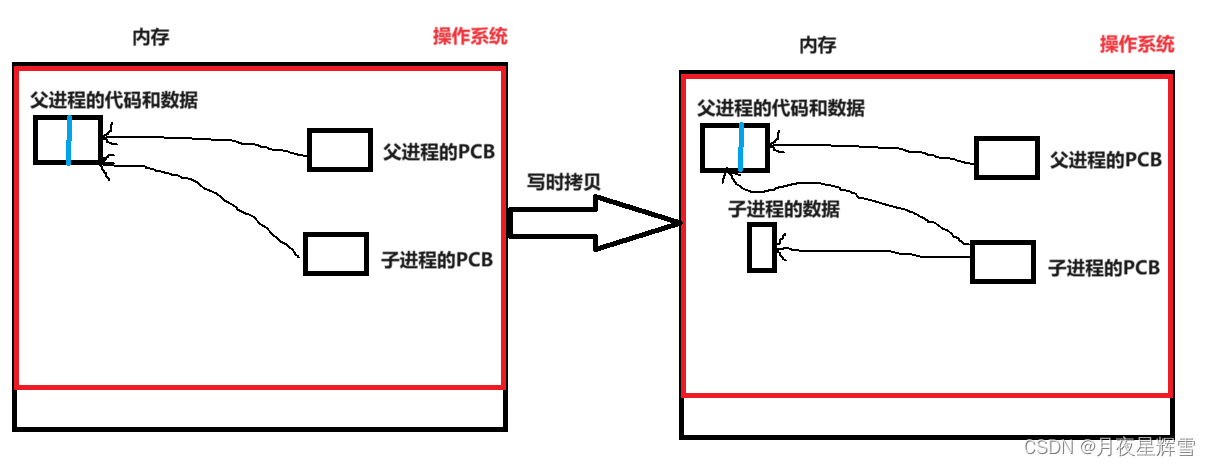
fork的返回值用变量id接收,那么fork返回值给id的本质就是写入,而id是父进程创建的变量,里面保存的就是数据,所以fork返回的时候发生了写时拷贝,所以同一个变量会有不同的值
可能讲到这里还是不太明白,为什么同一个变量有两个值。写时拷贝就写时拷贝呗,可我用的是同一个变量呀,难道两个进程中的变量id不是同一个吗?
int main()
{
printf("我是一个进程,我的pid是%d\n", getpid());//这个函数只执行了一次
pid_t id = fork();
if (id == -1)
{
return -1;
}
else if (id == 0)
{
while (1)
{
printf("我是子进程,我的pid是%d, ppid是%d, &id=%p, 我正在执行下载任务\n", getpid(), getppid(), &id);
sleep(1);
}
}
else
{
while (1)
{
printf("我是父进程,我的pid是%d, ppid是%d &id=%p, 我正在执行播放任务\n", getpid(), getppid(), &id);
sleep(1);
}
}
return 0;
}

结果证明,id的地址竟然是一样的,真是令人匪夷所思,如果是一样的,怎么可能同一个地址会有不同的值呢?
这个问题暂时无法解答,后面讲到进程地址空间的知识再回过头来解答这个问题。