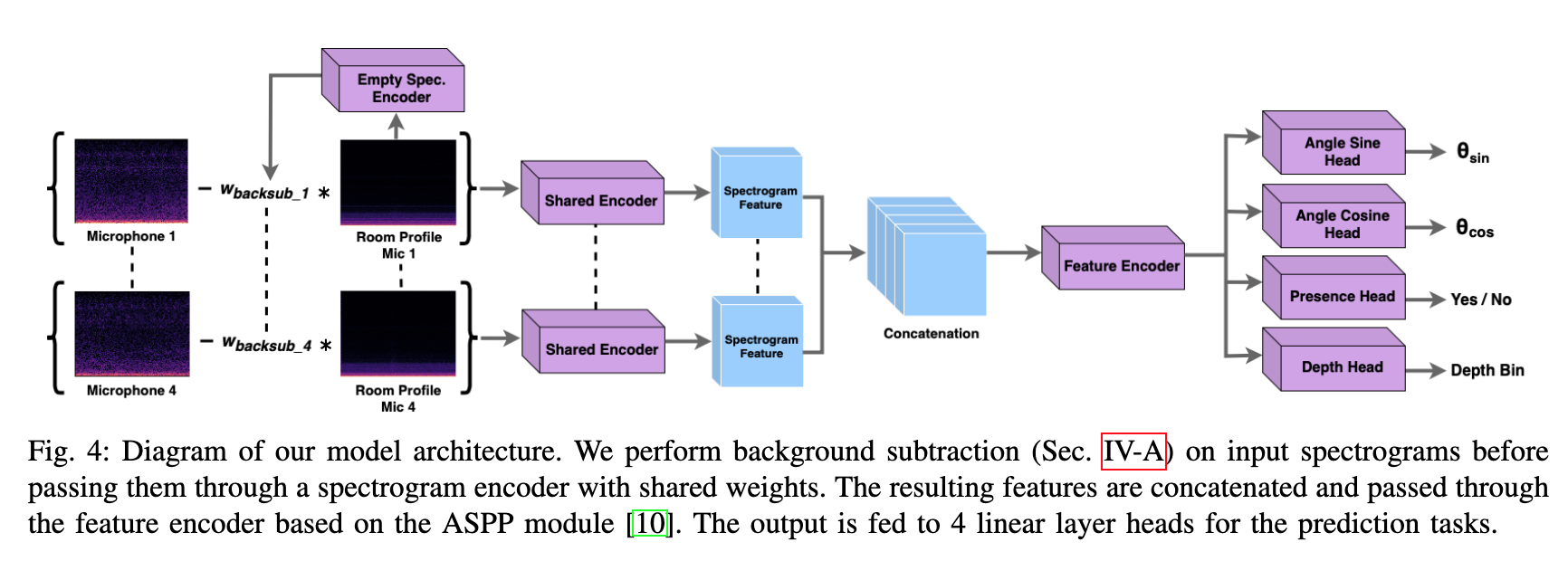
第7章 航空公司客户价值分析
- 7.1 了解航空公司现状与客户价值分析
- 7.1.1 了解航空公司现状
- 7.1.2 认识客户价值分析
- 7.1.3 熟悉航空客户价值分析的步骤与流程
- 7.2 预处理航空客户数据
- 7.2.1 处理数据缺失值与异常值
- 7.2.2 构建航空客户价值分析的关键特征
- 1. RFM模型介绍
- 2. RFM模型结果解读
- 3. 传统RFM模型在航空行业的缺陷
- 4. 航空客户价值分析的LRFMC模型
- 7.2.3 标准化LRFMC五个特征
- 7.2.4 代码
- 7.3 使用K-Means算法进行客户分群
- 7.3.1 了解K-Means聚类算法
- 1. 基本概念
- 2. 数据类型
- 3. kmeans函数及其参数介绍
- 7.3.2 分析聚类结果
- 7.3.3 模型应用
- 7.3.4 代码
7.1 了解航空公司现状与客户价值分析
7.1.1 了解航空公司现状
目前航空公司已积累了大量的会员档案信息和其乘坐航班记录。
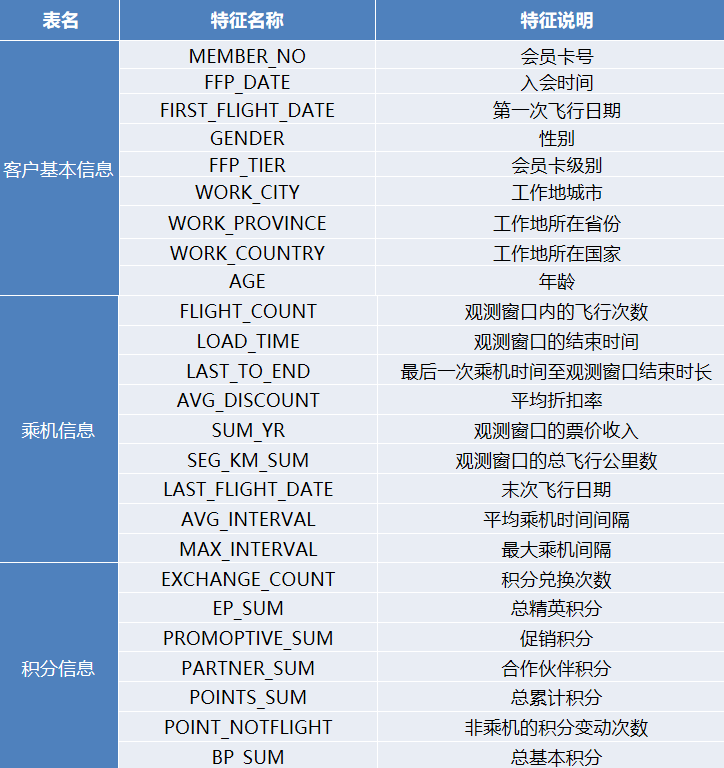
以2014-03-31为结束时间,选取宽度为两年的时间段作为分析观测窗口,抽取观测窗口内有乘机记录的所有客户的详细数据形成历史数据,44个特征,总共62988条记录。其中包含了会员卡号、入会时间、性别、年龄、会员卡级别、工作地城市、工作地所在省份、工作地所在国家、观测的窗口结束时间、总累计积分、观测窗口的总飞行千米数、观测窗口内的飞行次数、平均乘机时间间隔和平均折扣系数等特征。
数据特征及其说明如下表所示:
结合目前航空公司的数据情况,可以实现以下目标。
- 借助航空公司客户数据,对客户进行分类。
- 对不同的客户类别进行特征分析,比较不同类别客户的客户价值。
- 对不同价值的客户类别提供个性化服务,制定相应的营销策略。
7.1.2 认识客户价值分析
客户营销战略倡导者Jay & Adam Curry从国外数百家公司进行了客户营销实施的经验中提炼了如下经验。
公司收入的80%来自顶端的20%的客户。
20%的客户其利润率100%。
90%以上的收入来自现有客户。
大部分的营销预算经常被用在非现有客户上。
5%至30%的客户在客户金字塔中具有升级潜力。
客户金字塔中客户升级2%,意味着销售收入增加10%,利润增加50%。
这些经验也许并不完全准确,但是它揭示了新时代客户分化的趋势,也说明了对客户价值分析的迫切性和必要性。
7.1.3 熟悉航空客户价值分析的步骤与流程
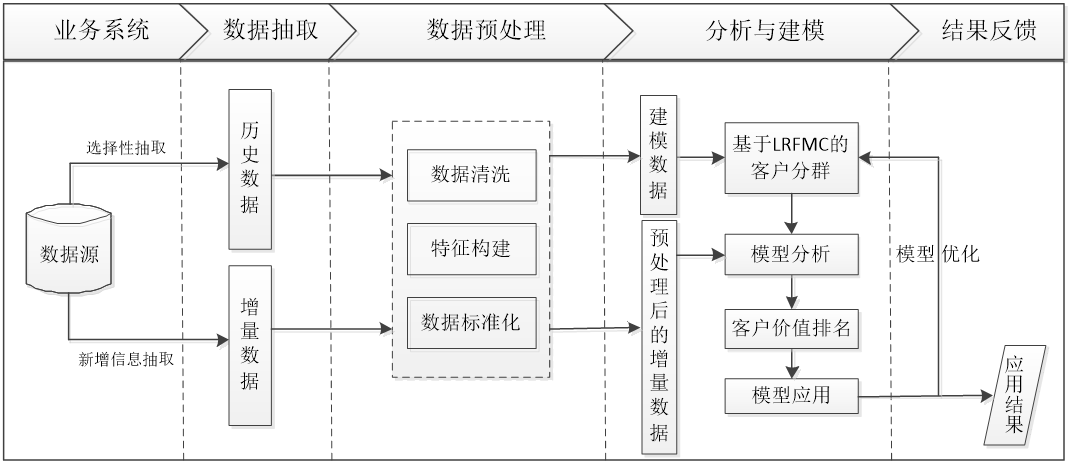
航空客户价值分析项目的总体流程如图所示,主要包括4个步骤:
- 抽取航空公司2012年4月1日到2014年3月31日的数据。
- 对抽取的数据进行数据清洗、特征构建和标准化等操作。
- 基于RFM模型,使用K-Means算法进行客户分群。
- 针对模型结果得到不同价值的客户,采用不同的营销手段,提供定制化的服务。
7.2 预处理航空客户数据
航空公司客户原始数据存在少量的缺失值和异常值,需要清洗后才能用于分析。同时由于原始数据的特征过多,不便直接用于客户价值分析,因此需要对特征进行筛选,挑选出衡量客户价值的关键特征。
对航空客户数据进行预处理可以分为3个步骤:
- 处理数据缺失值与异常值。
- 结合RFM模型筛选特征。
- 标准化筛选后的数据。
7.2.1 处理数据缺失值与异常值
通过对数据观察发现原始数据中存在票价为空值,票价最小值为0,折扣率最小值为0,总飞行公里数大于0的记录。
票价为空值的数据可能是客户不存在乘机记录造成。其他的数据可能是客户乘坐0折机票或者积分兑换造成。由于原始数据量大,这类数据所占比例较小,对于问题影响不大,因此对其进行丢弃处理。
处理方法:
1.丢弃票价为空的记录。
2.保留票价非0,或者平均折扣率不为0且总飞行公里数大于0的记录。
7.2.2 构建航空客户价值分析的关键特征
本项目的目标是客户价值分析,即通过航空公司客户数据识别不同价值的客户,识别客户价值应用最广泛的模型是RFM模型。
1. RFM模型介绍
R(Recency)指的是最近一次消费时间与截止时间的间隔。通常情况下,最近一次消费时间与截止时间的间隔越短,对即时提供的商品或是服务也最有可能感兴趣。
F(Frequency)指顾客在某段时间内所消费的次数。可以说消费频率越高的顾客,也是满意度越高的顾客,其忠诚度也就越高,顾客价值也就越大。
M(Monetary)指顾客在某段时间内所消费的金额。消费金额越大的顾客,他们的消费能力自然也就越大,这就是所谓“20%的顾客贡献了80%的销售额”的二八法则。
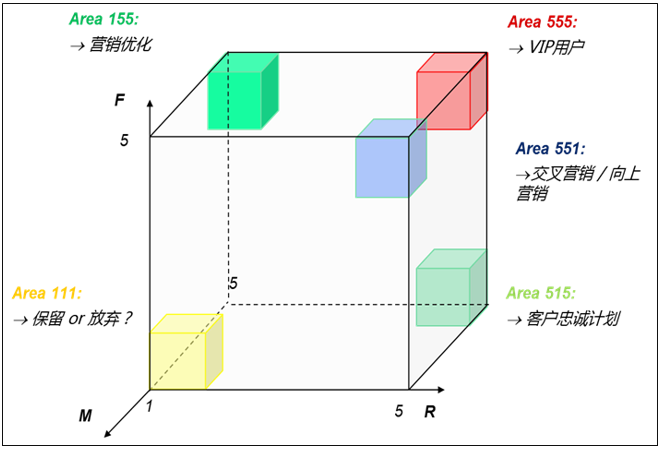
2. RFM模型结果解读
RFM模型包括三个特征,使用三维坐标系进行展示,如图所示。X轴表示Recency,Y轴表示Frequency,Z轴表示Monetary,每个轴一般会分成5级表示程度,1为最小,5为最大。
3. 传统RFM模型在航空行业的缺陷
在RFM模型中,消费金额表示在一段时间内,客户购买该企业产品金额的总和,由于航空票价受到运输距离,舱位等级等多种因素影响,同样消费金额的不同旅客对航空公司的价值是不同的,因此这个特征并不适合用于航空公司的客户价值分析。
4. 航空客户价值分析的LRFMC模型
本项目选择客户在一定时间内累积的飞行里程M和客户在一定时间内乘坐舱位所对应的折扣系数的平均值C两个特征代替消费金额。此外,航空公司会员入会时间的长短在一定程度上能够影响客户价值,所以在模型中增加客户关系长度L,作为区分客户的另一特征。
本项目将客户关系长度L,消费时间间隔R,消费频率F,飞行里程M和折扣系数的平均值C作为航空公司识别客户价值的关键特征(如下表所示),记为LRFMC模型。

根据LRFMC模型,选择与LRFMC特征相关的6个特征:FFP_DATE、LOAD_TIME、FLIGHT_COUNT、AVG_DISCOUNT、SEG_KM_SUM、LAST_TO_END。删除与其不相关、弱相关或冗余的特征,例如会员卡号、性别、工作地、年龄等。
L = LOAD_TIME - FFP_DATE
R = LAST_TO_END
F = FLIGHT_COUNT
M = SEG_KM_SUM
C = AVG_DISCOUNT
7.2.3 标准化LRFMC五个特征
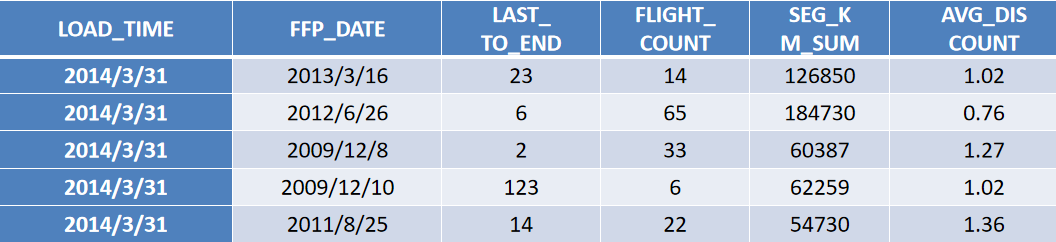
完成五个特征的构建以后,对每个特征数据分布情况进行分析,其数据的取值范围如表所示。从表中数据可以发现,五个特征的取值范围数据差异较大,为了消除数量级数据带来的影响,需要对数据做标准化处理。

L、R、F、M和C五个特征的数据示例,上图为原始数据,下图为标准差标准化处理后的数据。
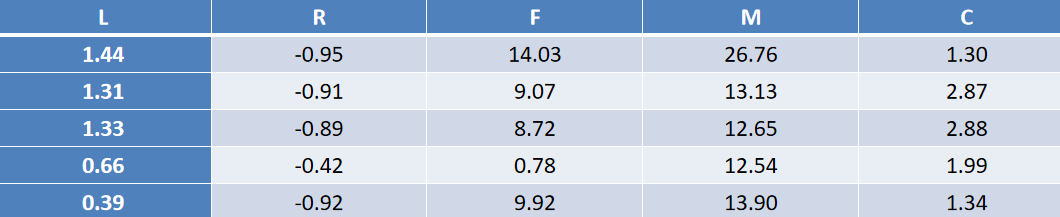
7.2.4 代码
# 代码 7-1 缺失值与异常值处理
import numpy as np
import pandas as pd
airline_data = pd.read_csv(
"F:/书籍\Python数据分析与应用/37304_Python数据分析与应用_源代码和实验数据"
"/第7章/data/air_data.csv",
encoding="gb18030") # 导入航空数据
print('原始数据的形状为:', airline_data.shape)
## 去除票价为空的记录
exp1 = airline_data["SUM_YR_1"].notnull()
exp2 = airline_data["SUM_YR_2"].notnull()
exp = exp1 & exp2
airline_notnull = airline_data.loc[exp, :]
print('删除缺失记录后数据的形状为:', airline_notnull.shape)
# 只保留票价非零的,或者平均折扣率不为0且总飞行公里数大于0的记录。
index1 = airline_notnull['SUM_YR_1'] != 0
index2 = airline_notnull['SUM_YR_2'] != 0
index3 = (airline_notnull['SEG_KM_SUM'] > 0) & \
(airline_notnull['avg_discount'] != 0)
airline = airline_notnull[(index1 | index2) & index3]
print('删除异常记录后数据的形状为:', airline.shape)
# 代码 7-2 选取并构建LRFMC模型的特征
## 选取需求特征
airline_selection = airline[["FFP_DATE", "LOAD_TIME",
"FLIGHT_COUNT", "LAST_TO_END",
"avg_discount", "SEG_KM_SUM"]]
## 构建L特征
L = pd.to_datetime(airline_selection["LOAD_TIME"]) - \
pd.to_datetime(airline_selection["FFP_DATE"])
L = L.astype("str").str.split().str[0]
L = L.astype("int") / 30
## 合并特征
airline_features = pd.concat([L,
airline_selection.iloc[:, 2:]], axis=1)
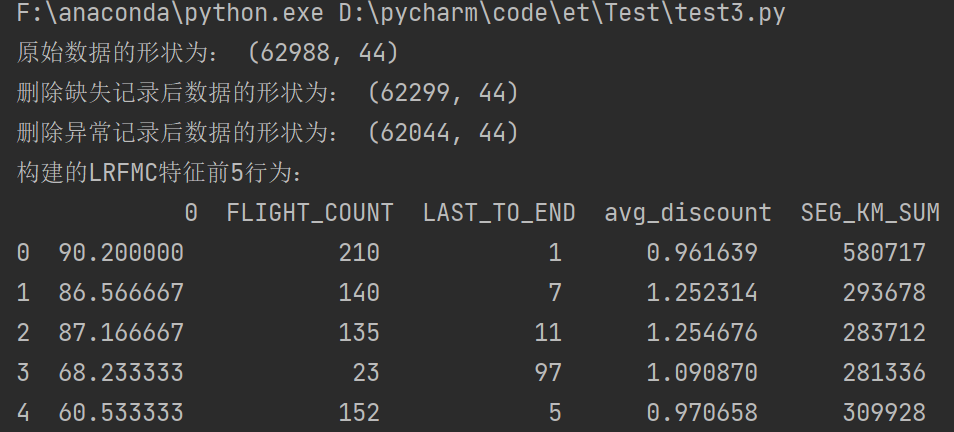
print('构建的LRFMC特征前5行为:\n', airline_features.head())
# 代码 7-3 标准化LRFMC模型的特征
from sklearn.preprocessing import StandardScaler
data = StandardScaler().fit_transform(airline_features)
np.savez('F:/书籍/Python数据分析与应用/37304_Python数据分析与应用_源代码和实验数据/第7章/airline_scale.npz',data)
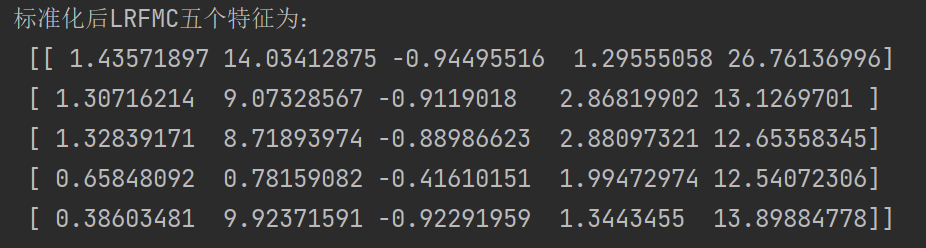
print('标准化后LRFMC五个特征为:\n', data[:5, :])
7.3 使用K-Means算法进行客户分群
7.3.1 了解K-Means聚类算法
1. 基本概念
K-Means聚类算法是一种基于质心的划分方法,输入聚类个数k,以及包含n个数据对象的数据库,输出满足误差平方和最小标准的k个聚类。算法步骤如下。
(1)从n个样本数据中随机选取k个对象作为初始的聚类中心。
(2)分别计算每个样本到各个聚类质心的距离,将样本分配到距离最近的那个聚类中心类别中。
(3)所有样本分配完成后,重新计算k个聚类的中心。
(4)与前一次计算得到的k个聚类中心比较,如果聚类中心发生变化,转(2),否则转(5)。
(5)当质心不发生变化时停止并输出聚类结果。
2. 数据类型
K-Means聚类算法是在数值类型数据的基础上进行研究,然而数据分析的样本复杂多样,因此要求不仅能够对特征为数值类型的数据进行分析,还要适应数据类型的变化,对不同特征做不同变换,以满足算法的要求。
3. kmeans函数及其参数介绍
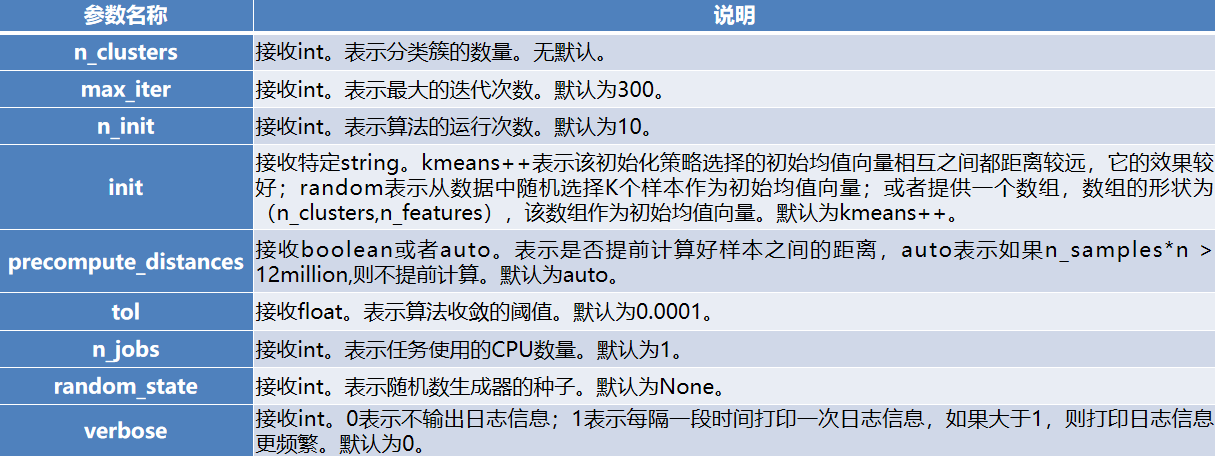
sklearn的cluster模块提供了KMeans函数构建K-Means聚类模型,其基本语法如下。
sklearn.cluster.KMeans(n_clusters=8, init=‘k-means++’, n_init=10, max_iter=300, tol=0.0001,precompute_distances=‘auto’, verbose=0, random_state=None, copy_x=True, n_jobs=1,algorithm=‘auto’)
常用参数及其说明如表所示。
K-Means模型构建完成后可以通过属性查看不同的信息,如表所示。

7.3.2 分析聚类结果
对数据进行聚类分群的结果如表所示。
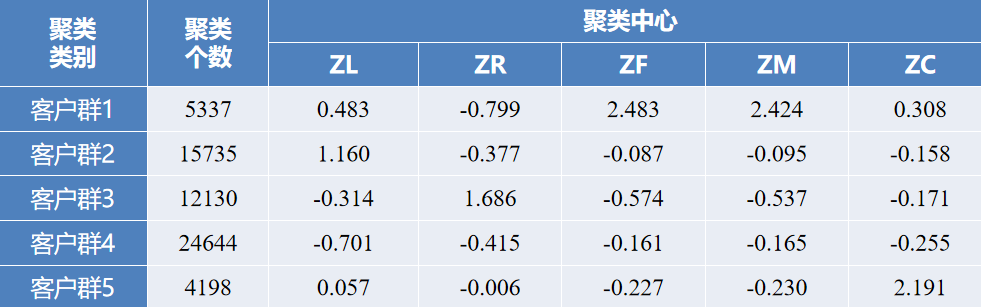
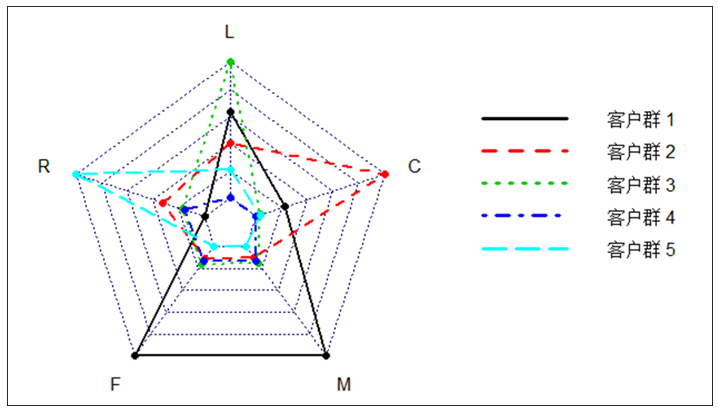
针对聚类结果进行特征分析,如图所示。
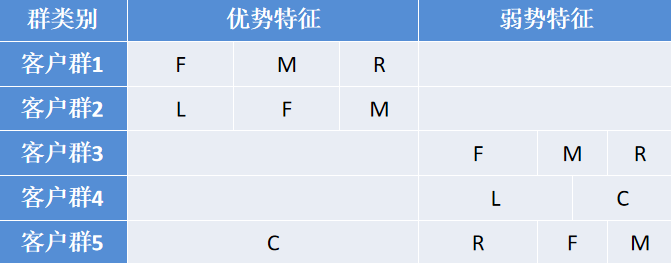
结合业务分析,通过比较各个特征在群间的大小对某一个群的特征进行评价分析,从而总结出每个群的优势和弱势特征,具体结果如表所示。
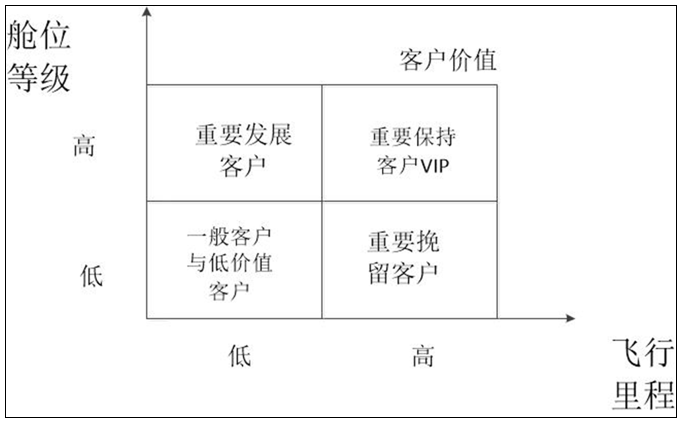
基于特征描述,本项目定义五个等级的客户类别:重要保持客户,重要发展客户,重要挽留客户,一般客户,低价值客户。每种客户类别的特征如图所示。

7.3.3 模型应用
根据对各个客户群进行特征分析,采取下面的一些营销手段和策略,为航空公司的价值客户群管理提供参考。
1、会员的升级与保级:航空公司可以在对会员升级或保级进行评价的时间点之前,对那些接近但尚未达到要求的较高消费客户进行适当提醒甚至采取一些促销活动,刺激他们通过消费达到相应标准。这样既可以获得收益,同时也提高了客户的满意度,增加了公司的精英会员。
2、首次兑换:采取的措施是从数据库中提取出接近但尚未达到首次兑换标准的会员,对他们进行提醒或促销,使他们通过消费达到标准。一旦实现了首次兑换,客户在本公司进行再次消费兑换就比在其他公司进行兑换要容易许多,在一定程度上等于提高了转移的成本。
3、交叉销售:通过发行联名卡等与非航空类企业的合作,使客户在其他企业的消费过程中获得本公司的积分,增强与公司的联系,提高他们的忠诚度。
7.3.4 代码
# 代码 7-4 航空客户价值分析K-Means聚类
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans #导入kmeans算法
airline_scale = np.load('F:/书籍/Python数据分析与应用/37304_Python数据分析与应用_源代码和实验数据/第7章/airline_scale.npz')['arr_0']
k = 5 ## 确定聚类中心数
#构建模型
# kmeans_model = KMeans(n_clusters = k,n_jobs=4,random_state=123)
kmeans_model = KMeans(n_clusters = k, random_state=123)
fit_kmeans = kmeans_model.fit(airline_scale) #模型训练
kmeans_model.cluster_centers_ #查看聚类中心
kmeans_model.labels_ #查看样本的类别标签
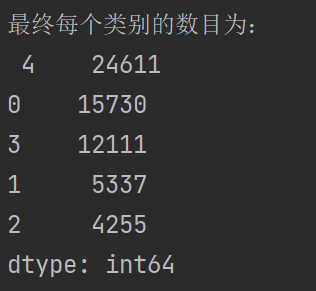
#统计不同类别样本的数目
r1 = pd.Series(kmeans_model.labels_).value_counts()
print('最终每个类别的数目为:\n',r1)



![[算法应用]关键路径算法的简单应用](https://img-blog.csdnimg.cn/11c2019d349146b6b99eb229051bae20.png)


![[架构之路-228]:目标系统 - 纵向分层 - 计算机硬件与体系结构 - 硬盘存储结构原理:如何表征0和1,即如何存储0和1,如何读数据,如何写数据(修改数据)](https://img-blog.csdnimg.cn/img_convert/ec8a420edd3c717b8212414255d52239.png)