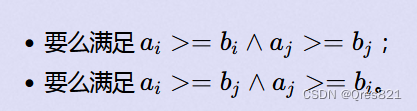Part15-Query Planning & Optimization II
Selection Statistics
维护每张表中的基本主要信息也就是tuple数量 N R N_R NR以及每个属性中不同值的数量 V ( A , R ) V(A,R) V(A,R), N R N_R NR关系R中的元组数量,单独维护,不能用page * 每个page中的tuple数,因为mvcc 或者 填不满tuple。selection cardinality (SC(A,R)) 选择基数,tuple数量除以属性A下 去重之后值的数量来计算出 选择基数。
假设数据均匀分布,data uniformity
Complex Predicates
selectivity(sel)选择率针对该表的一个给定的选择条件P,会计算出该表中有多少符合条件的tuple。
例子: V(age,people) 0-4, Nr = 5,Equality Predicate:A=constant → sel(A = const) = SC§ / Nr。 sel(age=2) = 1 5 \frac{1}{5} 51
Range Predict:sel(A ≥ a) = (Amax - a) / (Amax - Amin) Example : sel(age ≥ 2) = (4-2) / (4-0) = 1/2
Negation Query:sel (not P) = 1 - sel§, sel(age≠2) = 1-1/5 = 4/5
条件选择率selectivity ≈ Probability
Conjunction:sel(P1 ∩ \cap ∩ P2) = sel(P1) * sel(P2)
Disjunction: sel(P1 ∪ \cup ∪ P2) = sel(P1) + sel(P2) - sel(P1) * sel(P2)
上述假设前提1. uniform data 2. independent predicates 3. inclusion principle(嵌套原则:inner table 的 tuple outer table中一定有匹配)
Cost Estimations
data values uniformly distributed

equi-width Histogram

Histograms with Quantiles
调整bucket的宽度,使得每个bucket的count总和都大致相等

Sampling
收集samples来维护一张sample样本表,然后根据该样本来衍生出统计信息,样本来估测总体。
Single-Relation Query Planning
- 循序扫描
- binary search
- index scan
- heuristics 启发式方法
OLTP Query Planning
本质上鉴定这个查询是否是sargable(search argument able)的
- 通常pick the best index
- Join几乎总是在小基数的外键关系上
- 可以用简单的启发式规则就能实现
Multi-Relation Query Planning
限制搜索空间,System R:只考虑左深连接树 left-deep join tree,
join operator 可以任意顺序交换来join 但是得到的结果都是一样的。
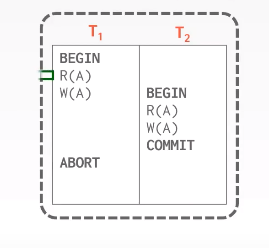
why left-deep join tree? pipelined model可以不用吧中间结果写入临时文件,是流水的
枚举查询计划
- Enumerate the orderings:left -deep tree#1 , …#2
- Enumerate the plans for each operator, hash join\sort-merge join \ nested-loop join …
- Enumerate the acess paths for each table, index #1,#2 ,seq scan …
Dynamic Programming

Postgres Optimizer
-
传统的dynamic programming Approach
-
还有genetic Query Optimizer GEQO遗传查询优化器,查询过于复杂的时候就会选择用遗传算法, 比如≥12个表join就用。模拟退火、遗传算法、启发式

snowflake scheme,对超大表进行拆分,数亿条很长的购买记录进行解耦,雪花模型就是:fact table 在中心,然后diemension在四周,
Nested Sub-Queries
- rewrite to de-correlate and/or flatten them,重写查询来去掉彼此关联性,扁平化处理
- 将内部查询提取出来作为一个单独的查询执行,然后把查询结果传入第一个查询
select name from sailors as S
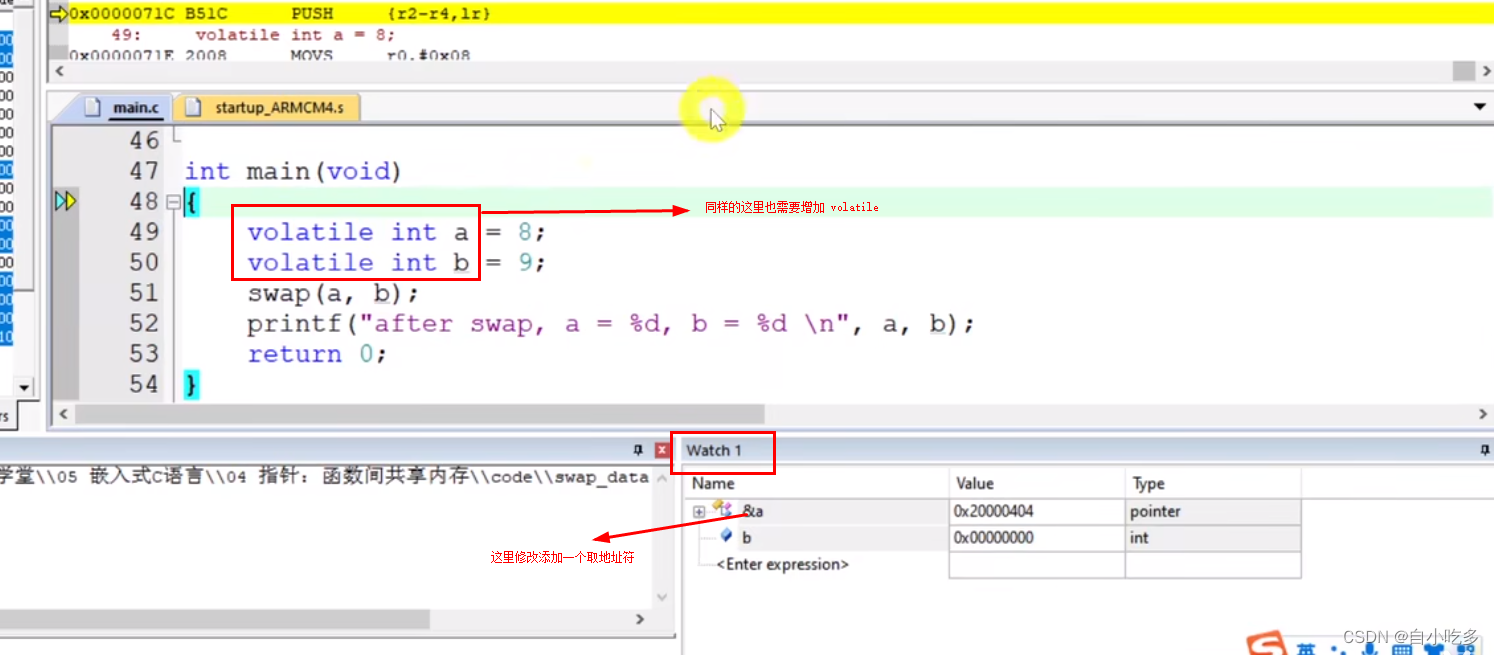
where exists(
select * from reserves as R
where S.sid = R.sid
and R.day = '2018-10-15'
)
# ------------------------------------
select name from sailors as S, reservers AS R
where S.sid = R.sid
and R.day = '2018-10-15'
内外查询是相关的,重写成下面
例子,取出nested block 保存为某个变量,