前言
在学习Java的路上还是遇到了很多不错的好项目的,今天分享给大家,希望能对大家面试有所帮助!
后续会继续推荐其他好的项目,这次推荐的是B站开源的视频黑马头条项目,来吧学会它一起去虐面试官!!!
内容安全第三方接口
概述
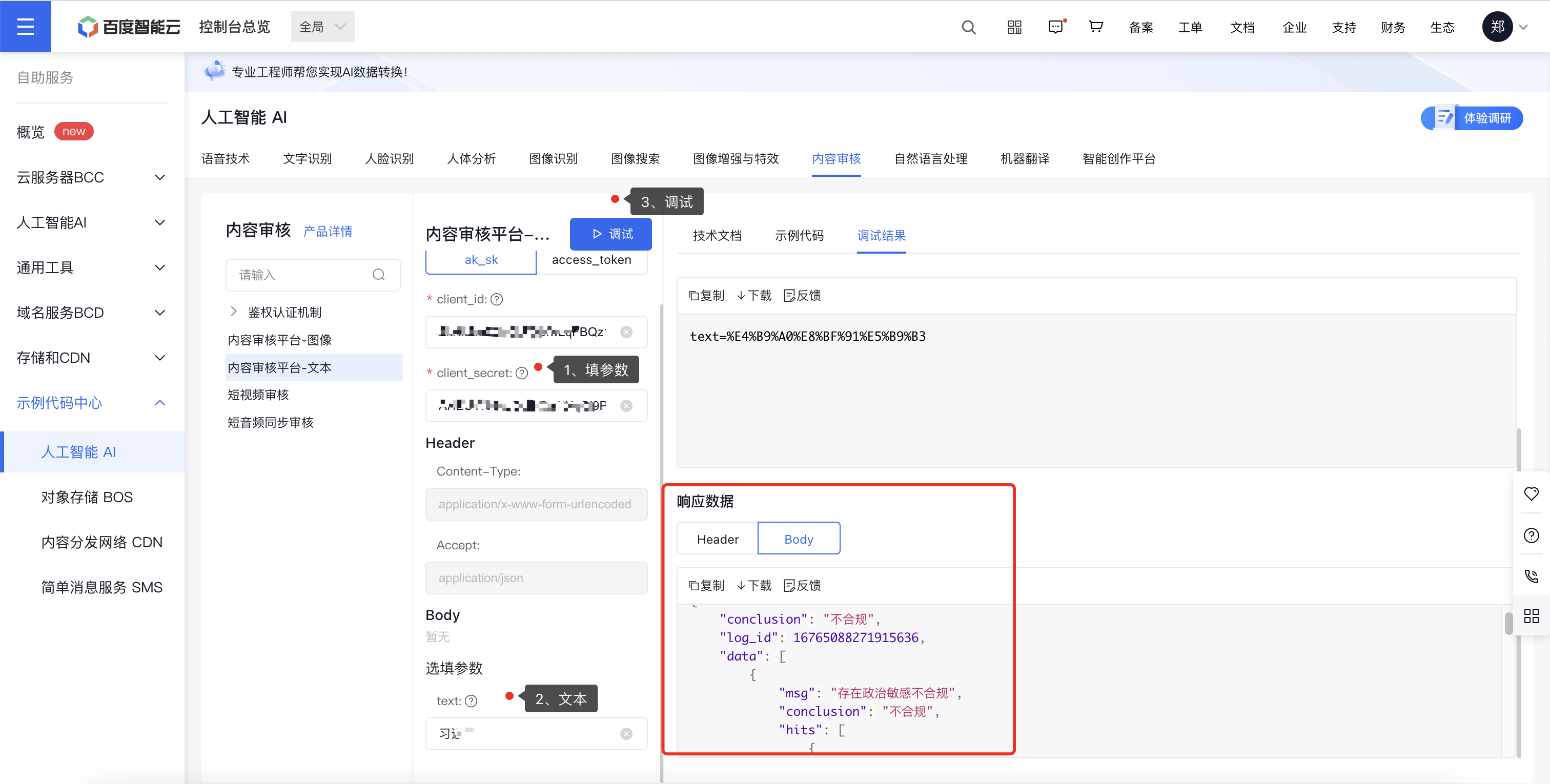
阿里云不好使,这里使用百度云的来进行测试
百度云搜索内容识别即可使用
https://ai.baidu.com/tech/textcensoring
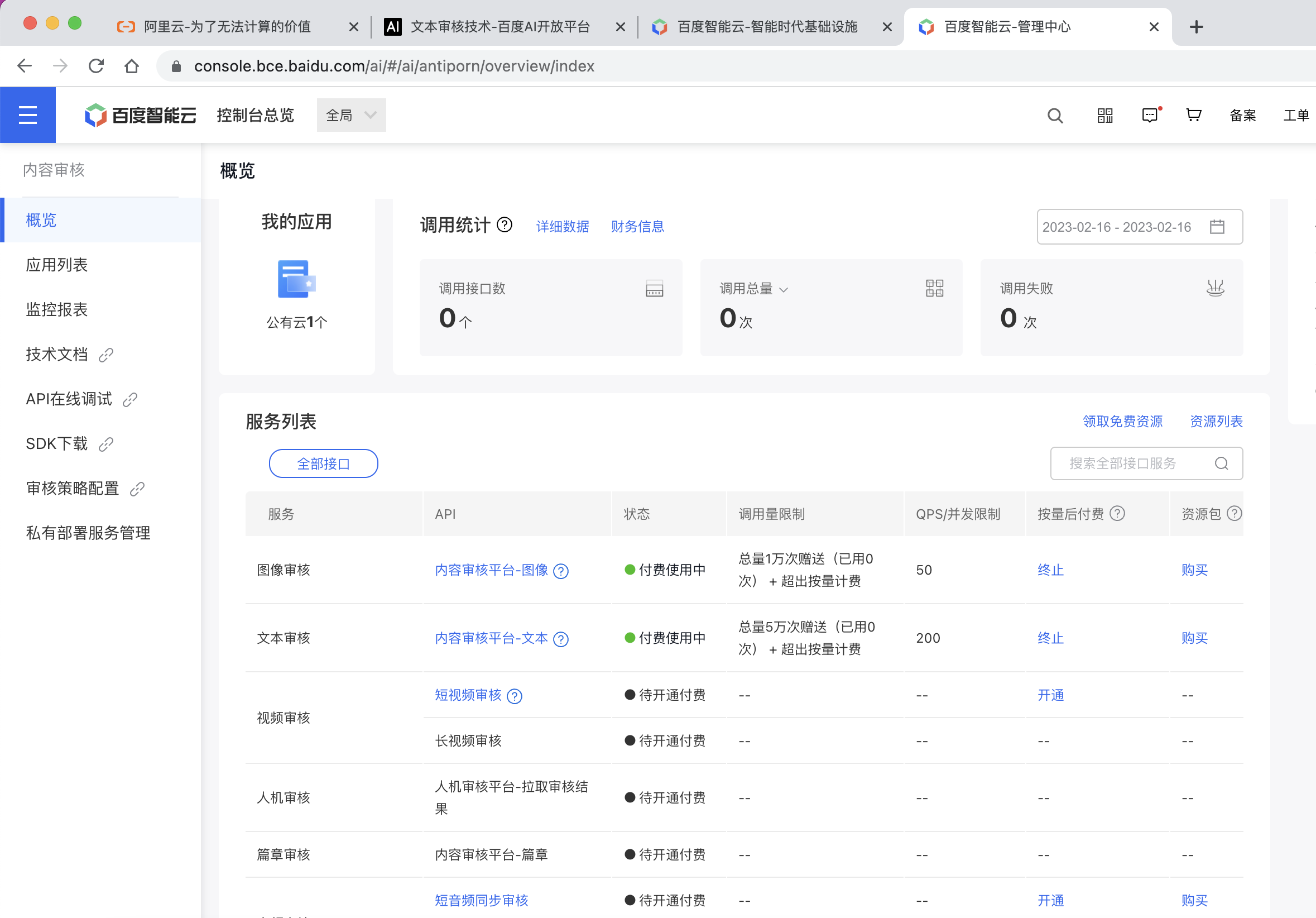
图像测试
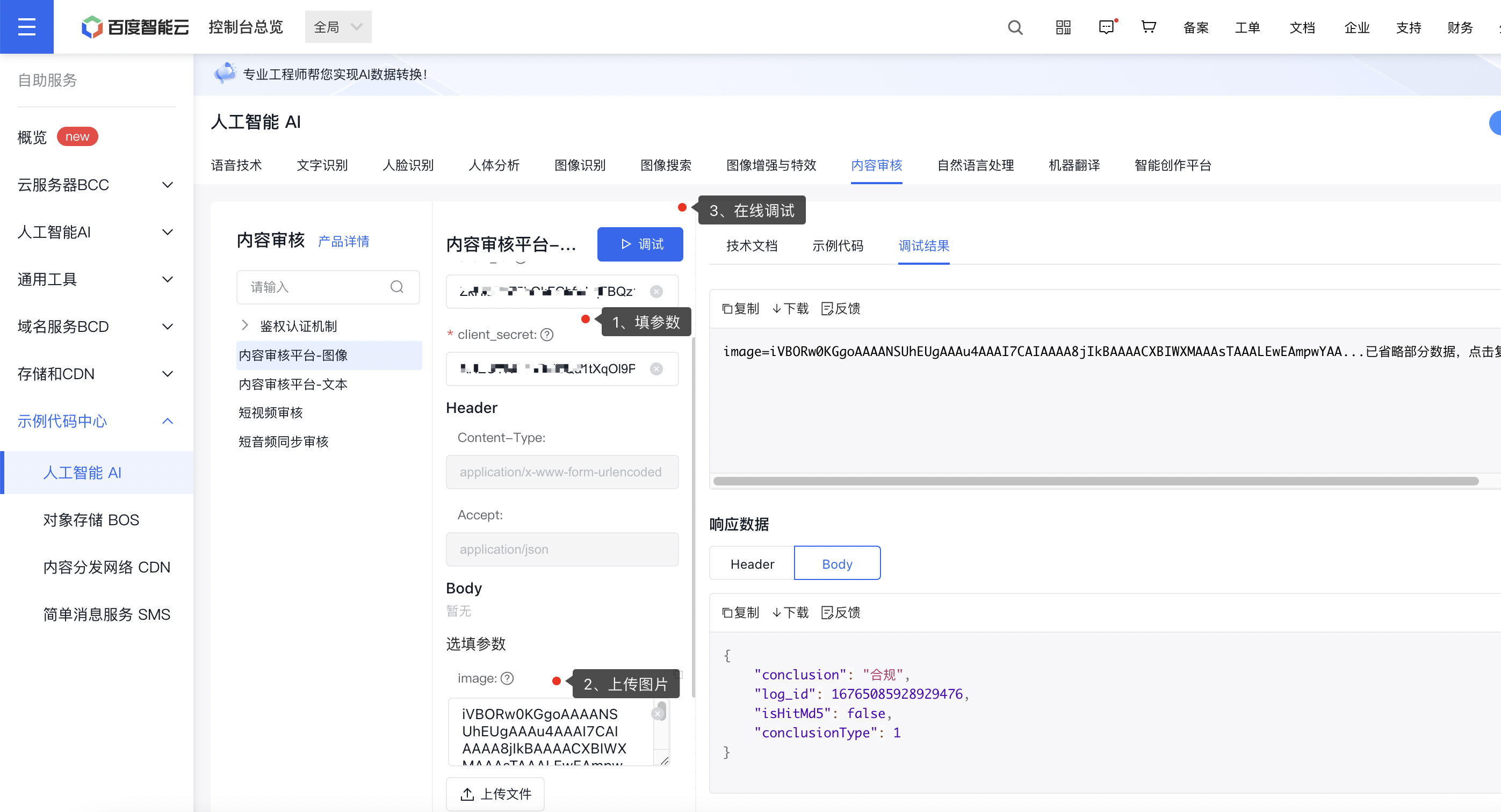
文本测试
代码
百度云所需要的key、secret、appid均写在nacos配置中心
图片检测
package com.heima.common.aip;
import com.baidu.aip.contentcensor.AipContentCensor;
import lombok.Getter;
import lombok.Setter;
import org.json.JSONArray;
import org.json.JSONObject;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
import java.util.HashMap;
import java.util.Map;
@Getter
@Setter
@Component
@ConfigurationProperties(prefix = "aip")
public class GreenImageScan {
//设置APPID/AK/SK
private String APP_ID;
private String API_KEY;
private String SECRET_KEY;
public Map<String, String> imageScan(byte[] imgByte) {
// 初始化一个AipContentCensor
AipContentCensor client = new AipContentCensor(APP_ID, API_KEY, SECRET_KEY);
Map<String, String> resultMap = new HashMap<>();
JSONObject res = client.imageCensorUserDefined(imgByte, null);
System.out.println(res.toString(2));
//返回的响应结果
Map<String, Object> map = res.toMap();
// 获得特殊字段
String conclusion = (String) map.get("conclusion");
if (conclusion.equals("合规")) {
resultMap.put("conclusion", conclusion);
return resultMap;
}
// 获得特殊集合字段
JSONArray dataArrays = res.getJSONArray("data");
String msg = "";
for (Object result : dataArrays) {
//获得原因
msg = ((JSONObject) result).getString("msg");
}
resultMap.put("conclusion", conclusion);
resultMap.put("msg", msg);
return resultMap;
}
}
内容检测
package com.heima.common.aip;
import com.alibaba.fastjson.JSON;
import com.aliyuncs.DefaultAcsClient;
import com.aliyuncs.IAcsClient;
import com.aliyuncs.exceptions.ClientException;
import com.aliyuncs.exceptions.ServerException;
import com.aliyuncs.green.model.v20180509.TextScanRequest;
import com.aliyuncs.http.FormatType;
import com.aliyuncs.http.HttpResponse;
import com.aliyuncs.profile.DefaultProfile;
import com.aliyuncs.profile.IClientProfile;
import com.baidu.aip.contentcensor.AipContentCensor;
import com.google.gson.Gson;
import com.google.gson.JsonArray;
import lombok.Getter;
import lombok.Setter;
import org.json.JSONArray;
import org.json.JSONObject;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
import java.util.*;
@Getter
@Setter
@Component
@ConfigurationProperties(prefix = "aip")
public class GreenTextScan {
//设置APPID/AK/SK
private String APP_ID;
private String API_KEY;
private String SECRET_KEY;
public Map<String, String> testScan(String content) {
// 初始化一个AipContentCensor
AipContentCensor client = new AipContentCensor(APP_ID, API_KEY, SECRET_KEY);
Map<String, String> resultMap = new HashMap<>();
JSONObject res = client.textCensorUserDefined(content);
System.out.println(res.toString(2));
//返回的响应结果
Map<String, Object> map = res.toMap();
// 获得特殊字段
String conclusion = (String) map.get("conclusion");
if (conclusion.equals("合规")) {
resultMap.put("conclusion", conclusion);
return resultMap;
}
// 获得特殊集合字段
JSONArray dataArrays = res.getJSONArray("data");
String msg = "";
for (Object result : dataArrays) {
//获得原因
msg = ((JSONObject) result).getString("msg");
}
resultMap.put("conclusion", "合格");
resultMap.put("msg", msg);
return resultMap;
}
}
App端文章保存接口
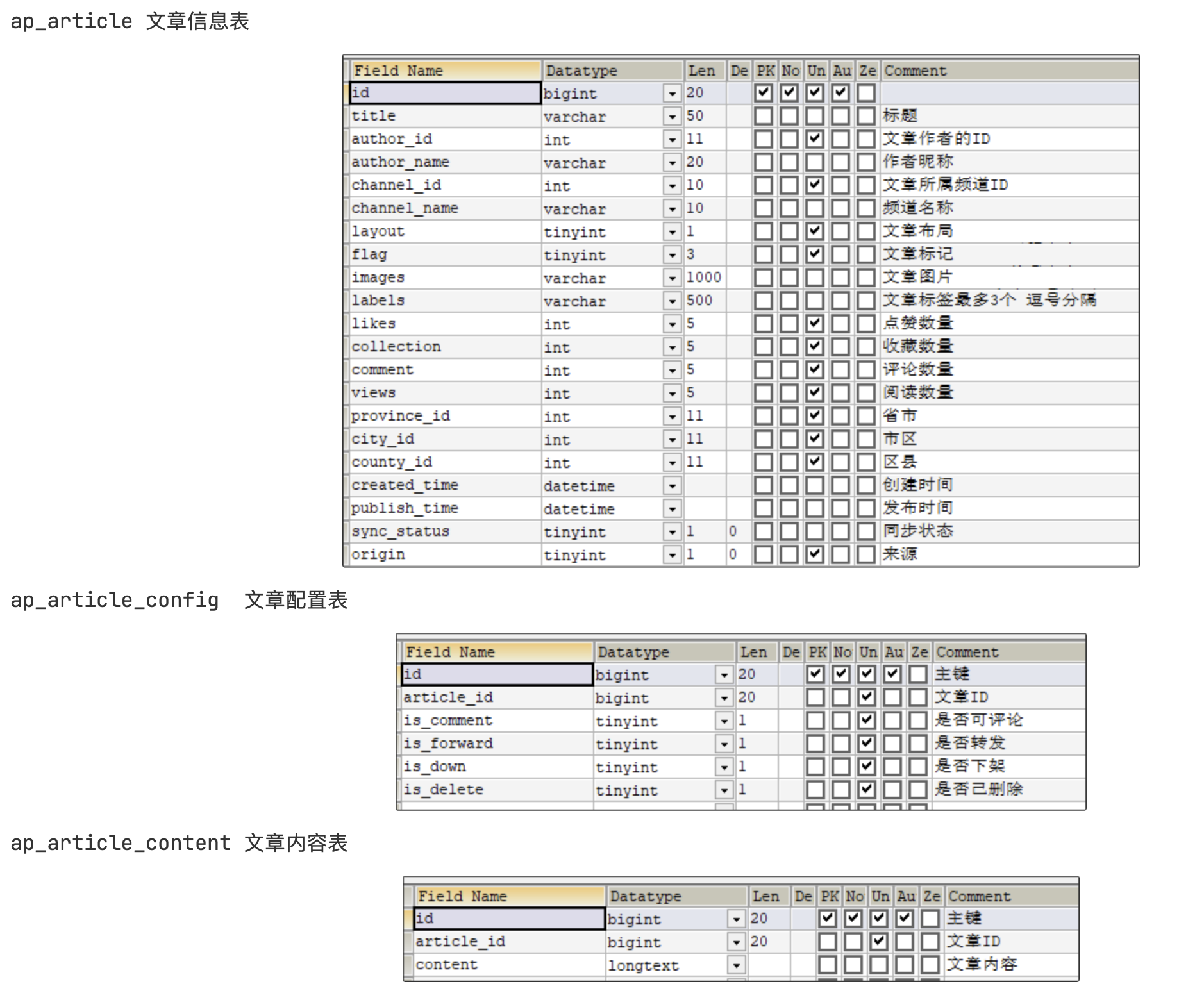
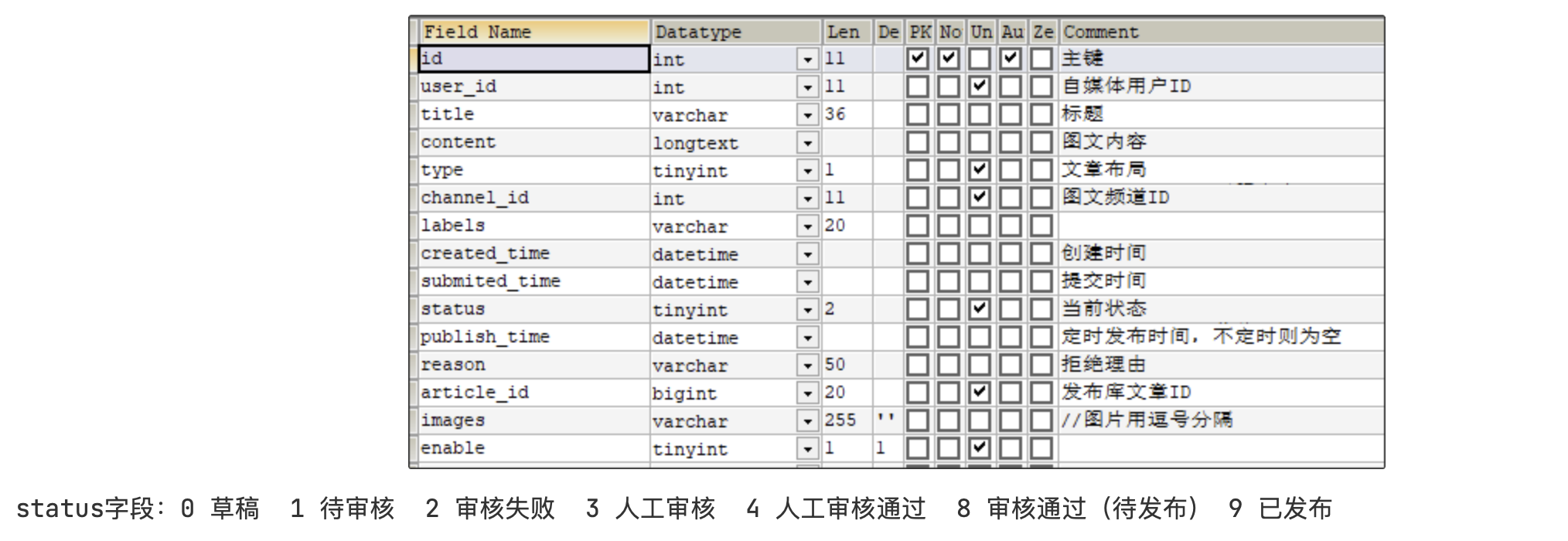
表结构说明
分布式id
分布式系统下,id重复的问题
随着业务的增长,文章表可能要占用很大的物理存储空间,为了解决该问题,后期使用数据库分片技术。将一个数据库进行拆分,通过数据库中间件连接。如果数据库中该表选用ID自增策略,则可能产生重复的ID,此时应该使用分布式ID生成策略来生成ID。
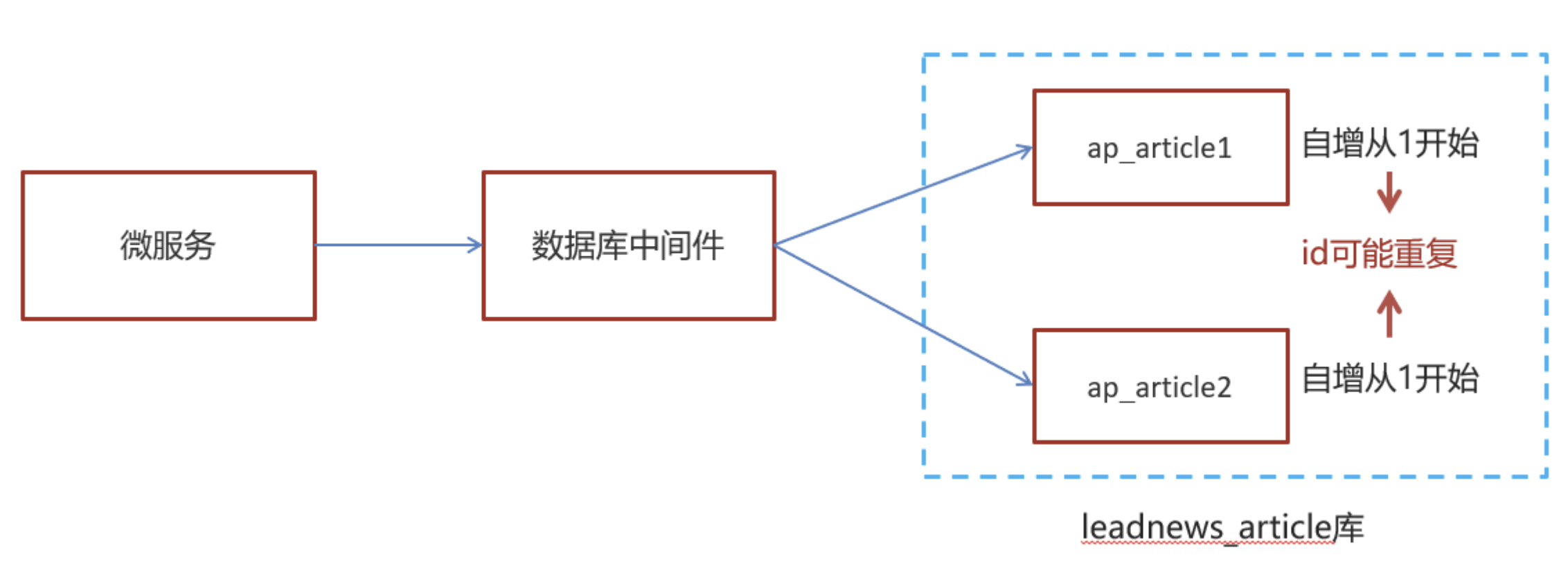
如何解决分布式系统下,id重复的问题?

雪花算法
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数2据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生(2的12次方) 4096 个 ID),最后还有一个符号位,永远是0

文章端相关的表都使用雪花算法生成id,包括ap_article、 ap_article_config、 ap_article_content
mybatis-plus已经集成了雪花算法,完成以下两步即可在项目中集成雪花算法
第一:在实体类中的id上加入如下配置,指定类型为id_worker
@TableId(value = "id",type = IdType.ID_WORKER)
private Long id;
第二:在application.yml文件中配置数据中心id和机器id
mybatis-plus:
mapper-locations: classpath*:mapper/*.xml
# 设置别名包扫描路径,通过该属性可以给包中的类注册别名
type-aliases-package: com.heima.model.article.pojos
global-config:
datacenter-id: 1
workerId: 1
datacenter-id:数据中心id(取值范围:0-31)
workerId:机器id(取值范围:0-31)
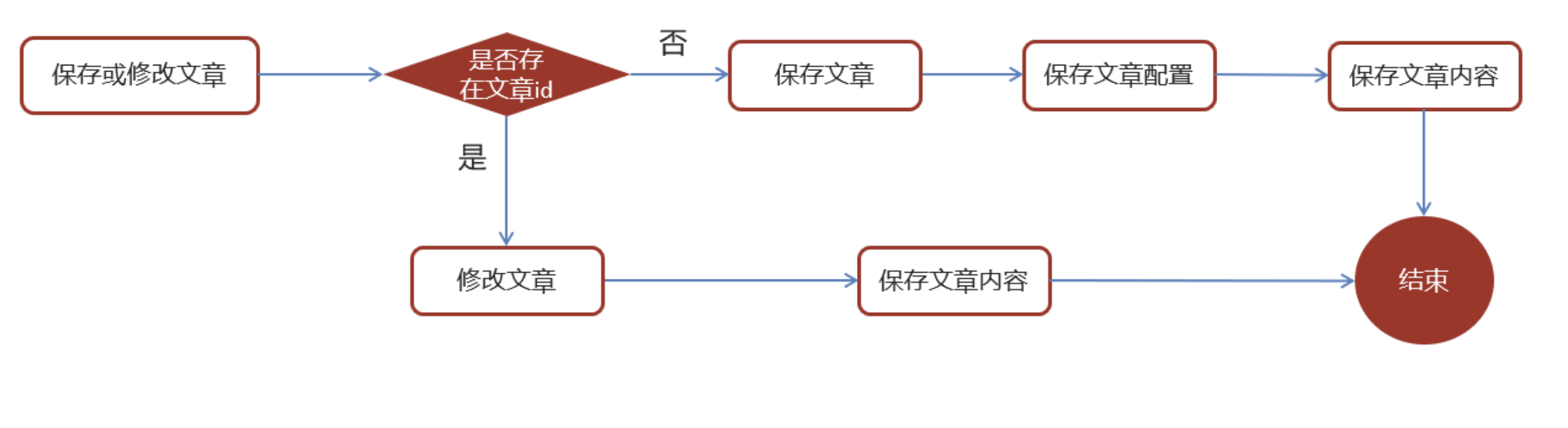
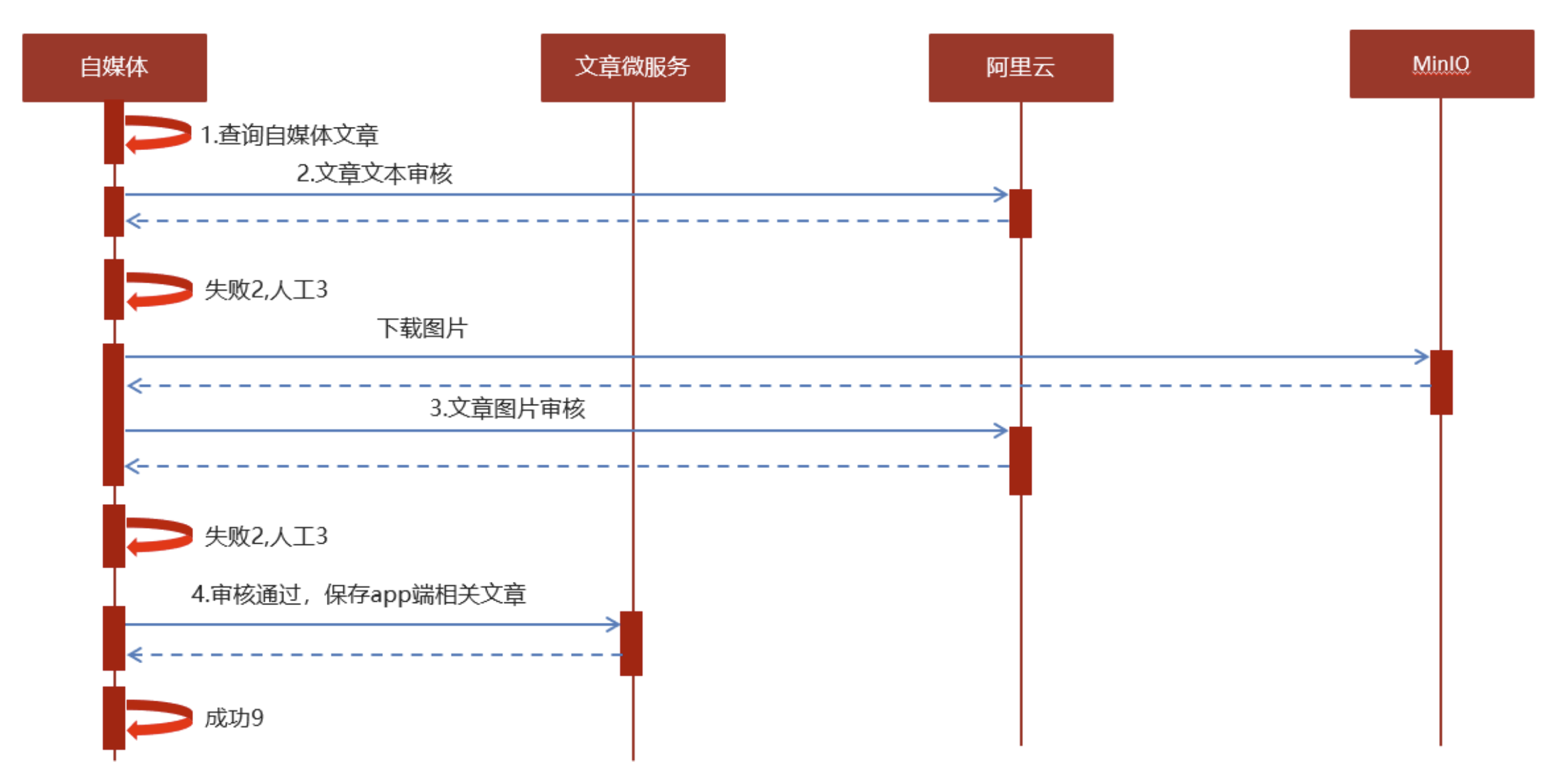
思路分析
在文章审核成功以后需要在app的article库中新增文章数据
1.保存文章信息 ap_article
2.保存文章配置信息 ap_article_config
3.保存文章内容 ap_article_content
实现思路:
feign接口
如何实现远程调用?
dubbo或者springcloud
| 说明 | |
|---|---|
| 接口路径 | /api/v1/article/save |
| 请求方式 | POST |
| 参数 | ArticleDto |
| 响应结果 | ResponseResult |
ArticleDto
package com.heima.model.article.dtos;
import com.heima.model.article.pojos.ApArticle;
import lombok.Data;
@Data
public class ArticleDto extends ApArticle {
/**
* 文章内容
*/
private String content;
}
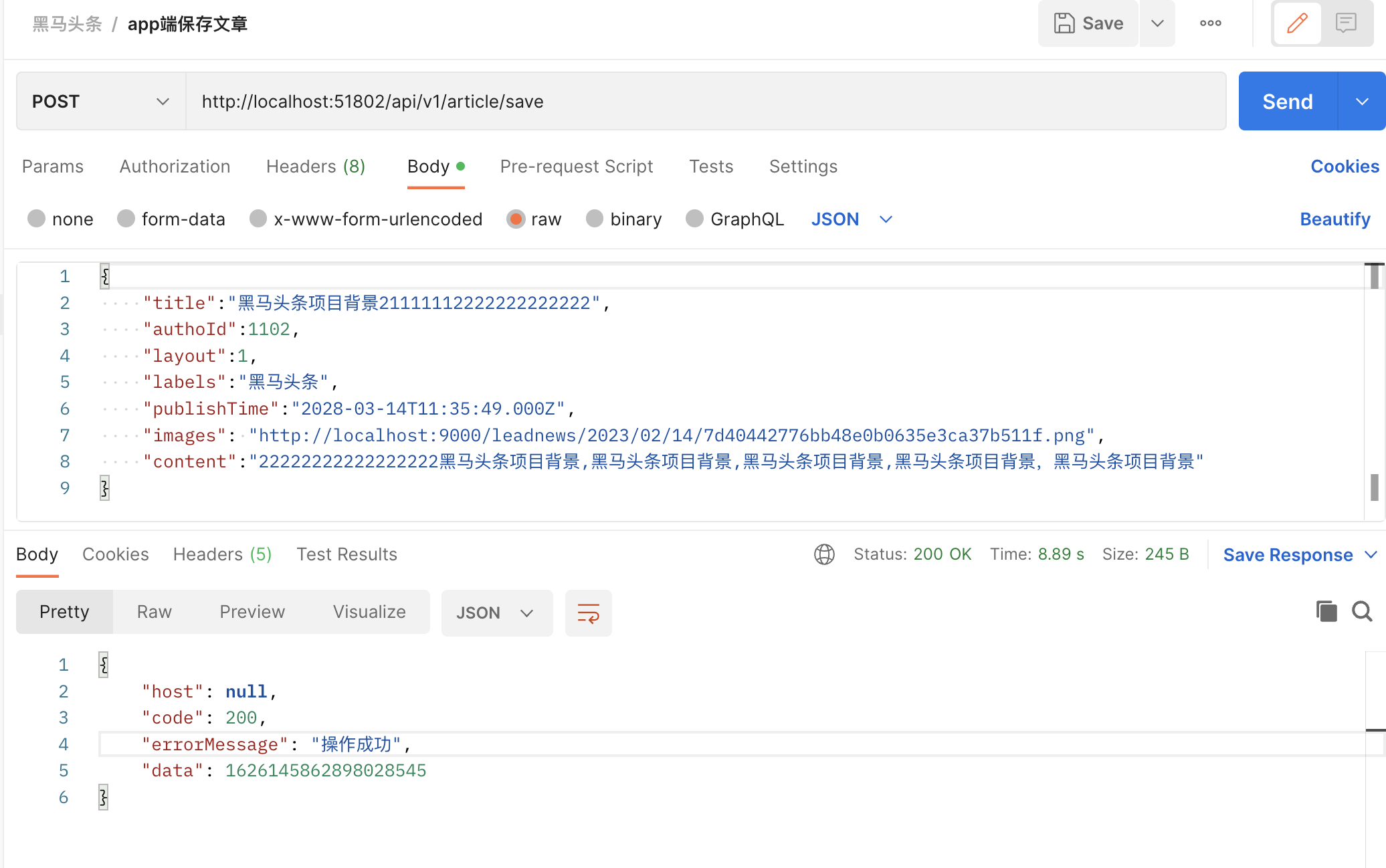
成功:
{
"code": 200,
"errorMessage" : "操作成功",
"data":"1302864436297442242"
}
失败:
{
"code":501,
"errorMessage":"参数失效",
}
{
"code":501,
"errorMessage":"文章没有找到",
}
功能实现:
①:在heima-leadnews-feign-api中新增接口
第一:导入feign的依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
第二:定义文章端的接口
package com.heima.apis.article;
import com.heima.model.article.dtos.ArticleDto;
import com.heima.model.common.dtos.ResponseResult;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import java.io.IOException;
@FeignClient(value = "leadnews-article")
public interface IArticleClient {
@PostMapping("/api/v1/article/save")
public ResponseResult saveArticle(@RequestBody ArticleDto dto) ;
}
②:在heima-leadnews-article中实现该方法
package com.heima.article.feign;
import com.heima.apis.article.IArticleClient;
import com.heima.article.service.ApArticleService;
import com.heima.model.article.dtos.ArticleDto;
import com.heima.model.common.dtos.ResponseResult;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.io.IOException;
@RestController
public class ArticleClient implements IArticleClient {
@Autowired
private ApArticleService apArticleService;
@Override
@PostMapping("/api/v1/article/save")
public ResponseResult saveArticle(@RequestBody ArticleDto dto) {
return apArticleService.saveArticle(dto);
}
}
③:拷贝mapper
在资料文件夹中拷贝ApArticleConfigMapper类到mapper文件夹中
同时,修改ApArticleConfig类,添加如下构造函数
package com.heima.model.article.pojos;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.io.Serializable;
/**
* <p>
* APP已发布文章配置表
* </p>
*
* @author itheima
*/
@Data
@NoArgsConstructor
@TableName("ap_article_config")
public class ApArticleConfig implements Serializable {
public ApArticleConfig(Long articleId){
this.articleId = articleId;
this.isComment = true;
this.isForward = true;
this.isDelete = false;
this.isDown = false;
}
@TableId(value = "id",type = IdType.ID_WORKER)
private Long id;
/**
* 文章id
*/
@TableField("article_id")
private Long articleId;
/**
* 是否可评论
* true: 可以评论 1
* false: 不可评论 0
*/
@TableField("is_comment")
private Boolean isComment;
/**
* 是否转发
* true: 可以转发 1
* false: 不可转发 0
*/
@TableField("is_forward")
private Boolean isForward;
/**
* 是否下架
* true: 下架 1
* false: 没有下架 0
*/
@TableField("is_down")
private Boolean isDown;
/**
* 是否已删除
* true: 删除 1
* false: 没有删除 0
*/
@TableField("is_delete")
private Boolean isDelete;
}
④:在ApArticleService中新增方法
/**
* 保存app端相关文章
* @param dto
* @return
*/
ResponseResult saveArticle(ArticleDto dto) ;
实现类:
@Autowired
private ApArticleConfigMapper apArticleConfigMapper;
@Autowired
private ApArticleContentMapper apArticleContentMapper;
/**
* 保存app端相关文章
* @param dto
* @return
*/
@Override
public ResponseResult saveArticle(ArticleDto dto) {
//1.检查参数
if(dto == null){
return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);
}
ApArticle apArticle = new ApArticle();
BeanUtils.copyProperties(dto,apArticle);
//2.判断是否存在id
if(dto.getId() == null){
//2.1 不存在id 保存 文章 文章配置 文章内容
//保存文章
save(apArticle);
//保存配置
ApArticleConfig apArticleConfig = new ApArticleConfig(apArticle.getId());
apArticleConfigMapper.insert(apArticleConfig);
//保存 文章内容
ApArticleContent apArticleContent = new ApArticleContent();
apArticleContent.setArticleId(apArticle.getId());
apArticleContent.setContent(dto.getContent());
apArticleContentMapper.insert(apArticleContent);
}else {
//2.2 存在id 修改 文章 文章内容
//修改 文章
updateById(apArticle);
//修改文章内容
ApArticleContent apArticleContent = apArticleContentMapper.selectOne(Wrappers.<ApArticleContent>lambdaQuery().eq(ApArticleContent::getArticleId, dto.getId()));
apArticleContent.setContent(dto.getContent());
apArticleContentMapper.updateById(apArticleContent);
}
//3.结果返回 文章的id
return ResponseResult.okResult(apArticle.getId());
}
⑤:测试
编写junit单元测试,或使用postman进行测试
{
"id":1390209114747047938,
"title":"黑马头条项目背景22222222222222",
"authoId":1102,
"layout":1,
"labels":"黑马头条",
"publishTime":"2028-03-14T11:35:49.000Z",
"images": "http://192.168.200.130:9000/leadnews/2021/04/26/5ddbdb5c68094ce393b08a47860da275.jpg",
"content":"22222222222222222黑马头条项目背景,黑马头条项目背景,黑马头条项目背景,黑马头条项目背景,黑马头条项目背景"
}
测试
自媒体文章自动审核功能
表结构说明
wm_news 自媒体文章表
实现
在heima-leadnews-wemedia中的service新增接口
package com.heima.wemedia.service;
public interface WmNewsAutoScanService {
/**
* 自媒体文章审核
* @param id 自媒体文章id
*/
public void autoScanWmNews(Integer id);
}
实现类
这里我对源代码做了改进,因为我的阿里云内容识别不能用~
/**
* @author: xiaocai
* @since: 2023/02/16/17:15
*/
@Service
public class WmNewsAutoScanServiceImpl implements WmNewsAutoScanService {
@Autowired
private WmNewsMapper wmNewsMapper;
@Autowired
private IArticleClient iArticleClient;
@Autowired
private WmChannelMapper wmChannelMapper;
@Autowired
private WmUserMapper wmUserMapper;
@Autowired
private FileStorageService fileStorageService;
@Autowired
private GreenTextScan greenTextScan;
@Autowired
private GreenImageScan greenImageScan;
/**
* 自媒体文章审核
*
* @param id 自媒体文章id
*/
@Override
public void autoScanWmNews(Integer id) {
// 1、查询自媒体文章
WmNews wmNews = wmNewsMapper.selectById(id);
if (wmNews == null) {
throw new RuntimeException("WmNewsAutoScanServiceImpl-文章不存在");
}
// 从内容中提取纯文本内容和图片
if (wmNews.getStatus().equals(WmNews.Status.SUBMIT.getCode())) { //SUBMIT=1=待审核
Map<String, Object> textAndImages = handleTextAndImages(wmNews);
// 2、审核文本内容,百度云接口
boolean textCheck = handleScanText(wmNews, textAndImages);
if (!textCheck) return;
// 3、审核图片的内容,百度云接口
boolean imgCheck = handleScanImg(textAndImages, wmNews);
if (!imgCheck) return;
// 4、审核成功,保存app端的相关数据
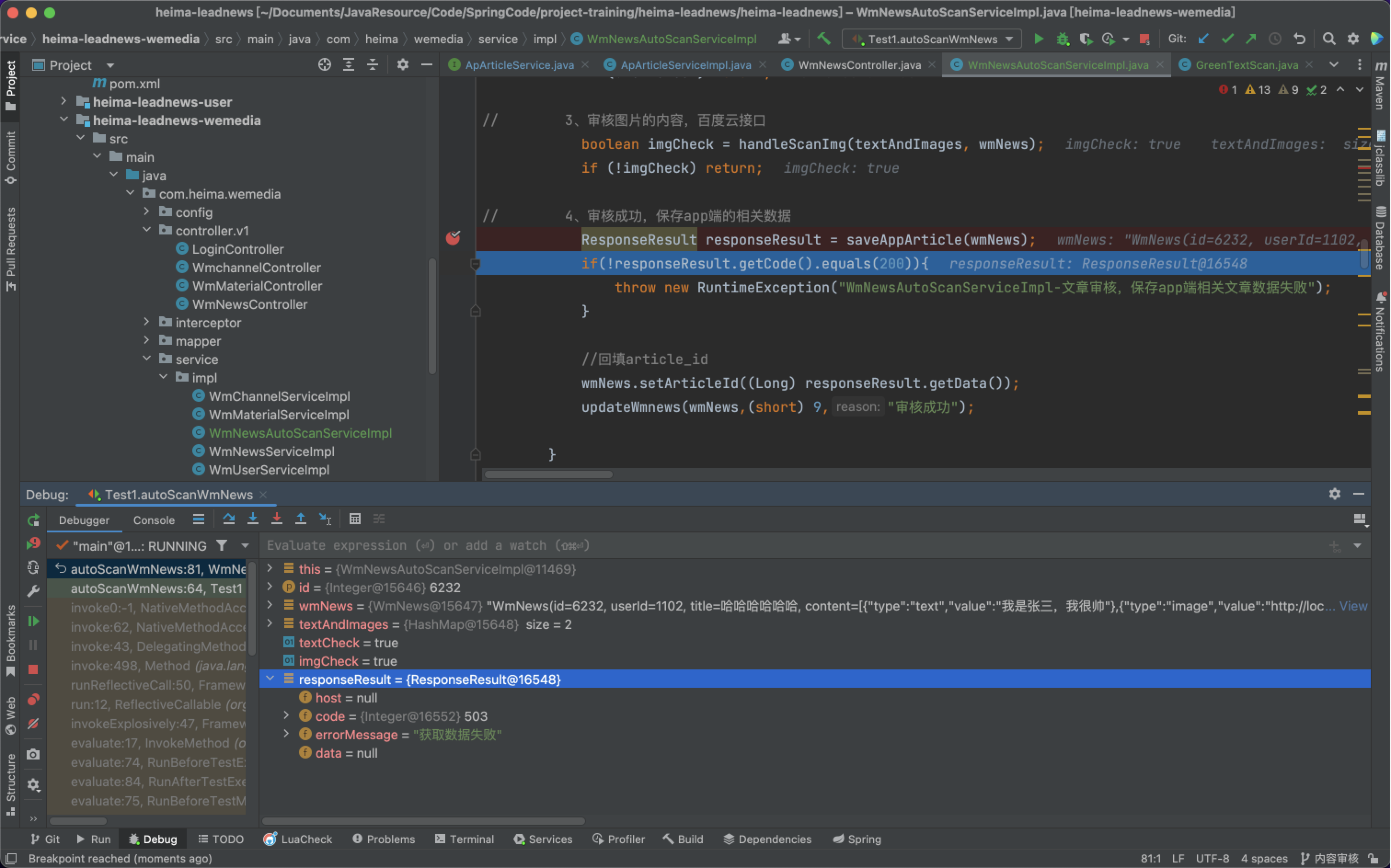
ResponseResult responseResult = saveAppArticle(wmNews);
if(!responseResult.getCode().equals(200)){
throw new RuntimeException("WmNewsAutoScanServiceImpl-文章审核,保存app端相关文章数据失败");
}
//回填article_id
wmNews.setArticleId((Long) responseResult.getData());
updateWmnews(wmNews,(short) 9,"审核成功");
}
}
private ResponseResult saveAppArticle(WmNews wmNews) {
ArticleDto dto = new ArticleDto();
BeanUtils.copyProperties(wmNews,dto);
dto.setLayout(wmNews.getType());
WmChannel wmChannel = wmChannelMapper.selectById(dto.getChannelId());
// 频道
if (wmChannel != null) {
dto.setChannelName(wmChannel.getName());
}
// 作者
dto.setAuthorId(wmNews.getUserId().longValue());
WmUser wmUser = wmUserMapper.selectById(wmNews.getUserId());
if(wmUser != null){
dto.setAuthorName(wmUser.getName());
}
//设置文章id
if(wmNews.getArticleId() != null){
dto.setId(wmNews.getArticleId());
}
dto.setCreatedTime(new Date());
ResponseResult responseResult = iArticleClient.saveArticle(dto);
return responseResult;
}
private boolean handleScanImg(Map<String, Object> textAndImages, WmNews wmNews) {
List<String> images = (List<String>) textAndImages.get("images");
List<String> imgUrlList = images.stream().distinct().collect(Collectors.toList());
boolean flag = true;
List<byte[]> imgList = new ArrayList<>();
for (String img : imgUrlList) {
byte[] bytes = fileStorageService.downLoadFile(img);
imgList.add(bytes);
}
for (byte[] bytes : imgList) {
Map<String, String> map = greenImageScan.imageScan(bytes);
if (!map.get("conclusion").equals("合规")) {
flag = false;
updateWmnews(wmNews, (short) 3, map.get("msg"));
}
}
return flag;
}
private boolean handleScanText(WmNews wmNews, Map<String, Object> textAndImages) {
String content = (String) textAndImages.get("content");
Map<String, String> map = greenTextScan.testScan(content);
boolean flag = true;
if (!map.get("conclusion").equals("合规")) {
updateWmnews(wmNews, (short) 3, map.get("msg"));
flag = false;
return flag;
}
return flag;
}
private void updateWmnews(WmNews wmNews, short status, String reason) {
wmNews.setStatus(status);
wmNews.setReason(reason);
wmNewsMapper.updateById(wmNews);
}
/**
* 获得文本、图片、封面图
*
* @param wmNews
* @return
*/
private Map<String, Object> handleTextAndImages(WmNews wmNews) {
StringBuilder stringBuilder = new StringBuilder();
List<String> images = new ArrayList<>();
if (!StringUtils.isEmpty(wmNews.getContent())) {
List<Map> maps = JSONArray.parseArray(wmNews.getContent(), Map.class);
for (Map map : maps) {
if (map.get("type").equals("text")) {
stringBuilder.append(map.get("value"));
}
if (map.get("type").equals("image")) {
images.add((String) map.get("value"));
}
}
}
if (!StringUtils.isEmpty(wmNews.getImages())) {
String[] split = wmNews.getImages().split(",");
images.addAll(Arrays.asList(split));
}
HashMap<String, Object> resultMap = new HashMap<>();
resultMap.put("content", stringBuilder.toString());
resultMap.put("images", images);
return resultMap;
}
}
单元测试
@Autowired
private WmNewsAutoScanService wmNewsAutoScanService;
@Test
public void autoScanWmNews() {
wmNewsAutoScanService.autoScanWmNews(6232);
}
feign远程接口调用方式
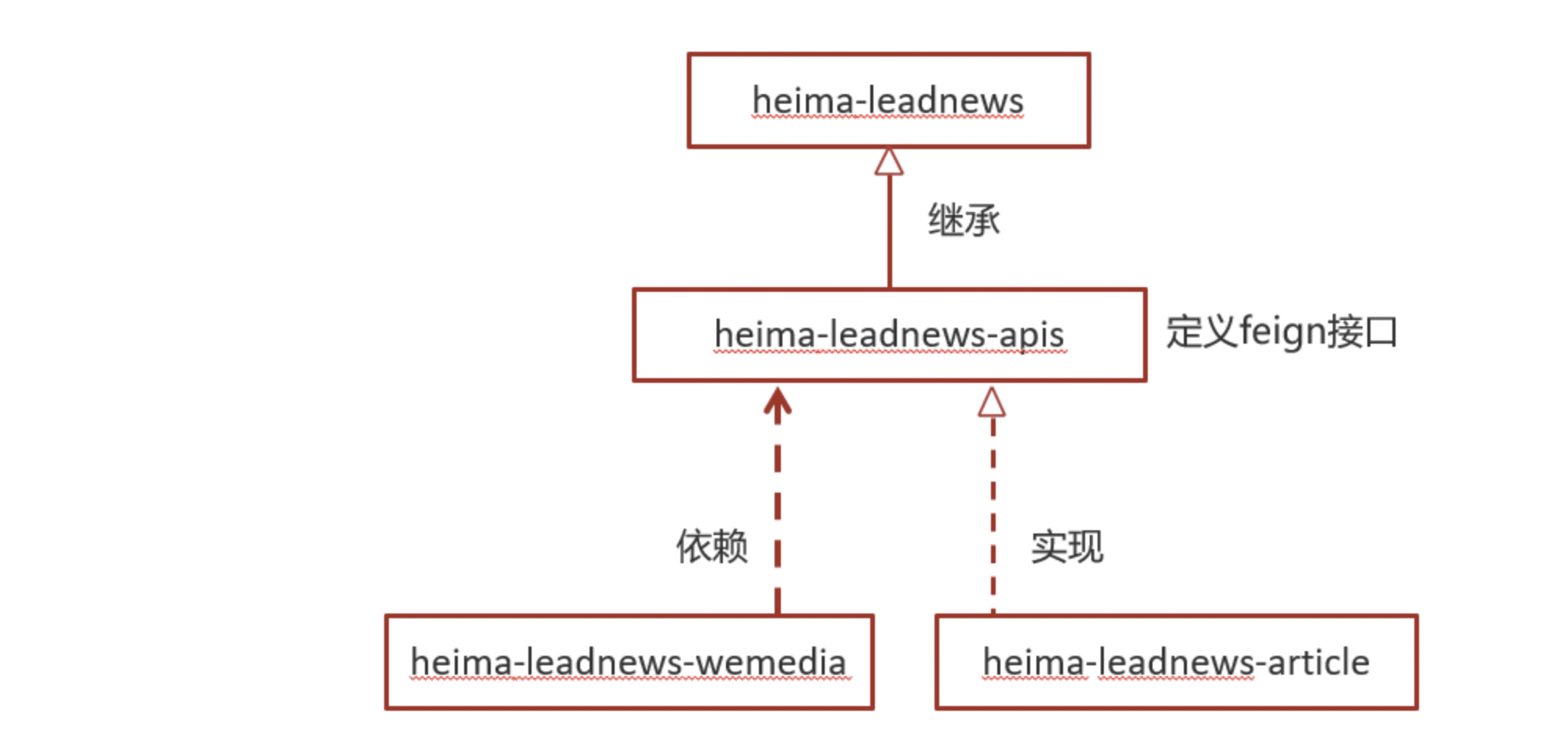
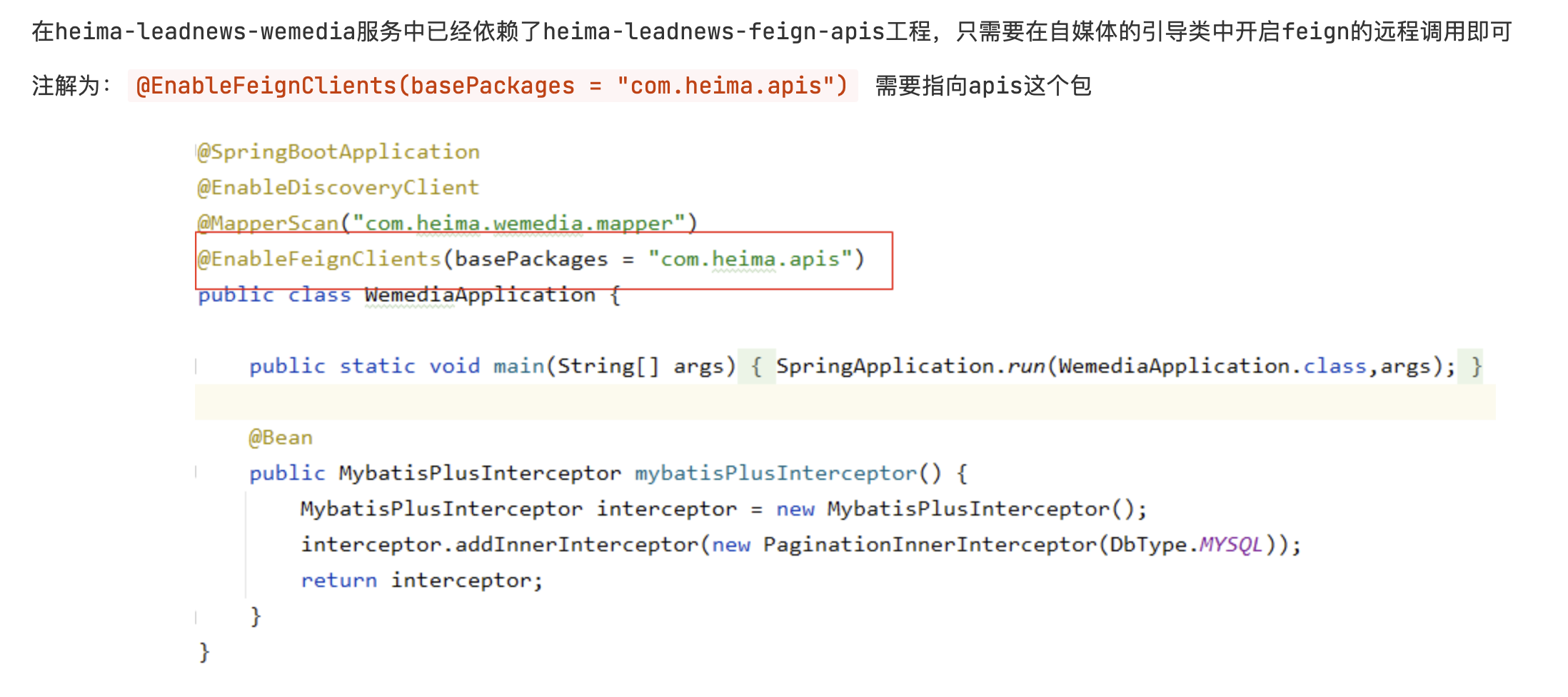
在heima-leadnews-wemedia服务中已经依赖了heima-leadnews-feign-apis工程,只需要在自媒体的引导类中开启feign的远程调用即可
注解为:@EnableFeignClients(basePackages = "com.heima.apis") 需要指向apis这个包
服务降级处理

- 服务降级是服务自我保护的一种方式,或者保护下游服务的一种方式,用于确保服务不会受请求突增影响变得不可用,确保服务不会崩溃
- 服务降级虽然会导致请求失败,但是不会导致阻塞。
实现步骤:
①:在heima-leadnews-feign-api编写降级逻辑
package com.heima.apis.article.fallback;
import com.heima.apis.article.IArticleClient;
import com.heima.model.article.dtos.ArticleDto;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.common.enums.AppHttpCodeEnum;
import org.springframework.stereotype.Component;
/**
* feign失败配置
* @author itheima
*/
@Component
public class IArticleClientFallback implements IArticleClient {
@Override
public ResponseResult saveArticle(ArticleDto dto) {
return ResponseResult.errorResult(AppHttpCodeEnum.SERVER_ERROR,"获取数据失败");
}
}
在自媒体微服务中添加类,扫描降级代码类的包
package com.heima.wemedia.config;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
@Configuration
@ComponentScan("com.heima.apis.article.fallback")
public class InitConfig {
}
②:远程接口中指向降级代码
package com.heima.apis.article;
import com.heima.apis.article.fallback.IArticleClientFallback;
import com.heima.model.article.dtos.ArticleDto;
import com.heima.model.common.dtos.ResponseResult;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
@FeignClient(value = "leadnews-article",fallback = IArticleClientFallback.class)
public interface IArticleClient {
@PostMapping("/api/v1/article/save")
public ResponseResult saveArticle(@RequestBody ArticleDto dto);
}
③:客户端开启降级heima-leadnews-wemedia
在wemedia的nacos配置中心里添加如下内容,开启服务降级,也可以指定服务响应的超时的时间
feign:
# 开启feign对hystrix熔断降级的支持
hystrix:
enabled: true
# 修改调用超时时间
client:
config:
default:
connectTimeout: 2000
readTimeout: 2000
④:测试
在ApArticleServiceImpl类中saveArticle方法添加代码
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
在自媒体端进行审核测试,会出现服务降级的现象
测试结果如下:
成功触发了Hystrix实现了服务降级