目录
一、Cookie
二、响应的回报结果含义
三、实际开发中的选择
一、Cookie
Cookie是浏览器本地存储数据的一种机制,
在浏览器访问服务器之间,此时你的浏览器对着个服务器之间是一点也不了解的,你的浏览器上是没有任何和着个服务器相关的数据的。
浏览器拿到这些数据,就可以展示网页了。
与此同时,用户拿着网页,操作的过程中,也会产生出很多临时性数据,像临时数据有的可以放到服务器这边存储,有的不太重要的,就直接放到浏览器这边存储(方便下次之间使用,但是你换个电脑或者浏览器可能就不同了(小时候的4399,就是这样,只有我老玩 的那个浏览器才显示出来最近常玩之类的)
但是有一些数据属于是临时性数据,这样的数据可以放到服务器这边保存,这样你换一个电脑,数据这边还是有效的。4399的账号)
Cookie就是一个主要保存机制,你点击循环也就在Cookie中写入一个数据(比如b站的洗脑循环呢)“洗脑循环"=true ,浏览器就自动存储这个数据,后续在访问B站,浏览器就能够自动把这个读出来,放到http的请求中。
为了保证安全,浏览器对网页做出限制(其中禁止直接访问硬盘就是一个限制),为了保证安全,同时又能存储数据,浏览器提供了Cookie功能(后续有的其他功能)->(Cookie:是按照键值对方式存储一些字符串,这些键值对往往都是服务器返回来的,浏览器把这些键值对按照域名维度,进行分类存储。不同的网站Cookie是独立的,内容都是程序员自定义的)
一个网站中存很多键值对在Cookie中,
有一个很重要的键值对,用来表示用户身份信息的->尤其有的时候,登入一个网站,后续再去访问这个网站的其他页面,都不必重新登入,并且关闭电脑后,第二天再去访问依旧不需要重新访问。
为了实现身份识别的效果,不仅仅需要Cookie支持服务器这里,也要Session机制来支持。
什么是Session机制呢?(植入看病场景)
首次访问网站,登入之后,相当于用户给你一个就诊卡(身份标识,SessionId)
身份标识就通过服务器返回给浏览器的响应保存在浏览器的Cookie中了(键值对)
与此同时,人家网站服务器这边,也就会创建啊一个对应的Session(电子档案),Session中就会记录一些关键信息,网站服务器一定不止有你一个用户,每个用户都有自己的session,并且sessionId主键(非空不重复)服务器就会使用类似的Hash表这样的方式,以sessionId为key,以Session为Value,把数据组织起来。
后续访问网站的其他页面,都会在请求的Cookie字段中带上sessionId,服务器可以通过sessionId,了解你的用户信息。
Cookie:······buvid=cf85;live-BuVID=AUTO····键值对之间使用;分隔,键与值之间用=分隔。

小总结:
Cookie从哪里来?
从服务器返回给浏览器
Cookie保存在哪里?
保存在浏览器上,浏览器所在电脑的键盘上,每个域名都有自己的一组Cookie
Cookie里面的内容是什么?
Cookie中的内容是键值对结构的数据,这里的键值对都是程序员自定义的,其中有一个键值对,作为用户身份标识。
Cookie里面的内容到哪里去?
后续再访问这个网站的各个页面,都会在请求中带上Cookie,服务器就可以进一步知道客户端的详细情况了。
当然有人获取了我的Cookie里面的sessionid,然后和服务器对话,可能会冒充你的身份(但是还是不会知道你的账号密码,就像是有人拿了你的医保卡,但是并不知道密码)
json是键值对,key和value用:键值对之间用,分隔。
二、响应的回报结果含义
响应对应四行
1.首行
2.响应头
3.空行
4.正文
HTTP/.1.1. 200 ok HTTP/.1.1.:版本号 200:状态码(这次响应的定性,成功,失败,或者其他情况) OK:状态码的描述常常我们用数字来表示结果,不同数字表示不同失败的原因
200 表示获取成功
404😡😡😡小伙伴的网址一个一个都是这么没的
502:服务器挂了
504服务器响应超时
302重定向(服务器会自动跳转到其他的页面)
重定向和下面这个呼叫转移类似
“呼叫转移”手机运营商一个业务“现在很少了,想我之前是182转156,如果有人带电话到182,就自动转到156这个手机号这里
HTTP的重定向:使用浏览器访问www.aaa.com这个url,此时请求发送给对应服务器,结果服务器返回了一个302,同时告诉你,要去访问www.bbb.com,于是浏览器收到这个响应,就会自动跳转到www.bbb.com(当然无视风险,无视防火墙之类的🐷🐷🐷。)
HTTP协议
请求 响应
1.首行(方法,URL版本号) 1.首行(版本号,状态码,状态码描述)
2.header 2.header(键值对)
3.空行 3.空行
4.body 4.body
三、实际开发中的选择
实际开发中,经常能够手动构造出HTTP请求来
1.html的form表单
2.通过js的ajax.
3.Java代码(其他各种语言的代码)
4.借助一些第三方工具
form表单
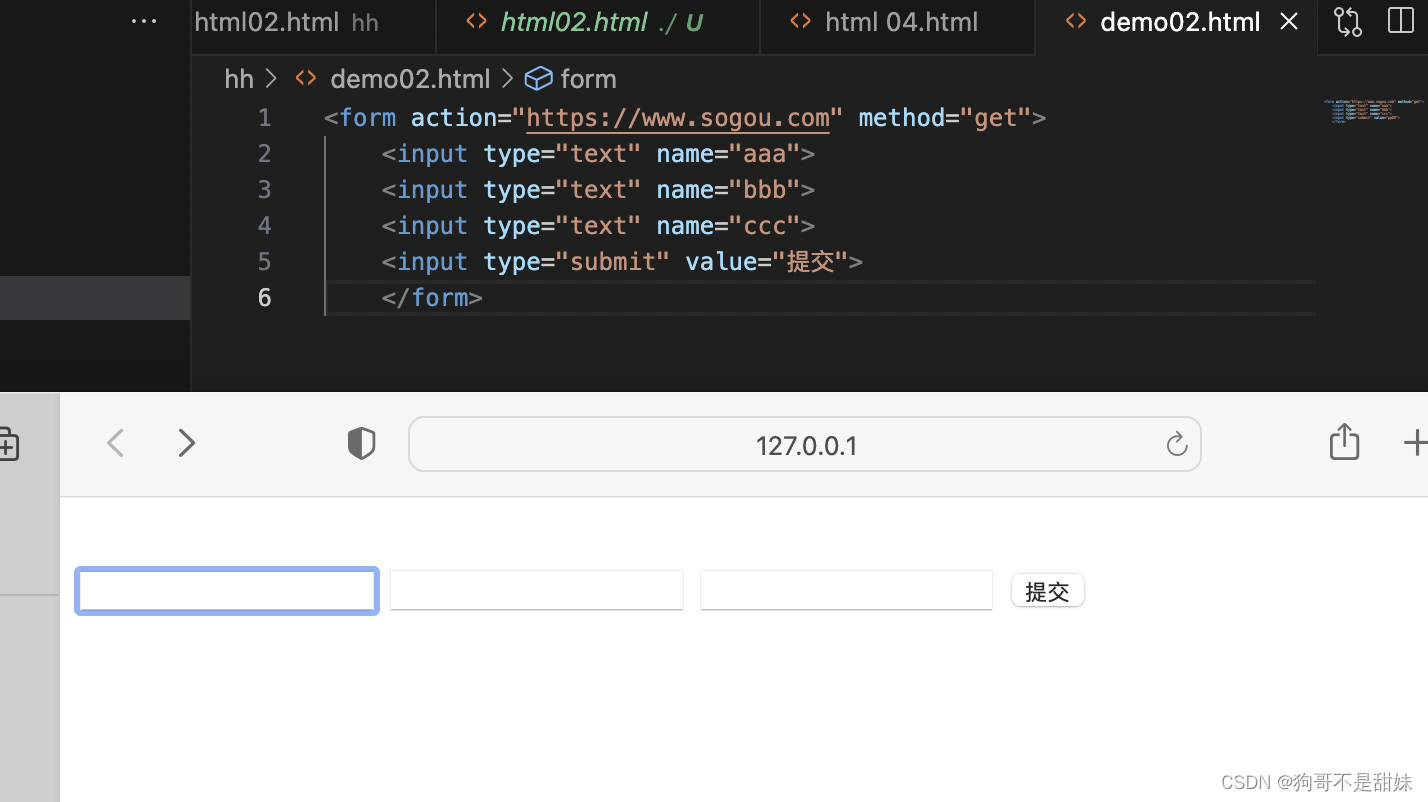
<form action=""></form>对于开始标签来说,可以写一些属性(键值对)action属性,描述了构造HTTP请求,URL是什么 比如: <form action="http://www.sogou.com" method="get"> get:请求的方法(就是那个GET,POST) <input type="text" name="aaa"> //aaa会作为参数,被放到http请求的QueryString/body //中name属性aaa,就是键值对的键,用户输入框输入的内容就是键值对的值 //input:在html中有多个意思,他是通过type属性来控制的,其中text这个类型,就是一个最简单的单行输入框 //假如搭配的类型是submit也就是变成了发出去这个请求 <input type="submit" value="提交">(value 的值就是按钮上的文本) //完整 <form action="https://www.sogou.com" method="get"> <input type="text" name="aaa"> <input type="text" name="bbb"> <input type="text" name="ccc"> <input type="submit" value="提交"> </form> //这里面的get方法可以换成POST,但是POST没有指向的QueryString
最终的效果就是这样,不管你输入什么,都会自动跳转到搜狗。
GET https:www.sougou
这里的输入框中,你填入的东西,会显示到搜狗的报头URL中
当然现在更经常使用2.ajax构造HTTP
(Asynchronous JAVAscript AND XML,
Asynchronous:是异步的意思,synchronized:同步)
我和小薛约去网吧
我等薛 同步的情况是:我这边时刻看,小薛是否出来了(等待的职责放到了发起者的身上)
异步的情况是:小学出来,主动来去找我(异步的等待职责放到了被发起者的身上)
ajax就是一种异步的通信方式,通过代码,发出了HTTP请求,请求发出去之后,js代码就继续往下执行,当服务器的响应回来之后,就会自动的通知到咱们的代码中,进一步就能够处理响应了。(ajax是js提供的一组API,js原生的ajax,非常不好用,所以出现了:JQuery这是个js界的一个知名第三方库)
<script> $.ajax({ //不仅get和post,也支持其他的东西 type:'get', //uel构造http请求的路径 url:'https://sogou.com', //下面这一段 contentType:'application/x-www-form-urlencoded', adata:'aaa=111&bbb=222', //可加可不加,服务器返回响应,要如何处理success的值是一个函数,这个函数就会在收到响应的时候被浏览器自动调用这个函数的时候,就会把响应的body,通过参数传过这个函数。 //此处所谓的异步:js执行ajax方法的时候,把请求发出去之后,就立即往下执行,这时,还没调用success对方的方法呢,一直响应回来,success才会被调用(这也被叫做回调函数) success:function(body){ console.log('ok'); } //js中,{}表示的是js的对象,里面是键值对,键值对之间用,分割,键和值之间用:分割,键固定是string类型,可以写‘’也可以不行,值的话数字,字符串,数组,对象皆可。 }); </script>ajax功能更灵活,是否想要有QueryString都可以,如果想要QueryString直接做一个字符串拼接即可或通过body传输,JAVA有一些第三方封装的HTTP的构造。