TreeSLS (SOSP'23)
- 1. 背景 (Background)
- 1.1 内存-存储二级架构 (§1, §2.1)
- 1.2 单级架构 (§2.2)
- 1.3 总结
- 2. 动机 (Motivation)
- 2.1 现有SLS性能低下 (§2.3)
- 2.2 现有SLS难以支持External Synchrony (§1, §2.4)
- 2.3 高速PM出现为SLS带来新的机遇与挑战 (§1, §2.5)
- 3. TreeSLS设计与实现 (Design & Implementation)
- 3.1 系统概览 (§3)
- 3.1.1 Capability Tree
- 3.1.2 Checkpoint Manager
- 3.1.3 Checkpoint/Restore流程
- 3.2 Capability Tree Checkpoint (§4.1, §4.2)
- 3.2.1 Backup Capability Tree的生成
- 3.2.2 崩溃一致性
- 3.3 Hybrid Copy (§4.3)
- 3.3.1 Hot Page检测与迁移
- 3.3.2 崩溃一致性拓展
- 3.4 Transparent External Synchrony (§5)
- 3.5 实现 (§6)
- 4. 评估 (Evaluation)
- 4.1 实验设置 (§7.1)
- 4.2 功能性测试 (§7.2)
- 4.3 Checkpoint STW开销 (§7.3)
- 4.4 运行时开销 (§7.4)
- 4.5 真实应用 (§7.5)
- 总结
导读:
- 总览:TreeSLS是继Aurora@SOSP’21来,又一篇实现Single Level Store (SLS) 系统的工作,与前面工作不同的地方在于,TreeSLS是首个利用持久化内存做运行时和存储环境的操作系统,其通过快速Checkpoint机制 (1000HZ) 对应用实现透明持久化;而以前的工作仍然假设操作系统工作在二级存储架构中,需要将内存中的数据刷回持久化介质,导致持久化过程十分缓慢,因此Checkpoint频率受限。
- 本质:TreeSLS的设计本质还是利用Checkpoint对进程进行持久化,不过PM的特性使得TreeSLS可以减少需要保存的数据,因为许多运行时数据可以被PM原生地保存下来。
- 延伸:在PM相关的运行时库以及持久化文件系统/数据库研究得火热的今天,个人认为SLS或将成为未来研究方向(工业实践方向),因为PM同时结合了内存与存储特性,天然符合SLS的要求 (单级存储OS)。
从本次博文开始,后续文章都会给出梳理后的文字出处,如:§1代表来源原文第一章。同时,将PM与NVM不加区分。
1. 背景 (Background)
1.1 内存-存储二级架构 (§1, §2.1)
以往的OS运行在主存 (Main Memory) 和持久化存储器上,这是基于“内存易失但是速度快,而存储器非易失但速度慢”之上。如此一来,应用常常将运行时保数据存在内存中,而通过文件系统将数据持久化在存储介质中。然而,内存和存储器之间的数据移动开销很大;此外,由于内存和存储中的数据表现形式不同(例如:内存中的Inode与介质中的Inode),数据在移动过程中还需要额外的序列化(serialization)和反序列化(deserialization),进一步带来开销。
应用可以利用文件系统API自行保证数据的持久化,并实现崩溃一致性机制(如:Journaling等),但这常常非常复杂,且容易出错。
1.2 单级架构 (§2.2)
Single-Level Store (SLS) 为应用提供了另一种透明的持久化手段。SLS将内存向下拓展至存储器,并移除了文件系统层。由此,对应用而言,整个系统只有一级大的持久化内存,在SLS下,用户可以编写无需考虑持久化的应用,例如,内存KV store可以不用刷回持久化存储做崩溃恢复。以往的SLS基于内存-存储二级架构进行建设,需要透明地将内存数据结构持久化到磁盘中,反之恢复到内存中。持久化过程通过Checkpoint技术实现,但由于受以往存储技术限制,Checkpoint时间往往在分钟级别 (minute-level)。
近年来,高速存储设备重新引发了SLS的相关研究,例如,Aurora SLS。
1.3 总结
总结来说,相比传统的面向二级存储架构的持久化方法,例如:应用自行实现持久化(App-implemented Persistence)、基于库/编译器实现持久化,SLS方案通过实现单级持久化内存架构能够使应用天然持久化而无需额外的工作(如实现Journaling等),TreeSLS主要针对现有(以往)SLS Checkpoint效率低的问题,结合PM设备大大提升了SLS Checkpoint的性能。
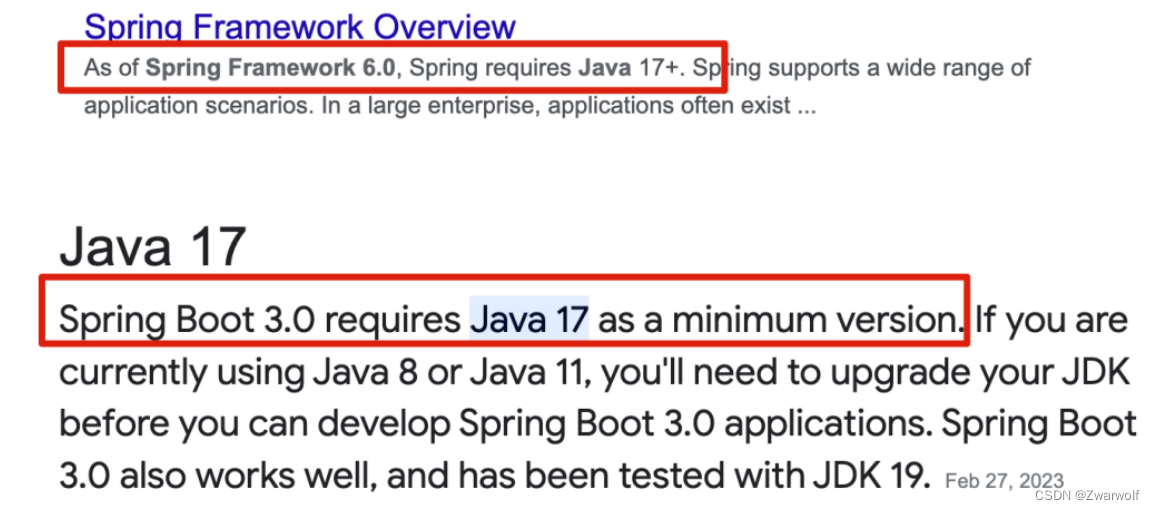
2. 动机 (Motivation)
2.1 现有SLS性能低下 (§2.3)
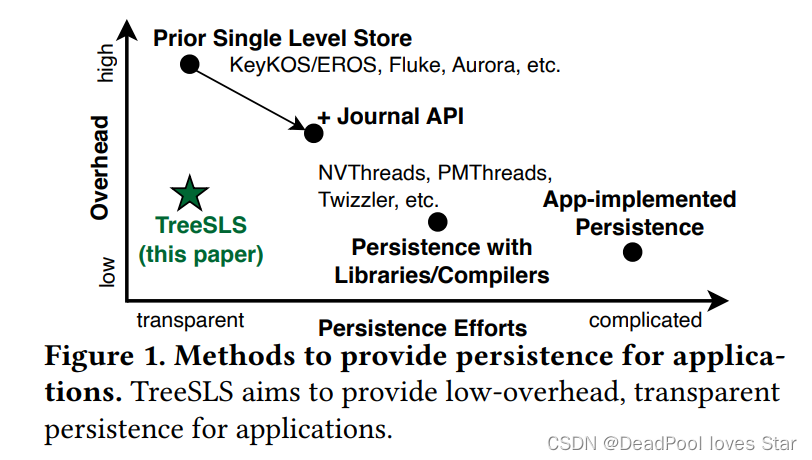
现有(以往的)的SLS仍然基于二级内存-存储架构进行构建,通过软件Checkpoint对易失数据进行持久化从而为应用提供透明地持久性。下图展示了两个最典型的SLS系统——EROS和Aurora的结构。可以看到,他们将对象缓存在内存中,存储器中持久化对象。TreeSLS同时将PM作为运行时与持久化介质,可以避免大量数据的移动。
然而,这些系统(EROS和Aurora)都存在一个共性问题:运行时内存访问接口与持久化存储器访问接口的不匹配,这带来两点性能开销:
- 写放大。内存访问按字节进行,但是数据的持久化常常以Block为单位进行,这会带来写放大开销;
- 受限的Checkpoint频率。以往的SLS通过Stop-the-World (STW) 来将易失状态拷贝至专用内存Buffer,这些Buffer中的数据进而被后台线程异步刷回持久化存储介质中。这种异步方式避免了缓慢的STW开销,但是导致Checkpoint的频率受限,这是因为在所有脏数据被持久化之前Checkpoint都不会被创建。受限的Checkpoint频率导致数据丢失更容易发生。
2.2 现有SLS难以支持External Synchrony (§1, §2.4)
External Synchrony(外部同步性)是指对外部系统的同步,简单来说就是向外界系统响应时,要保证自身系统的状态都已经持久化。对于SLS来说就是Checkpoint完成后,即可向外界响应。以往的SLS的Checkpoint频率过大,对于以往的应用可以接受,但对于现代数据中心来说,SLS系统的响应应该是实时的(例如,当数据库向用户回应已提交请求时,其必须保证数据已经持久化),因此仅凭过去的Checkpoint技术难以做到External Synchrony。
为了提供External Synchrony需求,以往的SLS通过为应用提供额外的机制保证,例如:Journaling API等。然而,这使得应用的持久化复杂度进一步提升,与SLS提出的初衷相反。
2.3 高速PM出现为SLS带来新的机遇与挑战 (§1, §2.5)
持久化内存PM的出现,使得SLS能够很好地利用其低延迟、字节级寻址以及非易失性,最小化Checkpoint的开销:SLS可以将PM设备当作内存与存储,快速直接操作PM上的数据(从而避免数据移动)。
需要说明的是,PM虽然原生地适配SLS的语义,但是直接将DRAM替换为PM并不能直接做到SLS,这是因为CPU寄存器、设备寄存器、Cache内的内容仍然会在掉电后丢失。基于PM构建SLS存在以下挑战:
- 在PM设备上仍然需要Checkpoint。仍然需要通过Checkpoint保证寄存器等除内存外易失数据的持久化;
- 运行时数据与持久化数据的一致性。可以利用PM的运行时特性以及存储特性避免数据移动以及写放大问题,然而如何保证PM上运行时数据以及持久化数据的一致性仍然是一大挑战,这是因为同一个PM page可以既被用于运行时,亦被用于持久化(Checkpoint);
- 实现透明的External Synchrony是一大挑战。以往的方案都使用定制API,但是为External Synchrony编写正确的持久化代码(例如Journal)仍然非常困难;
3. TreeSLS设计与实现 (Design & Implementation)
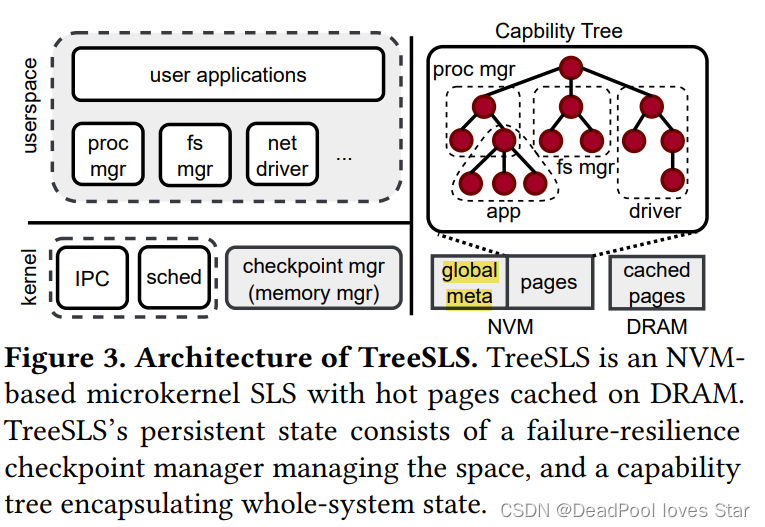
3.1 系统概览 (§3)
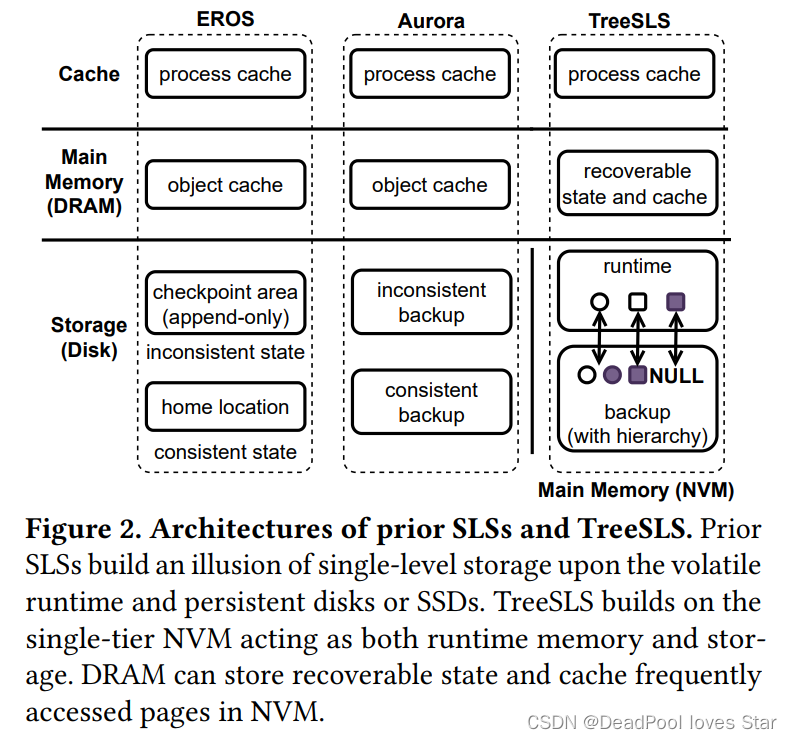
TreeSLS发现微内核(microkernel)架构有利于构建SLS,一方面微内核架构将大多数系统服务(如:IPC,调度等)部署在用户态,内核功能较为简单;另一方面,微内核架构常常会维护一颗Capability Tree,这个Tree能够实时反映系统的运行状态。这样一来,TreeSLS可以通过Capability Tree快速高效地对系统进行Checkpoint。
Capability似乎是微内核架构的一个专用术语。EROS介绍到Capability是由一个对象描述符和一系列在该对象描述符上授权的操作,例如:UNIX文件描述符就是一种Capability,这是因为fd是一个对象描述符,而read/write等操作都是在该对象符上授权的操作。不过,还是很难将Capability与系统模块结合起来。TreeSLS对Capability的解释是:系统资源都属于对象,而Capability是为对象赋予的一些列访问权限。
相比于传统宏内核(monolithic kernel)而言,微内核中的Capability Tree结构更为清晰简单,这使得Checkpoint的实现更加容易,而不是像以往的工作一样,需要针对复杂的宏内核对象设计专用的Checkpoint方案。
此外,TreeSLS可以通过Capability Tree的运行时状态做高效的增量Checkpoint操作(即,跳过上个Checkpoint的既有状态)。其他的一些能够被推导的状态,例如IPC和调度器不需要被持久化, 这是因为这些状态可以通过Capability Tree恢复。例如,将所有线程加入到调度器队列中即可恢复调度器。
3.1.1 Capability Tree
下图和表分别展示了TreeSLS中的Capability Tree的内部结构以及各对象的描述。每个用户态进程由Capability Tree的一颗子树构成(大概就是一个进程可由多个Objects和对应的Capabilities构成),所有的系统资源都可以通过树的根:Root Cap Group获取。
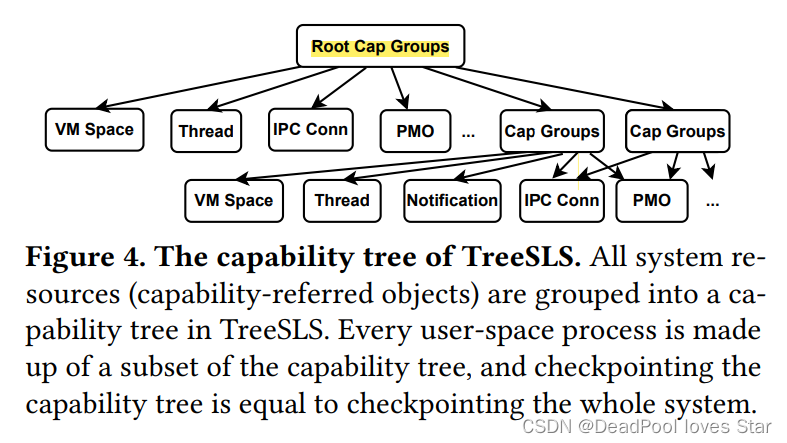 |  |
|---|
3.1.2 Checkpoint Manager
Checkpoint Manager用于进行Checkpoint以及管理PM的运行时对象和持久化对象(Checkpoints)。Checkpoint Manager通过Buddy Allocator和Slab子系统进行PM空间管理,Buddy和Slab所需要的元数据被存在PM上(见3.1 global meta)。
Checkpoint Manager被部署在PM中,其不会为自己Checkpoint,因此TreeSLS通过Journaling的方法保证Checkpoint Manager的崩溃一致性。例如:应用通过malloc分配的空间需要在恢复后由Checkpoint Manager释放。
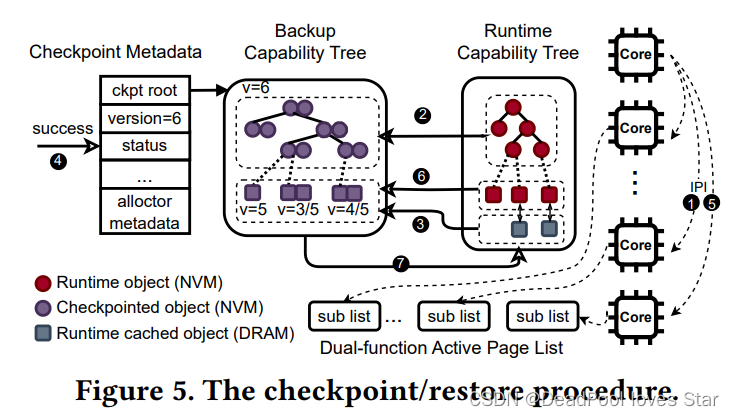
3.1.3 Checkpoint/Restore流程
Checkpoint流程:
① 当前CPU(Leader)发送IPI(Inter-Process Interrupt)至其他CPU是他们进入暂停状态。TreeSLS关闭了内核中断,因此IPI不会使正在修改内核态对象的CPU暂停,即,只会在用户态暂停,并陷入内核态。
② Leader检查当前的Runtime Capability Tree,并据此生成一颗Backup Capability Tree。在该过程中,TreeSLS不会拷贝应用的物理页面,而是将这些页面对应的权限置为只读。
③ 于此同时,其他CPU进行内存内热页面(Hot Page)的拷贝,我们会在3.3部分介绍。
④ TreeSLS将该Checkpoint标记为有效,并且增加全局版本号(global version)。这些元数据信息一并维护在global meta中(见3.1图)。
⑤ Leader接下来再次发送IPI使其他CPU恢复执行。
⑥ 在运行时,会触发Page Fault(因为所有页面都被标记为只读),TreeSLS通过COW将页面复制给Backup Capability Tree。这个过程的本质是以降低Runtime性能换取更快的Checkpoint性能;
Restore流程:
⑦ 在崩溃恢复过程中,TreeSLS通过Backup Capability Tree恢复Runtime Capability Tree。Checkpoint Manager自身的状态通过Journal进行恢复。
3.2 Capability Tree Checkpoint (§4.1, §4.2)
3.2.1 Backup Capability Tree的生成
TreeSLS通过复制Capability Tree中的所有对象以生成Backup Tree。但需要注意的是,有些对象可能同时被多个Cap Group引用(见3.1.1图,直观的理解是某些内存页面可能被多个进程引用,例如:shared memory,在TreeSLS中,即PMO被多次引用)。为了避免重复Checkpoint,TreeSLS提出Capability Object Root(ORoot),该结构为每个(unique)对象记录了其在Runtime Tree对象以及在Backup Tree对象中的地址。所有的对象包含一个反向指针指向ORoot。
接下来介绍对各种对象的Checkpoint方式。
-
Cap Group。Cap Group是一个Capabilities数组,每个Capability都指向一个Runtime Object以及其对应的访问权限。为了Checkpoint Cap Group,TreeSLS在Backup Tree种分配相应的空间,然后拷贝每个Capability至该数组空间中。Backup的Capability指向Runtime Object对应的ORoot,而非Backup Object。
具体而言,对于每个Capability,TreeSLS定位其Runtime Object位置,然后在通过反向指针定位ORoot位置。如果ORoot不存在,则说明这个Runtime Object是新建的,那么TreeSLS为其新生成一个ORoot。通过检查ORoot中的Backup Object,TreeSLS即可指导该Runtime Object是否已经被Backup,如果没有被Backup,那么TreeSLS便递归地Checkpoint该对象(因为该Object下面还可能会有很多子树)。
-
Thread。TreeSLS为Thread Object分配空间,并将当前的Thread对应的上下文(如寄存器、调度状态等)拷贝到Backup Tree中。由于此时CPU一定是陷入内核中的(IPI),因此,所有用户态线程状态都被持久化在PM上,因此在这时拷贝不会出现不一致的情况。
-
IPC Connection,Notification和IRQ Notification。这些对象都用于进程间通信以及同步,TreeSLS直接拷贝这些对象至Backup Tree。
-
VM Space。VM Space记录了一系列虚拟内存Region以及对应的Page Table(看起来比较类似rCore的结构)。每个Region由PMO表示。为了Checkpoint VM Space,TreeSLS直接拷贝虚拟内存Region而不拷贝Page Table,这是因为Page Table可以由Region(PMO)重建。TreeSLS通过Page Fault完成Page Table的重建。进一步地,TreeSLS将Page Table放在DRAM中以获取更高效的运行时性能。
-
PMO。PMO使用Radix Tree记录了一系列PM页面。在Checkpoint PMO的过程中,TreeSLS将其Radix Tree拷贝到Backup Tree中。对于PMO对应的PM页面,TreeSLS将Page Table中对应的页面标记为只读,在Page Fault过程中,TreeSLS会复制对应的页面,并更新Backup Tree中Radix Tree的指针至复制的页面。这样一来,TreeSLS降低Runtime性能(Page Fault)换取更快的Checkpoint性能(无需物理页面拷贝)。
-
其他状态。有些状态在Capability Tree中没有,例如:Kernel Buffer,页表中的COW位等,TreeSLS将这些信息作为Special Node放在Capability Tree中。
3.2.2 崩溃一致性
以往的方法将运行时页面置于易失内存,因此需要至少两个持久化页面作为备份,其中一个用于接受写入(可能Inconsistent),另一个用于Consistent的备份。这样一来既浪费存储空间又浪费存储带宽。
考虑到PM的特性(原文是考虑到PMO对象包含的页面很多),TreeSLS可以将Runtime Page视为一个Backup,最多额外分配一个Backup用于Checkpoint。对于其他的对象,除了运行时Backup外,TreeSLS还会在Checkpoint过程中维护两个Backup(也许是更好的鲁棒性)。TreeSLS为每个Backup都会附上一个Version,并维护一个全局Version来保证一致性。
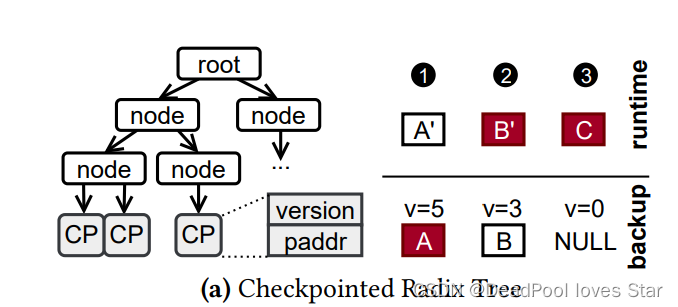
如上图所示,对于每个Backup的PMO而言,Radix Tree的叶子节点由Checkpointed Page(CP)表示,每个CP包含了Version以及Backup PM页面的地址(paddr)。在恢复过程中,TreeSLS比对Backup Radix Tree与Runtime Radix Tree已选择一致的物理页面。假设全局版本号为5。那么会存在三种情况:
① Backup的页面版本 = 全局版本:说明页面已经被Backup了,选择Backup页面
② Backup的页面版本 < 全局版本:说明Runtime Page还没有Checkpoint(Backup),选择Runtime页面
③ Backup的页面版本为空:说明页面没有被Checkpoint,选择Runtime页面。为空是因为这个页面一直没有被修改(没有脏),所以不会被Backup。
3.3 Hybrid Copy (§4.3)
基于Capability Tree的系统全局状态获取以及轻量的状态拷贝,TreeSLS实现了轻量的Checkpoint。TreeSLS还需要进一步减少Runtime的开销。TreeSLS发现当Checkpoint的频率足够高时(1ms),Runtime开销非常大,大多数开销来源于处理Page Fault以及对应的页面拷贝。
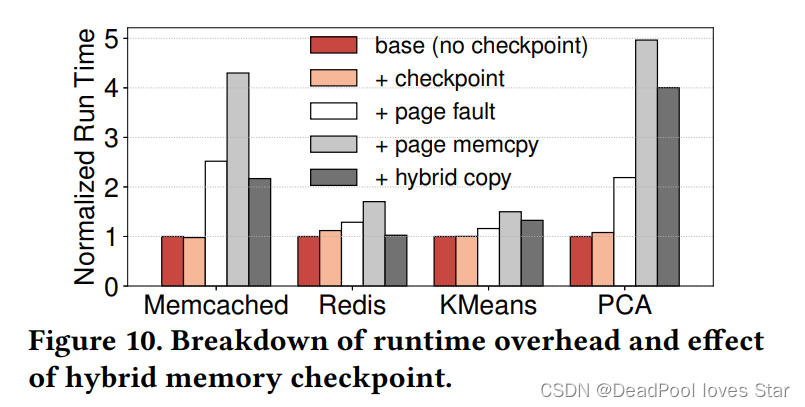
为了减少Runtime时,来自页面拷贝的开销,TreeSLS探索了四种方案:
- Stop-and-Copy:在Checkpoint的过程中拷贝页面,避免Page Fault。
- Speculative Stop-and-Copy:在Runtime过程中(Checkpoint之前)预测可能会被拷贝的页面,并提前拷贝,减少Checkpoint开销。
- Copy-on-Write:在Runtime过程中触发Page Fault,拷贝页面。
- Speculative Copy-on-Write:在触发Page Fault前预测可能会触发COW的页面,并提前拷贝,减少Page Fault开销。但错误的预取可能反而降低系统性能。

TreeSLS提出Hybrid Copy,这种方案结合了Stop-and-Copy与Speculative Copy-on-Write的思想。Hybrid Copy基于两个观察:
- 应用具有访问的空间局部性,即某些物理页面会多次访问,这些页面被称为Hot Pages。为了提升Runtime性能,TreeSLS将Hot Pages迁移至DRAM中,并在Checkpoint时通过Stop-and-Copy将这些页面拷贝至PM中。这样的,在Page Fault前进行拷贝的操作可以被视为一种Speculative Copy。
- Stop-and-Copy的过程可以与Checkpoint的过程并行执行,即那些被IPI暂停的CPU可以被用起来进行Stop-and-Copy,从而避免Stop-and-Copy在Checkpoint时带来的额外开销。
接下来要解决的问题便是如何进行Hot Page的检测与迁移以及对应的崩溃一致性。
3.3.1 Hot Page检测与迁移
TreeSLS通过Dual-Function Active Page List来跟踪Hot Pages。每当Page Fault发生时,TreeSLS增加对应Page的热度,一旦热度超过某个阈值时,TreeSLS将该Page追加到List中。在Checkpoint过程中,所有除Leader外的CPU会遍历List的一段(sub-list),脏页会通过Stop-and-Copy被写回PM,而自上个检查点后新追加的页面会被迁移至DRAM中。对于那些热度不够的页面会从DRAM中迁移回PM中,并从List中移除。这些页面的热度会被清空。
3.3.2 崩溃一致性拓展
为了支持Hybrid Copy,Backup Radix Tree需要维护两个备份,一个用于从DRAM中向PM中Checkpoint(这个过程可能因为掉电变得不一致),另一个用于绝对一致的Checkpoint(因为没有写入,它保证一致)。为此,TreeSLS拓展了原来Backup Tree的CP至Checkpointed Page Pairs(CPP)。后者维护两个页面备份。下面讨论三种情况。
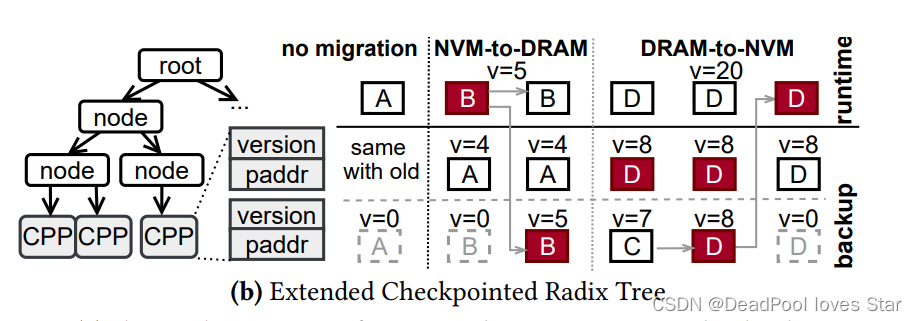
- 当没有迁移发生时,CPP中的第一个备份页面为Backup Page,第二个备份页面为Runtime Page。在这个情况下,与原有的崩溃一致性相同。
- 当发生PM到DRAM的页面迁移时(PM的页面很热),TreeSLS在DRAM中分配一个内存页,并将PM中对应的Runtime Page拷贝至DRAM中。接着,TreeSLS更新页表以使用DRAM中的页面。然后,TreeSLS将Backup Tree中CPP对应的Runtime Page的Version置为Global Version,于是该Runtime Page变为最新的Backup Page。接下来,CPP中的这两个Page可以被交替使用以保存DRAM中的Runtime Page。
- 当发生DRAM到PM的页面迁移时(DRAM中的页面没被更新),此时DRAM中的页面内容与PM上的某一个Backup Page内容一致。TreeSLS确保第二个备份页面为最新的数据(如果必要的话将DRAM Page中的数据拷贝至该页面中)。接着,TreeSLS将第二个备份页面版本置为0,并更新页表使得第二个备份页面变为PM上的Runtime Page。
3.4 Transparent External Synchrony (§5)
为了支持外部同步性,SLS需要确保在响应外部系统前,请求状态的更改需要被持久化(而不是异步的)。得益于TreeSLS的高频Checkpoint,TreeSLS将External Visible操作(例如发送网络包)延迟到下一次Checkpoint完成时。
为了保证对应用的透明,TreeSLS为用户态系统服务程序注册Checkpoint Callback,每当Checkpoint完成后都会调用该Callback;此外,还会注册一个Restore Callback,在每次Recovery完成后调用。这样一来, TreeSLS将保证External Synchrony的任务向下递交给驱动程序,而应用可以透明地获得External Synchrony的保证。
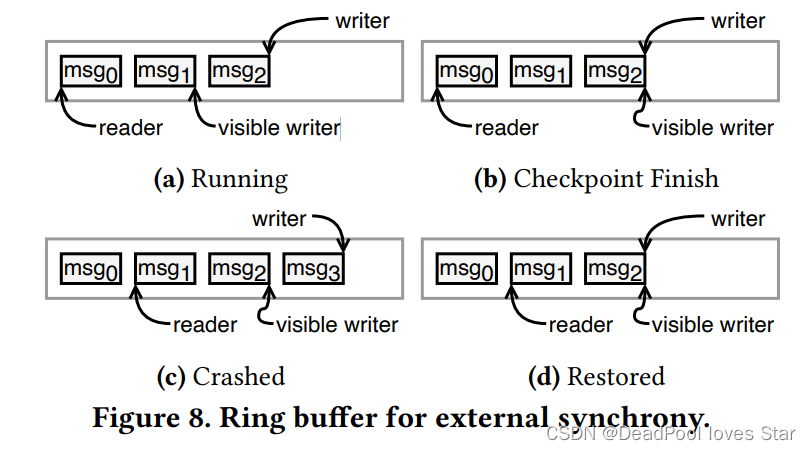
以网络驱动的Send Queue为例:
(a) 为了发送msg2,msg2被追加到Queue中,并且更新writer指针。当前msg2还没有被发送。
(b) 当Checkpoint完成后,Checkpoint Callback被调用,Driver更新visible writer指针来发送msg2,此时Driver的状态已经持久化。
© 掉电后的状态。
(d) 系统恢复到上个检查点状态,Restore Callback被调用,msg3被丢弃因为上个检查点msg3还没有被Checkpoint。应用会重新发送msg3(因为回到了上个检查点状态)。
3.5 实现 (§6)
TreeSLS基于上交ChCore实现,相关代码位于:https://ipads.se.sjtu.edu.cn/projects/treesls.html。看起来本工作的难点主要有如下几个方面:
- 能够跑在真实的傲腾服务器上,如何与PM交互的,值得研究。
- 如何快速在服务器上上路操作系统的,值得研究。
- 如何编写脚本获取对比测试性能(Linux/Aurora/TreeSLS)的,值得研究。
4. 评估 (Evaluation)
4.1 实验设置 (§7.1)
-
环境
-
CPU:Dual Intel® Xeon® Gold 6330 CPUs(支持eADR)
-
DRAM:256GiB DDR4 DRAM
-
PM:1 TiB Intel® Optane™ Persistent Memory
-
-
测试负载
-
Phoenix-2.0 test suite
-
Redis and Memcached
-
LevelDB and RocksDB
-
SQLite3
-
-
对比对象
Aurora及Linux
4.2 功能性测试 (§7.2)
略
4.3 Checkpoint STW开销 (§7.3)
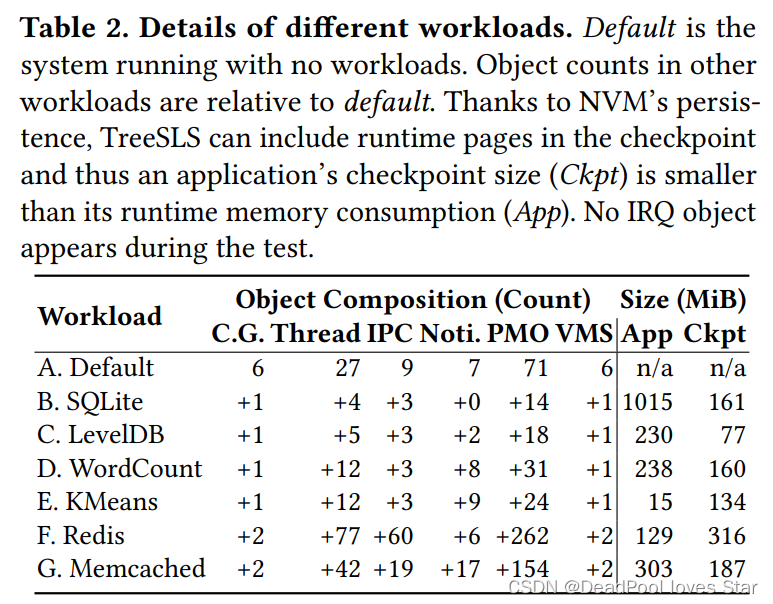
测试负载以及占用空间。在大多数情况下,Checkpoint的大小比运行时App大小消耗要小。
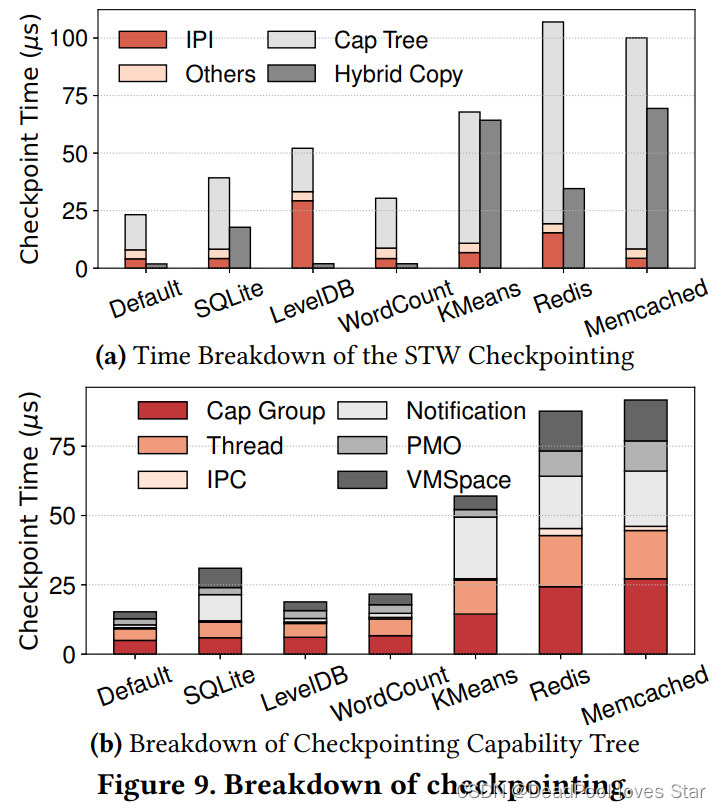
增量Checkpoint性能分解。下图(a)左边的柱子表示Checkpoint性能分解,右边柱子表明并发执行的Hybrid Copy开销。可以看到Checkpoint时间都不超过100us。图(b)将Capability Tree的Checkpoint进一步分解,可以看到开销主要在Thread和Cap Group上,因为他们的数量很多(见上表)。VM Space(VMS)开销不大是因为无需拷贝物理页面,只需要修改页表对应项为只读。
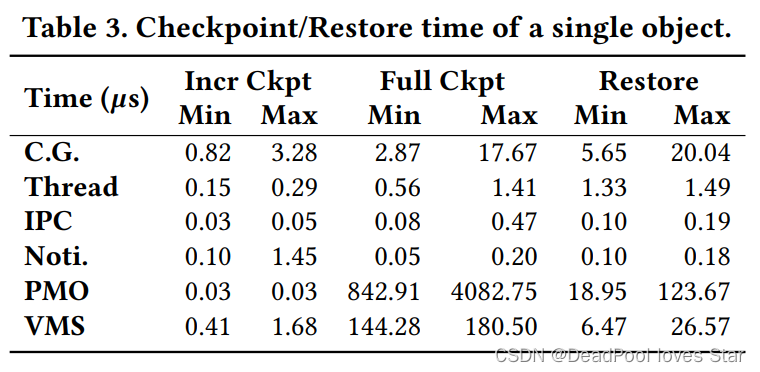
单个对象Checkpoint/Restore性能。分为全量Checkpoint(Full Ckpt)和增量Checkpoint(Incr Ckpt)两种。增量很快因为许多对象都可被重用。全量很慢,例如PMO需要重新构建其Radix Tree。
4.4 运行时开销 (§7.4)
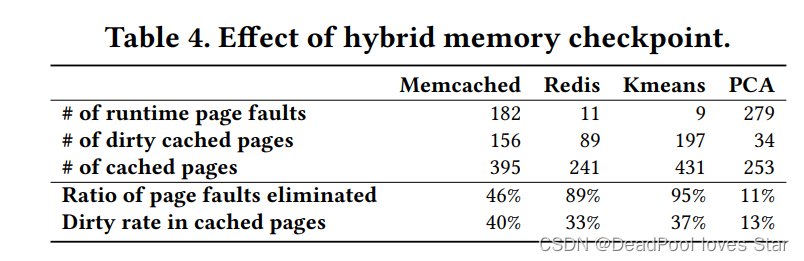
Hybrid Copy。3.3已经给出了Hybrid Copy的性能提升。下面给出Hybrid Copy在不同应用下的精确统计,效果很好。
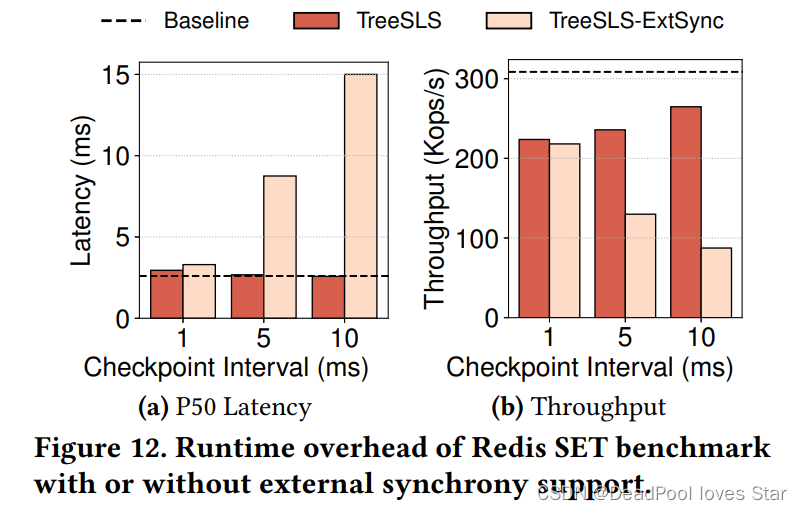
Checkpoint频率影响。Baseline时没有Checkpoint的C-S通信,TreeSLS(1ms的Checkpoint Intervel)添加了额外11-160us的延迟。

External Synchrony。很明显开启External Synchrony后,系统的延迟上升,带宽下降。是否启动TreeSLS对总体性能影响较小。
4.5 真实应用 (§7.5)
内存KV Store。YCSB + redis。TreeSLS带来的下降比WAL(崩溃一致性机制)带来的下降要少得多。

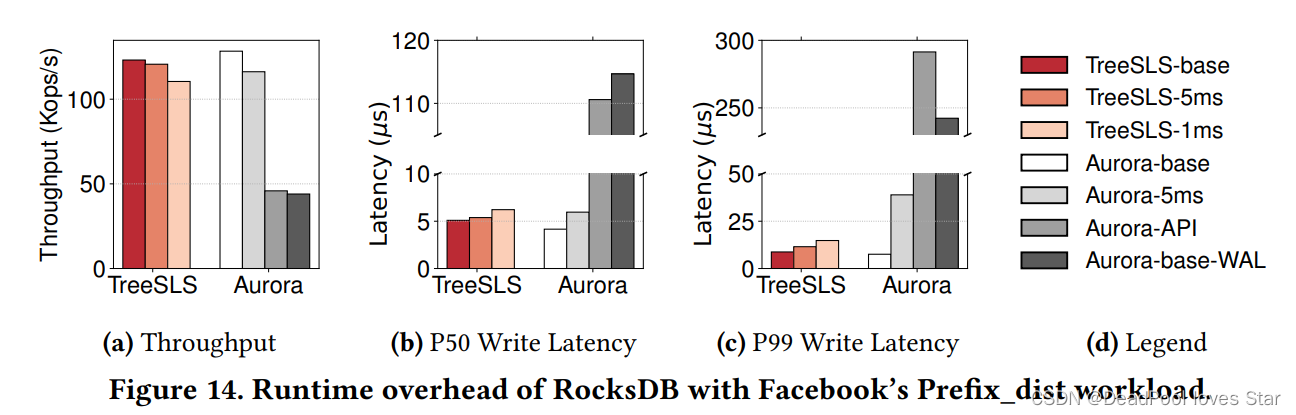
持久化KV Store。”-base”代表无persistence,“Aurora-base-WAL”代表RocksDB在DRAM上实现WAL,“-5ms、-1ms”代表Checkpoint频率,“Aurora-API”代表使用Aurora自定义API。Aurora被配置为使用DRAM作为Storage(很奇怪的配置,猜测是Aurora没有PM驱动?)。下图显示TreeSLS-1ms带来的性能下降较小,而Aurora采用定制Journaling API需要多次I/O,而TreeSLS保证in-memoyr的操作能够持久化。
总结
TreeSLS的最大贡献在于充分利用PM的内存与存储特性,结合PM-aware的Checkpoint技术构建了一个高性能Single Level Store操作系统,该系统能够在Runtime PM Page和Checkpointed PM Page间做出交互,从而避免传统SLS面临的大量数据拷贝问题。TreeSLS在很大程度上表明了在PM上实现SLS的可行性。