PoolFormer
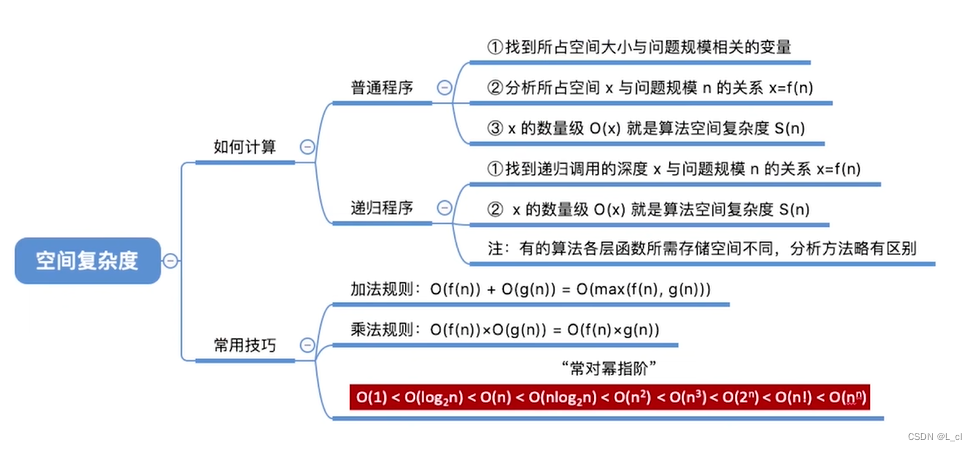
MetaFormer是颜水成大佬的一篇Transformer的论文,该篇论文的贡献主要有两点:第一、将Transformer抽象为一个通用架构的MetaFormer,并通过经验证明MetaFormer架构在Transformer/ mlp类模型取得了极大的成功。 第二、通过仅采用简单的非参数算子pooling作为MetaFormer的极弱token混合器,构建了一个名为PoolFormer。
原文地址:MetaFormer Is Actually What You Need for Vision
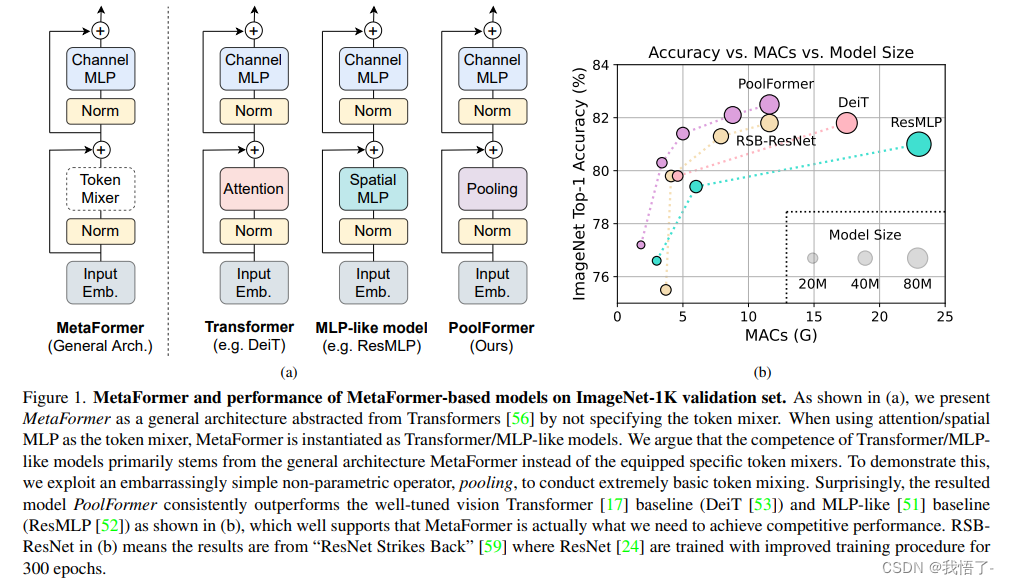
Transformer编码器如图1(a)所示,由两部分组成。一个是注意力模块,用于在token之间混合信息,我们将其称为token mixer。另一个组件包含剩余的模块,如通道mlp和残差连接。transformer的成功归功于基于注意力的token混合器。基于这一共识,已经开发了许多注意力模块的变体,以改进视觉Transformer,比如上篇DEiT就是增加了一个dist token。
最近的一些方法在MetaFormer架构中探索了其他类型的token mixers,例如,用傅里叶变换取代了注意力,仍然达到了普通transformer的约97%的精度。综合所有这些结果,似乎只要模型采用MetaFormer作为通用架构,就可以获得非常优秀的结果。为了验证这一假设,作者应用一个极其简单的非参数操作符pooling作为令牌混合器,只进行基本的令牌混合,将其命名为PoolFormer。PoolFormer-M36在ImageNet-1K分类基准上达到82.1%的top-1精度,超过了DeiT[53]和ResMLP[52]等调优的视觉变压器,充分展示了MetaFormer通用架构的优秀性能。
PoolFormer代码实现
# Copyright 2021 Garena Online Private Limited
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
PoolFormer implementation
"""
import os
import copy
import torch
import torch.nn as nn
import numpy as np
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, trunc_normal_, to_2tuple
from timm.models.registry import register_model
__all__ = ['poolformer_s12', 'poolformer_s24', 'poolformer_s36', 'poolformer_m48', 'poolformer_m36']
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'pool_size': None,
'crop_pct': .95, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'classifier': 'head',
**kwargs
}
default_cfgs = {
'poolformer_s': _cfg(crop_pct=0.9),
'poolformer_m': _cfg(crop_pct=0.95),
}
class PatchEmbed(nn.Module):
"""
Patch Embedding that is implemented by a layer of conv.
Input: tensor in shape [B, C, H, W]
Output: tensor in shape [B, C, H/stride, W/stride]
"""
def __init__(self, patch_size=16, stride=16, padding=0,
in_chans=3, embed_dim=768, norm_layer=None):
super().__init__()
patch_size = to_2tuple(patch_size)
stride = to_2tuple(stride)
padding = to_2tuple(padding)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size,
stride=stride, padding=padding)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
x = self.proj(x)
x = self.norm(x)
return x
class LayerNormChannel(nn.Module):
"""
LayerNorm only for Channel Dimension.
Input: tensor in shape [B, C, H, W]
"""
def __init__(self, num_channels, eps=1e-05):
super().__init__()
self.weight = nn.Parameter(torch.ones(num_channels))
self.bias = nn.Parameter(torch.zeros(num_channels))
self.eps = eps
def forward(self, x):
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight.unsqueeze(-1).unsqueeze(-1) * x \
+ self.bias.unsqueeze(-1).unsqueeze(-1)
return x
class GroupNorm(nn.GroupNorm):
"""
Group Normalization with 1 group.
Input: tensor in shape [B, C, H, W]
"""
def __init__(self, num_channels, **kwargs):
super().__init__(1, num_channels, **kwargs)
class Pooling(nn.Module):
"""
Implementation of pooling for PoolFormer
--pool_size: pooling size
"""
def __init__(self, pool_size=3):
super().__init__()
self.pool = nn.AvgPool2d(
pool_size, stride=1, padding=pool_size//2, count_include_pad=False)
def forward(self, x):
return self.pool(x) - x
class Mlp(nn.Module):
"""
Implementation of MLP with 1*1 convolutions.
Input: tensor with shape [B, C, H, W]
"""
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Conv2d):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class PoolFormerBlock(nn.Module):
"""
Implementation of one PoolFormer block.
--dim: embedding dim
--pool_size: pooling size
--mlp_ratio: mlp expansion ratio
--act_layer: activation
--norm_layer: normalization
--drop: dropout rate
--drop path: Stochastic Depth,
refer to https://arxiv.org/abs/1603.09382
--use_layer_scale, --layer_scale_init_value: LayerScale,
refer to https://arxiv.org/abs/2103.17239
"""
def __init__(self, dim, pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=GroupNorm,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
self.norm1 = norm_layer(dim)
self.token_mixer = Pooling(pool_size=pool_size)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
# The following two techniques are useful to train deep PoolFormers.
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(
self.layer_scale_1.unsqueeze(-1).unsqueeze(-1)
* self.token_mixer(self.norm1(x)))
x = x + self.drop_path(
self.layer_scale_2.unsqueeze(-1).unsqueeze(-1)
* self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.token_mixer(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def basic_blocks(dim, index, layers,
pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=GroupNorm,
drop_rate=.0, drop_path_rate=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
"""
generate PoolFormer blocks for a stage
return: PoolFormer blocks
"""
blocks = []
for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (
block_idx + sum(layers[:index])) / (sum(layers) - 1)
blocks.append(PoolFormerBlock(
dim, pool_size=pool_size, mlp_ratio=mlp_ratio,
act_layer=act_layer, norm_layer=norm_layer,
drop=drop_rate, drop_path=block_dpr,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
))
blocks = nn.Sequential(*blocks)
return blocks
class PoolFormer(nn.Module):
"""
PoolFormer, the main class of our model
--layers: [x,x,x,x], number of blocks for the 4 stages
--embed_dims, --mlp_ratios, --pool_size: the embedding dims, mlp ratios and
pooling size for the 4 stages
--downsamples: flags to apply downsampling or not
--norm_layer, --act_layer: define the types of normalization and activation
--num_classes: number of classes for the image classification
--in_patch_size, --in_stride, --in_pad: specify the patch embedding
for the input image
--down_patch_size --down_stride --down_pad:
specify the downsample (patch embed.)
--fork_feat: whether output features of the 4 stages, for dense prediction
--init_cfg, --pretrained:
for mmdetection and mmsegmentation to load pretrained weights
"""
def __init__(self, layers, embed_dims=None,
mlp_ratios=None, downsamples=None,
pool_size=3,
norm_layer=GroupNorm, act_layer=nn.GELU,
num_classes=1000,
in_patch_size=7, in_stride=4, in_pad=2,
down_patch_size=3, down_stride=2, down_pad=1,
drop_rate=0., drop_path_rate=0.,
use_layer_scale=True, layer_scale_init_value=1e-5,
fork_feat=True,
init_cfg=None,
pretrained=None,
**kwargs):
super().__init__()
if not fork_feat:
self.num_classes = num_classes
self.fork_feat = fork_feat
self.patch_embed = PatchEmbed(
patch_size=in_patch_size, stride=in_stride, padding=in_pad,
in_chans=3, embed_dim=embed_dims[0])
# set the main block in network
network = []
for i in range(len(layers)):
stage = basic_blocks(embed_dims[i], i, layers,
pool_size=pool_size, mlp_ratio=mlp_ratios[i],
act_layer=act_layer, norm_layer=norm_layer,
drop_rate=drop_rate,
drop_path_rate=drop_path_rate,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value)
network.append(stage)
if i >= len(layers) - 1:
break
if downsamples[i] or embed_dims[i] != embed_dims[i+1]:
# downsampling between two stages
network.append(
PatchEmbed(
patch_size=down_patch_size, stride=down_stride,
padding=down_pad,
in_chans=embed_dims[i], embed_dim=embed_dims[i+1]
)
)
self.network = nn.ModuleList(network)
if self.fork_feat:
# add a norm layer for each output
self.out_indices = [0, 2, 4, 6]
for i_emb, i_layer in enumerate(self.out_indices):
if i_emb == 0 and os.environ.get('FORK_LAST3', None):
# TODO: more elegant way
"""For RetinaNet, `start_level=1`. The first norm layer will not used.
cmd: `FORK_LAST3=1 python -m torch.distributed.launch ...`
"""
layer = nn.Identity()
else:
layer = norm_layer(embed_dims[i_emb])
layer_name = f'norm{i_layer}'
self.add_module(layer_name, layer)
else:
# Classifier head
self.norm = norm_layer(embed_dims[-1])
self.head = nn.Linear(
embed_dims[-1], num_classes) if num_classes > 0 \
else nn.Identity()
self.init_cfg = copy.deepcopy(init_cfg)
self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 224, 224))]
def reset_classifier(self, num_classes):
self.num_classes = num_classes
self.head = nn.Linear(
self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_embeddings(self, x):
x = self.patch_embed(x)
return x
def forward_tokens(self, x):
outs = []
for idx, block in enumerate(self.network):
x = block(x)
if self.fork_feat and idx in self.out_indices:
norm_layer = getattr(self, f'norm{idx}')
x_out = norm_layer(x)
outs.append(x_out)
return outs
def forward(self, x):
# input embedding
x = self.forward_embeddings(x)
# through backbone
x = self.forward_tokens(x)
return x
model_urls = {
"poolformer_s12": "https://github.com/sail-sg/poolformer/releases/download/v1.0/poolformer_s12.pth.tar",
"poolformer_s24": "https://github.com/sail-sg/poolformer/releases/download/v1.0/poolformer_s24.pth.tar",
"poolformer_s36": "https://github.com/sail-sg/poolformer/releases/download/v1.0/poolformer_s36.pth.tar",
"poolformer_m36": "https://github.com/sail-sg/poolformer/releases/download/v1.0/poolformer_m36.pth.tar",
"poolformer_m48": "https://github.com/sail-sg/poolformer/releases/download/v1.0/poolformer_m48.pth.tar",
}
def update_weight(model_dict, weight_dict):
idx, temp_dict = 0, {}
for k, v in weight_dict.items():
if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):
temp_dict[k] = v
idx += 1
model_dict.update(temp_dict)
print(f'loading weights... {idx}/{len(model_dict)} items')
return model_dict
def poolformer_s12(pretrained=False, **kwargs):
"""
PoolFormer-S12 model, Params: 12M
--layers: [x,x,x,x], numbers of layers for the four stages
--embed_dims, --mlp_ratios:
embedding dims and mlp ratios for the four stages
--downsamples: flags to apply downsampling or not in four blocks
"""
layers = [2, 2, 6, 2]
embed_dims = [64, 128, 320, 512]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(
layers, embed_dims=embed_dims,
mlp_ratios=mlp_ratios, downsamples=downsamples,
**kwargs)
model.default_cfg = default_cfgs['poolformer_s']
if pretrained:
url = model_urls['poolformer_s12']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(update_weight(model.state_dict(), checkpoint))
return model
def poolformer_s24(pretrained=False, **kwargs):
"""
PoolFormer-S24 model, Params: 21M
"""
layers = [4, 4, 12, 4]
embed_dims = [64, 128, 320, 512]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(
layers, embed_dims=embed_dims,
mlp_ratios=mlp_ratios, downsamples=downsamples,
**kwargs)
model.default_cfg = default_cfgs['poolformer_s']
if pretrained:
url = model_urls['poolformer_s24']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(update_weight(model.state_dict(), checkpoint))
return model
def poolformer_s36(pretrained=False, **kwargs):
"""
PoolFormer-S36 model, Params: 31M
"""
layers = [6, 6, 18, 6]
embed_dims = [64, 128, 320, 512]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(
layers, embed_dims=embed_dims,
mlp_ratios=mlp_ratios, downsamples=downsamples,
layer_scale_init_value=1e-6,
**kwargs)
model.default_cfg = default_cfgs['poolformer_s']
if pretrained:
url = model_urls['poolformer_s36']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(update_weight(model.state_dict(), checkpoint))
return model
def poolformer_m36(pretrained=False, **kwargs):
"""
PoolFormer-M36 model, Params: 56M
"""
layers = [6, 6, 18, 6]
embed_dims = [96, 192, 384, 768]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(
layers, embed_dims=embed_dims,
mlp_ratios=mlp_ratios, downsamples=downsamples,
layer_scale_init_value=1e-6,
**kwargs)
model.default_cfg = default_cfgs['poolformer_m']
if pretrained:
url = model_urls['poolformer_m36']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(update_weight(model.state_dict(), checkpoint))
return model
@register_model
def poolformer_m48(pretrained=False, **kwargs):
"""
PoolFormer-M48 model, Params: 73M
"""
layers = [8, 8, 24, 8]
embed_dims = [96, 192, 384, 768]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, True, True, True]
model = PoolFormer(
layers, embed_dims=embed_dims,
mlp_ratios=mlp_ratios, downsamples=downsamples,
layer_scale_init_value=1e-6,
**kwargs)
model.default_cfg = default_cfgs['poolformer_m']
if pretrained:
url = model_urls['poolformer_m48']
checkpoint = torch.hub.load_state_dict_from_url(url=url, map_location="cpu", check_hash=True)
model.load_state_dict(update_weight(model.state_dict(), checkpoint))
return model
if __name__ == '__main__':
model = poolformer_s12(pretrained=True)
inputs = torch.randn((1, 3, 640, 640))
for i in model(inputs):
print(i.size())
Backbone替换
yolo.py修改
def parse_model函数
def parse_model(d, ch): # model_dict, input_channels(3)
# Parse a YOLOv5 model.yaml dictionary
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')
if act:
Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
LOGGER.info(f"{colorstr('activation:')} {act}") # print
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
is_backbone = False
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
try:
t = m
m = eval(m) if isinstance(m, str) else m # eval strings
except:
pass
for j, a in enumerate(args):
with contextlib.suppress(NameError):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
args[j] = a
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in {
Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
# TODO: channel, gw, gd
elif m in {Detect, Segment}:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
if m is Segment:
args[3] = make_divisible(args[3] * gw, 8)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
elif isinstance(m, str):
t = m
m = timm.create_model(m, pretrained=args[0], features_only=True)
c2 = m.feature_info.channels()
elif m in {poolformer_s12}: #可添加更多Backbone
m = m(*args)
c2 = m.channel
else:
c2 = ch[f]
if isinstance(c2, list):
is_backbone = True
m_ = m
m_.backbone = True
else:
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type, m_.np = i + 4 if is_backbone else i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
save.extend(x % (i + 4 if is_backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
if isinstance(c2, list):
ch.extend(c2)
for _ in range(5 - len(ch)):
ch.insert(0, 0)
else:
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
def _forward_once函数
def _forward_once(self, x, profile=False, visualize=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
if hasattr(m, 'backbone'):
x = m(x)
for _ in range(5 - len(x)):
x.insert(0, None)
for i_idx, i in enumerate(x):
if i_idx in self.save:
y.append(i)
else:
y.append(None)
x = x[-1]
else:
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x
创建.yaml配置文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, poolformer_s12, [False]], # 4
[-1, 1, SPPF, [1024, 5]], # 5
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]], # 6
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 7
[[-1, 3], 1, Concat, [1]], # cat backbone P4 8
[-1, 3, C3, [512, False]], # 9
[-1, 1, Conv, [256, 1, 1]], # 10
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 11
[[-1, 2], 1, Concat, [1]], # cat backbone P3 12
[-1, 3, C3, [256, False]], # 13 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]], # 14
[[-1, 10], 1, Concat, [1]], # cat head P4 15
[-1, 3, C3, [512, False]], # 16 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]], # 17
[[-1, 5], 1, Concat, [1]], # cat head P5 18
[-1, 3, C3, [1024, False]], # 19 (P5/32-large)
[[13, 16, 19], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]