文章目录
- 1、关于定时任务
- 2、Java原生实现
- 3、相关名词
- 4、SpringBoot整合Quartz
- 5、Quartz的通用配置
- 6、关于QuartzJobBean
- 7、关于调度器Scheduler的绑定
- 8、Quartz持久化
1、关于定时任务
定时任务在实际开发中使用场景很多,比如:
- 年度报告
- 各种统计报告
- 某个同步任务
而定时任务的实现技术,业界流行的有:
- Quartz
- Spring Task
2、Java原生实现
demo代码如下:TimerTask是一个抽象类,new它的对象要实现方法,而它里面的run方法,应该能想到的是多线程也有个run,而定时任务也确实是这个run,到时间了以后就去开一个异步线程来执行任务。(TimerTask实现了Runnable接口)
import java.util.Timer;
import java.util.TimerTask;
public class TaskTest{
public static void main(String[] args){
Timer timer = new Timer();
TimerTask task = new TimerTask(){
@Override
public void run(){
System.out.println("task...");
}
}
timer.schedule(task,0,2000); //传入要执行的任务,0即从现在开始,2000即每隔两秒执行一次
}
}
简单执行下,效果为每两秒输出以下task…

以上为原生Java的实现,在此基础上,市面上出现了更加完善和规范的落地技术Quartz,于是,Spring整合了Quartz,后来,Spring又推出了自己的Spring Task
3、相关名词
- 工作(Job):用于定义具体执行的工作
- 工作明细(JobDetail):用于描述定时工作相关的信息
- 触发器(Trigger):用于描述触发工作的规则,通常使用cron表达式定义调度规则
- 调度器(Scheduler):描述了工作明细与触发器的对应关系
其中,Job被JobDetail绑定,JobDetail又被Trigger绑定。
4、SpringBoot整合Quartz
导入Quartz起步依赖坐标:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
继承QuartzJobBean,定义具体要执行的任务:
public class QuartzTaskBean extends QuartzJobBean {
@Override
protected void executeInternal(JobExecutionContext context) throws JobExecutionException {
//...这里写定时任务的逻辑代码
System.out.println("quartz job run... ");
}
}
定义工作明细与触发器,并绑定对应关系:
@Configuration
public class QuartzConfig {
@Bean
public JobDetail printJobDetail(){
return JobBuilder.newJob(QuartzTaskBean.class) //传入上面的Job类,实现绑定到JobDetail
.storeDurably() //持久化,storeDurably()方法是用来持久化的,即Job创建完以后若当时没有使用,是否要持久化一下先存起来
.build();
}
@Bean
public Trigger printJobTrigger() {
CronScheduleBuilder cronScheduleBuilder = CronScheduleBuilder.cronSchedule("0/3 * * * * ?");
return TriggerBuilder.newTrigger()
.forJob(printJobDetail()) //绑定JobDetail
.withSchedule(cronScheduleBuilder)
.build();
}
}
整合完成,重启服务看下效果:

5、Quartz的通用配置
以上整合中,不用加任何配置,采用默认配置就完成了定时任务。但还可以在服务的yml配置文件中对Quartz进行更详细的配置。(可选)
spring:
# Quartz 的配置,对应 QuartzProperties 配置类
quartz:
job-store-type: memory # Job 存储器类型。默认为 memory 表示内存,可选 jdbc 使用数据库。
auto-startup: true # Quartz 是否自动启动
startup-delay: 0 # 延迟 N 秒启动
wait-for-jobs-to-complete-on-shutdown: true # 应用关闭时,是否等待定时任务执行完成。默认为 false ,建议设置为 true
overwrite-existing-jobs: false # 是否覆盖已有 Job 的配置
properties: # 添加 Quartz Scheduler 附加属性
org:
quartz:
threadPool:
threadCount: 25 # 线程池大小。默认为 10 。
threadPriority: 5 # 线程优先级
class: org.quartz.simpl.SimpleThreadPool # 线程池类型
# jdbc: # 这里暂时不说明,使用 JDBC 的 JobStore 的时候,才需要配置
这些yaml配置自然有对应的实体类去读取和接收,这个实体类就是QuartzProperties搭配@ConfigurationProperties注解:
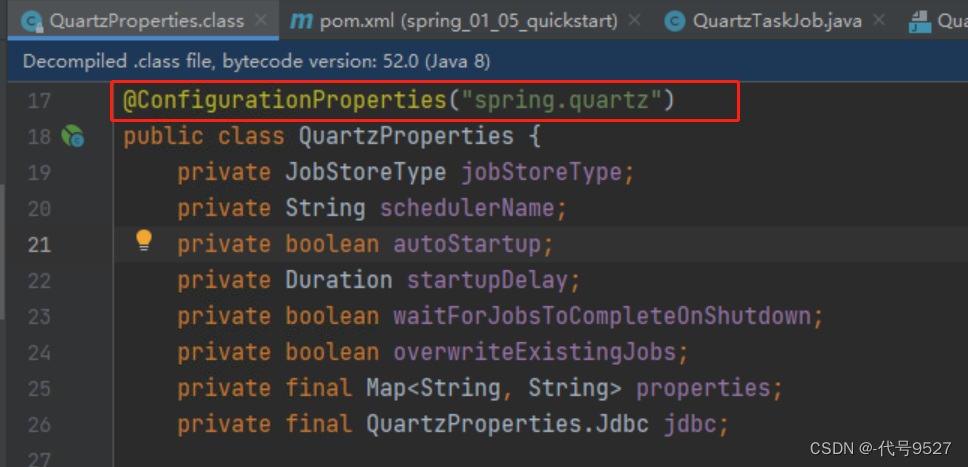
6、关于QuartzJobBean
QuartzJobBean类的源码:它实现了Job,并且定义了公用的execute方法
public abstract class QuartzJobBean implements Job {
/**
* This implementation applies the passed-in job data map as bean property
* values, and delegates to {@code executeInternal} afterwards.
* @see #executeInternal
*/
@Override
public final void execute(JobExecutionContext context) throws JobExecutionException {
try {
// 将当前对象包装为BeanWrapper
BeanWrapper bw = PropertyAccessorFactory.forBeanPropertyAccess(this);
// 设置属性
MutablePropertyValues pvs = new MutablePropertyValues();
pvs.addPropertyValues(context.getScheduler().getContext());
pvs.addPropertyValues(context.getMergedJobDataMap());
bw.setPropertyValues(pvs, true);
}
catch (SchedulerException ex) {
throw new JobExecutionException(ex);
}
// 子类实现该方法
executeInternal(context);
}
/**
* Execute the actual job. The job data map will already have been
* applied as bean property values by execute. The contract is
* exactly the same as for the standard Quartz execute method.
* @see #execute
*/
protected abstract void executeInternal(JobExecutionContext context) throws JobExecutionException;
}
因此,创建Job的时候,可以继承QuartzJobBean类,也可直接实现Job接口,但继承QuartzJobBean并实现executeInternal方法,当然效率最高
7、关于调度器Scheduler的绑定
Scheduler绑定有两种方式,一种是使用bena的自动配置,一种是Scheduler手动配置。上面整合时,采用的是自动配置的方式,即定义两个Bean以及它们之间的关系,然后交给Spring容器管理。这里再补充一下手动配置的方式:实现Spring的ApplicationRuunner接口,注入Quartz的Scheduler对象,调用scheduleJob方法完成手动绑定。
@Component
public class QuartzJob implements ApplicationRunner {
@Resource
private Scheduler scheduler;
@Override
public void run(ApplicationArguments args) throws Exception {
//创建JobDetail对象
JobDetail jobDetail = JobBuilder.newJob(QuartzTaskBean.class)
.storeDurably()
.build();
// 简单的调度计划的构造器
SimpleScheduleBuilder scheduleBuilder = SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(5) // 频率
.repeatForever(); // 次数
// 创建任务触发器
Trigger trigger = TriggerBuilder.newTrigger()
.forJob(jobDetail)
.withSchedule(scheduleBuilder)
.startNow() //立即执行一次任務
.build();
// 手动将触发器与任务绑定到调度器内
scheduler.scheduleJob(jobDetail, trigger);
}
}
注意,这个类要注册成一个Bean,记得放在被Spring容器能扫描到的目录下。此外,上面没有用Cron表达式的调度器,用的简单的调度计划,调这个类提供的方法来描述你的执行规则就行。

8、Quartz持久化
Quartz持久化配置提供了两种存储器:RAMJobStore和JDBCJobStore,就是内存和硬盘:默认是内存形式维护任务信息,意味着服务重启了任务就从头再来,之前的执行数据等就全没了
| 存储方式 | 优点 | 缺点 |
|---|---|---|
| RAMJobStore | 不要外部数据库,配置容易,运行速度快 | 因为调度程序信息是存储在被分配给 JVM 的内存里面,所以,当应用程序停止运行时,所有调度信息将被丢失。另外因为存储到JVM内存里面,所以可以存储多少个 Job 和 Trigger 将会受到限制 |
| JDBCJobStore | 支持集群,因为所有的任务信息都会保存到数据库中,可以控制事物,还有就是如果应用服务器关闭或者重启,任务信息都不会丢失,并且可以恢复因服务器关闭或者重启而导致执行失败的任务 | 运行速度的快慢取决与连接数据库的快慢 |
下面实现持久化到MySQL,首先创建Quartz数据库,脚本在:
org\quartz-scheduler\quartz\2.3.2\quartz-2.3.2.jar!\org\quartz\impl\jdbcjobstore\tables_mysql_innodb.sql
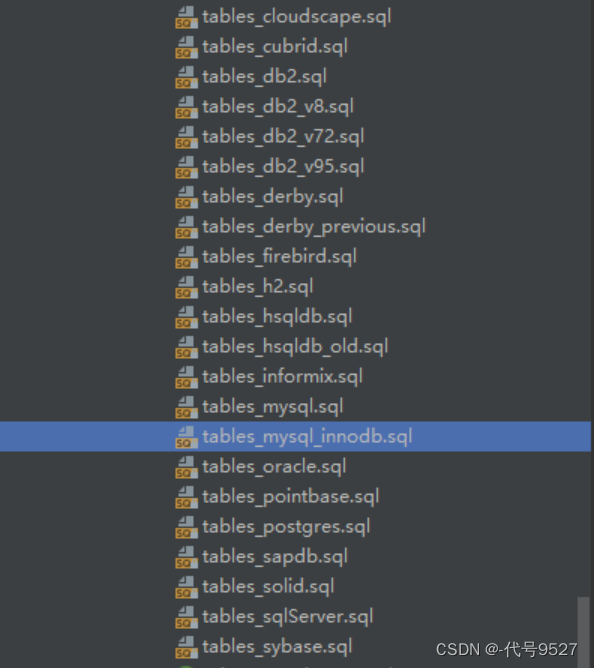
这里有各种数据库类型的SQL脚本,执行完MySQL后查看表:
mysql> use quartz;
Database changed
mysql> show tables;
+--------------------------+
| Tables_in_quartz |
+--------------------------+
| qrtz_blob_triggers |## blog类型存储triggers
| qrtz_calendars |## 以blog类型存储Calendar信息
| qrtz_cron_triggers |## 存储cron trigger信息
| qrtz_fired_triggers |## 存储已触发的trigger相关信息
| qrtz_job_details |## 存储每一个已配置的job details
| qrtz_locks |## 存储悲观锁的信息
| qrtz_paused_trigger_grps |## 存储已暂停的trigger组信息
| qrtz_scheduler_state |## 存储Scheduler状态信息
| qrtz_simple_triggers |## 存储simple trigger信息
| qrtz_simprop_triggers |## 存储其他几种trigger信息
| qrtz_triggers |## 存储已配置的trigger信息
+--------------------------+
加MySQL驱动以及JDBC的依赖坐标(看技术选型,采用MySQL驱动+MyBatis的不用加,MyBatis起步依赖下面包含Jdbc Starter)
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!--看当前项目的已有依赖,很多封装JDBC的框架starter包含jdbc-starter-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!--数据源自己选吧,我用的druid,一般接手的项目这些肯定都有了-->
修改application.yml:
# 旧的数据源配置,用的druid
spring:
datasource:
druid:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test_quartz?serverTimezone=GMT%2B8
username: root
password: root123
# quartz持久化的关键配置
quartz:
job-store-type: jdbc # 使用数据库存储
scheduler-name: testScheduler # 相同 Scheduler 名字的节点,形成一个 Quartz 集群
wait-for-jobs-to-complete-on-shutdown: true # 应用关闭时,是否等待定时任务执行完成。默认为 false ,建议设置为 true
jdbc:
initialize-schema: never # 是否自动使用 SQL 初始化 Quartz 表结构。这里设置成 never ,我们手动创建表结构。可以选择always,never,embedded,第一次也可偷懒让框架去创建表
重启服务,可以看到持久化成功:
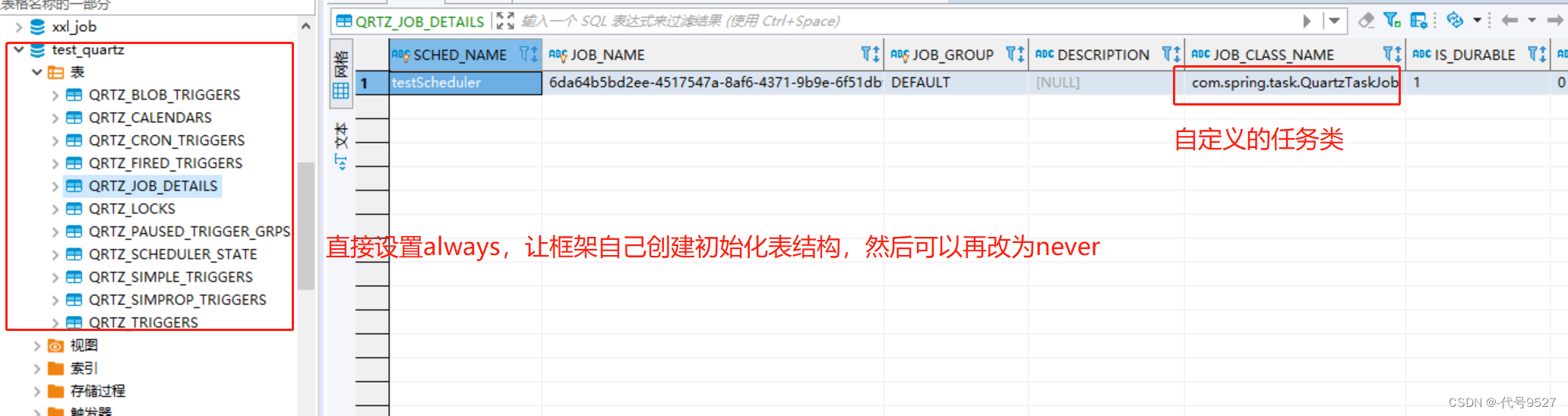
除了以上关键配置外,集群、线程池等Quartz Scheduler 附加属性相关配置可参考以下这个COPY的比较全的配置文件:
spring:
datasource:
druid:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test_quartz?serverTimezone=GMT%2B8
username: root
password: root123
quartz:
job-store-type: jdbc # 使用数据库存储
scheduler-name: hyhScheduler # 相同 Scheduler 名字的节点,形成一个 Quartz 集群
wait-for-jobs-to-complete-on-shutdown: true # 应用关闭时,是否等待定时任务执行完成。默认为 false ,建议设置为 true
jdbc:
initialize-schema: never # 是否自动使用 SQL 初始化 Quartz 表结构。这里设置成 never ,我们手动创建表结构。可以选择always,never,embedded,第一次也可偷懒让框架去创建表
properties:
org:
quartz:
# JobStore 相关配置
jobStore:
dataSource: quartzDataSource # 使用的数据源
class: org.quartz.impl.jdbcjobstore.JobStoreTX # JobStore 实现类
driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
tablePrefix: QRTZ_ # Quartz 表前缀
isClustered: true # 是集群模式
clusterCheckinInterval: 1000
useProperties: false
# 线程池相关配置
threadPool:
threadCount: 25 # 线程池大小。默认为 10 。
threadPriority: 5 # 线程优先级
class: org.quartz.simpl.SimpleThreadPool # 线程池类型
配置中有一个scheduler-name字段,看上面Quartz的库里的表,所有的表中都含有一个SCHED_NAME字段,对应配置的这个scheduler-name,相同 Scheduler-name的节点,形成一个 Quartz 集群。
![vs code 离线安装 CodeLLDB 包[Acquiring CodeLLDB platform package]](https://img-blog.csdnimg.cn/b8cc6341394c486c90f32511ab080d1d.png)


![[QT编程系列-45]: 内存检测工具Dr.Memory在Windows上的使用实践与详解](https://img-blog.csdnimg.cn/dc8d9e9d0a60462597d1ee673ab4aa7c.png)