【C语言】浅谈代码运行效率及内存优化
C语言作为一种高效率的编译语言 常用来写单片机等讲究时序性的设备
而只有代码优化得好 才能提高运行效率
当然这里的代码优化 并不是编译器优化 而是人为的代码习惯
文章目录
- 代码效率
- 条件判断
- if else语句 抛弃边缘状态
- 中断函数
- 串口解析中断
- 内存优化
- 数据定义
- 结构体
- 附录:压缩字符串、大小端格式转换
- 压缩字符串
- 浮点数
- 压缩Packed-ASCII字符串
- 大小端转换
- 什么是大端和小端
- 数据传输中的大小端
- 总结
- 大小端转换函数
代码效率
条件判断
对于多级判断的函数 其效率排名如下:
switch>while>if else
所以 如果条件允许 则尽量采用switch来进行判断(除非只有0 1两种选择 可以直接用if else)
另外 用于braek的判断条件尽量放在while中 而不是if break
if else语句 抛弃边缘状态
if else可以用来判断比较复杂的情况 但为了提高效率 可以抛弃边缘状态来去掉else
所谓边缘状态也就是不常发生的状态
比如:
代码if(y>4 || y==0)后没有else 而正常情况下运行的代码放在if之后
uint32_t I2C_Read_y(I2C_HandleTypeDef *hi2c,uint16_t DevAddress,uint16_t add,uint16_t add_length,uint8_t y,bool prologue_flag)
{
DevAddress=(DevAddress<<1)&0xFF;
uint8_t pData[y];
memset(pData,0,sizeof(pData));
uint32_t dat=0;
uint16_t MemAddSize=0;
if(y>4 || y==0)
{
return 0;
}
if(prologue_flag)
{
switch(add_length)
{
case 1:MemAddSize=I2C_MEMADD_SIZE_8BIT;break;
case 2:MemAddSize=I2C_MEMADD_SIZE_16BIT;break;
default:MemAddSize=I2C_MEMADD_SIZE_8BIT;break;
}
HAL_I2C_Mem_Read(hi2c,DevAddress,add,MemAddSize,pData,y,0xFFFF);
}
else
{
HAL_I2C_Master_Receive(hi2c,DevAddress,pData,y,0xFFFF);
}
for(uint8_t i=0;i<y;i++)
{
dat|=pData[i]<<(8*(y-1-i));
}
return dat;
}
同样的 多种状态判断时 也可以把比较容易发生的放在前面 则就不会一直判断else if
比如:
void HAL_TIM_PeriodElapsedCallback(TIM_HandleTypeDef *htim)
{
if (htim == &htim4)
{
HART_Timer_Flag++;
if(HART_Timer_Flag>=10)
{
HART_RxFlag=0;
HART_Timer_Flag=10;
HAL_TIM_Base_Stop_IT(&htim4);
}
}
else if (htim == &htim5)
{
GUI_Timer_Flag++;
if(GUI_Timer_Flag>=10)
{
GUI_RxFlag=0;
GUI_Status=0;
GUI_Timer_Flag=10;
HAL_TIM_Base_Stop_IT(&htim5);
}
}
else if (htim == &htim2)
{
}
else if (htim == &htim3)
{
TIM3_CH2_Overflow++;
}
}
中断函数
在中断函数中 不要调用任何阻塞、等待、延时、循环函数
中断函数的目的就是在完成某个任务时 触发中断 然后执行一部分代码后 跳出中断继续执行
所以需要尽可能的快
可以类比成一个线程 但运行此线程时 主线程会被打断
串口解析中断
在串口中断中 如果用了解析函数 则应采用状态机的方式进行 而真正的解析部分则放在主函数内完成
比如:
void HAL_UART_RxCpltCallback(UART_HandleTypeDef *huart)
{
if(huart==&huart2)
{
switch(GUI_Status)
{
case 0:
{
if(GUI_RxBit==GUI_START0)
{
GUI_Status=1;
}
GUI_RxFlag=0;
break;
}
case 1:
{
if(GUI_RxBit==GUI_START1 && GUI_RxFlag==1)
{
GUI_Status=2;
}
else
{
GUI_Status=0;
GUI_RxFlag=0;
}
break;
}
case 2:
{
if(GUI_RxFlag==3)
{
GUI_Data_Len=(GUI_RxBuffer[2]<<8)|GUI_RxBit;
GUI_Status=3;
if(!GUI_Data_Len)
{
GUI_Status=0;
GUI_RxFlag=0;
}
}
break;
}
case 3:
{
if(GUI_RxFlag==(GUI_Data_Len+9))
{
if(GUI_RxBit==GUI_STOP1 && GUI_RxBuffer[GUI_Data_Len+8]==GUI_STOP0)
{
GUI_Status=4;
}
else
{
GUI_Status=0;
GUI_RxFlag=0;
}
}
break;
}
default:break;
}
GUI_RxBuffer[GUI_RxFlag]=GUI_RxBit;
GUI_RxFlag++;
GUI_RxBit=0;
GUI_Timer_Flag=0;
HAL_TIM_Base_Start_IT(&htim5);
HAL_UART_Receive_IT(&huart2,&GUI_RxBit,1);
}
内存优化
数据定义
数据定义则是用多大空间的数据 就定义多大(当然 内存对齐的数据除外)
在C语言基本库#include <stdint.h>中 将各种定义重新命令 比较方便直接阅读变量大小
typedef signed char int8_t;
typedef signed short int int16_t;
typedef signed int int32_t;
typedef signed __INT64 int64_t;
/* exact-width unsigned integer types */
typedef unsigned char uint8_t;
typedef unsigned short int uint16_t;
typedef unsigned int uint32_t;
typedef unsigned __INT64 uint64_t;
/* 7.18.1.2 */
/* smallest type of at least n bits */
/* minimum-width signed integer types */
typedef signed char int_least8_t;
typedef signed short int int_least16_t;
typedef signed int int_least32_t;
typedef signed __INT64 int_least64_t;
/* minimum-width unsigned integer types */
typedef unsigned char uint_least8_t;
typedef unsigned short int uint_least16_t;
typedef unsigned int uint_least32_t;
typedef unsigned __INT64 uint_least64_t;
/* 7.18.1.3 */
/* fastest minimum-width signed integer types */
typedef signed int int_fast8_t;
typedef signed int int_fast16_t;
typedef signed int int_fast32_t;
typedef signed __INT64 int_fast64_t;
/* fastest minimum-width unsigned integer types */
typedef unsigned int uint_fast8_t;
typedef unsigned int uint_fast16_t;
typedef unsigned int uint_fast32_t;
typedef unsigned __INT64 uint_fast64_t;
结构体
在结构体定义时 通常会由于编译器优化 浪费掉一些空间
比如:
typedef struct
{
float Damping_Time; //阻尼时间
uint8_t Unit_Code; //主单位变量
float Range; //量程
float Blind; //盲区范围
float Fixed_Current_Mode; //固定电流模式
uint8_t HART_Mode; //HART模式(HART地址)
uint8_t Current_Mode[3]; //电流模式 GUI_Current_Mode 三个字节分别控制是否输出电流、4-20mA还是20-4mA、报警模式
}GUI_Unique_Value_Struct;
该结构体中 有float类型 也有uint8类型 如果你打印过每个变量的地址 不难发现 Damping_Time为地址0 Unit_Code为地址4 Range为地址8
这是由于编译器优化后 将每个变量尽量按相同的间距排列 但这样无疑会浪费空间
所以:
采用#pragma pack(1)语句告诉编译器这里要按1B对齐(就是两个变量之间的间隔最小为1) 可以减少空间浪费
#pragma pack(1)
typedef struct
{
float Damping_Time; //阻尼时间
uint8_t Unit_Code; //主单位变量
float Range; //量程
float Blind; //盲区范围
float Fixed_Current_Mode; //固定电流模式
uint8_t HART_Mode; //HART模式(HART地址)
uint8_t Current_Mode[3]; //电流模式 GUI_Current_Mode 三个字节分别控制是否输出电流、4-20mA还是20-4mA、报警模式
}GUI_Unique_Value_Struct;
#pragma pack()
最后在结尾也要加上#pragma pack() 告诉编译器这里取消了对齐
如果用memcpy等函数 则一定要对齐以后才能复制 不然可能会出现数据错误的问题
附录:压缩字符串、大小端格式转换
压缩字符串
首先HART数据格式如下:


重点就是浮点数和字符串类型
Latin-1就不说了 基本用不到
浮点数
浮点数里面 如 0x40 80 00 00表示4.0f
在HART协议里面 浮点数是按大端格式发送的 就是高位先发送 低位后发送
发送出来的数组为:40,80,00,00
但在C语言对浮点数的存储中 是按小端格式来存储的 也就是40在高位 00在低位
浮点数:4.0f
地址0x1000对应00
地址0x1001对应00
地址0x1002对应80
地址0x1003对应40
若直接使用memcpy函数 则需要进行大小端转换 否则会存储为:
地址0x1000对应40
地址0x1001对应80
地址0x1002对应00
地址0x1003对应00
大小端转换:
void swap32(void * p)
{
uint32_t *ptr=p;
uint32_t x = *ptr;
x = (x << 16) | (x >> 16);
x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);
*ptr=x;
}
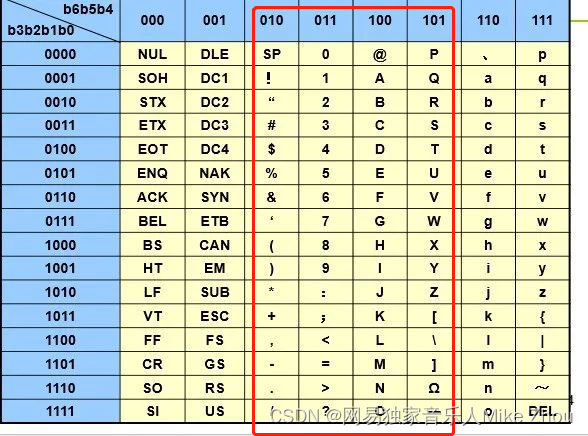
压缩Packed-ASCII字符串
本质上是将原本的ASCII的最高2位去掉 然后拼接起来 比如空格(0x20)
四个空格拼接后就成了
1000 0010 0000 1000 0010 0000
十六进制:82 08 20
对了一下表 0x20之前的识别不了
也就是只能识别0x20-0x5F的ASCII表
压缩/解压函数后面再写:
//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_ASCII_to_Pack(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{
if(str_len%4)
{
return 0;
}
uint8_t i=0;
memset(buf,0,str_len/4*3);
for(i=0;i<str_len;i++)
{
if(str[i]==0x00)
{
str[i]=0x20;
}
}
for(i=0;i<str_len/4;i++)
{
buf[3*i]=(str[4*i]<<2)|((str[4*i+1]>>4)&0x03);
buf[3*i+1]=(str[4*i+1]<<4)|((str[4*i+2]>>2)&0x0F);
buf[3*i+2]=(str[4*i+2]<<6)|(str[4*i+3]&0x3F);
}
return 1;
}
//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_Pack_to_ASCII(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{
if(str_len%4)
{
return 0;
}
uint8_t i=0;
memset(str,0,str_len);
for(i=0;i<str_len/4;i++)
{
str[4*i]=(buf[3*i]>>2)&0x3F;
str[4*i+1]=((buf[3*i]<<4)&0x30)|(buf[3*i+1]>>4);
str[4*i+2]=((buf[3*i+1]<<2)&0x3C)|(buf[3*i+2]>>6);
str[4*i+3]=buf[3*i+2]&0x3F;
}
return 1;
}
大小端转换
在串口等数据解析中 难免遇到大小端格式问题
什么是大端和小端
所谓的大端模式,就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
所谓的小端模式,就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
简单来说:大端——高尾端,小端——低尾端
举个例子,比如数字 0x12 34 56 78在内存中的表示形式为:
1)大端模式:
低地址 -----------------> 高地址
0x12 | 0x34 | 0x56 | 0x78
2)小端模式:
低地址 ------------------> 高地址
0x78 | 0x56 | 0x34 | 0x12
可见,大端模式和字符串的存储模式类似。
数据传输中的大小端
比如地址位、起止位一般都是大端格式
如:
起始位:0x520A
则发送的buf应为{0x52,0x0A}
而数据位一般是小端格式(单字节无大小端之分)
如:
一个16位的数据发送出来为{0x52,0x0A}
则对应的uint16_t类型数为: 0x0A52
而对于浮点数4.0f 转为32位应是:
40 80 00 00
以大端存储来说 发送出来的buf就是依次发送 40 80 00 00
以小端存储来说 则发送 00 00 80 40
由于memcpy等函数 是按字节地址进行复制 其复制的格式为小端格式 所以当数据为小端存储时 不用进行大小端转换
如:
uint32_t dat=0;
uint8_t buf[]={0x00,0x00,0x80,0x40};
memcpy(&dat,buf,4);
float f=0.0f;
f=*((float*)&dat); //地址强转
printf("%f",f);
或更优解:
uint8_t buf[]={0x00,0x00,0x80,0x40};
float f=0.0f;
memcpy(&f,buf,4);
而对于大端存储的数据(如HART协议数据 全为大端格式) 其复制的格式仍然为小端格式 所以当数据为小端存储时 要进行大小端转换
如:
uint32_t dat=0;
uint8_t buf[]={0x40,0x80,0x00,0x00};
memcpy(&dat,buf,4);
float f=0.0f;
swap32(&dat); //大小端转换
f=*((float*)&dat); //地址强转
printf("%f",f);
或:
uint8_t buf[]={0x40,0x80,0x00,0x00};
memcpy(&dat,buf,4);
float f=0.0f;
swap32(&f); //大小端转换
printf("%f",f);
或更优解:
uint32_t dat=0;
uint8_t buf[]={0x40,0x80,0x00,0x00};
float f=0.0f;
dat=(buf[0]<<24)|(buf[0]<<16)|(buf[0]<<8)|(buf[0]<<0)
f=*((float*)&dat);
总结
固 若数据为小端格式 则可以直接用memcpy函数进行转换 否则通过移位的方式再进行地址强转
对于多位数据 比如同时传两个浮点数 则可以定义结构体之后进行memcpy复制(数据为小端格式)
对于小端数据 直接用memcpy写入即可 若是浮点数 也不用再进行强转
对于大端数据 如果不嫌麻烦 或想使代码更加简洁(但执行效率会降低) 也可以先用memcpy写入结构体之后再调用大小端转换函数 但这里需要注意的是 结构体必须全为无符号整型 浮点型只能在大小端转换写入之后再次强转 若结构体内采用浮点型 则需要强转两次
所以对于大端数据 推荐通过移位的方式来进行赋值 然后再进行个别数的强转 再往通用结构体进行写入
多个不同变量大小的结构体 要主要字节对齐的问题
可以用#pragma pack(1) 使其对齐为1
但会影响效率
大小端转换函数
直接通过对地址的操作来实现 传入的变量为32位的变量
中间变量ptr是传入变量的地址
void swap16(void * p)
{
uint16_t *ptr=p;
uint16_t x = *ptr;
x = (x << 8) | (x >> 8);
*ptr=x;
}
void swap32(void * p)
{
uint32_t *ptr=p;
uint32_t x = *ptr;
x = (x << 16) | (x >> 16);
x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);
*ptr=x;
}
void swap64(void * p)
{
uint64_t *ptr=p;
uint64_t x = *ptr;
x = (x << 32) | (x >> 32);
x = ((x & 0x0000FFFF0000FFFF) << 16) | ((x >> 16) & 0x0000FFFF0000FFFF);
x = ((x & 0x00FF00FF00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF00FF00FF);
*ptr=x;
}

![哈希/散列--哈希表[思想到结构]](https://img-blog.csdnimg.cn/4417c76f041e4fc2b7b10a2c25917b0e.png)