目录
一,冯诺依曼体系结构
1.是什么?特点
2.为什么?
二,操作系统
三,进程
1.什么是进程?
2.查看进程
3.进程的管理
4.fork()创建子进程
1.fork()简介
2.fork()干了啥
3.fork()为什么会有两个返回值?
4.子进程与父进程谁先运行?
5.一个变量里有两个值
一,冯诺依曼体系结构
1.是什么?特点
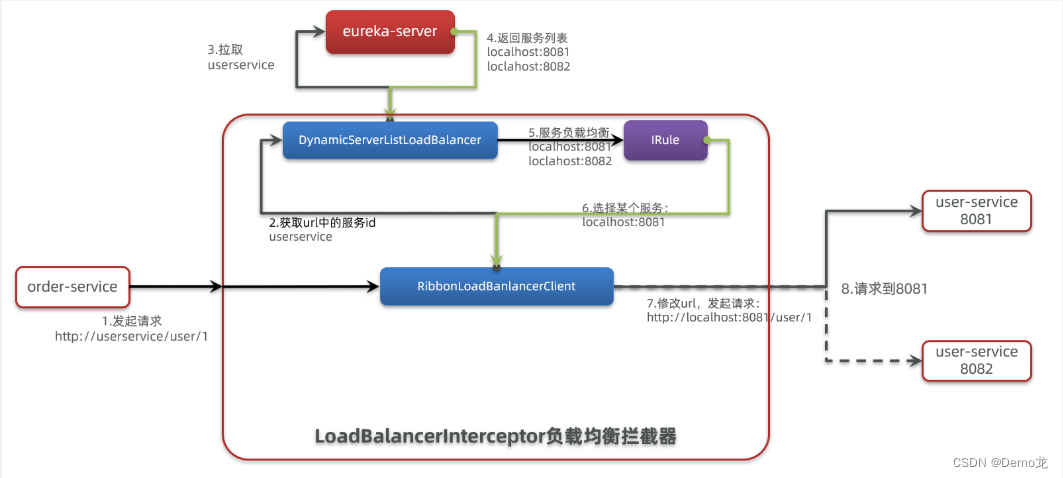
先来看看一张图,看看什么叫做冯诺依曼体系结构:
这张图便是冯诺依曼体系结构的图。中央处理器便是我们的Cpu。通过这张图我们能看到的便是Cpu只和存储器相连,这个存储器便是内存。然后内存再和输入输出设备相连。于是我们可以得到一个结论:Cpu只和内存相连不和外设相连,内存和外设相连。

2.为什么?
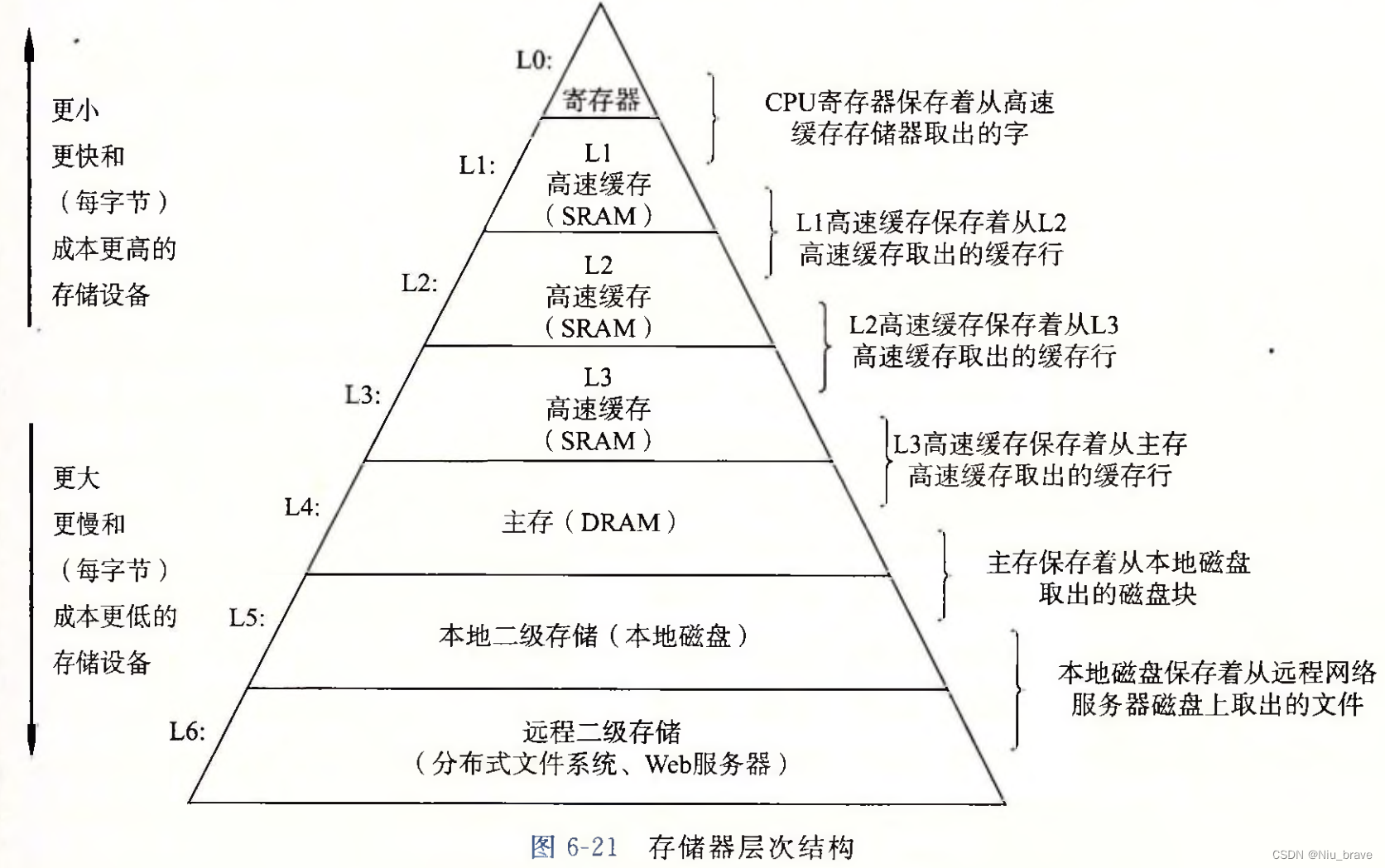
我们的计算机大多数都是遵循冯诺依曼体系结构设计的。但这是为什么呢?原因其实就是性价比高。这样做能够然更多人买得起一台好用且不贵的计算机。为什么呢?因为在计算机中有一个金字塔:
在这个金字塔里,越是金字塔上面的运行速度就越快但是也越贵。越是下面的就越慢但是越便宜。为了造出又快又便宜的计算机,于是便有了冯诺依曼体系结构的出现。冯诺依曼体系结构的Cpu只和内存相连,内存和外设相连。于是便可以通过先将外设里的数据先搬到内存中存储然后再搬到cpu中处理。这样便可以在保证造价较低的情况下保证计算机的运行速度。
二,操作系统
在计算机中有大量的资源需要被管理,于是我们便要有一款可以管理资源的软件。这个软件就被叫做操作系统。在计算机中有一个层状结构如下:
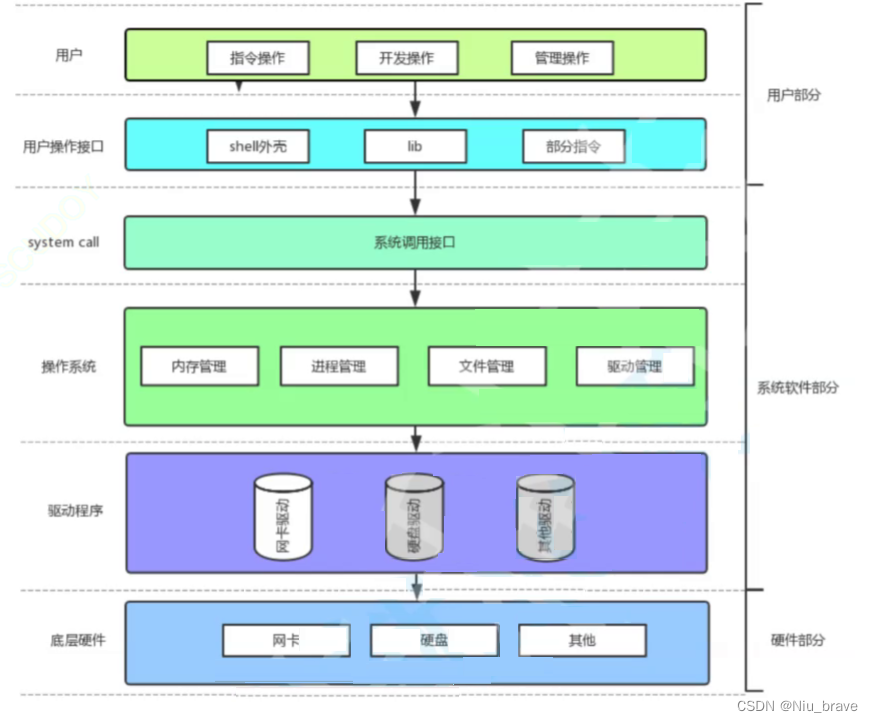
这个层状结构从上到下分别是:用户-》用户接口-》系统调用接口-》操作系统-》驱动程序-》底层硬件。
可以看到操作系统便在这个层状结构的中间位置。所以计算机在运行时传输数据的时候必定要经过操作系统。操作系统管理的只是一些数据,而不是具体的硬件。Linux操作系统其实有狭义和广义之分,狭义的操作系统便是Linux内核。广义的操作系统便是Linux内核+系统调用接口+lib库。如下图:
狭义:
广义:


三,进程
1.什么是进程?
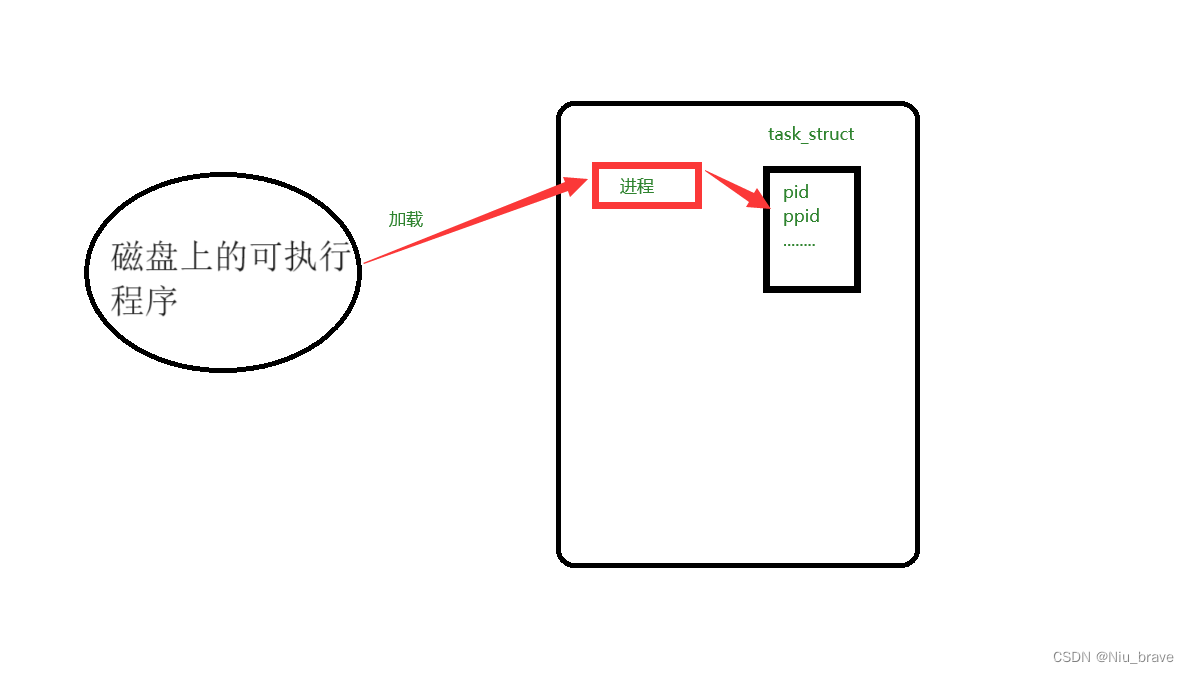
进程其实就是加载到内存中的可执行程序。所以进程与程序就有以下区别:
1.位置:进程在内存中,程序在磁盘里。
2.状态:程序的状态是静态的,进程的状态是动态的。
2.查看进程
在Linux下可以通过命令(ps ajx | grep 可执行程序名)来查看进程。
比如我有以下可执行程序:
可执行程序是Mycode.
然后通过这个窗口:在
再来打开一个窗口输入查看进程的指令便可以查看可执行程序的进程:
但是这些数字是啥子意思呢?鬼知道啊?于是我们再来一条指令(ps ajx | head -1&& ps ajx | grep 可执行程序)来查看更加详细的信息:
通过这条指令便可以看到在这些数字上面多了一些叫做PPID和PID的东西,这是啥啊?
不知道!!!
现在我们再来学一条指令能让我们看到动态的进程信息,指令如下:
while:;do ps ajx | head -1&& ps ajx | grep 可执行程序;sleep 1;echo "###########";done;
然后我们便可以看到滚动起来的进程信息了:




3.进程的管理
我们该如何管理一个事物呢?联想到生活中其实我们是通过管理事物的属性来管理事务的,比如管理一个人的时候便要知道这个人的姓名,性别,电话等等。而我们在管理进程的时候也是这样子管理的,这套管理的方法也被称为先描述后组织。
在操作系统中有一个叫做PCB的东西,全称叫做process control block(进程控制块)。在Linux中这个东西就叫做:task_struck()。在这个结构体里面便管理着PID,PPID等进程属性。PID和PPID的意思就是子ID和父ID可以通过getpid()和getppid()两个函数来的到PID和PPID。
所以说到这里的话那就可以再来丰富一下生成进程的过程:
然后如果有多个进程的话便会生成多个PCB。这些PCB形成一个双向循环链表。于是这个列表就会存储着所有进程的信息,操作系统通过控制这个链表便可以控制所有的进程。
4.fork()创建子进程
1.fork()简介
fork()其实是一个系统调用接口。它的作用便是创建子进程。现在可以来对这个接口来使用一番。写下以下程序:
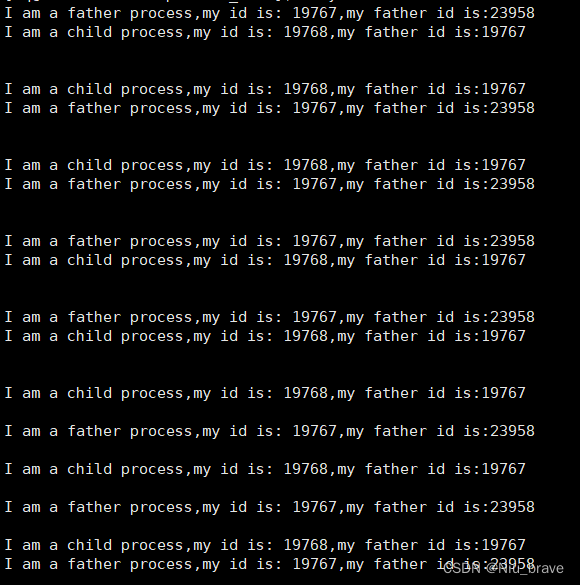
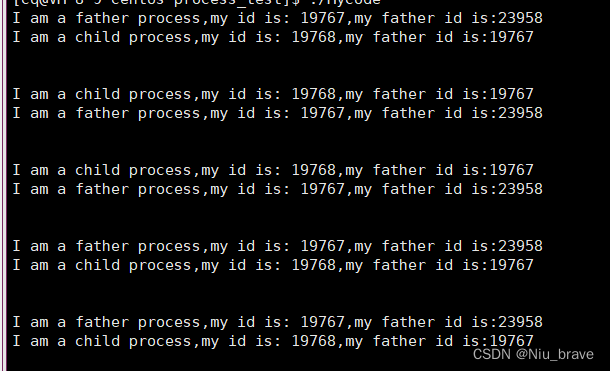
#include<stdio.h> 2 #include<unistd.h> 3 #include<sys/types.h> 4 int main() 5 { 6 pid_t id = fork();//接收fork()的返回值 7 if(id<0) return 1; 8 else if(id == 0)//因为给子进程返回0 9 { 10 while(1) 11 { 12 sleep(1); 13 printf("I am a child process,my id is: %d,my father id is:%d\n",getpid(),getppid( )); 14 printf("\n"); 15 } 16 } 17 18 else//因为给父进程返回子进程的pid() 19 { 20 while(1) 21 { 22 sleep(1); 23 printf("I am a father process,my id is: %d,my father id is:%d\n",getpid(),getppid( )); 24 printf("\n"); 25 26 } 27 } 28 29 30 return 0; 31 32 }然后将这段代码运行起来会是下面的样子:
可以发现这里会有同时执行父子进程的情况:
能同时执行两个不同的if else语句那就说明id接收了两个返回值。fork()能同时返回两个值。
2.fork()干了啥
我们通过上面的学习可以知道,fork()可以创建一个子进程。但是是如何创建子进程的呢?首先要明确的一点便是:fork()是一个系统级别的接口,fork()只能在内存中创建子进程。所以子进程是没有可执行程序的,所以创建子进程其实就是创建一个PCB。这个PCB里面的属性大多数都是继承于父进程的。
3.fork()为什么会有两个返回值?
这是因为fork()在创建完一个子进程以后,在系统中就有两个进程了。fork()在返回的时候会将两个返回值分别放在两个不同的寄存器里面。当返回结束时,父子进程各自会读取各自的返回值。于是就得到了两个不同的返回值。
4.子进程与父进程谁先运行?
在一般条件下我们是无法预测的。这两个进程谁先运行完全由操作系统说了算。操作系统调度谁,谁就先执行。
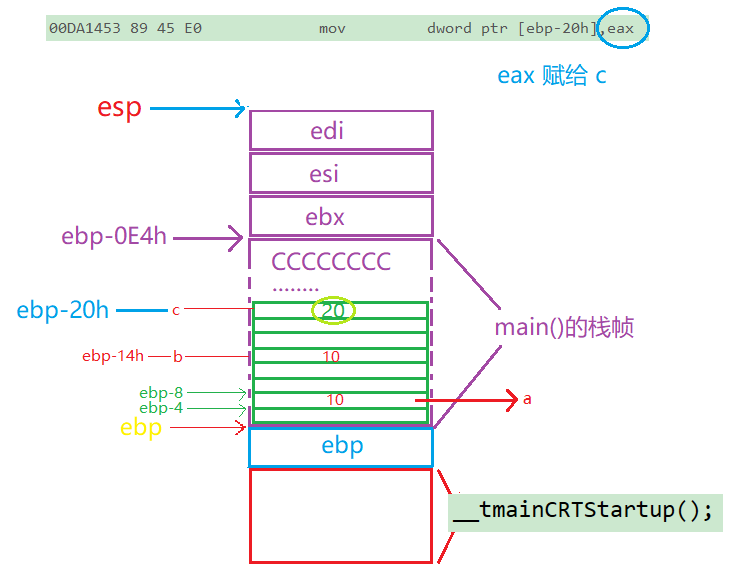
5.一个变量里有两个值
为什么一个变量id里面却有两个值呢?这是因为id在接收返回值的时候使用了一个叫做写时拷贝的技术实现了。fork()返回一次id就接收一次,id接收完了以后便执行下面的代码。然后fork()再返回一个值id再写入一次,id接收完了以后再执行下面的代码。