嵌入式Linux应用开发-基础知识-第十九章驱动程序基石④
- 第十九章 驱动程序基石④
- 19.7 工作队列
- 19.7.1 内核函数
- 19.7.1.1 定义 work
- 19.7.1.2 使用 work:schedule_work
- 19.7.1.3 其他函数
- 19.7.2 编程、上机
- 19.7.3 内部机制
- 19.7.3.1 Linux 2.x的工作队列创建过程
- 19.7.3.2
- 19.8 中断的线程化处理
- 19.8.1 内核机制
- 19.8.1.1 调用 request_threaded_irq后内核的数据结构
- 19.8.1.2
- 19.8.1.3 中断的执行过程
- 19.8.2 编程、上机
第十九章 驱动程序基石④

19.7 工作队列
使用 GIT命令载后,本节源码位于这个目录下:
01_all_series_quickstart\
05_嵌入式 Linux驱动开发基础知识\source\
06_gpio_irq\
09_read_key_irq_poll_fasync_block_timer_tasklet_workqueue
前面讲的定时器、下半部 tasklet,它们都是在中断上下文中执行,它们无法休眠。当要处理更复杂的事情时,往往更耗时。这些更耗时的工作放在定时器或是下半部中,会使得系统很卡;并且循环等待某件事情完成也太浪费 CPU资源了。
如果使用线程来处理这些耗时的工作,那就可以解决系统卡顿的问题:因为线程可以休眠。
在内核中,我们并不需要自己去创建线程,可以使用“工作队列”(workqueue)。内核初始化工作队列是,就为它创建了内核线程。以后我们要使用“工作队列”,只需要把“工作”放入“工作队列中”,对应的内核线程就会取出“工作”,执行里面的函数。
在 2.xx的内核中,工作队列的内部机制比较简单;在现在 4.x的内核中,工作队列的内部机制做得复杂无比,但是用法是一样的。
工作队列的应用场合:要做的事情比较耗时,甚至可能需要休眠,那么可以使用工作队列。
缺点:多个工作(函数)是在某个内核线程中依序执行的,前面函数执行很慢,就会影响到后面的函数。 在多 CPU的系统下,一个工作队列可以有多个内核线程,可以在一定程度上缓解这个问题。
我们先使用看看怎么使用工作队列。
19.7.1 内核函数
内核线程、工作队列(workqueue)都由内核创建了,我们只是使用。使用的核心是一个 work_struct结构体,定义如下:

使用工作队列时,步骤如下:
① 构造一个 work_struct结构体,里面有函数;
② 把这个 work_struct结构体放入工作队列,内核线程就会运行 work中的函数。
19.7.1.1 定义 work
参考内核头文件:include\linux\workqueue.h
#define DECLARE_WORK(n, f) \
struct work_struct n = __WORK_INITIALIZER(n, f)
#define DECLARE_DELAYED_WORK(n, f)
\
struct delayed_work n = __DELAYED_WORK_INITIALIZER(n, f, 0)
第 1个宏是用来定义一个 work_struct结构体,要指定它的函数。
第 2个宏用来定义一个 delayed_work结构体,也要指定它的函数。所以“delayed”,意思就是说要让它运行时,可以指定:某段时间之后你再执行。
如果要在代码中初始化 work_struct结构体,可以使用下面的宏:
#define INIT_WORK(_work, _func)
19.7.1.2 使用 work:schedule_work
调用 schedule_work时,就会把 work_struct结构体放入队列中,并唤醒对应的内核线程。内核线程就会从队列里把 work_struct结构体取出来,执行里面的函数。
19.7.1.3 其他函数
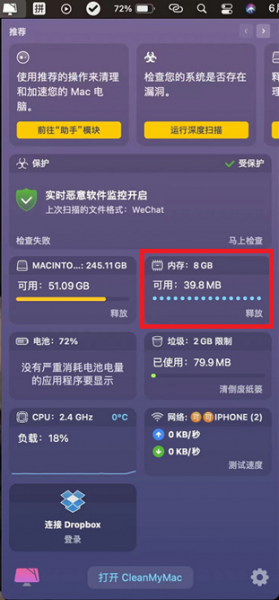
19.7.2 编程、上机
19.7.3 内部机制
初学者知道 work_struct中的函数是运行于内核线程的上下文,这就足够了。
在 2.xx版本的 Linux内核中,创建 workqueue时就会同时创建内核线程;
在 4.xx版本的 Linux内核中,内核线程和 workqueue是分开创建的,比较复杂。
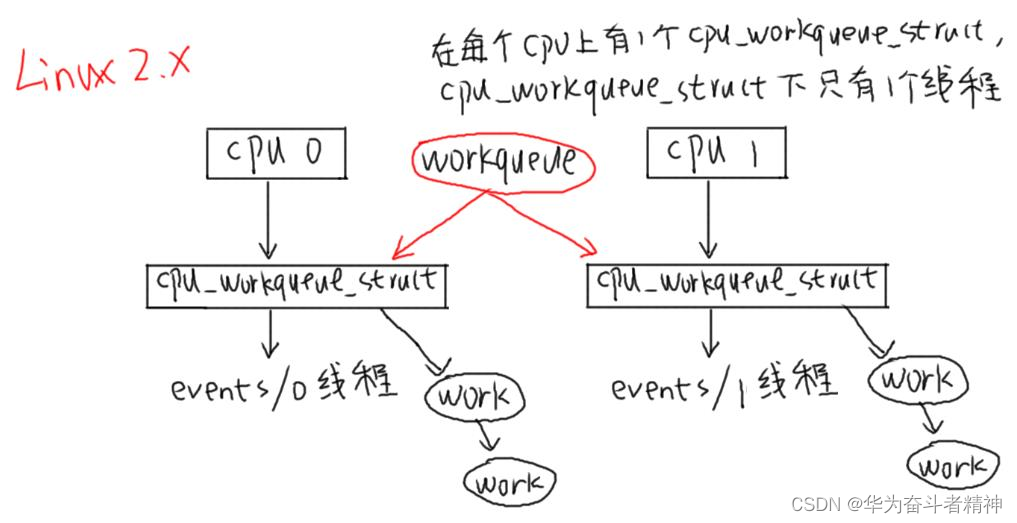
19.7.3.1 Linux 2.x的工作队列创建过程
代码在 kernel\workqueue.c中:
init_workqueues
keventd_wq = create_workqueue("events");
__create_workqueue((name), 0, 0)
for_each_possible_cpu(cpu) {
err = create_workqueue_thread(cwq, cpu);
p = kthread_create(worker_thread, cwq, fmt, wq->name, cpu);
对于每一个 CPU,都创建一个名为“events/X”的内核线程,X从 0开始。
在创建 workqueue的同时创建内核线程。
19.7.3.2
Linux 4.x的工作队列创建过程
Linux4.x中,内核线程和工作队列是分开创建的。
先创建内核线程,代码在 kernel\workqueue.c中: init_workqueues
/* initialize CPU pools */
for_each_possible_cpu(cpu) {
for_each_cpu_worker_pool(pool, cpu) {
/* 对每一个 CPU都创建 2个 worker_pool结构体,它是含有 ID的 */
/* 一个 worker_pool对应普通优先级的 work,第 2个对应高优先级的 work */ }
/* create the initial worker */
for_each_online_cpu(cpu) {
for_each_cpu_worker_pool(pool, cpu) {
/* 对每一个 CPU的每一个 worker_pool,创建一个 worker */
/* 每一个 worker对应一个内核线程 */
BUG_ON(!create_worker(pool)); }
}
create_worker函数代码如下:

创建好内核线程后,再创建 workqueue,代码在 kernel\workqueue.c中:
init_workqueues
system_wq = alloc_workqueue("events", 0, 0);
__alloc_workqueue_key
wq = kzalloc(sizeof(*wq) + tbl_size, GFP_KERNEL); // 分配 workqueue_struct alloc_and_link_pwqs(wq) // 跟 worker_poll建立联系
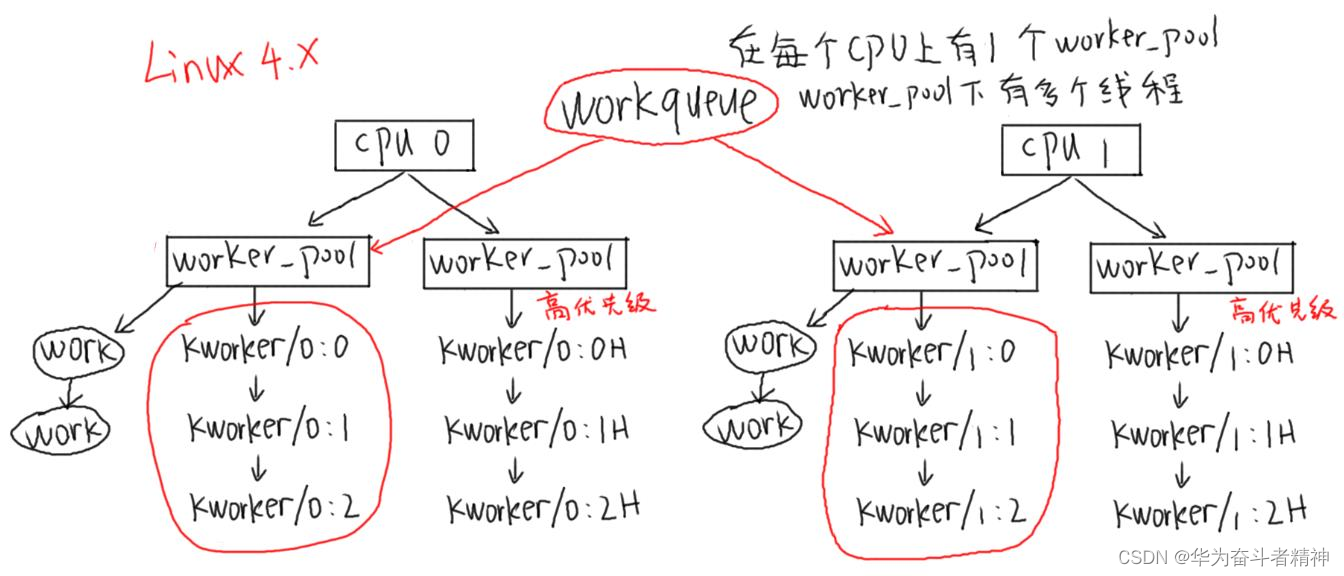
一开始时,每一个 worker_poll下只有一个线程,但是系统会根据任务繁重程度动态创建、销毁内核线程。所以你可以在 work中打印线程 ID,发现它可能是变化的。
19.8 中断的线程化处理
使用 GIT命令载后,本节源码位于这个目录下:
01_all_series_quickstart\
05_嵌入式 Linux驱动开发基础知识\source\
06_gpio_irq\
10_read_key_irq_poll_fasync_block_timer_tasklet_workqueue_threadedirq
请先回顾《18.2.7 新技术:threaded irq》。
复杂、耗时的事情,尽量使用内核线程来处理。上节视频介绍的工作队列用起来挺简单,但是它有一个缺点:工作队列中有多个 work,前一个 work没处理完会影响后面的 work。解决方法有很多种,比如干脆自己创建一个内核线程,不跟别的 work凑在一块了。在 Linux系统中,对于存储设备比如 SD/TF卡,它的驱动程序就是这样做的,它有自己的内核线程。
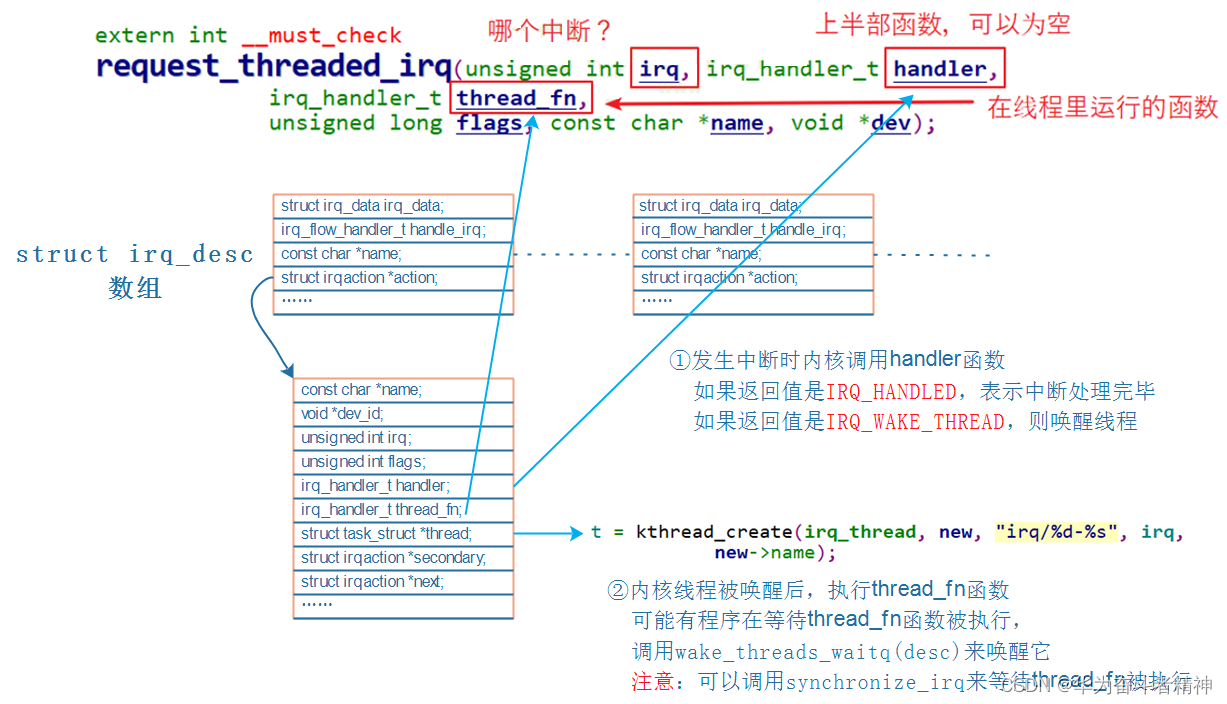
对于中断处理,还有另一种方法:threaded irq,线程化的中断处理。中断的处理仍然可以认为分为上半部、下半部。上半部用来处理紧急的事情,下半部用一个内核线程来处理,这个内核线程专用于这个中断。 内核提供了这个函数:

你可以只提供 thread_fn,系统会为这个函数创建一个内核线程。发生中断时,系统会立刻调用 handler函数,然后唤醒某个内核线程,内核线程再来执行 thread_fn函数。
19.8.1 内核机制
19.8.1.1 调用 request_threaded_irq后内核的数据结构
19.8.1.2
request_threaded_irq
request_threaded_irq函数,肯定会创建一个内核线程。
源码在内核文件 kernel\irq\manage.c中,
int request_threaded_irq(unsigned int irq, irq_handler_t handler, irq_handler_t thread_fn, unsigned long irqflags,
const char *devname, void *dev_id)
{
// 分配、设置一个 irqaction结构体
action = kzalloc(sizeof(struct irqaction), GFP_KERNEL);
if (!action)
return -ENOMEM;
action->handler = handler;
action->thread_fn = thread_fn; action->flags = irqflags;
action->name = devname;
action->dev_id = dev_id;
retval = __setup_irq(irq, desc, action); // 进一步处理 }
__setup_irq函数代码如下(只摘取重要部分):
if (new->thread_fn && !nested) {
ret = setup_irq_thread(new, irq, false);
setup_irq_thread函数代码如下(只摘取重要部分):
if (!secondary) {
t = kthread_create(irq_thread, new, "irq/%d-%s", irq,
new->name);
} else {
t = kthread_create(irq_thread, new, "irq/%d-s-%s", irq, new->name);
param.sched_priority -= 1;
}
new->thread = t;
19.8.1.3 中断的执行过程
对于 GPIO中断,我使用 QEMU的调试功能找出了所涉及的函数调用,其他板子可能稍有不同。 调用关系如下,反过来看:
Breakpoint 1, gpio_keys_gpio_isr (irq=200, dev_id=0x863e6930) at drivers/input/keyboard/gpio_keys.c:393
393 {
(gdb) bt
#0 gpio_keys_gpio_isr (irq=200, dev_id=0x863e6930) at drivers/input/keyboard/gpio_keys.c:393 #1 0x80270528 in __handle_irq_event_percpu (desc=0x8616e300, flags=0x86517edc) at kernel/irq/handle.c:145
#2 0x802705cc in handle_irq_event_percpu (desc=0x8616e300) at kernel/irq/handle.c:185
#3 0x80270640 in handle_irq_event (desc=0x8616e300) at kernel/irq/handle.c:202
#4 0x802738e8 in handle_level_irq (desc=0x8616e300) at kernel/irq/chip.c:518
#5 0x8026f7f8 in generic_handle_irq_desc (desc=<optimized out>) at ./include/linux/irqdesc.h:150
#6 generic_handle_irq (irq=<optimized out>) at kernel/irq/irqdesc.c:590
#7 0x805005e0 in mxc_gpio_irq_handler (port=0xc8, irq_stat=2252237104) at drivers/gpio/gpio-mxc.c:274
#8 0x805006fc in mx3_gpio_irq_handler (desc=<optimized out>) at drivers/gpio/gpio-mxc.c:291 #9 0x8026f7f8 in generic_handle_irq_desc (desc=<optimized out>) at ./include/linux/irqdesc.h:150
#10 generic_handle_irq (irq=<optimized out>) at kernel/irq/irqdesc.c:590
#11 0x8026fd0c in __handle_domain_irq (domain=0x86006000, hwirq=32, lookup=true, regs=0x86517fb0) at kernel/irq/irqdesc.c:627
#12 0x80201484 in handle_domain_irq (regs=<optimized out>, hwirq=<optimized out>, domain=<optimized out>) at ./include/linux/irqdesc.h:168
#13 gic_handle_irq (regs=0xc8) at drivers/irqchip/irq-gic.c:364
#14 0x8020b704 in __irq_usr () at arch/arm/kernel/entry-armv.S:464
我们只需要分析__handle_irq_event_percpu函数,它在 kernel\irq\handle.c中:
线程的处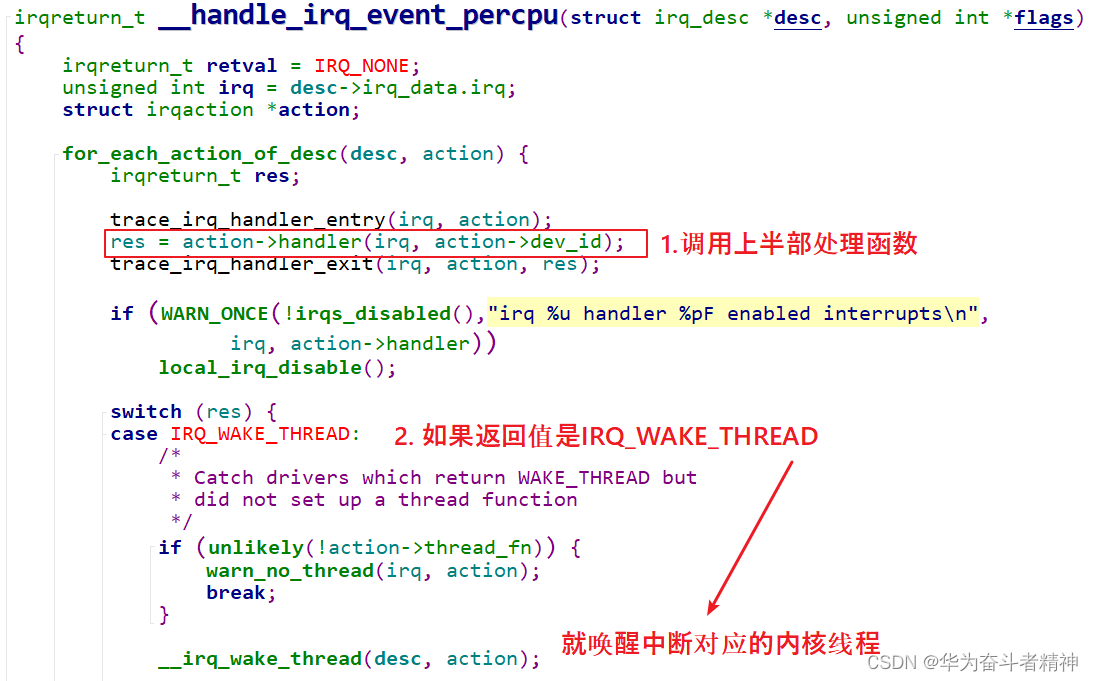
理函数为 irq_thread,代码在 kernel\irq\handle.c中:

19.8.2 编程、上机
调用request_threaded_irq函数注册中断,调用free_irq卸载中断。
从前面可知,我们可以提供上半部函数,也可以不提供:
① 如果不提供
内核会提供默认的上半部处理函数:irq_default_primary_handler,它是直接返回 IRQ_WAKE_THREAD。 ② 如果提供的话
返回值必须是:IRQ_WAKE_THREAD。
在 thread_fn中,如果中断被正确处理了,应该返回 IRQ_HANDLED。