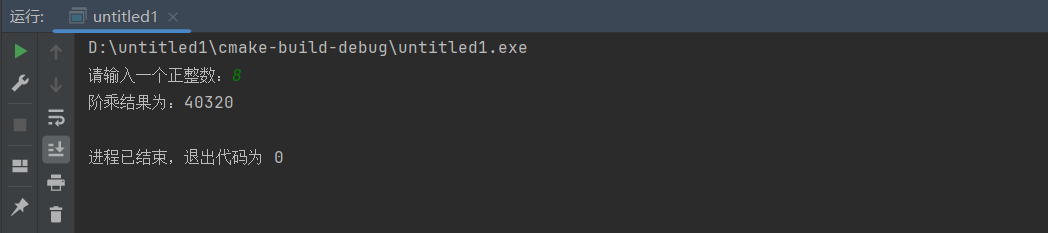
目录
eBPF 是什么
掌握 eBPF 是不是得先成为内核开发者?
eBPF 的发展历程是什么样的?
eBPF 是怎么工作的?
eBPF 是万能的吗?
小结
eBPF 是什么
eBPF 是什么呢? 从它的全称“扩展的伯克利数据包过滤器 (Extended Berkeley Packet Filter)” 来看,它是一种数据包过滤技术,是从 BPF (Berkeley Packet Filter) 技术扩展而来的。
BPF 提供了一种在内核事件和用户程序事件发生时安全注入代码的机制,这就让非内核开发人员也可以对内核进行控制。随着内核的发展,BPF 逐步从最初的数据包过滤扩展到了网络、内核、安全、跟踪等,而且它的功能特性还在快速发展中,这种扩展后的 BPF 被简称为 eBPF(相应的,早期的 BPF 被称为经典 BPF,简称 cBPF)。实际上,现代内核所运行的都是 eBPF,如果没有特殊说明,内核和开源社区中提到的 BPF 等同于 eBPF。
我想你已经知道,在 eBPF 之前,内核模块是注入内核的最主要机制。由于缺乏对内核模块的安全控制,内核的基本功能很容易被一个有缺陷的内核模块破坏。而 eBPF 则借助即时编译(JIT),在内核中运行了一个虚拟机,保证只有被验证安全的 eBPF 指令才会被内核执行。同时,因为 eBPF 指令依然运行在内核中,无需向用户态复制数据,这就大大提高了事件处理的效率。
正是由于这些突出的特性,eBPF 现如今已经在故障诊断、网络优化、安全控制、性能监控等领域获得大量应用。比如,Facebook 开源的高性能网络负载均衡器 Katran、Isovalent 开源的容器网络方案 Cilium ,以及著名的内核跟踪排错工具 BCC 和 bpftrace 等,都是基于 eBPF 技术实现的。
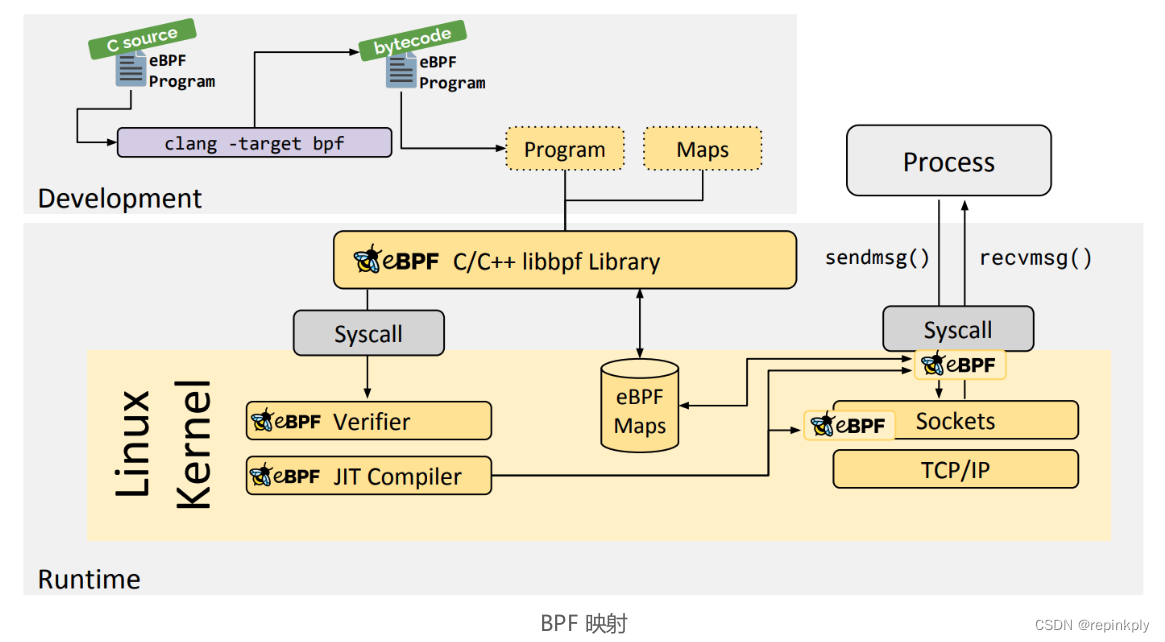
下图(来自 ebpf.io)是对 eBPF 技术及其应用的一个概览:
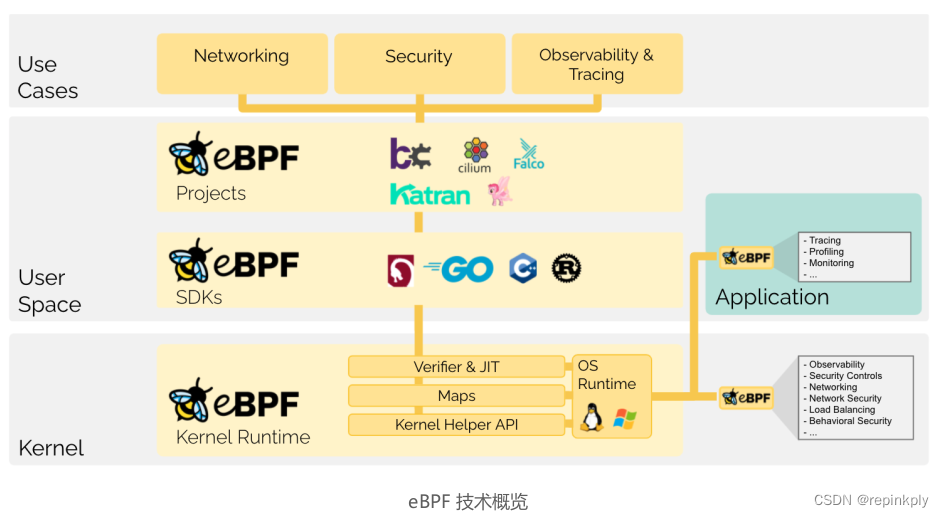
可以说,如果你想洞悉内核的运行状态,优化内核网络性能,控制诸如容器等应用程序的安全,那么 eBPF 就是一个你必须要掌握的技能。
掌握 eBPF 是不是得先成为内核开发者?
实际上,前面我提到的 BCC、bpftrace 等一系列的开源项目已经提供了大量工具,可以帮你解决像故障诊断、性能监控、安全控制等绝大部分场景中的问题。而在你需要开发新的eBPF 程序时,内核社区提供的 libbpf 库不仅帮你避免了直接调用内核函数,而且还提供了跨内核版本的兼容性(即一次编译到处执行,简称 CO-RE)。
所以,掌握 eBPF 并不需要掌握内核开发。我认为,学习最快的方法就是理解原理的同时配合大量的实践,eBPF 也不例外。下面这三点是学习 eBPF 的重中之重:
eBPF 的发展历程是什么样的?
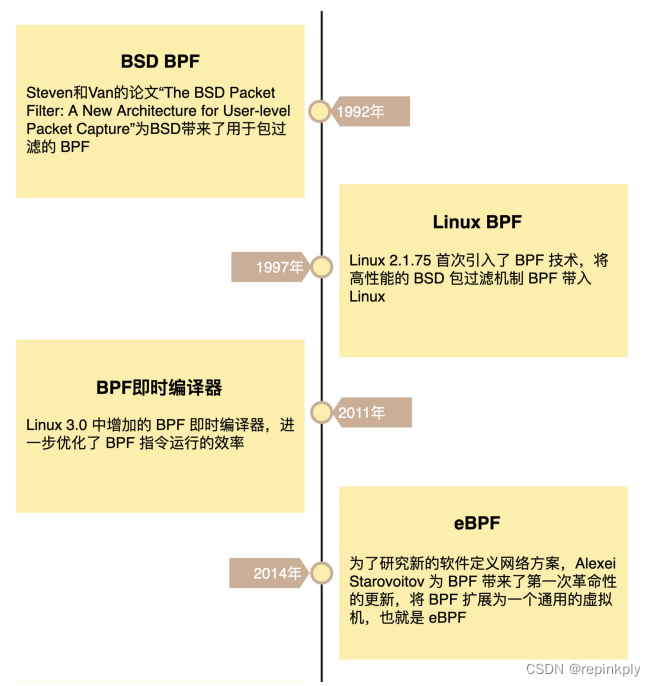
eBPF 是从 BPF (Berkeley Packet Filter) 技术扩展而来的。而说起 BPF,它的历史就更悠长了。
早在 1992 年的 USENIX 会议上,Steven McCanne 和 Van Jacobson 发布的论文“ The BSD Packet Filter: A New Architecture for User-level Packet Capture” 就为 BSD 操作系统带来了革命性的包过滤机制 BSD Packet Filter(简称为 BPF),这比当时最先进的数据包过滤技术还快 20 倍。为什么性能这么好呢?这主要得益于 BPF 的两大设计:
第一,内核态引入一个新的虚拟机,所有指令都在内核虚拟机中运行。
第二,用户态使用 BPF 字节码来定义过滤表达式,然后传递给内核,由内核虚拟机解释执行。
这就使得包过滤可以直接在内核中执行,避免了向用户态复制每个数据包,从而极大提升了包过滤的性能,进而被各大操作系统广泛接受。BPF 最初的名字 BSD Packet Filter ,也被作者的工作单位名所替代,变成了 Berkeley Packet Filter(很巧的是,还是简称BPF)。
在 BPF 诞生五年后,Linux 2.1.75 首次引入了 BPF 技术,随后 BPF 开始了不温不火的发展历程。其中,Linux 3.0 中增加的 BPF 即时编译器可以算是一个最重大的更新了。它替换掉了原本性能更差的解释器,进一步优化了 BPF 指令运行的效率。但直到此时,BPF 的应用还是仅限于网络包过滤这个传统的领域中。
时间到了 2014 年。为了研究新的软件定义网络方案,Alexei Starovoitov 为 BPF 带来了第一次革命性的更新,将 BPF 扩展为一个通用的虚拟机,也就是 eBPF。eBPF 不仅扩展了寄存器的数量,引入了全新的 BPF 映射存储,还在 4.x 内核中将原本单一的数据包过滤事件逐步扩展到了内核态函数、用户态函数、跟踪点、性能事件(perf_events)以及安全控制等。
eBPF 的诞生是 BPF 技术的一个转折点,使得 BPF 不再仅限于网络栈,而是成为内核的一个顶级子系统。
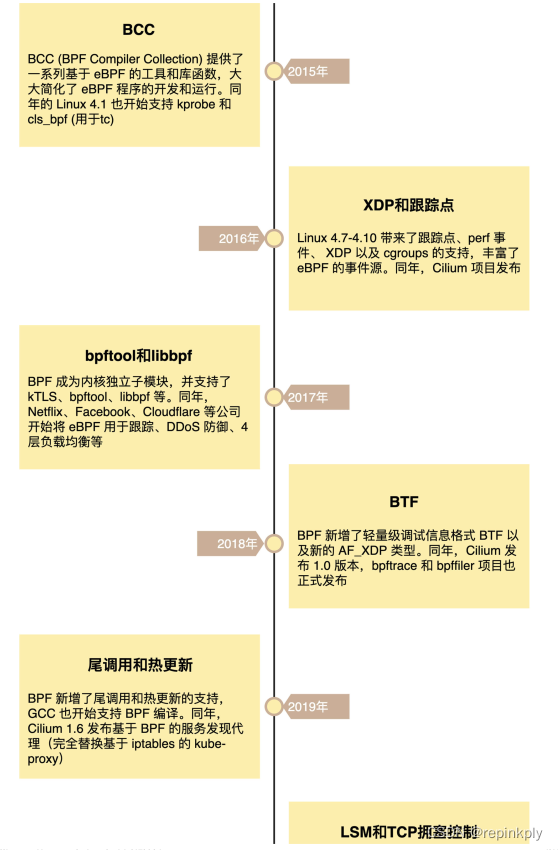
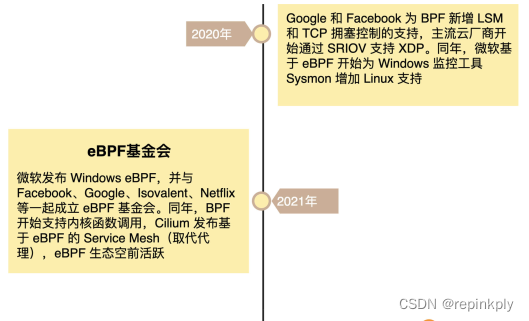
在内核发展的同时,eBPF 繁荣的生态也进一步促进了 eBPF 的蓬勃发展。这其中,最典型的就是 iovisor 带来的 BCC、bpftrace 等工具,成为 eBPF 在跟踪和排错领域的最佳实践。由于 eBPF 无需修改内核源码和重新编译内核就可以扩展内核的功能,Cilium、Katran、Falco 等一系列基于 eBPF 优化网络和安全的开源项目也逐步诞生。并且,越来越多的开源和商业解决方案开始借助 eBPF,优化其网络、安全以及观测的性能。比如,最流行的网络解决方案之一 Calico,就在最近的版本中引入了 eBPF 数据面网络,大大提升了网络的性能。
为了帮你更好地理解 eBPF 的发展历程,我把 eBPF 诞生以来的发展过程整理成了一张图片:
eBPF 是怎么工作的?
eBPF 程序并不像常规的线程那样,启动后就一直运行在那里,它需要事件触发后才会执行。这些事件包括系统调用、内核跟踪点、内核函数和用户态函数的调用退出、网络事件,等等。借助于强大的内核态插桩(kprobe)和用户态插桩(uprobe),eBPF 程序几乎可以在内核和应用的任意位置进行插桩。
看到这个令人惊叹的能力,你一定有疑问:这会不会像内核模块一样,一个异常的 eBPF程序就会损坏整个内核的稳定性呢?其实,确保安全和稳定一直都是 eBPF 的首要任务,不安全的 eBPF 程序根本就不会提交到内核虚拟机中执行。
Linux 内核是如何实现 eBPF 程序的安全和稳定的呢?其实很简单,我带你看个 eBPF 程序的执行过程,你就明白了。
如下图(图片来自 brendangregg.com)所示,通常我们借助 LLVM 把编写的 eBPF程序转换为 BPF 字节码,然后再通过 bpf 系统调用提交给内核执行。内核在接受 BPF 字节码之前,会首先通过验证器对字节码进行校验,只有校验通过的 BPF 字节码才会提交到即时编译器执行。
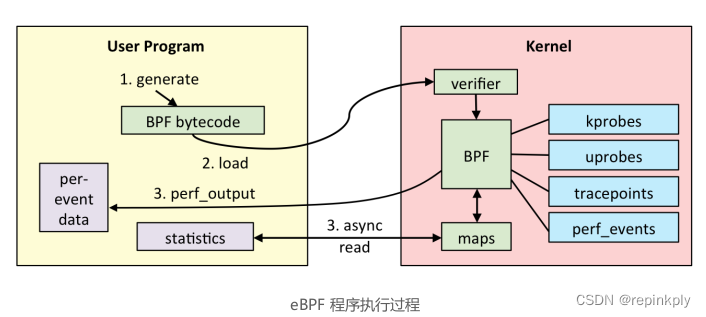
如果 BPF 字节码中包含了不安全的操作,验证器会直接拒绝 BPF 程序的执行。比如,下面就是一些典型的验证过程:
- 只有特权进程才可以执行 bpf 系统调用;
- BPF 程序不能包含无限循环;
- BPF 程序不能导致内核崩溃;
- BPF 程序必须在有限时间内完成。
BPF 程序可以利用 BPF 映射(map)进行存储,而用户程序通常也需要通过 BPF 映射同运行在内核中的 BPF 程序进行交互。如下图(图片来自 ebpf.io)所示,在性能观测中,BPF 程序收集内核运行状态存储在映射中,用户程序再从映射中读出这些状态。
可以看到,eBPF 程序的运行需要历经编译、加载、验证和内核态执行等过程,而用户态程序则需要借助 BPF 映射来获取内核态 eBPF 程序的运行状态。
eBPF 是万能的吗?
看到这里,你是不是因为 eBPF 在扩展内核功能上的强大能力而兴奋不已?我猜你已经迫不及待想要体验一下了。不过,在你体验之前,我还要提醒你一点:eBPF 并不是万能的,它也有很多的局限性。下面是一些最常见的 eBPF 限制:
- eBPF 程序必须被验证器校验通过后才能执行,且不能包含无法到达的指令;
- eBPF 程序不能随意调用内核函数,只能调用在 API 中定义的辅助函数;
- eBPF 程序栈空间最多只有 512 字节,想要更大的存储,就必须要借助映射存储;
- 在内核 5.2 之前,eBPF 字节码最多只支持 4096 条指令,而 5.2 内核把这个限制提高到了 100 万条;
由于内核的快速变化,在不同版本内核中运行时,需要访问内核数据结构的 eBPF 程序很可能需要调整源码,并重新编译。
小结
eBPF 是从 BPF 技术扩展而来的。BPF 出现后,一直都是网络数据包过滤的核心,但直到eBPF 诞生前,BPF 都仅用于包过滤这个场景中。eBPF 的诞生是 BPF 技术的一个转折点,使它的应用范围逐步从包过滤扩展到内核函数、用户函数、跟踪点、性能事件、安全控制等全新的领域中。而这也进一步催生了 Cilium、Katran、Falco 等一大批基于 eBPF 构建的网络和安全解决方案,形成了繁荣的 eBPF 生态。
eBPF 程序以内核事件触发的方式运行,并且其运行过程包括编译、加载、验证和内核态执行等。为了保护内核的安全和稳定,如果编译后 BPF 字节码中包含了不安全的操作,验证阶段会直接拒绝 BPF 程序的执行。
不过,需要提醒你的是:为了确保安全和稳定,eBPF 程序也有很多的限制,这是你在后续的学习过程中需要特别留心的。